













MySQL分區表詳解
在我們日常處理海量數據的過程中,如何有效管理和優化數據庫一直是一個既重要又具有挑戰性的問題。
分區表技術就為此提供了一種解決方案,尤其是在使用MySQL這類關系型數據庫時。該技術將大型表的數據切割成更易于管理和查詢的小塊,從而提高了整體數據庫操作的性能。
本文將詳細探討MySQL分區表的概念、實現方式以及具體應用場景,幫助讀者更好地理解并運用這一高效的數據庫優化策略。
一、分區表介紹
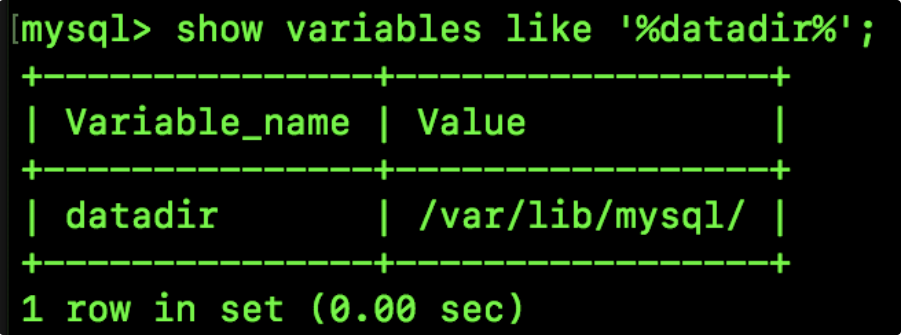
MySQL 數據庫中的數據是以文件的形勢存在磁盤上的,默認放在 /var/lib/mysql/ 目錄下面,我們可以通過 show variables like '%datadir%' 命令來進行查看:
我們進入到這個目錄下,就可以看到我們定義的所有數據庫了,一個數據庫就是一個文件夾,一個庫中,有其對應的表的信息,如下:

在 MySQL 中,如果存儲引擎是 MyISAM,那么在 data 目錄下會看到 3 類文件:.frm、.myi、.myd,文件含義如下:
- *.frm:這個是表定義,是描述表結構的文件。
- *.myd:這個是數據信息文件,是表的數據文件。
- *.myi:這個是索引信息文件。
如果存儲引擎是 InnoDB, 那么在 data 目錄下會看到兩類文件:.frm、.ibd,文件含義如下:
- *.frm:表結構文件。
- *.ibd:表數據和索引的文件。
無論是哪種存儲引擎,只要一張表的數據量過大,就會導致 *.myd、*.myi 以及 *.ibd 文件過大,從而數據的查找就會變的很慢。
為了解決這個問題,我們可以利用 MySQL 的分區功能,在物理上將這一張表對應的文件,分割成許多小塊,如此,當我們查找一條數據時,就不用在某一個文件中進行整個遍歷了,我們只需要知道這條數據位于哪一個數據塊,然后在那一個數據塊上查找就行了。
另一方面,如果一張表的數據量太大,可能一個磁盤放不下,這個時候,通過表分區我們就可以把數據分配到不同的磁盤里面去。
通俗地講表分區就是將一大表,根據條件分割成若干個小表。
如:某用戶表的記錄超過了 600 萬條,那么就可以根據入庫日期將表分區,也可以根據所在地將表分區。當然也可根據其他的條件分區。
MySQL 從 5.1 版本開始添加了對分區的支持,分區的過程是將一個表或索引分解為多個更小、更可管理的部分。
對于開發者而言,分區后的表使用方式和不分區基本上還是一模一樣,只不過在物理存儲上,原本該表只有一個數據文件,現在變成了多個,每個分區都是獨立的對象,可以獨自處理,也可以作為一個更大對象的一部分進行處理。
需要注意的是,分區功能并不是在存儲引擎層完成的,常見的存儲引擎如 InnoDB、MyISAM、NDB 等都支持分區。
但并不是所有的存儲引擎都支持,如 CSV、FEDORATED、MERGE **等就不支持分區,因此在使用此分區功能前,應該對選擇的存儲引擎對分區的支持有所了解。
表分區的優缺點和限制
MySQL 分區有優點也有一些缺點,羅列如下:
優點:
- 查詢性能提升:分區可以將大表劃分為更小的部分,查詢時只需掃描特定的分區,而不是整個表,從而提高查詢性能。特別是在處理大量數據或高并發負載時,分區可以顯著減少查詢的響應時間。
- 管理和維護的簡化:使用分區可以更輕松地管理和維護數據。可以針對特定的分區執行維護操作,如備份、恢復、優化和數據清理,而不必處理整個表。這簡化了維護任務并減少了操作的復雜性。
- 數據管理靈活性:通過分區,可以根據業務需求輕松地添加或刪除分區,而無需影響整個表。這使得數據的增長和變化更具彈性,可以根據需求進行動態調整。
- 改善數據安全性和可用性:可以將不同分區的數據分布在不同的存儲設備上,從而提高數據的安全性和可用性。例如,可以將熱數據放在高速存儲設備上,而將冷數據放在廉價存儲設備上,以實現更高的性能和成本效益。
缺點:
- 復雜性增加:分區引入了額外的復雜性,包括分區策略的選擇、表結構的設計和維護、查詢邏輯的調整等。正確地設置和管理分區需要一定的經驗和專業知識。
- 索引效率下降:對于某些查詢,特別是涉及跨分區的查詢,可能會導致索引效率下降。由于查詢需要在多個分區之間進行掃描,可能無法充分利用索引優勢,從而影響查詢性能。
- 存儲空間需求增加:使用分區會導致一定程度的存儲空間浪費。每個分區都需要占用一定的存儲空間,包括分區元數據和一些額外的開銷。因此,對于分區鍵的選擇和分區粒度的設置需要權衡存儲空間和性能之間的關系。
- 功能限制:在某些情況下,分區可能會限制某些 MySQL 的功能和特性的使用。例如,某些類型的索引可能無法在分區表上使用,或者某些 DDL 操作可能需要更復雜的處理。
- 在考慮使用分區時,需要綜合考慮業務需求、查詢模式、數據規模和硬件資源等因素,并權衡分區帶來的優勢和缺點。對于特定的應用和數據場景,分區可能是一個有效的解決方案,但并不適用于所有情況。
同時分區表也存在一些限制,如下:
- 在 MySQL 5.6.7 之前的版本,一個表最多有 1024 個分區,從 5.6.7 開始,一個表最多可以有 8192 個分區。
- 分區表無法使用外鍵約束。
- NULL 值會使分區過濾無效。
- 所有分區必須使用相同的存儲引擎。
二、分區適用場景
分區表在以下情況可以發揮其優勢,適用于以下幾種使用場景:
- 大型表處理:當面對非常大的表時,分區表可以提高查詢性能。通過將表分割為更小的分區,查詢操作只需要處理特定的分區,從而減少掃描的數據量,提高查詢效率。這在處理日志數據、歷史數據或其他需要大量存儲和高性能查詢的場景中非常有用。
- 時間范圍查詢:對于按時間排序的數據,分區表可以按照時間范圍進行分區,每個分區包含特定時間段內的數據。這使得按時間范圍進行查詢變得更高效,例如在某個時間段內檢索數據、生成報表或執行時間段的聚合操作。
- 數據歸檔和數據保留:分區表可用于數據歸檔和數據保留的需求。舊數據可以歸檔到單獨的分區中,并將其存儲在低成本的存儲介質上。同時,可以保留較新數據在高性能的存儲介質上,以便快速查詢和操作。
- 并行查詢和負載均衡:通過哈希分區或鍵分區,可以將數據均勻地分布在多個分區中,從而實現并行查詢和負載均衡。查詢可以同時在多個分區上進行,并在最終合并結果,提高查詢性能和系統吞吐量。
- 數據刪除和維護:使用分區表,可以更輕松地刪除或清理不再需要的數據。通過刪除整個分區,可以更快速地刪除大量數據,而不會影響整個表的操作。此外,可以針對特定分區執行維護任務,如重新構建索引、備份和優化,以減少對整個表的影響。
分區表并非適用于所有情況。在選擇使用分區表時,需要綜合考慮數據量、查詢模式、存儲資源和硬件能力等因素,并評估分區對性能和管理的影響。
三、分區方式
分區有兩種方式,水平切分和垂直切分,MySQL 數據庫支持的分區類型為水平分區,它不支持垂直分區。
此外,MySQL 數據庫的分區是局部分區索引,一個分區中既存放了數據又存放了索引。而全局分區是指,數據存放在各個分區中,但是所有數據的索引放在一個對象中。目前,MySQL 數據庫還不支持全局分區。
四、分區策略
RANGE 分區
RANGE 分區是 MySQL 中的一種分區策略,根據某一列的范圍值將數據分布到不同的分區。每個分區包含特定的范圍。下面是 RANGE 分區的定義方式、特點以及代碼示例。
定義方式:
- 指定分區鍵:選擇作為分區依據的列作為分區鍵,通常是日期、數值等具有范圍特性的列。
- 分區函數:通過PARTITION BY RANGE指定使用 RANGE 分區策略。
- 定義分區范圍:使用VALUES LESS THAN子句定義每個分區的范圍。
- RANGE 分區的特點:
- 范圍劃分:根據指定列的范圍進行分區,適用于需要按范圍進行查詢和管理的情況。
- 靈活的范圍定義:可以定義任意數量的分區,并且每個分區可以具有不同的范圍。
- 高效查詢:根據查詢條件的范圍,MySQL 能夠快速定位到特定的分區,提高查詢效率。
- 動態管理:可以根據業務需求輕松添加或刪除分區,適應數據增長或變更的需求。
以下是一個使用 RANGE 分區的代碼示例:
CREATE TABLE sales (
id INT,
sales_date DATE,
amount DECIMAL(10, 2)
)
PARTITION BY RANGE (YEAR(sales_date)) (
PARTITION p1 VALUES LESS THAN (2020),
PARTITION p2 VALUES LESS THAN (2021),
PARTITION p3 VALUES LESS THAN (2022),
PARTITION p4 VALUES LESS THAN MAXVALUE
);在上述示例中,我們創建了名為sales的表,使用 RANGE 分區策略。根據sales_date列的年份范圍將數據分布到不同的分區:
- PARTITION BY RANGE (YEAR(sales_date)):指定使用 RANGE 分區,基于sales_date列的年份進行分區。
- PARTITION p1 VALUES LESS THAN (2020):定義名為p1的分區,包含年份小于 2020 的數據。
- PARTITION p2 VALUES LESS THAN (2021):定義名為p2的分區,包含年份小于 2021 的數據。
- PARTITION p3 VALUES LESS THAN (2022):定義名為p3的分區,包含年份小于 2022 的數據。
- PARTITION p4 VALUES LESS THAN MAXVALUE:定義名為p4的分區,包含超出定義范圍的數據。
RANGE 分區允許根據列值的范圍將數據分散到不同的分區中,適用于按范圍進行查詢和管理的情況。它提供了更靈活的數據管理和查詢效率的提升。
LIST 分區
LIST 分區是根據某一列的離散值將數據分布到不同的分區。每個分區包含特定的列值列表。下面是 LIST 分區的定義方式、特點以及代碼示例。
定義方式:
- 指定分區鍵:選擇作為分區依據的列作為分區鍵,通常是具有離散值的列,如地區、類別等。
- 分區函數:通過PARTITION BY LIST指定使用 LIST 分區策略。
- 定義分區列表:使用VALUES IN子句定義每個分區包含的列值列表。
LIST 分區的特點:
- 列值離散:根據指定列的具體取值進行分區,適用于具有離散值的列。
- 靈活的分區定義:可以定義任意數量的分區,并且每個分區可以具有不同的列值列表。
- 高效查詢:根據查詢條件的列值直接定位到特定分區,提高查詢效率。
- 動態管理:可以根據業務需求輕松添加或刪除分區,適應數據增長或變更的需求。
以下是一個使用 LIST 分區的代碼示例:
CREATE TABLE users (
id INT,
username VARCHAR(50),
region VARCHAR(50)
)
PARTITION BY LIST (region) (
PARTITION p_east VALUES IN ('New York', 'Boston'),
PARTITION p_west VALUES IN ('Los Angeles', 'San Francisco'),
PARTITION p_other VALUES IN (DEFAULT)
);在上述示例中,我們創建了名為users的表,使用 LIST 分區策略。根據region列的具體取值將數據分布到不同的分區:
- PARTITION BY LIST (region):指定使用 LIST 分區,基于region列的值進行分區。
- PARTITION p_east VALUES IN ('New York', 'Boston'):定義名為p_east的分區,包含值為'New York'和'Boston'的region列的數據。
- PARTITION p_west VALUES IN ('Los Angeles', 'San Francisco'):定義名為p_west的分區,包含值為'Los Angeles'和'San Francisco'的region列的數據。
- PARTITION p_other VALUES IN (DEFAULT):定義名為p_other的分區,包含其他region列值的數據。
HASH 分區
HASH 分區是使用哈希算法將數據均勻地分布到多個分區中。下面是 HASH 分區的定義方式、特點以及代碼示例。
定義方式:
- 指定分區鍵:選擇作為分區依據的列作為分區鍵。
- 分區函數:通過PARTITION BY HASH指定使用 HASH 分區策略。
- 定義分區數量:使用PARTITIONS關鍵字指定分區的數量。
HASH 分區的特點:
- 數據均勻分布:HASH 分區使用哈希算法將數據均勻地分布到不同的分區中,確保數據在各個分區之間平衡。
- 并行查詢性能:通過將數據分散到多個分區,HASH 分區可以提高并行查詢的性能,多個查詢可以同時在不同分區上執行。
- 簡化管理:HASH 分區使得數據管理更加靈活,可以輕松地添加或刪除分區,以適應數據增長或變更的需求。
以下是一個使用 HASH 分區的代碼示例:
CREATE TABLE sensor_data (
id INT,
sensor_name VARCHAR(50),
value INT
)
PARTITION BY HASH (id) PARTITIONS 4;在上述示例中,我們創建了名為sensor_data的表,使用 HASH 分區策略。根據id列的哈希值將數據分布到 4 個分區中:
- PARTITION BY HASH (id):指定使用 HASH 分區,基于id列的哈希值進行分區。
- PARTITIONS 4:指定創建 4 個分區。
KEY 分區
KEY 分區是根據某一列的哈希值將數據分布到不同的分區。不同于 HASH 分區,KEY 分區使用的是列值的哈希值而不是哈希函數。下面是 KEY 分區的定義方式、特點以及代碼示例。
定義方式:
- 指定分區鍵:選擇作為分區依據的列作為分區鍵。
- 分區函數:通過PARTITION BY KEY指定使用 KEY 分區策略。
- 定義分區數量:使用PARTITIONS關鍵字指定分區的數量。
KEY 分區的特點:
- 哈希分布:KEY 分區使用列值的哈希值將數據分布到不同的分區中,與哈希函數不同,它使用的是列值的哈希值。
- 高度自定義:KEY 分區允許根據業務需求自定義分區邏輯,可以靈活地選擇分區鍵和分區數量。
- 并行查詢性能:通過將數據分散到多個分區,KEY 分區可以提高并行查詢的性能,多個查詢可以同時在不同分區上執行。
- 簡化管理:KEY 分區使得數據管理更加靈活,可以輕松地添加或刪除分區,以適應數據增長或變更的需求。
以下是一個使用 KEY 分區的代碼示例:
CREATE TABLE orders (
order_id INT,
customer_id INT,
order_date DATE
)
PARTITION BY KEY (customer_id) PARTITIONS 5;在上述示例中,我們創建了名為orders的表,使用 KEY 分區策略。根據customer_id列的哈希值將數據分布到 5 個分區中:
- PARTITION BY KEY (customer_id):指定使用 KEY 分區,基于customer_id列的哈希值進行分區。
- PARTITIONS 5:指定創建 5 個分區。
COLUMNS 分區
MySQL 在 5.5 版本引入了 COLUMNS 分區類型,其中包括 RANGE COLUMNS 分區和 LIST COLUMNS 分區。以下是對這兩種 COLUMNS 分區的詳細說明:
RANGE COLUMNS 分區:RANGE COLUMNS 分區是根據列的范圍值將數據分布到不同的分區的分區策略。它類似于 RANGE 分區,但是根據多個列的范圍值進行分區,而不是只根據一個列。這使得范圍的定義更加靈活,可以基于多個列的組合來進行分區。
下面是一個 RANGE COLUMNS 分區的代碼示例:
CREATE TABLE sales (
id INT,
sales_date DATE,
region VARCHAR(50),
amount DECIMAL(10, 2)
)
PARTITION BY RANGE COLUMNS (region, sales_date) (
PARTITION p1 VALUES LESS THAN ('East', '2022-01-01'),
PARTITION p2 VALUES LESS THAN ('West', '2022-01-01'),
PARTITION p3 VALUES LESS THAN ('East', MAXVALUE),
PARTITION p4 VALUES LESS THAN ('West', MAXVALUE)
);在上述示例中,我們創建了一個名為 sales 的表,并使用 RANGE COLUMNS 分區策略。根據 region 和 sales_date 兩列的范圍將數據分布到不同的分區。每個分區根據這兩列的范圍值進行劃分。
LIST COLUMNS 分區:LIST COLUMNS 分區是根據列的離散值將數據分布到不同的分區的分區策略。它類似于 LIST 分區,但是根據多個列的離散值進行分區,而不是只根據一個列。這使得離散值的定義更加靈活,可以基于多個列的組合來進行分區。
下面是一個 LIST COLUMNS 分區的代碼示例:
CREATE TABLE users (
id INT,
username VARCHAR(50),
region VARCHAR(50),
category VARCHAR(50)
)
PARTITION BY LIST COLUMNS (region, category) (
PARTITION p_east VALUES IN (('New York', 'A'), ('Boston', 'B')),
PARTITION p_west VALUES IN (('Los Angeles', 'C'), ('San Francisco', 'D')),
PARTITION p_other VALUES IN (DEFAULT)
);在上述示例中,我們創建了一個名為 users 的表,并使用 LIST COLUMNS 分區策略。根據 region 和 category 兩列的離散值將數據分布到不同的分區。每個分區根據這兩列的離散值進行劃分。
五、常見分區命令
是否支持分區
在 MySQL5.6.1 之前可以通過命令 show variables like '%have_partitioning%' 來查看 MySQL 是否支持分區。如果 have_partitioning 的值為 YES,則表示支持分區。
從 MySQL5.6.1 開始,have_partitioning 參數已經被去掉了,而是用 SHOW PLUGINS 來代替。若有 partition 行且 STATUS 列的值為 ACTIVE,則表示支持分區,如下所示:

創建分區表
CREATE TABLE sales (
id INT,
sales_date DATE,
amount DECIMAL(10, 2)
)
PARTITION BY RANGE (YEAR(sales_date)) (
PARTITION p1 VALUES LESS THAN (2020),
PARTITION p2 VALUES LESS THAN (2021),
PARTITION p3 VALUES LESS THAN (2022),
PARTITION p4 VALUES LESS THAN MAXVALUE
);向分區表添加新的分區
ALTER TABLE sales
ADD PARTITION (PARTITION p5 VALUES LESS THAN (2023));刪除指定的分區
ALTER TABLE sales DROP PARTITION p3;重新組織分區
ALTER TABLE sales
REORGANIZE p1, p2, p5 INTO (PARTITION p1 VALUES LESS THAN (2020), PARTITION p2 VALUES LESS THAN (2022), PARTITION p3 VALUES LESS THAN MAXVALUE);合并相鄰的分區
ALTER TABLE sales COALESCE PARTITION p1, p2;分析指定分區的統計信息
ALTER TABLE sales ANALYZE PARTITION p1;:總的來說,MySQL分區表在數據管理和查詢性能上提供了顯著的優勢。它可以幫助我們處理大規模數據,提高查詢速度,并改善系統性能。
然而,合理地、有效地實施分區策略也需要對業務需求和數據特性有深刻理解。雖然分區表的使用在許多場景下都是有益的,但仍需要注意其適用性及可能存在的限制。無論如何,掌握和使用MySQL分區表無疑是每個數據庫管理員和開發人員工具箱中的一個重要工具。












