12個(gè)優(yōu)化SQL語句的小技巧,提升查詢性能
優(yōu)化SQL查詢的方法
在當(dāng)今數(shù)據(jù)驅(qū)動(dòng)的世界中,數(shù)據(jù)庫應(yīng)用程序已成為許多企業(yè)的重要組成部分。隨著越來越多的公司選擇在云端處理和存儲數(shù)據(jù),優(yōu)化查詢對于企業(yè)的利潤變得比以往任何時(shí)候都更加重要。

本文將介紹一些有效的技術(shù),以提升SQL查詢性能。下文是幾種優(yōu)化SQL查詢以提高性能的方法。
1. 減少使用通配符字符
在SQL查詢中使用通配符字符(例如%和_)會降低查詢性能。使用通配符字符時(shí),數(shù)據(jù)庫必須掃描整個(gè)表以查找相關(guān)數(shù)據(jù)。為了優(yōu)化SQL查詢,重要的是要減少使用通配符字符,僅在絕對必要時(shí)使用它們。
例如,有一個(gè)查詢,查找所有姓氏以字母“P”開頭的客戶。下面的查詢使用通配符字符查找所有匹配記錄:
SELECT * FROM customers WHERE last_name_city LIKE 'P%';這個(gè)查詢可以工作,但它會比使用last_name_city列上的索引的查詢慢。可以通過向last_name_city列添加索引并將其重寫來改進(jìn)查詢,如下:
SELECT * FROM customers WHERE last_name_city >= 'P' AND last_name < 'Q';這個(gè)查詢將使用姓氏列上的索引,并且比之前的查詢更快。
2. 使用索引提高查詢性能
使用索引可以加速 SQL 查詢,使得數(shù)據(jù)庫能夠快速查找符合特定條件的條目。索引是將表中一個(gè)或多個(gè)列的值映射為便于搜索匹配某個(gè)值或一定范圍行的唯一值的過程。
為了優(yōu)化 SQL 查詢,可以在經(jīng)常用于 WHERE、JOIN 和 ORDER BY 子句的列上創(chuàng)建索引。但是,創(chuàng)建過多的索引可能會降低數(shù)據(jù)修改操作(如 INSERT、UPDATE 和 DELETE)的性能。
在確定對哪些列進(jìn)行索引以及使用何種類型的索引時(shí),需要權(quán)衡讀取性能和寫入性能之間的關(guān)系。
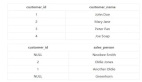
使用以下查詢查找特定客戶所做的所有訂單:
SELECT * FROM orders WHERE customer_number = 2154;由于數(shù)據(jù)庫必須搜索整個(gè)表以查找與客戶號匹配的條目,因此如果訂單表包含大量記錄,則此查詢可能需要很長時(shí)間。您可以在customer_number列上創(chuàng)建索引以改進(jìn)查詢:
CREATE INDEX idx_orders_customer_number ON orders (customer_id);這將在訂單表的customer_number列上創(chuàng)建一個(gè)索引。此時(shí)您運(yùn)行查詢時(shí),數(shù)據(jù)庫可以使用索引快速定位與客戶號匹配的行,從而提高查詢性能。
3. 使用適當(dāng)?shù)臄?shù)據(jù)類型
在數(shù)據(jù)庫中為列使用適當(dāng)?shù)臄?shù)據(jù)類型可以明顯提高查詢性能。例如,對于包含數(shù)字值的列,使用整數(shù)數(shù)據(jù)類型可以使查詢運(yùn)行速度比使用文本數(shù)據(jù)類型更快。同時(shí),選擇正確的數(shù)據(jù)類型還可以確保數(shù)據(jù)的完整性,避免數(shù)據(jù)轉(zhuǎn)換錯(cuò)誤。
讓我們考慮一個(gè)表,其中每一行表示零售店訂單的詳細(xì)信息。該表包含訂單ID、客戶ID、訂單日期和訂單總額等列。
訂單總額列包含數(shù)字值。如果將訂單總額列存儲為文本數(shù)據(jù)類型,則對訂單總額執(zhí)行計(jì)算的查詢將比將該列存儲為數(shù)字?jǐn)?shù)據(jù)類型的查詢速度更慢。
4. 避免子查詢
子查詢可能會降低查詢性能,特別是在WHERE或HAVING子句中使用時(shí)。盡可能避免子查詢,并改用JOIN或其他技術(shù)。
例如,有一個(gè)查詢,查找在過去30天內(nèi)下過訂單的所有客戶。以下查詢使用子查詢查找過去30天內(nèi)的所有訂單ID:
SELECT * FROM customers WHERE customer_id IN (SELECT customer_id FROM orders WHERE order_date >= DATEADD(day, -30, GETDATE()));這個(gè)查詢可以工作,但它會比使用JOIN查找相關(guān)數(shù)據(jù)的查詢慢。以下查詢使用JOIN查找在過去30天內(nèi)下過訂單的所有客戶:
SELECT DISTINCT c.* FROM customers c JOIN orders o ON c.customer_id = o.customer_id WHERE o.order_date >= DATEADD(day, -30, GETDATE());這個(gè)查詢將客戶表與訂單表連接起來,并檢索所有在過去30天內(nèi)下過訂單的客戶信息。這個(gè)查詢比前面的查詢更快,因?yàn)樗苊饬耸褂米硬樵儭?/p>
5. 使用LIMIT或TOP限制返回的行數(shù)
在 SQL 查詢中,可以使用 LIMIT 或 TOP 子句來限制返回的行數(shù)。這樣可以減少需要處理和返回的數(shù)據(jù)量。
例如,有個(gè)查詢用來查找在過去27天內(nèi)下過訂單的所有客戶。如果在過去27天內(nèi)有大量客戶下了訂單,則查詢可能會返回大量行。這可以使用LIMIT或TOP進(jìn)行優(yōu)化。以下查詢將返回的行數(shù)限制為10:
SELECT TOP 10 * FROM customers WHERE customer_id IN (SELECT customer_id FROM orders WHERE order_date >= DATEADD(day, -27, GETDATE()));這個(gè)查詢將只返回與條件匹配的前10行,這將提高查詢性能。
6. 避免使用SELECT*
使用SELECT* 語句可能會降低查詢性能,因?yàn)樗祷乇碇械乃辛校ú恍枰樵兊牧小榱藘?yōu)化SQL查詢,重要的是只選擇需要查詢的列。
例如,考慮一個(gè)查詢,查找在過去30天內(nèi)下過訂單的所有客戶。以下查詢從客戶表中選擇所有列:
SELECT * FROM customers WHERE customer_id IN (SELECT customer_id FROM orders WHERE order_date >= DATEADD(day, -30, GETDATE()));為了優(yōu)化查詢,可以修改SELECT語句以僅選擇所需的列:
SELECT customer_id, first_name, last_name FROM customers WHERE customer_id IN (SELECT customer_id FROM orders WHERE order_date >= DATEADD(day, -30, GETDATE()));這個(gè)查詢將只選擇客戶ID、名字和姓氏列,這將提高查詢性能。
7. 使用EXISTS而不是IN
使用IN運(yùn)算符可以將值與子查詢返回的值列表進(jìn)行比較。但是,使用IN可能會降低查詢性能,因?yàn)樗髷?shù)據(jù)庫對子查詢執(zhí)行完整的表掃描。為了優(yōu)化SQL查詢,可以考慮使用EXISTS運(yùn)算符來替代IN。
使用EXISTS運(yùn)算符時(shí),數(shù)據(jù)庫只需要判斷子查詢是否返回至少一行結(jié)果,而不需要返回全部匹配的結(jié)果集。這樣可以減少數(shù)據(jù)庫的工作量,提高查詢性能。
例如,考慮一個(gè)查詢,查找在過去30天內(nèi)下過訂單的所有客戶:
SELECT * FROM customers WHERE customer_id IN (SELECT customer_id FROM orders WHERE order_date >= DATEADD(day, -30, GETDATE()));這個(gè)查詢使用IN將客戶ID與子查詢返回的客戶ID列表進(jìn)行比較。為了優(yōu)化查詢,可以使用EXISTS代替IN:
SELECT * FROM customers c WHERE EXISTS (SELECT 1 FROM orders o WHERE o.customer_id = c.customer_id AND o.order_date >= DATEADD(day, -30, GETDATE()));這個(gè)查詢使用EXISTS來檢查訂單表中是否存在匹配的行,而不是使用IN。這可以通過避免對子查詢進(jìn)行完整表掃描來提高查詢性能。
8. 使用GROUP BY對數(shù)據(jù)進(jìn)行分組
使用GROUP BY對數(shù)據(jù)進(jìn)行分組,可以按照一個(gè)或多個(gè)列對行進(jìn)行分組。這在對數(shù)據(jù)進(jìn)行匯總或執(zhí)行聚合函數(shù)時(shí)非常有用。但是,如果過度使用GROUP BY會降低查詢性能。為了優(yōu)化SQL查詢,應(yīng)該僅在必要的情況下使用GROUP BY。
例如,考慮一個(gè)查詢,以查找每個(gè)客戶下的訂單總數(shù):
SELECT customer_id, COUNT(*) as order_count FROM orders GROUP BY customer_id;此查詢使用GROUP BY按客戶ID分組行,并計(jì)算每個(gè)客戶下的訂單數(shù)量。為了優(yōu)化查詢,可以使用子查詢檢索客戶信息并將其與訂單表連接:
SELECT c.customer_id, c.first_name, c.last_name, o.order_count FROM customers c JOIN (SELECT customer_id, COUNT(*) as order_count FROM orders GROUP BY customer_id) o ON c.customer_id = o.customer_id;此查詢使用子查詢計(jì)算每個(gè)客戶下的訂單數(shù)量,然后將結(jié)果與客戶表連接以檢索客戶信息。這避免了使用GROUP BY,并可以提高查詢性能。
9. 使用存儲過程
存儲過程是指預(yù)先編譯的SQL語句,存儲在數(shù)據(jù)庫中的程序。存儲過程可以從應(yīng)用程序或直接從SQL查詢中調(diào)用,以提高查詢性能。使用存儲過程能夠減少在數(shù)據(jù)庫和應(yīng)用程序之間傳輸?shù)臄?shù)據(jù)量,并且減少編譯和執(zhí)行SQL語句所需的時(shí)間,從而提高查詢性能。
10. 優(yōu)化數(shù)據(jù)庫設(shè)計(jì)
優(yōu)化數(shù)據(jù)庫設(shè)計(jì)也可以提高查詢性能。包括確保表被正確規(guī)范化并且索引被有效使用。此外,還需要確保數(shù)據(jù)庫針對預(yù)期的工作負(fù)載進(jìn)行適當(dāng)?shù)恼{(diào)整,并配置適當(dāng)?shù)牟l(fā)級別。
11. 使用查詢優(yōu)化工具
有許多查詢優(yōu)化工具可用,可以幫助識別SQL查詢中的性能問題。這些工具可以提供改進(jìn)查詢性能的建議,例如創(chuàng)建索引、重寫查詢或優(yōu)化數(shù)據(jù)庫設(shè)計(jì)。一些流行的查詢優(yōu)化工具包括Microsoft SQL Server Query Optimizer、Oracle SQL Developer和MySQL Query Optimizer。
12. 監(jiān)控查詢性能
監(jiān)控查詢性能是優(yōu)化SQL查詢的重要步驟。通過監(jiān)視查詢性能,可以識別性能問題并進(jìn)行適當(dāng)?shù)恼{(diào)整。這可以包括優(yōu)化索引、重寫查詢或調(diào)整數(shù)據(jù)庫設(shè)計(jì)。有許多工具可用于跟蹤查詢性能,包括SQL Server Profiler、Oracle Enterprise Manager和MySQL Enterprise Monitor。
結(jié)語
為了確保數(shù)據(jù)庫應(yīng)用程序的高效運(yùn)行,優(yōu)化SQL查詢以提高性能是非常重要的。通過本文,我們可以得出以下結(jié)論:
- 索引是提高SQL查詢性能最有效的技術(shù),但在決定對哪些列創(chuàng)建索引以及使用何種類型的索引時(shí),需要仔細(xì)考慮讀取性能和寫入性能之間的權(quán)衡。
- 優(yōu)化SQL查詢是一個(gè)持續(xù)的過程,需要定期監(jiān)控和調(diào)整,以確保持續(xù)的性能改進(jìn)。
- 為了提高性能,應(yīng)盡量減少使用JOIN、GROUP BY、IN和子查詢等耗費(fèi)資源的操作。
- 為了確保優(yōu)化效果符合預(yù)期,應(yīng)該在實(shí)際數(shù)據(jù)集上對查詢進(jìn)行測試。