MySQL高可用:分庫分表你學廢了嗎?
1. 引言
為什么企業招不到人,求職者也說找不到工作?
前段時間公司的師兄在面試候選人之后,發出了這樣感慨:2023 年,企業太難招到人了!
而同時,脈脈(技術圈社交軟件)上也是一片哀鴻,說今年互聯網行情非常差。
 圖片來源:脈脈,侵刪
圖片來源:脈脈,侵刪
也正如脈脈這位網友所言,現在做普通業務的后臺開發基本都是 CRUD(數據庫 “增刪改查” 的意思,形容沒有技術含量的活),正常情況下很少涉及高并發、海量數據的實踐場景。
畢竟,技術服務于業務,如果你的業務每天就幾百人使用,咱搞個能抗幾千萬并發的系統又有什么意義呢?
性價比不高!
但是,這些企業 HR 能不知道嗎?企業面試官也不是傻子,天天在簡歷和面試上挑挑揀揀的,也耽誤時間。有這功夫,不如在工位多摸一會魚,不香嗎?
所以啊,你用沒用過,和你知不知道是兩個概念。面評里一般會有幾個等級的打分,分別是:
- 差:和簡歷完全不符,懷疑簡歷造假。
- 中:可以略答一二,但核心要點說不清楚。
- 良:可以說清楚,但實踐不足。
- 優:邏輯清晰,表達精準,實踐豐富。
但是,有面評的前提是:你得通過簡歷。
如果你的簡歷全是 CRUD,那面試官根本不會想和你聊!
所以,為了擺脫 CRUD-candidate 的身份,今天小?和大家聊一聊數據量增長和高并發帶來的數據庫問題以及如何解決。
1.2 用戶激增,怎么破?
當用戶量和數據量激增時,對于 MySQL 這樣的關系型數據庫管理系統,如何有效地應對高并發、高性能成了工程師們一項重要的任務。
在這篇文章中,我們將探討兩種常見的數據庫架構設計策略:MySQL 的拆表(Sharding)和分片(Table Partitioning)。
 圖片
圖片
這兩種策略都旨在應對數據規模的增大以及高并發訪問的問題,但它們各有特點,適用于不同的場景和需求。
本文將通過深入拆表和分片的原理、應用場景以及優缺點,為大家揭示如何在面對不斷增長的數據和流量時,保持數據庫的高性能和可用性。
無論您是一名數據庫工程師、開發人員,還是對數據庫架構設計感興趣的朋友,本文都將為您提供有價值的見解,幫助您更好地應對數據庫擴展的挑戰。
而且,數據庫擴展是架構設計繞不開的一項重要話題,更是簡歷和面試中合理 Zhuangbility 的要點內容。
低投入,高回報,性價比極高!
接下來讓我們一起深入探討 MySQL 拆表和分片,為構建可靠的系統架構鋪平道路吧~~
2. 拆表
拆表是一種常見的數據庫分割技術,通常用于解決單表數據量過大、查詢性能下降以及維護困難等問題,下面是拆表的一些場景及其優缺點。
什么時候拆表?
- 大數據量表:拆表適用于那些包含大量數據的表,例如日志表、歷史數據表、交易記錄表等。當單個表的數據量已經超過數據庫服務器的處理能力時,拆分成多個子表可以提高查詢性能。
- 數據分區:某些應用需要按照時間、地理位置等維度對數據進行分區存儲,以便更有效地管理和查詢數據。拆表可以將不同分區的數據存儲在不同的子表中,提高數據管理的效率。
- 權限控制:在某些情況下,不同用戶或應用程序需要訪問相同表的不同數據集。通過拆分表,可以更容易地實現數據的權限控制。
怎么拆表?
假設有一個 ChatGPT 人機對話系統,其中有一個對話表,每個對話包含多條對話句子。
在對話表 dialog 有一問一答兩條數據:
dialog_id | user_id | sentence_id | content | role | state | created_at |
1 | 1 | 1 | 你好啊,你叫什么名字 | prompt | unfinished | 2023-09-25 |
1 | 1 | 2 | 我叫 xin猿意碼 | answer | unfinished | 2023-09-26 |
可以發現,數據庫的 dialog_id、user_id、state 等信息重復冗余了。當數據量增多時,類似的數據不僅會大量浪費磁盤空間,還會在查詢時影響整體性能,所以我們可以將其拆為兩個表:
dialog 對話表
dialog_id | user_id | state |
1 | 1 | unfinished |
sentence 對話句子表
dialog_id | sentence_id | content | role | created_at |
1 | 1 | 你好啊,你叫什么名字 | prompt | 2023-09-25 |
1 | 2 | 我叫 xin猿意碼 | answer | 2023-09-26 |
這只是個相對簡單的拆表例子,還有一些拆表可能根據用戶,或者時間來拆表。
 圖片
圖片
比如,對于時間敏感的查詢業務,可以將主表按年、月、日來拆為多個表,以提升查詢性能。
拆表的好處
- 提高查詢性能:拆表可以將大表拆分成多個較小的子表,從而加快查詢速度。查詢只需要針對特定子表進行,減少了掃描的數據量。
- 靈活性:拆表可以根據不同的業務需求進行定制,例如按時間、地理位置、用戶等維度進行拆分,提高數據管理的靈活性。
- 維護和備份:拆表可以使備份和維護更加容易,可以單獨備份和維護每個子表,而不影響其他子表的正常運行。
拆表的壞處
- 復雜性:拆表需要額外的管理和維護工作,包括數據遷移、查詢路由、子表之間的關聯等。增加了系統復雜性。
- 查詢路由:在查詢時需要確定查詢應該路由到哪個子表,這可能需要額外的路由邏輯和代碼。
- 跨子表查詢:如果查詢需要涉及多個子表的數據,可能需要更復雜的 SQL 查詢語句和邏輯。
- 數據一致性:在拆表的環境下,確保數據一致性可能會更加復雜,需要額外的措施。
綜合考慮,拆表是一種有效的數據庫性能優化方法,但需要根據具體的業務需求和數據特點來決定是否采用,以及如何進行拆表設計。
3. 分片
分片 是將大型數據庫分成多個小片段的方法,每個片段獨立運行。
使用分片場景包括:
- 高并發寫入:當一個表需要頻繁進行插入、更新或刪除操作,可能會導致鎖競爭和性能下降。通過拆分表,可以將寫入操作分散到多個分片,減輕鎖競爭,提高并發性能。
- 多租戶系統:在多租戶系統中,不同租戶的數據可以存儲在不同的分片中,確保數據隔離。
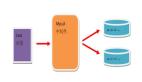
分片也需要考慮數據一致性和查詢路由的問題。通常,分片數據庫需要一個中心控制節點來管理數據分布和查詢路由。
比如,在上述 dialog 表例子上,我們用 user_id 作為哈希鍵分片。
 圖片
圖片
具體做法為:把數據的 user_id 對數據分片數量取余,假設我們一共有 8 個分片,user_id 為 10 時,就將該數據插入 dialog_2 的分片中(10%8 = 2)。
查詢時也是先哈希,再去對應的分片上查找數據,以此減少每個分片的數據量,提升數據庫的響應速度,分片的優缺點如下。
分片的好處
- 水平擴展:分片允許數據庫系統水平擴展,通過添加更多的分片來增加存儲容量和吞吐量。
- 高并發:每個分片可以并行處理寫入操作,減少鎖競爭,提高并發性能。
- 數據隔離:不同分片之間的數據相互隔離,有助于保持數據的完整性和隱私性。
分片的壞處
- 復雜性:分片增加了系統的復雜性,包括數據路由、分片鍵選擇、數據遷移等方面的管理工作。
- 跨分片查詢:在跨越多個分片的查詢中,需要合并和聚合數據,可能導致性能下降。
- 數據一致性:確保跨分片數據的一致性是一個挑戰,可能需要實施額外的措施。
看到這里,大家可能有點疑惑。對于數據量的增加,拆表和分片都可以起到一定的作用,也都會出現數據一致性問題,那他們的區別是啥呢?
別急,接著往下看。
4. 拆表 VS 分片
MySQL的拆表和分片都是用于處理大規模數據的技術,但它們的應用場景和方式有所不同,以下是它們的聯系和區別。
相同點
- 處理大規模數據:拆表和分片都是為了應對數據量巨大的情況而設計的。它們可以提高數據庫系統的性能和擴展性,以應對高并發和大量數據存儲需求。
- 水平擴展:拆表和分片都支持水平擴展,允許將數據分布在多個物理存儲位置上,以分攤負載并提高性能。
不同點
應用場景不同
- 拆表:通常在單一表中存儲的數據量已經非常龐大,難以繼續擴展或查詢性能下降時,考慮拆分表。拆表是將單一表按照某種規則或邏輯分割成多個較小的表,通常是為了提高查詢性能或簡化數據管理。每個拆分的表通常保留原表的一部分數據。
- 分片:適用于整個數據庫的數據量已經無法容納在一臺服務器上,或者需要跨多臺服務器水平擴展的情況。分片是將數據庫中的數據按照某種規則或策略分布到多個物理服務器上,每個服務器稱為一個分片。分片通常是為了提高整體系統的性能、可用性和擴展性。
數據分布方式不同
- 拆表:拆表是在邏輯上將數據拆分為多個表,但這些表通常仍然存儲在同一個數據庫實例中。各個表之間可能存在關聯關系,但它們在同一數據庫中。
- 分片:分片是將數據分布到多個物理服務器上,每個服務器上都有自己的數據庫實例。各個分片之間通常是獨立的,可以在不同的服務器上運行。
管理復雜度不同
- 拆表:相對于分片,拆表的管理復雜度較低,因為所有數據仍然在同一個數據庫中。但需要注意表之間的關聯和查詢性能。
- 分片:分片可能涉及到跨多個服務器的數據同步、故障恢復、路由管理等復雜問題,管理上相對復雜一些。
查詢方式不同
- 拆表:查詢通常需要在多個表之間進行聯合或使用應用程序邏輯來合并結果,查詢性能可能會因此受到一定影響。
- 分片:分片系統通常具有路由層,負責將查詢路由到正確的分片上,因此查詢通常更為直接和高效。
綜上所述,拆表和分片都是用于處理大規模數據的技術,但在應用場景、管理復雜度、數據分布方式和查詢方式等方面存在差異。
選擇哪種技術取決于具體的需求和系統架構,一般情況下,應對高并發和海量數據,分片拆表(又叫分庫分表)都會用到。
數據一致性問題
拆表和分片都可能引入數據一致性問題,但問題的性質和解決方法有所不同。
拆表的數據一致性問題
還以上述的對話表舉例,原始的 dialog 表是一個單一的表,每個對話項都以對話 ID 關聯。
現在,為了優化查詢性能,決定將對話表拆分為兩個表:dialog 和 sentence 表。
在這種情況下,數據一致性問題可能出現在以下情況下:
- 當向 dialog 表插入新對話時,如果在插入 sentence 之前發生了錯誤,可能導致對話主表和對話句子表之間的數據不一致。
- 當從 dialog 表刪除對話時,如果在刪除相關的對話句子之前發生了錯誤,也可能導致數據不一致。
解決這些問題的方法通常包括使用事務或一致性哈希等技術來確保數據操作的原子性。如果數據一致性對業務非常重要,建議使用數據庫事務來處理這些操作。
不了解事務的朋友可以看我之前的這篇文章,解鎖MySQL的黑科技:事務與隔離
分片的數據一致性問題
假設有一個社交媒體應用程序,用戶數據表存儲了全球 10 億用戶的數據,現在決定將用戶數據分片到不同的數據庫服務器上,以提高性能。
分片的方式可能是按用戶 ID 的范圍進行劃分,每個分片負責一定范圍內的用戶數據。
在這種情況下,數據一致性問題可能出現在以下情況下:
- 當用戶在不同分片之間進行互動(例如,用戶 A 在分片 1 上,用戶 B 在分片 2 上)時,需要確保跨分片的操作具有一致性。
- 如果一個分片的服務器發生故障,需要確保用戶數據可以遷移到其他分片而不丟失或破壞。
解決這些問題的方法通常包括使用分布式事務或一致性哈希等分片技術。例如,可以使用分布式事務來確保跨分片的操作是原子性的,或者使用數據復制和備份來確保故障恢復。
總之,拆表和分片都可能引入數據一致性問題,但可以通過適當的技術和設計來解決這些問題,以確保數據的完整性和一致性。
5. 小結
MySQL 拆表和分片的設計策略,為應對不斷增長的數據和高并發訪問提供了可行的解決方案,同時也伴隨著各自的優勢和挑戰。
拆表,像一位精巧的工匠,把復雜的數據庫切割成可管理的小塊,為數據的水平擴展提供了堅實的基礎。
而分片,似一位智慧的園丁,將數據按照規則有序地分類,使得數據庫的維護和查詢更加高效。
但是,無論是選擇拆表還是分片,都需要根據實際需求和場景來進行權衡和決策。
本文我們剖析了這兩種策略的內部工作原理,還深入探討了它們的使用場景、優點和限制。通過這些知識,相信屏幕前的你已經對如何更好地構建和維護 MySQL 數據庫有了更清晰的認識。
無論您是一名數據庫專業人士,還是對技術探索充滿激情的讀者,都希望這篇文章能為您帶來價值和啟發。