Ceph 中的寫入放大
介紹
 圖片
圖片
Ceph 是一個開源的分布式存儲系統,設計初衷是提供較好的性能、可靠性和可擴展性。 Ceph 獨一無二地在一個統一的系統中同時提供了對象、塊、和文件存儲功能。 Ceph 消除了對系統單一中心節點的依賴,實現了無中心結構的設計思想。
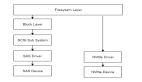
我們知道Ceph為了保障數據的可靠性,存放數據通常是三副本策略(另有EC策略)。那么無論是data,metadata,journal都是三份。因此在應用端寫入一個IO,在ceph內部實際上會額外產生許多內部IO,不同的存儲后端差異很大。 Ceph提供了FileStore、KStore和BlueStore三種存儲后端以供選擇,那么以FileStore為例,來看看13X的寫放大的來由。FileStore中ceph的數據被存放在XFS或者ZFS等本地文件系統中。這些文件系統本身又會記錄日志(FS journal),以及還有它自己的元數據(FS metadata)。
在設計存儲基礎結構時,為了防止故障,保證一定的冗余度是非常有必要的。但是,冗余伴隨著存儲效率的降低,這也會增加您的成本。對于大型基礎設施,每 TB 成本的差異可能會導致總存儲成本顯著提高。因此,Ceph 中的糾刪碼非常有吸引力。 糾刪碼類似于基于奇偶校驗的 RAID 陣列。為每個對象創建許多數據塊 (K) 和奇偶校驗塊 (M)。另一方面,副本只是創建給定對象的其他副本,類似于鏡像 RAID 陣列。這通常意味著糾刪碼比副本具有更高的存儲效率,計算公式為 k/(k+m)。 例如,以 6+2 為例,您將獲得 75% 的存儲效率——在記錄的總 8 個區塊中,有 6 個數據塊。與三個副本相比,您將有 33% 的效率,總共 3 個記錄的塊中有 1 個數據塊。
寫入放大
正常來說,Ceph 都沒啥問題,除了一個經常被忽視的問題:寫入放大。 數據存儲中的最小分配大小本質上是一段數據可以寫入的最小單位。在 Pacific Ceph 之前,此值默認為 64kb。此最小分配單元會給某些工作負載帶來問題,尤其是那些對小文件進行操作的工作負載。
案例
4% 存儲效率示例如下圖:
 圖片
圖片
為了更直觀一點,讓我們考慮一個傳入寫入為 16kb 的 4+2 糾刪碼池。 在上面的示例中,單個 16K 寫入最終會放大 24 倍的大小,因為每個塊至少需要以 64K 的速度寫入磁盤。這導致此特定對象的總存儲效率為 ~4%。如果您的工作負載主要由 16K 對象組成,那么這可能會很快抵消您的 EC 配置文件提供的任何優勢。下面是使用相同文件大小的 3 副本示例。
 圖片
圖片
如上圖所示,在此特定工作負載中,3 Replica 實際上比 4+2 糾刪碼池的存儲效率更高。這表明規則總是有例外。從理論上講,當存儲效率是最高優先級時,應使用糾刪碼,但根據您的數據集,這可能會發生巨大變化。
寫入放大重要的用例
當然,即使按照小文件工作負載標準,16K 文件也很小,單單一篇文章的大小就 100K 左右。另外,一些可能存在寫入放大問題的場景是:
- AI training 人工智能訓練
- audio editing 音頻編輯
- log storing/aggregation 日志存儲/聚合
- scientific computing 科學計算
結論
了解數據和工作負載是確定 Ceph 集群構建的關鍵部分。了解整個數據的平均文件大小將使您能夠避免這種極高的寫入放大。 當然,這并不總是這樣的。通常,在單個集群中往往會存在各種大小的文件。在這種情況下,只需確定數據的位置即可。例如,如果單個目錄樹擁有大部分小文件,則可以將副本池固定到該特定樹,而具有較大文件大小的其余數據仍保留在糾刪碼上。 如前所述,當您的最小分配大小太大時,寫入放大會更加普遍,這就是為什么較新版本的 Ceph(如 Pacific 和 Quincy)默認為 4K 而不是 64K 的原因。在較新的集群或最小分配大小修改的 Octopus 集群中,寫入放大的問題要小得多,因此,我們在后續的集群部署前,需要認真考慮一下。