













圖解 V8 執行 JS 的過程

本文來分享 V8 引擎執行 JavaScript 的過程和垃圾回收機制。
1、JS 代碼執行過程
在說V8的執行JavaScript代碼的機制之前,我們先來看看編譯型和解釋型語言的區別。
(1)編譯型語言和解釋型語言
我們知道,機器是不能直接理解代碼的。所以,在執行程序之前,需要將代碼翻譯成機器能讀懂的機器語言。按語言的執行流程,可以把計算機語言劃分為編譯型語言和解釋型語言:
- 編譯型語言:在代碼運行前編譯器直接將對應的代碼轉換成機器碼,運行時不需要再重新翻譯,直接可以使用編譯后的結果。
- 解釋型語言:需要將代碼轉換成機器碼,和編譯型語言的區別在于運行時需要轉換。解釋型語言的執行速度要慢于編譯型語言,因為解釋型語言每次執行都需要把源碼轉換一次才能執行。
Java 和 C++ 等語言都是編譯型語言,而 JavaScript 是解釋性語言,它整體的執行速度會略慢于編譯型的語言。V8 是眾多瀏覽器的 JS 引擎中性能表現最好的一個,并且它是 Chrome 的內核,Node.js 也是基于 V8 引擎研發的。
編譯型語言和解釋器語言代碼執行的具體流程如下:
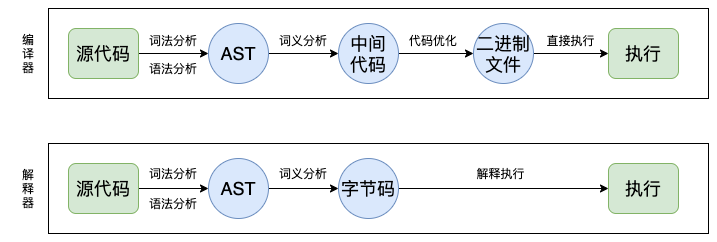
兩者的執行流程如下:
- 在編譯型語言的編譯過程中,編譯器首先會依次對源代碼進行詞法分析、語法分析,生成抽象語法樹(AST),然后優化代碼,最后再生成處理器能夠理解的機器碼。如果編譯成功,將會生成一個可執行的文件。但如果編譯過程發生了語法或者其他的錯誤,那么編譯器就會拋出異常,最后的二進制文件也不會生成成功。
- 在解釋型語言的解釋過程中,同樣解釋器也會對源代碼進行詞法分析、語法分析,并生成抽象語法樹(AST),不過它會再基于抽象語法樹生成字節碼,最后再根據字節碼來執行程序、輸出結果。
(2) V8 執行代碼過程
V8 在執行過程用到了解釋器和編譯器。 其執行過程如下:
- Parse 階段:V8 引擎將 JS 代碼轉換成 AST(抽象語法樹)。
- Ignition 階段:解釋器將 AST 轉換為字節碼,解析執行字節碼也會為下一個階段優化編譯提供需要的信息。
- TurboFan 階段:編譯器利用上個階段收集的信息,將字節碼優化為可以執行的機器碼。
- Orinoco 階段:垃圾回收階段,將程序中不再使用的內存空間進行回收。
這里前三個步驟是JavaScript的執行過程,最后一步是垃圾回收的過程。下面就先來看看V8 執行 JavaScript的過程。
生成抽象語法樹
這個過程就是將源代碼轉換為抽象語法樹(AST),并生成執行上下文,執行上下文就是代碼在執行過程中的環境信息。
將 JS 代碼解析成 AST主要分為兩個階段:
- 詞法分析:這個階段會將源代碼拆成最小的、不可再分的詞法單元,稱為 token。比如代碼 var a = 1;通常會被分解成 var 、a、=、1、; 這五個詞法單元。代碼中的空格在 JavaScript 中是直接忽略的,簡單來說就是將 JavaScript 代碼解析成一個個令牌(Token)。
- 語法分析:這個過程是將上一步生成的 token 數據,根據語法規則轉為 AST。如果源碼符合語法規則,這一步就會順利完成。如果源碼存在語法錯誤,這一步就會終止,并拋出一個語法錯誤,簡單來說就是將令牌組裝成一棵抽象的語法樹(AST)。
通過詞法分析會對代碼逐個字符進行解析,生成類似下面結構的令牌(Token),這些令牌類型各不相同,有關鍵字、標識符、符號、數字等。代碼 var a = 1;會轉化為下面這樣的令牌:
Keyword(var)
Identifier(name)
Punctuator(=)
Number(1)語法分析階段會用令牌生成一棵抽象語法樹,生成樹的過程中會去除不必要的符號令牌,然后按照語法規則來生成。下面來看兩段代碼:
// 第一段代碼
var a = 1;
// 第二段代碼
function sum (a,b) {
return a + b;
}將這兩段代碼分別轉換成 AST 抽象語法樹之后返回的 JSON 如下:
- 第一段代碼,編譯后的結果:
{
"type": "Program",
"start": 0,
"end": 10,
"body": [
{
"type": "VariableDeclaration",
"start": 0,
"end": 10,
"declarations": [
{
"type": "VariableDeclarator",
"start": 4,
"end": 9,
"id": {
"type": "Identifier",
"start": 4,
"end": 5,
"name": "a"
},
"init": {
"type": "Literal",
"start": 8,
"end": 9,
"value": 1,
"raw": "1"
}
}
],
"kind": "var"
}
],
"sourceType": "module"
}它的結構大致如下:
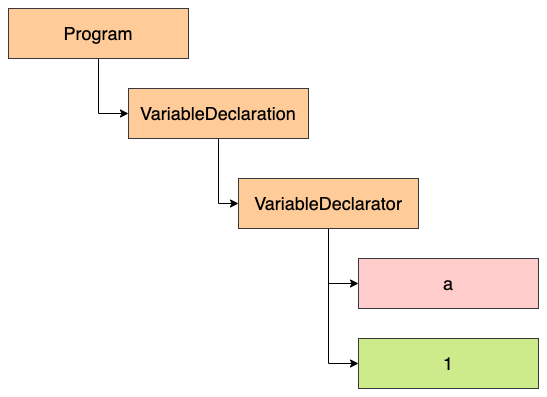
- 第二段代碼,編譯出來的結果:
{
"type": "Program",
"start": 0,
"end": 38,
"body": [
{
"type": "FunctionDeclaration",
"start": 0,
"end": 38,
"id": {
"type": "Identifier",
"start": 9,
"end": 12,
"name": "sum"
},
"expression": false,
"generator": false,
"async": false,
"params": [
{
"type": "Identifier",
"start": 14,
"end": 15,
"name": "a"
},
{
"type": "Identifier",
"start": 16,
"end": 17,
"name": "b"
}
],
"body": {
"type": "BlockStatement",
"start": 19,
"end": 38,
"body": [
{
"type": "ReturnStatement",
"start": 23,
"end": 36,
"argument": {
"type": "BinaryExpression",
"start": 30,
"end": 35,
"left": {
"type": "Identifier",
"start": 30,
"end": 31,
"name": "a"
},
"operator": "+",
"right": {
"type": "Identifier",
"start": 34,
"end": 35,
"name": "b"
}
}
}
]
}
}
],
"sourceType": "module"
}它的結構大致如下:
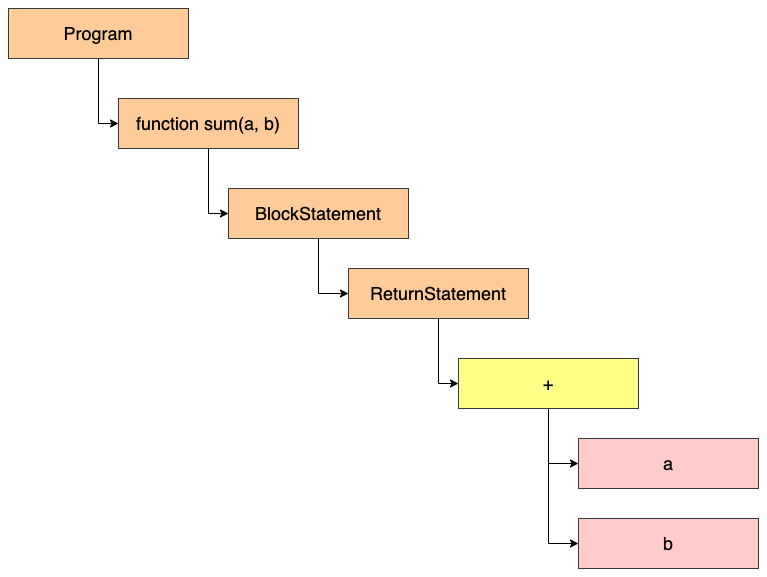
可以看到,AST 只是源代碼語法結構的一種抽象的表示形式,計算機也不會去直接去識別 JS 代碼,轉換成抽象語法樹也只是識別這一過程中的第一步。AST 的結構和代碼的結構非常相似,其實也可以把 AST 看成代碼的結構化的表示,編譯器或者解釋器后續的工作都需要依賴于 AST。
AST的應用場景:
AST 是一種很重要的數據結構,很多地方用到了AST。比如在 Babel 中,Babel 是一個代碼轉碼器,可以將 ES6 代碼轉為 ES5 代碼。Babel 的工作原理就是先將 ES6 源碼轉換為 AST,然后再將 ES6 語法的 AST 轉換為 ES5 語法的 AST,最后利用 ES5 的 AST 生成 JavaScript 源代碼。
除了 Babel 之外,ESLint 也使用到了 AST。ESLint 是一個用來檢查 JavaScript 編寫規范的插件,其檢測流程也是需要將源碼轉換為 AST,然后再利用 AST 來檢查代碼規范化的問題。
除了上述應用場景,AST 的應用場景還有很多:
- JS 反編譯,語法解析。
- 代碼高亮。
- 關鍵字匹配。
- 代碼壓縮。
生成字節碼
有了 抽象語法樹 AST 和執行上下文后,就輪到解釋器就登場了,它會根據 AST 生成字節碼,并解釋執行字節碼。
在 V8 的早期版本中,是通過 AST 直接轉換成機器碼的。將 AST 直接轉換為機器碼會存在一些問題:
- 直接轉換會帶來內存占用過大的問題,因為將抽象語法樹全部生成了機器碼,而機器碼相比字節碼占用的內存多了很多;
- 某些 JavaScript 使用場景使用解釋器更為合適,解析成字節碼,有些代碼沒必要生成機器碼,進而盡可能減少了占用內存過大的問題。
為了解決內存占用問題,就在 V8 引擎中引入了字節碼。那什么是字節碼呢?為什么引入字節碼就能解決內存占用問題呢?
字節碼就是介于 AST 和機器碼之間的一種代碼。 需要將其轉換成機器碼后才能執行,字節碼是對機器碼的一個抽象描述,相對于機器碼而言,它的代碼量更小,從而可以減少內存消耗。解釋器除了可以快速生成沒有優化的字節碼外,還可以執行部分字節碼。
生成機器碼
生成字節碼之后,就進入執行階段了,實際上,這一步就是將字節碼生成機器碼。
一般情況下,如果字節碼是第一次執行,那么解釋器就會逐條解釋執行。在執行字節碼過程中,如果發現有熱代碼(重復執行的代碼,運行次數超過某個閾值就被標記為熱代碼),那么后臺的編譯器就會把該段熱點的字節碼編譯為高效的機器碼,然后當再次執行這段被優化的代碼時,只需要執行編譯后的機器碼即可,這樣提升了代碼的執行效率。
字節碼配合解釋器和編譯器的技術就是 即時編譯(JIT)。在 V8 中就是指解釋器在解釋執行字節碼的同時,收集代碼信息,當它發現某一部分代碼變熱了之后,編譯器便閃亮登場,把熱點的字節碼轉換為機器碼,并把轉換后的機器碼保存起來,以備下次使用。
因為 V8 引擎是多線程的,編譯器的編譯線程和生成字節碼不會在同一個線程上,這樣可以和解釋器相互配合著使用,不受另一方的影響。下面是JIT技術的工作機制:

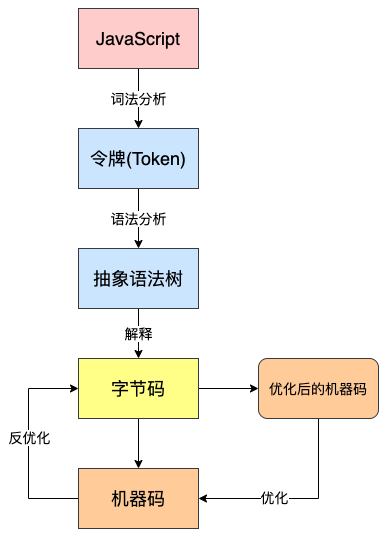
解釋器在得到 AST 之后,會按需進行解釋和執行。也就是說如果某個函數沒有被調用,則不會去解釋執行它。在這個過程中解釋器會將一些重復可優化的操作收集起來生成分析數據,然后將生成的字節碼和分析數據傳給編譯器,編譯器會依據分析數據來生成高度優化的機器碼。
優化后的機器碼的作用和緩存很類似,當解釋器再次遇到相同的內容時,就可以直接執行優化后的機器碼。當然優化后的代碼有時可能會無法運行(比如函數參數類型改變),那么會再次反優化為字節碼交給解釋器。
整個過程如下圖所示:
(3)執行過程優化
如果JavaScript代碼在執行前都要完全經過解析才能執行,那可能會面臨以下問題:
- 代碼執行時間變長:一次性解析所有代碼會增加代碼的運行時間。
- 消耗更多內存:解析完的 AST 以及根據 AST 編譯后的字節碼都會存放在內存中,會占用更多內存空間。
- 占用磁盤空間:編譯后的代碼會緩存在磁盤上,占用磁盤空間。
所以,V8 引擎使用了延遲解析:在解析過程中,對于不是立即執行的函數,只進行預解析;只有當函數調用時,才對函數進行全量解析。
進行預解析時,只驗證函數語法是否有效、解析函數聲明、確定函數作用域,不生成 AST,而實現預解析的,就是 Pre-Parser 解析器。
以下面代碼為例:
function sum(a, b) {
return a + b;
}
const a = 666;
const c = 996;
sum(1, 1);V8 解析器是從上往下解析代碼的,當解析器遇到函數聲明 sum 時,發現它不是立即執行,所以會用 Pre-Parser 解析器對其預解析,過程中只會解析函數聲明,不會解析函數內部代碼,不會為函數內部代碼生成 AST。
之后解釋器會把 AST 編譯為字節碼并執行,解釋器會按照自上而下的順序執行代碼,先執行 const a = 666; 和 const c = 996; ,然后執行函數調用 sum(1, 1) ,這時 Parser 解析器才會繼續解析函數內的代碼、生成 AST,再交給解釋器編譯執行。
2、垃圾回收
(1)JS 內存管理機制
計算機程序語言都運行在對應的代碼引擎上,使用內存過程可以分為以下三個步驟:
- 分配所需要的系統內存空間。
- 使用分配到的內存進行讀或寫等操作。
- 不需要使用內存時,將其空間釋放或者歸還。
在 JavaScript 中,當創建變量時,系統會自動給對象分配對應的內存,來看下面的例子:
var a = 123; // 給數值變量分配棧內存
var etf = "ARK"; // 給字符串分配棧內存
// 給對象及其包含的值分配堆內存
var obj = {
name: 'tom',
age: 13
};
// 給數組及其包含的值分配內存
var a = [1, null, "str"];
// 給函數分配內存
function sum(a, b){
return a + b;
}JavaScript 中的數據分為兩類:
- 基本類型:這些類型在內存中會占據固定的內存空間,它們的值都保存在棧空間中,直接可以通過值來訪問這些;
- 引用類型:由于引用類型值大小不固定,棧內存中存放地址指向堆內存中的對象,是通過引用來訪問的。
棧內存中的基本類型,可以通過操作系統直接處理;而堆內存中的引用類型,正是由于可以經常變化,大小不固定,因此需要 JavaScript 的引擎通過垃圾回收機制來處理。所謂的垃圾回收是指:JavaScript代碼運行時,需要分配內存空間來儲存變量和值。當變量不在參與運行時,就需要系統收回被占用的內存空間。 Javascript 具有自動垃圾回收機制,會定期對那些不再使用的變量、對象所占用的內存進行釋放,原理就是找到不再使用的變量,然后釋放掉其占用的內存。
JavaScript中存在兩種變量:局部變量和全局變量。全局變量的生命周期會持續要頁面卸載;而局部變量聲明在函數中,它的生命周期從函數執行開始,直到函數執行結束,在這個過程中,局部變量會在堆或棧中存儲它們的值,當函數執行結束后,這些局部變量不再被使用,它們所占有的空間就會被釋放。不過,當局部變量被外部函數使用時,其中一種情況就是閉包,在函數執行結束后,函數外部的變量依然指向函數內部的局部變量,此時局部變量依然在被使用,所以不會回收。
(2)V8 垃圾回收過程
先來看看 Chrome 瀏覽器的垃圾回收過程:
通過 GC Root 標記空間中活動對象和?活動對象
目前 V8 采用的可訪問性算法來判斷堆中的對象是否是活動對象。這個算法是將一些 GC Root 作為初始存活的對象的集合,從 GC Roots 對象出發,遍歷 GC Root 中所有對象:
- 通過 GC Root 遍歷到的對象是可訪問的,必須保證這些對象應該在內存中保留,可訪問的對象稱為活動對象。
- 通過 GC Roots 沒有遍歷到的對象是不可訪問的,這些不可訪問的對象就可能被回收,不可訪問的對象稱為非活動對象。
回收非活動對象所占據的內存
其實就是在所有的標記完成之后,統一清理內存中所有被標記為可回收的對象。
內存整理
一般來說,頻繁回收對象后,內存中就會存在大量不連續空間,這些不連續的內存空間稱為內存碎片。當內存中出現了大量的內存碎片之后,如果需要分配較大的連續內存時,就有可能出現內存不足的情況,所以最后一步需要整理這些內存碎片。這步其實是可選的,因為有的垃圾回收器不會產生內存碎片。
以上就是大致的垃圾回收流程。目前 V8 使用了兩個垃圾回收器:主垃圾回收器和副垃圾回收器。下面就來看看 V8 是如何實現垃圾回收的。
在 V8 中,會把堆分為新生代和老生代兩個區域,新生代中存放的是生存時間短的對象,老生代中存放生存時間久的對象:
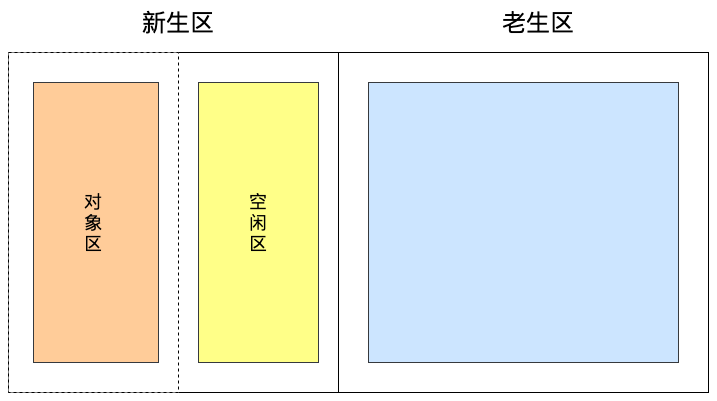
新?代通常只?持 1~8M 的容量,而老生代支持的容量就大很多。對于這兩塊區域,V8分別使用兩個不同的垃圾回收器,以便更高效地實施垃圾回收:
- 副垃圾回收器:負責新生代的垃圾回收。
- 主垃圾回收器:負責老生代的垃圾回收。
副垃圾回收器(新生代)
副垃圾回收器主要負責新生代的垃圾回收。大多數的對象最開始都會被分配在新生代,該存儲空間相對較小,分為兩個空間:from 空間(對象區)和 to 空間(空閑區)。
新加入的對象都會存放到對象區域,當對象區域快被寫滿時,就需要執行一次垃圾清理操作:首先要對對象區域中的垃圾做標記,標記完成之后,就進入垃圾清理階段。副垃圾回收器會把這些存活的對象復制到空閑區域中,同時它還會把這些對象有序地排列起來。這個復制過程就相當于完成了內存整理操作,復制后空閑區域就沒有內存碎片了:
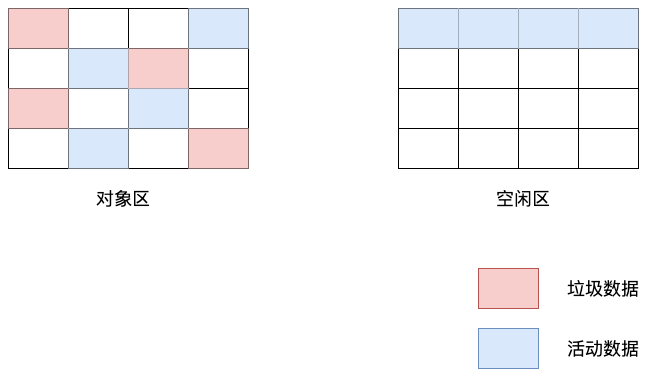
完成復制后,對象區域與空閑區域進行角色翻轉,也就是原來的對象區域變成空閑區域,原來的空閑區域變成了對象區域,這種算法稱之為 Scavenge 算法,這樣就完成了垃圾對象的回收操作。同時,這種角色翻轉的操作還能讓新生代中的這兩塊區域無限重復使用下去:

不過,副垃圾回收器每次執行清理操作時,都需要將存活的對象從對象區域復制到空閑區域,復制操作需要時間成本,如果新生區空間設置得太大了,那么每次清理的時間就會過久,所以為了執行效率,一般新生區的空間會被設置得比較小。 也正是因為新生區的空間不大,所以很容易被存活的對象裝滿整個區域,副垃圾回收器一旦監控對象裝滿了,便執行垃圾回收。同時,副垃圾回收器還會采用對象晉升策略,也就是移動那些經過兩次垃圾回收依然還存活的對象到老生代中。
主垃圾回收器(老生代)
主垃圾回收器主要負責老生代中的垃圾回收。除了新生代中晉升的對象,?些?的對象會直接被分配到老生代里。因此,老生代中的對象有兩個特點:
- 對象占用空間大。
- 對象存活時間間。
由于老生代的對象比較大,若要在老生代中使用 Scavenge 算法進行垃圾回收,復制這些大的對象將會花費較多時間,從而導致回收執行效率不高,同時還會浪費空間。所以,主垃圾回收器采用標記清除的算法進行垃圾回收。
這種方式分為標記和清除兩個階段:
- 標記階段: 從一組根元素開始,遞歸遍歷這組根元素,在這個遍歷過程中,能到達的元素稱為活動對象,沒有到達的元素就可以判斷為垃圾數據。
- 清除階段: 主垃圾回收器會直接將標記為垃圾的數據清理掉。
這兩個階段如圖所示:
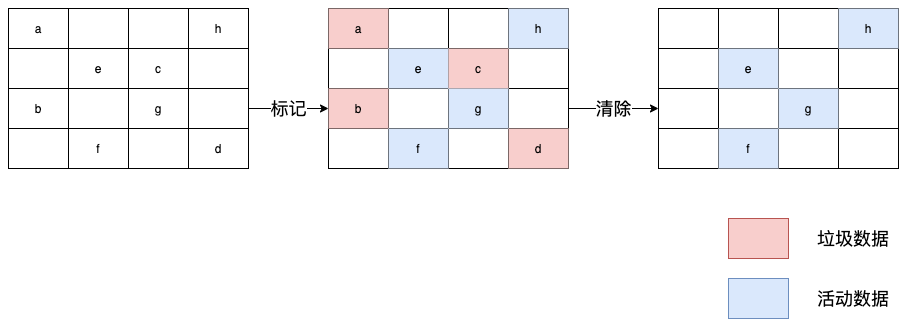
對垃圾數據進行標記,然后清除,這就是標記清除算法,不過對一塊內存多次執?標記清除算法后,會產生大量不連續的內存碎片。而碎片過多會導致大對象無法分配到足夠的連續內存,于是又引入了另外一種算法——標記整理。
這個算法的標記過程仍然與標記清除算法里的是一樣的,先標記可回收對象,但后續步驟不是直接對可回收對象進行清理,而是讓所有存活的對象都向一端移動,然后直接清理掉這一端之外的內存:

全停頓
我們知道,JavaScript 是單行線語言,運行在主線程上。一旦執行垃圾回收算法,都需要將正在執行的 JavaScript 腳本暫停下來,待垃圾回收完畢后再恢復腳本執行。這種行為叫做全停頓。
主垃圾回收器執行一次完整的垃圾回收流程如下圖所示:
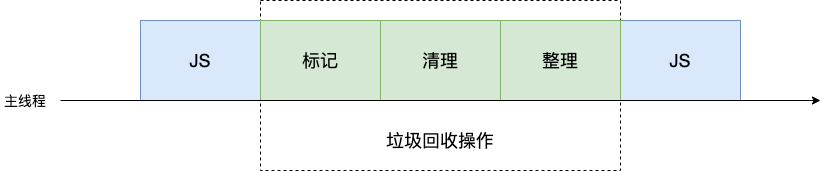
在 V8 新生代的垃圾回收中,因其空間較小,且存活對象較少,所以全停頓的影響不大。但老生代中,如果在執行垃圾回收的過程中,占用主線程時間過久,主線程是不能做其他事情的,需要等待執行完垃圾回收操作才能做其他事情,這將就可能會造成頁面的卡頓現象。
為了降低老生代的垃圾回收而造成的卡頓,V8 將標記過程分為一個個的子標記過程,同時讓垃圾回收標記和 JavaScript 應用邏輯交替進行,直到標記階段完成,這個算法稱為增量標記算法。如下圖所示:
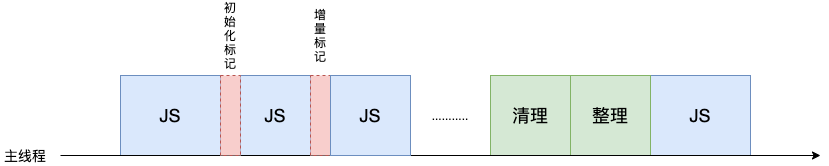
使用增量標記算法可以把一個完整的垃圾回收任務拆分為很多小的任務,這些小的任務執行時間比較短,可以穿插在其他的 JavaScript 任務中間執行,這樣當執行代碼時,就不會讓用戶因為垃圾回收任務而感受到頁面的卡頓了。
(3)減少垃圾回收
雖然瀏覽器可以進行垃圾自動回收,但是當代碼比較復雜時,垃圾回收所帶來的代價較大,所以應該盡量減少垃圾回收:
- 對數組進行優化: 在清空一個數組時,最簡單的方法就是給其賦值為[ ],但是與此同時會創建一個新的空對象,可以將數組的長度設置為0,以此來達到清空數組的目的。
- 對object進行優化: 對象盡量復用,對于不再使用的對象,就將其設置為null,盡快被回收。
- 對函數進行優化: 在循環中的函數表達式,如果可以復用,盡量放在函數的外面。





















