四個Spring Data JPA性能提升技巧,讓你的程序更絲滑!
Spring Data JPA 是一個強大的工具,用于在 Java 應用程序中處理數據庫。它為查詢和持久化數據提供了一個易于使用且靈活的接口,并且可以顯著簡化數據訪問層。但是,如同其他工具一樣,正確使用 Spring Data JPA 來獲得最佳性能和效率非常重要。

在本文中,我們將探索使用 Spring Data JPA 優化性能的一些技巧和最佳實踐。
避免N+1查詢問題
N+1查詢問題是指在使用延遲加載機制時,當我們查詢一個實體對象及其關聯對象時,由于需要每次查詢相應的關聯對象,所以就會發生多次查詢數據庫的情況。例如,我們查詢一個包含 N 個訂單的用戶,而每個訂單又包含 M 個商品,則會發生 (N+1)*M 次查詢數據庫的情況,其中 N+1 是因為查詢用戶時也需要進行一次查詢。
這種情況下,當數據量較大時,就會導致性能問題和資源浪費。因此,在使用
Spring Data JPA 時,應注意避免 N+1 查詢問題,從而提高查詢效率。
解決 N+1 查詢問題有以下幾種方式:
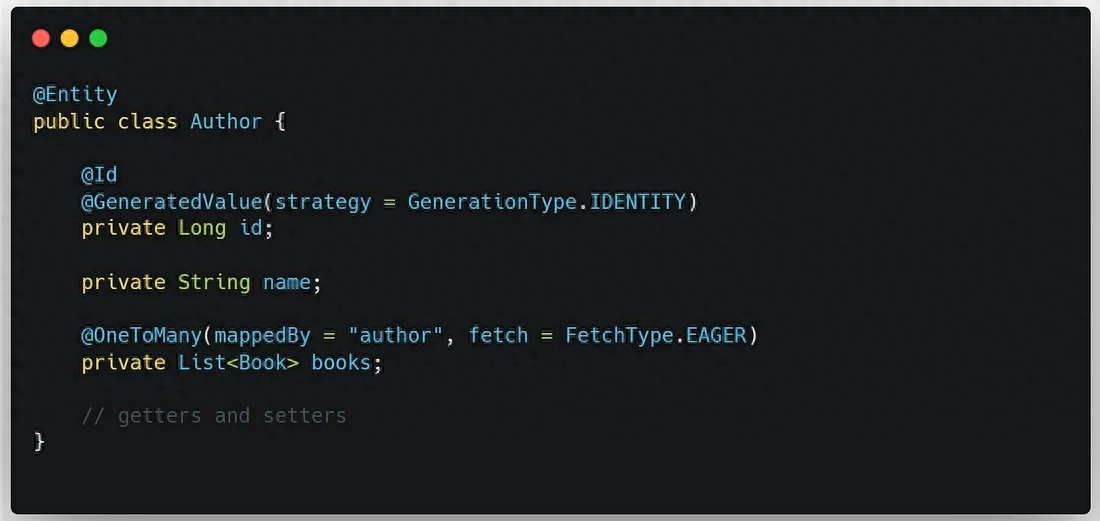
1.使用 FetchType.EAGER 進行即時加載
在定義實體類時,可以使用 @OneToMany 或 @ManyToOne 注解中的 fetch 屬性將關聯對象改為即時加載模式。但需要注意,如果關聯對象數量較大,可能會影響性能。

2.使用 @BatchSize 進行批量加載
@BatchSize 注解可以控制 Hibernate 在加載關聯對象時一次性加載的個數。例如,設置 @BatchSize(size = 100) 后,Hibernate 將會在一次查詢中加載 100 個關聯對象。
3.使用 JOIN FETCH 進行關聯查詢
使用 JPQL(Java Persistence Query Language)或 Criteria API 構建查詢語句時,可以使用 JOIN FETCH 關鍵字來實現關聯查詢,從而一次性加載關聯對象。
4.使用 EntityGraph 進行查詢
EntityGraph 是 JPA 2.1 中引入的一種機制,可以預定義實體類的加載圖(Load Graph),并在查詢時指定該加載圖,從而控制關聯對象的加載方式。例如,可以使用 @NamedEntityGraph 注解在實體類上定義加載圖,然后在查詢時使用 @EntityGraph 注解指定該加載圖。
需要注意的是,采用以上幾種方式來解決 N+1 查詢問題時,需要根據具體情況進行選擇和調整,避免出現新的性能問題。
使用延遲加載
延遲加載是一種將對象或數據的加載延遲到需要時才加載的技術。換句話說,延遲加載不是一次加載所有數據,而是在請求時只加載所需的數據。這可以通過減少加載到內存中的不必要數據量來節省大量時間和資源。
Spring Data JPA 支持兩種加載方式:即時加載(Eager loading)和延遲加載(Lazy loading)。即時加載是指在查詢實體對象時,將其關聯的所有對象都一并加載;而延遲加載則是指只有在需要使用到關聯對象時才進行加載。
下面是使用 Spring Data JPA 延遲加載的示例代碼:
@Entity
public class Order {
@Id
private Long id;
@OneToMany(mappedBy = "order", fetch = FetchType.LAZY)
private List<Item> items;
// getters and setters
}
@Entity
public class Item {
@Id
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
private Order order;
// getters and setters
}在上述代碼中,我們通過設置 @ManyToOne 和 @OneToMany 注解的 fetch 屬性為 FetchType.LAZY 來實現延遲加載。當我們查詢訂單對象時,與之關聯的商品列表并不會立即加載,只有當需要訪問該列表時才會進行加載。
需要注意的是,如果在延遲加載模式下訪問了未初始化的集合屬性,就會拋出
org.hibernate.LazyInitializationException 異常。為了避免這種情況,可以將實體類及其關聯對象一起加載,或者手動使用 Hibernate.initialize() 方法進行初始化。
使用緩存
緩存是一種用于將經常使用的數據存儲在內存中以便可以更快地訪問的技術。這可以顯著減少數據庫查詢的數量并提高應用程序的性能。Spring Data JPA 使用 Ehcache、Hazelcast、Infinispan、Redis 等流行的緩存框架為緩存提供內置支持。
Spring Data JPA 支持一級緩存和二級緩存。一級緩存是指在同一個事務下,對于相同的實體對象,第二次查詢時直接從緩存中獲取數據,而不需要再次查詢數據庫;二級緩存則是指多個事務之間共享同一個緩存區域。
下面是使用 Spring Data JPA 緩存的示例代碼:
1.一級緩存
@Repository
public class OrderRepositoryImpl implements OrderRepository {
@PersistenceContext
private EntityManager em;
@Override
@Transactional(readOnly = true)
public Order findById(Long id) {
return em.find(Order.class, id);
}
}在上述代碼中,我們通過 @PersistenceContext 注解注入了 EntityManager 對象,并在查詢時開啟了只讀事務。由于在同一個事務下,EntityManager 對象會自動緩存查詢過的實體對象,因此當我們多次查詢同一個訂單對象時,第二次查詢將直接從緩存中獲取,而不需要再次查詢數據庫。
2.二級緩存
@Entity
@Cacheable(true)
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class Order {
// ...
}
@Configuration
@EnableCaching
public class CacheConfig extends CachingConfigurerSupport {
@Bean
public CacheManager cacheManager() {
return new EhCacheCacheManager(ehCacheManager());
}
@Bean
public EhCacheManagerFactoryBean ehCacheManager() {
EhCacheManagerFactoryBean factory = new EhCacheManagerFactoryBean();
factory.setConfigLocation(new ClassPathResource("ehcache.xml"));
factory.setShared(true);
return factory;
}
}在上述代碼中,我們使用 @Cacheable 和 @Cache 注解對實體類進行緩存配置,并在配置類中開啟了緩存支持。同時,我們還需要在類路徑下添加一個名為 ehcache.xml 的 Ehcache 配置文件。
需要注意的是,使用二級緩存時需要謹慎,應根據具體的業務需求和系統性能要求來選擇使用何種類型的緩存,并合理配置相應的緩存策略。
使用分頁和排序
分頁和排序是用于限制查詢返回的結果數量并根據特定條件對結果進行排序的技術。在 Spring Data JPA 中,這些技術是使用接口實現的Pageable,該接口允許你指定頁面大小、排序標準和頁碼。
下面是使用 Spring Data JPA 分頁和排序的示例代碼:
1.分頁查詢
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
Page<Order> findAll(Pageable pageable);
}在上述代碼中,我們通過繼承 JpaRepository 接口來繼承 Spring Data JPA 提供的通用方法,并定義了一個名為 findAll 的方法并添加 Pageable 參數,從而實現分頁查詢功能。在調用該方法時,可以傳入一個 PageRequest 對象來指定查詢的頁數、每頁數據量以及排序方式等。
2.排序查詢
@Repository
public interface OrderRepository extends JpaRepository<Order, Long> {
List<Order> findByStatus(String status, Sort sort);
}在上述代碼中,我們定義了一個名為 findByStatus 的方法并添加 Sort 參數,從而實現根據狀態字段進行排序的查詢功能。在調用該方法時,可以傳入一個 Sort 對象來指定排序方式。
需要注意的是,在使用分頁和排序功能時,應盡可能減少查詢的數據量,避免出現性能問題。例如,可以使用查詢條件來限制查詢的范圍,或者對數據庫表建立索引等方式進行優化。
總結
使用 Spring Data JPA 與數據庫交互時,優化性能以確保有效利用資源和更快的響應時間非常重要。上述幾種技術可用于實現此目的:
- 避免 N+1 查詢問題;
- 使用延遲加載;
- 使用緩存;
- 使用分頁和排序。