Redis的高性能之謎
介紹
Redis通常用作緩存。當一致性要求不高時,它也可以用作存儲。此外,Redis還提供消息訂閱、事務、索引等功能。我們還可以使用集群功能構建分布式存儲服務,并實現非強一致性的分布式鎖服務。
在上述各種情況下,Redis都具有一個共同的優勢,即處理速度快(高性能)。

Redis有多快?
要了解Redis有多快,您需要有一個評估工具。
幸運的是,Redis提供了這樣一個工具,并提供了一些常用硬件平臺的性能數據。
- Redis基準測試可用于評估Redis的性能。命令行提供了在正常/管道模式下以及在不同壓力下評估特定命令性能的功能。
- Redis具有出色的性能。作為鍵值系統,最大負載級別為10W / s,設置和獲取時間消耗級別分別為10ms和5ms。使用流水線可以提高Redis操作的性能。
redis-benchmark -t set,lpush -n 100000 -q
SET: 97087.38 每秒請求 //處理97000次設置請求每秒
LPUSH: 101112.23 每秒請求 //處理100000次lpush請求每秒腳本執行時間
redis-benchmark -n 100000 -q script load "redis.call('set','foo','bar')"
SCRIPT load redis.call('set','foo','bar'): 101317.12 每秒請求, p50=0.255毫秒默認情況下,Redis基準測試使用100,000個請求、50個客戶端和3字節的負載進行測試。
Redis為何如此之快?
Redis是單線程應用程序,這意味著Redis使用單個線程來處理客戶端的請求。
Redis具有高性能的原因如下:
- 內存存儲:Redis使用內存(內存中)存儲,沒有磁盤I/O開銷。
- 單線程實現:Redis使用單個線程處理請求,避免了多線程之間的線程切換和鎖資源爭用的成本。
- 非阻塞I/O:Redis使用多路復用I/O技術,在poll、epoll和kqueue中選擇最佳的I/O實現。
- 優化的數據結構:Redis具有許多經過優化的數據結構實現,可以直接應用。應用層可以直接使用本機數據結構以提高性能。
單線程
Redis的核心網絡模型由單線程實現,這在一開始時曾引起了許多人的困惑。Redis官方對此的回答是:
CPU很少成為Redis的瓶頸,因為通常Redis要么是內存綁定的,要么是網絡綁定的。例如,使用管道在運行在平均Linux系統上的Redis上,每秒可以傳輸甚至100萬個請求,因此,如果您的應用程序主要使用O(N)或O(log(N))命令,它幾乎不會使用太多CPU。
單線程的好處是什么?
- 無需線程創建或線程銷毀引起的消耗
- 避免線程切換引起的CPU消耗
- 避免線程之間的競爭問題,如添加鎖、釋放鎖、死鎖等
此外,單線程機制極大地降低了Redis內部實現的復雜性。哈希的延遲重哈希、Lpush等“線程不安全”命令可以在無鎖的情況下執行。
I/O模型
一般來說,I/O操作分為兩個步驟:
- 等待數據從網絡到達,然后將其加載到內核空間緩沖區
- 將數據從內核空間緩沖區復制到用戶空間緩沖區
根據這兩個步驟是否阻塞線程,可以將其分為阻塞/非阻塞、同步/異步。
阻塞I/O模型
I/O最常見的模型是阻塞I/O模型,我們迄今為止在文本中使用的所有示例都使用了阻塞I/O模型。默認情況下,所有套接字都是阻塞的。
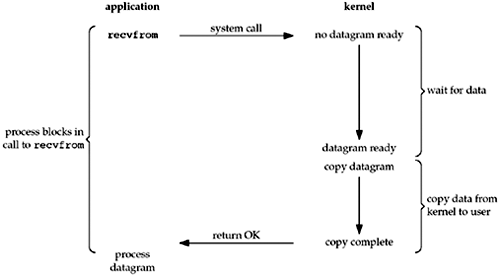
在此示例中,我們使用UDP而不是TCP,因為對于UDP,數據“準備”以供讀取的概念很簡單:要么接收到整個數據報,要么沒有。
而對于TCP,情況會更加復雜,因為還涉及到額外的變量,如套接字的低水位標記等。
非阻塞I/O模型
當我們將套接字設置為非阻塞時,我們告訴內核“當我請求的I/O操作不能在不使進程進入休眠的情況下完成時,請不要使進程進入休眠,而是返回一個錯誤”。
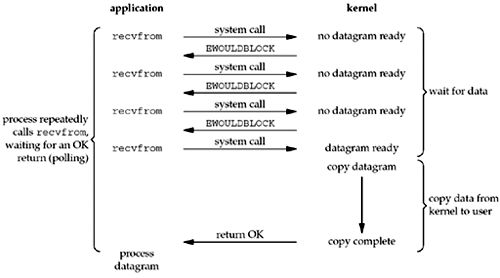
前三次調用recvfrom時,沒有數據返回,因此內核立即返回EWOULDBLOCK錯誤。第四次調用recvfrom時,數據報準備好了,它
被復制到我們的應用程序緩沖區中,recvfrom成功返回。然后我們處理數據。
當應用程序循環調用非阻塞描述符上的recvfrom時,這稱為輪詢。應用程序不斷輪詢內核,以查看某個操作是否準備好。這通常會浪費CPU時間,但通常在專用于一項功能的系統上遇到這種模型。
多路復用I/O模型
使用I/O多路復用時,我們調用select或poll并在這兩個系統調用中的一個中阻塞,而不是在實際I/O系統調用中阻塞。
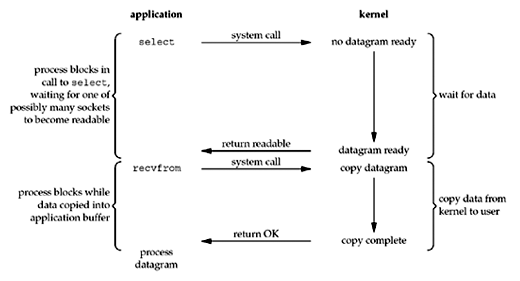
我們在調用select中阻塞,等待數據報套接字可讀。當select返回套接字可讀時,我們然后調用recvfrom將數據報復制到我們的應用程序緩沖區中。
與阻塞I/O相比,使用select似乎沒有任何優勢,實際上,由于使用select需要兩個系統調用而不是一個,因此實際上存在輕微的劣勢。
但使用select的優勢在于,我們可以等待多個描述符準備就緒。
現在讓我們看看Redis如何處理客戶端連接?
通常,Redis使用反應器設計模式,封裝了多個實現(select、epoll、kqueue等)以多路復用IO來處理來自客戶端的請求。
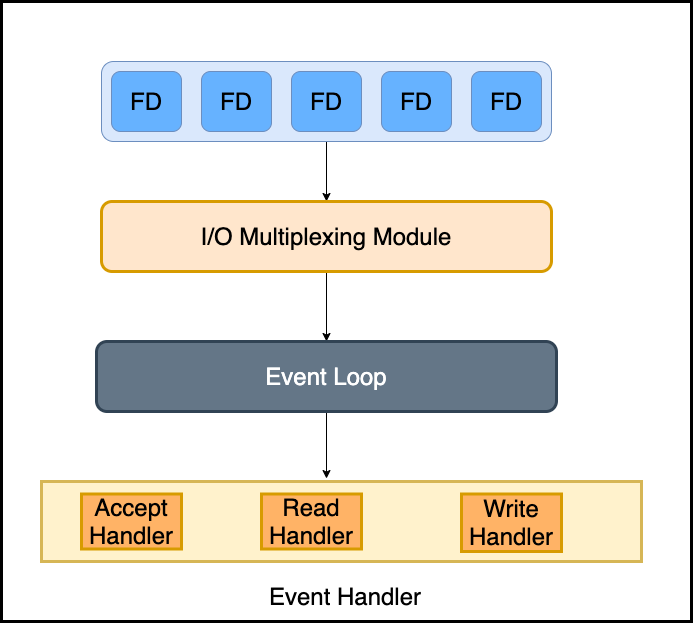
反應器設計模式通常用于實現事件驅動。此外,Redis在不同平臺上封裝了不同的多路復用IO庫。
Redis將優先選擇時間復雜度為O(1)的I/O多路復用函數作為底層實現,包括Solaris 10中的evport、Linux中的epoll和Mac OS / FreeBSD中的kqueue。
這些函數都使用內核的內部結構,并可以為數十萬個文件描述符提供服務。
但是,如果當前的編譯環境沒有上述函數,將選擇select作為備選方案。因為在使用時會掃描所有受監視的描述符,所以其時間復雜度較差O(n),同時一次只能為1024個文件描述符提供服務,因此通常不作為首選方案使用。