12個(gè)完全免費(fèi)的OCR開(kāi)源項(xiàng)目
大家好,我是Echa。
今天小編給大家介紹一個(gè)跟生活息息相關(guān)的而且經(jīng)常使用的好東西。物理世界和數(shù)字世界的信息轉(zhuǎn)換是數(shù)字化發(fā)展的一個(gè)技術(shù)內(nèi)容。
專業(yè)術(shù)語(yǔ)叫:光學(xué)字符識(shí)別——OCR(Optical Character Recognition)。
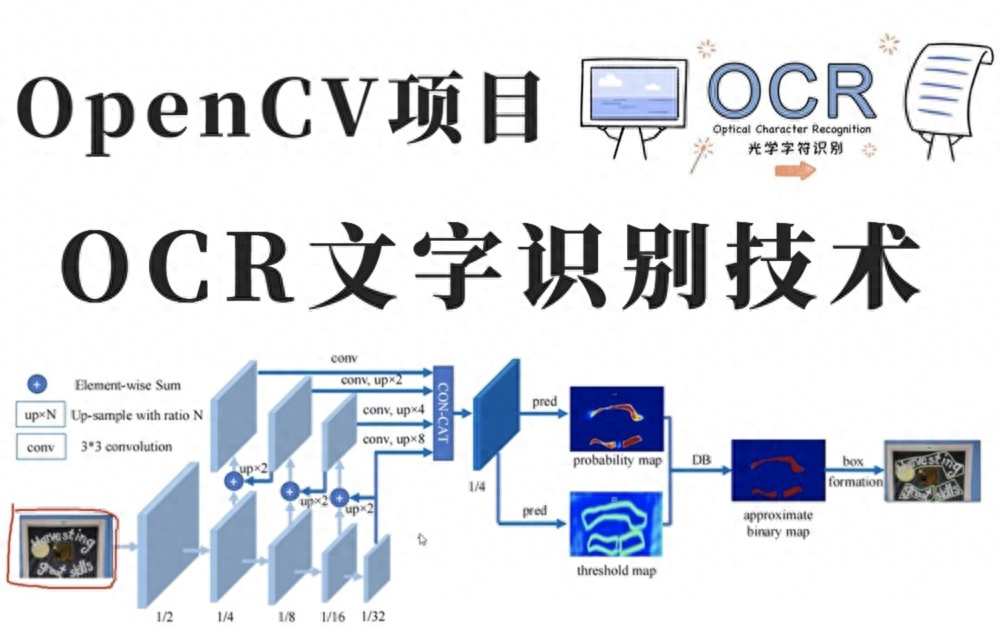 基于目標(biāo)檢測(cè)類的OCR識(shí)別技術(shù)
基于目標(biāo)檢測(cè)類的OCR識(shí)別技術(shù)
OCR是指對(duì)文本資料的圖像文件進(jìn)行分析識(shí)別處理,獲取文字及版面信息的過(guò)程。亦即將圖像中的文字進(jìn)行識(shí)別,并以文本的形式返回。這樣描述估計(jì)還是一頭霧水,下面直接說(shuō)應(yīng)用場(chǎng)景就會(huì)更清晰明了。
OCR應(yīng)用場(chǎng)景如下:
卡片證件識(shí)別類:大陸、港澳臺(tái)身份證、通行證、護(hù)照識(shí)別,卡類識(shí)別,車輛類駕駛證識(shí)別、行駛證識(shí)別,執(zhí)照識(shí)類識(shí)別,企業(yè)證件類識(shí)別
文字信息結(jié)構(gòu)化視頻類識(shí)別:字幕識(shí)別和文字檢測(cè),表格;
票據(jù)類識(shí)別:增值稅發(fā)票識(shí)別、全電發(fā)票識(shí)別、銀行支票識(shí)別、承兌匯票識(shí)別、銀行票據(jù)識(shí)別、物流快遞識(shí)別;
其他識(shí)別:二維碼識(shí)別、一維碼識(shí)別、車牌識(shí)別、數(shù)學(xué)公式識(shí)別、物理化學(xué)符號(hào)識(shí)別、音樂(lè)符號(hào)識(shí)別、工程圖識(shí)別、流程圖識(shí)別、古跡文獻(xiàn)識(shí)別、手寫(xiě)輸入識(shí)別;
除了以上列舉的之外,還有自然場(chǎng)景下的文字識(shí)別、菜單識(shí)別、橫幅檢測(cè)識(shí)別、圖章檢測(cè)識(shí)別、廣告類圖文識(shí)別等圍繞審核相關(guān)的業(yè)務(wù)應(yīng)用。
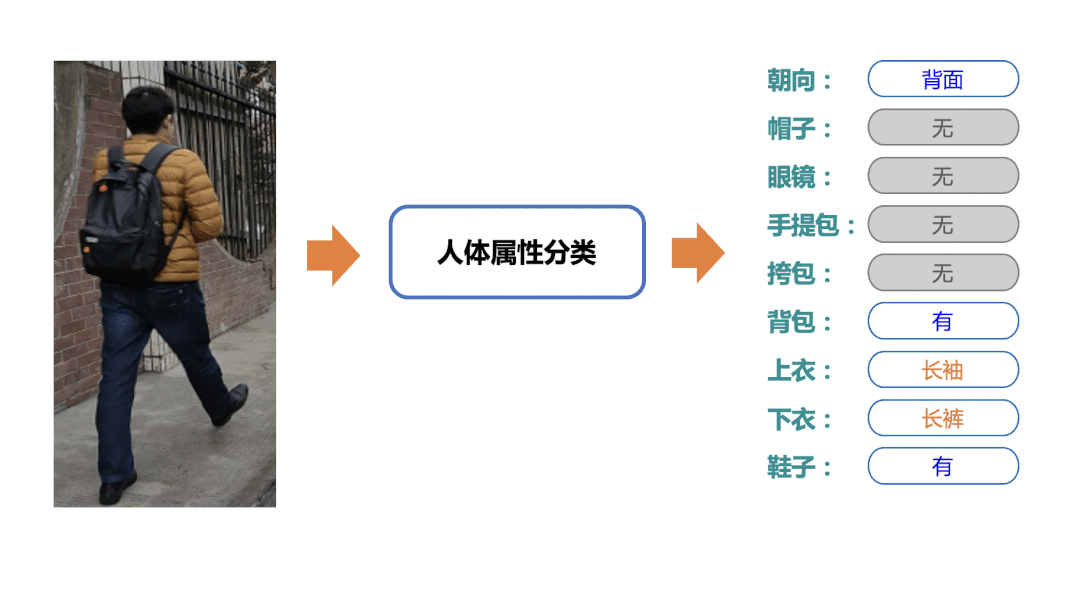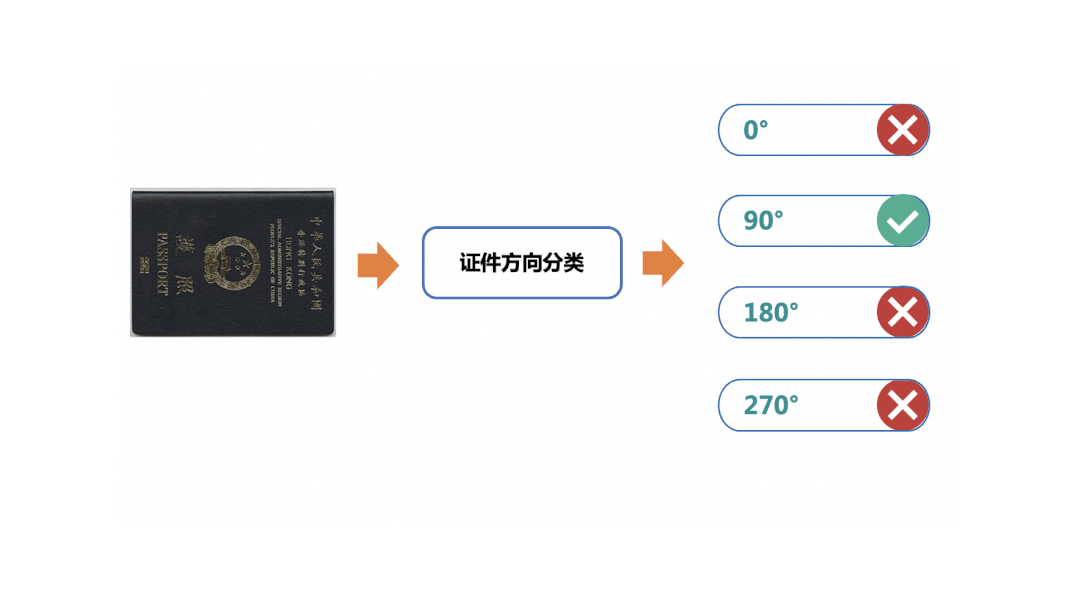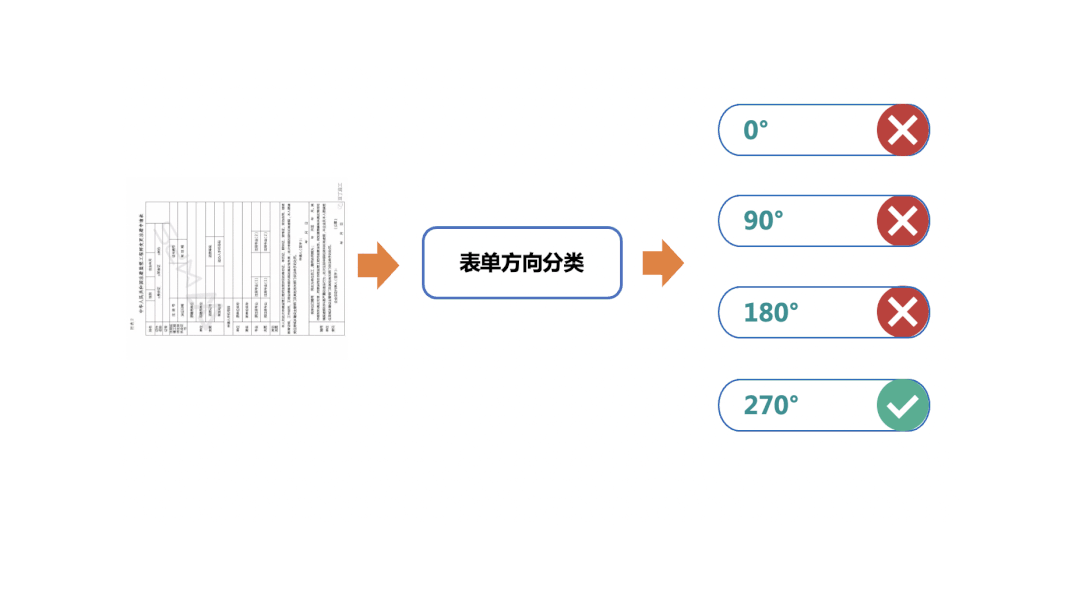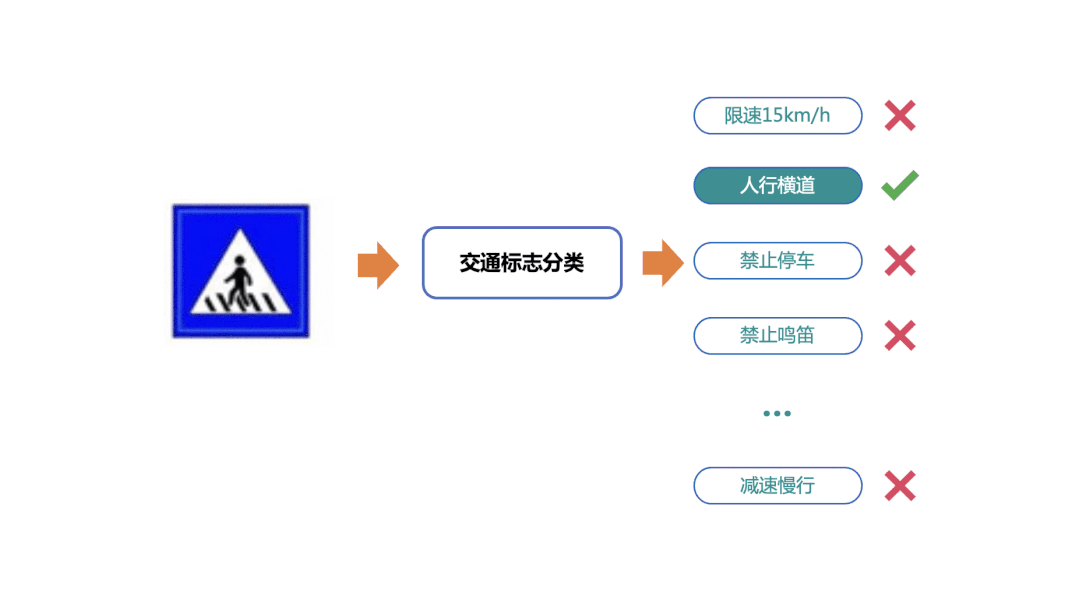 簡(jiǎn)單的OCR應(yīng)用場(chǎng)景
簡(jiǎn)單的OCR應(yīng)用場(chǎng)景
隨著科技的發(fā)展,OCR場(chǎng)景隨處可見(jiàn)。人臉、車輛、人體屬性、卡證、交通標(biāo)識(shí)等經(jīng)典圖像識(shí)別能力,在我們當(dāng)前數(shù)字化工作及生活中發(fā)揮著極其重要的作用。業(yè)內(nèi)也不乏頂尖公司提供的可直接調(diào)用的API、SDK,但這些往往面臨著定制化場(chǎng)景泛化效果不好、價(jià)格昂貴、黑盒可控性低、技術(shù)壁壘難以形成多諸多痛點(diǎn)。
 9大場(chǎng)景模型效果示意圖
9大場(chǎng)景模型效果示意圖
而今天小編要給大家好物分享12個(gè)完全開(kāi)源免費(fèi)的OCR開(kāi)源項(xiàng)目、覆蓋人、車、OCR等9大經(jīng)典識(shí)別場(chǎng)景、在CPU上可3毫秒實(shí)現(xiàn)急速識(shí)別、一行代碼就可實(shí)現(xiàn)迭代訓(xùn)練的項(xiàng)目!希望對(duì)大家有所幫助。可以借助一些主流開(kāi)源框架來(lái)快速應(yīng)用項(xiàng)目中,達(dá)到我們的目的。
全文大綱
- Tesseract.js - 是一個(gè)基于TesseractOCR的Web瀏覽器OCR軟件。
- OCRopus - 是由Google開(kāi)發(fā)的OCR相關(guān)工具集合。
- Tesseract OCR - 是一個(gè)非常經(jīng)典的開(kāi)源OCR引擎。
- Ocrad - 一個(gè)輕量級(jí)的OCR解決方案,主要以識(shí)別印刷文本而聞名。
- GOCR- 是在GNU通用公共許可證下開(kāi)發(fā)的開(kāi)源OCR引擎。
- Ocrad.js - 是一個(gè)基于Ocrad的瀏覽器的OCR軟件。
- Capture2Text- 是一個(gè)基于命令行的Windows OCR軟件。
- GImage Reader- 它能夠識(shí)別多種語(yǔ)言以及各種圖像文件格式的文本。
- OCRmyPDF-是一個(gè)專門用于PDF的OCR識(shí)別軟件。
- PaddleClas - 是飛槳為工業(yè)界和學(xué)術(shù)界所準(zhǔn)備的一個(gè)圖像識(shí)別和圖像分類任務(wù)的工具集。
- kraken - 一個(gè)由Python開(kāi)發(fā)的OCR軟件,主要用于非拉丁字符的識(shí)別。
- EasyOCR- 基于機(jī)器學(xué)習(xí)(CRNN)實(shí)現(xiàn)OCR功能。
Tesseract.js - 是一個(gè)基于TesseractOCR的Web瀏覽器OCR軟件。
Github:https://github.com/naptha/tesseract.js#tesseractjs
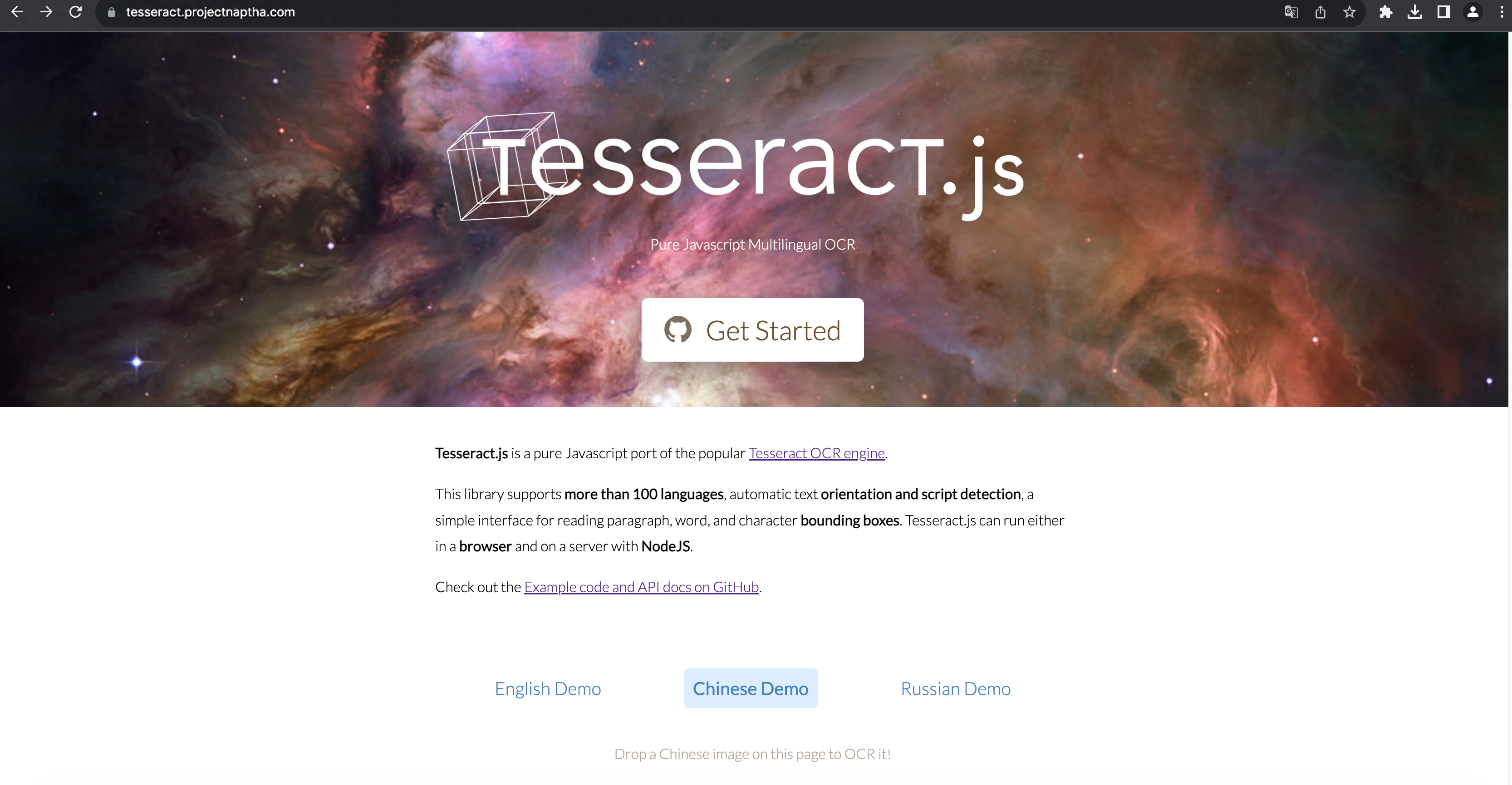 Tesseract.js 官網(wǎng)
Tesseract.js 官網(wǎng)
Tesseract.js是一個(gè)基于TesseractOCR的Web瀏覽器OCR軟件。你可以在瀏覽器中使用它,并且非常易用。與Tesseract OCR一樣,它也支持多種語(yǔ)言,包括中文。
Tesseract.js 網(wǎng)站上所說(shuō),它支持 100 多種語(yǔ)言,自動(dòng)文本定位和腳本檢測(cè),用于閱讀段落、單詞和字符邊界框的簡(jiǎn)單界面。
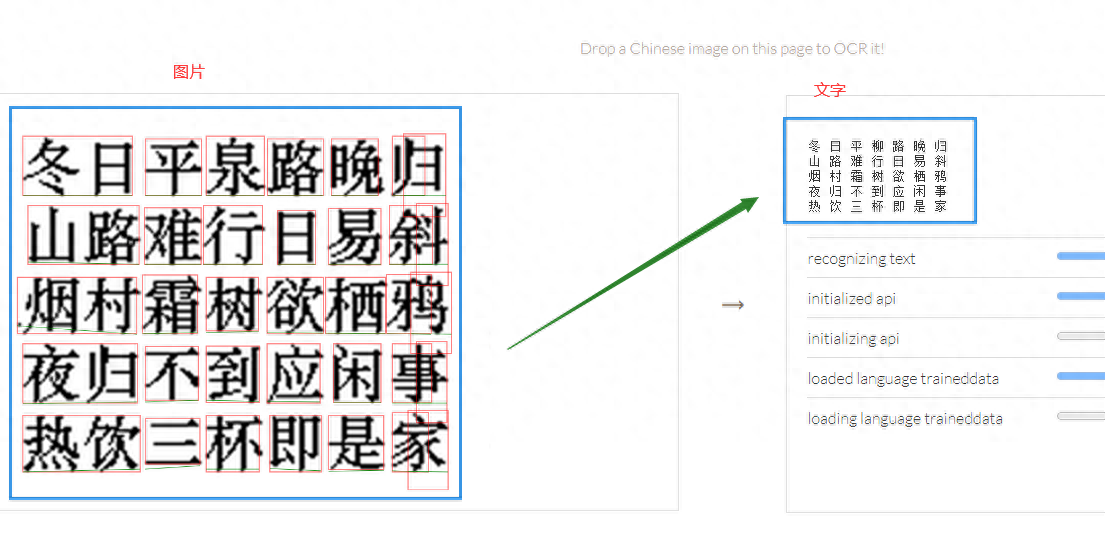
Tesseract.js 演示截圖
 Tesseract.js 案例演示
Tesseract.js 案例演示
OCRopus - 是由Google開(kāi)發(fā)的OCR相關(guān)工具集合。
Github:https://github.com/ocropus
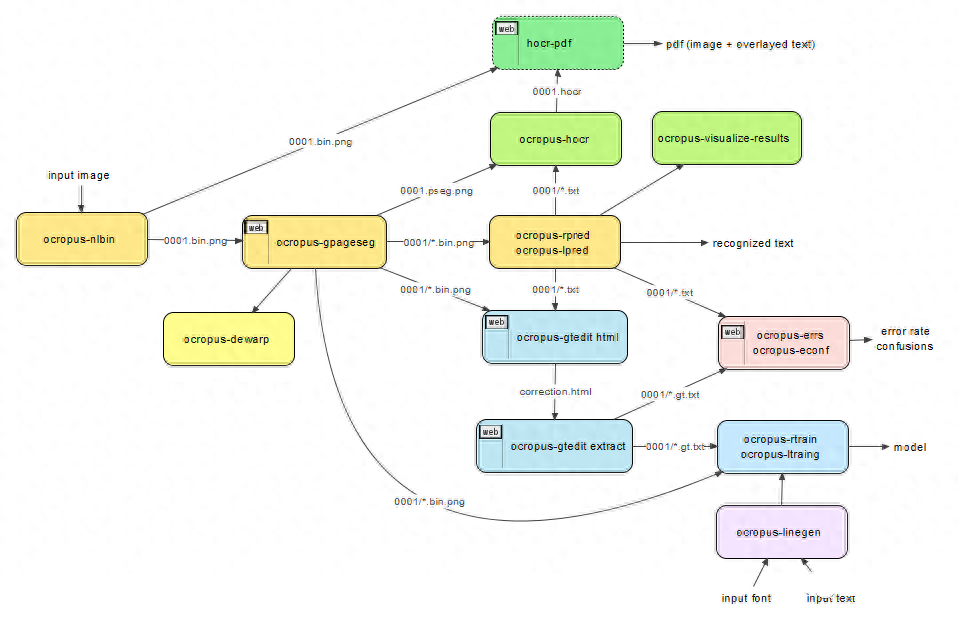
OCRopus是由Google開(kāi)發(fā)的OCR相關(guān)工具集合,它擴(kuò)展了Tesseract OCR引擎的功能。它提供了布局分析、文本識(shí)別和樣本數(shù)據(jù)生成的高級(jí)功能。
另外,OCRopus可以從命令行通過(guò)指定輸入的圖像來(lái)執(zhí)行它。它會(huì)將識(shí)別的文本直接輸出到標(biāo)準(zhǔn)輸出,或者將其作為hOCR(基于HTML)代碼寫(xiě)入文件,然后可以將其轉(zhuǎn)換為可搜索的PDF。如果需要更精確的控制,可以在命令行上指定選項(xiàng)來(lái)執(zhí)行特定操作。
優(yōu)勢(shì):
- 布局分析:OCRopus在布局分析方面非常精確,使其成為具有復(fù)雜布局或多列結(jié)構(gòu)文檔識(shí)別的理想選擇。
- 文本識(shí)別準(zhǔn)確性:OCRopus通過(guò)利用Tesseract的精確OCR引擎和其他組件,能夠提高識(shí)別的準(zhǔn)確性。
- 可定制性:OCRopus能夠生成用于訓(xùn)練的樣本數(shù)據(jù),用于訓(xùn)練自定義的OCR模型,從而在專業(yè)應(yīng)用中實(shí)現(xiàn)更高可定制性和準(zhǔn)確性。
缺點(diǎn)
- 學(xué)習(xí)曲線:與獨(dú)立的OCR引擎相比,OCRopus由于其工具和組件的范圍比較廣,因此具有更陡峭的學(xué)習(xí)曲線。
- 資源密集型:OCRopus的高級(jí)功能可能需要更多的計(jì)算資源,這個(gè)可能需要較高的成本,并且也需要考慮項(xiàng)目對(duì)處理時(shí)間的要求。
Tesseract OCR - 是一個(gè)非常經(jīng)典的開(kāi)源OCR引擎。
Github:https://github.com/tesseract-ocr/tesseract
 Tesseract OCR Github 官網(wǎng)
Tesseract OCR Github 官網(wǎng)
Tesseract是一個(gè)非常經(jīng)典的開(kāi)源OCR引擎,最初由Hewlett-Packard開(kāi)發(fā),現(xiàn)在由Google維護(hù)。Tesseract以其準(zhǔn)確性和多功能性而聞名,可以提取數(shù)據(jù)并將掃描的文檔、圖像和手寫(xiě)文字轉(zhuǎn)換為機(jī)器理解的文本。Tesseract支持100多種語(yǔ)言,并兼容多種操作系統(tǒng),并且提供了非常方便的命令行界面。
優(yōu)勢(shì):
- 準(zhǔn)確性:Tesseract提供了非常高OCR準(zhǔn)確性,特別是在打印文本和掃描文檔方面。
- 語(yǔ)言支持:Tesseract支持廣泛的語(yǔ)言,允許識(shí)別多種語(yǔ)言的文本,包括一些特殊語(yǔ)種,使其成為多語(yǔ)言應(yīng)用的理想選擇。
- 持續(xù)改進(jìn):Tesseract的開(kāi)源社區(qū)非常活躍,能夠及時(shí)地更新升級(jí)項(xiàng)目、修復(fù)Bug、完善用戶反饋的性能需求等。
缺點(diǎn):
- 復(fù)雜布局文檔識(shí)別:Tesseract在簡(jiǎn)單布局的文檔上表現(xiàn)非常好,但在布局比較復(fù)雜的文檔上就需要額外的預(yù)處理或后續(xù)處理步驟。
- 手寫(xiě)識(shí)別準(zhǔn)確度:Tesseract在識(shí)別機(jī)器打印文本方面表現(xiàn)出色,但在手寫(xiě)文本上的表現(xiàn)并不盡如人意,有時(shí)還不如一些專用手寫(xiě)識(shí)別工具準(zhǔn)確。
Ocrad - 一個(gè)輕量級(jí)的OCR解決方案,主要以識(shí)別印刷文本而聞名。
傳送門:https://www.gnu.org/software/ocrad/
 Ocrad 官網(wǎng)
Ocrad 官網(wǎng)
Ocrad以其簡(jiǎn)單性和識(shí)別速度而聞名,它提供了一個(gè)輕量級(jí)的OCR解決方案,主要以識(shí)別印刷文本而聞名。它旨在提供一個(gè)簡(jiǎn)單高效的OCR解決方案,側(cè)重文本識(shí)別提取的速度和易用性。
優(yōu)勢(shì)
- 易用性和識(shí)別效率:Ocrad簡(jiǎn)單的設(shè)計(jì)和輕量級(jí)的特性有助于其易用性和識(shí)別效率。特別適合用于快速和簡(jiǎn)單的OCR解決方案需求。
- 打印文本識(shí)別:Ocrad擅長(zhǎng)從掃描圖像中識(shí)別打印文本,可以從清晰且格式良好的打印文檔中識(shí)別提取出可靠的結(jié)果。
缺點(diǎn)
- 缺乏高級(jí)功能:Ocrad的側(cè)重點(diǎn)在于基礎(chǔ)的OCR任務(wù),它可能缺乏高級(jí)功能,例如布局分析或手寫(xiě)識(shí)別等。
- 復(fù)雜文本和低質(zhì)量圖像的準(zhǔn)確性:在處理復(fù)雜的文本結(jié)構(gòu)或低質(zhì)量的掃描圖像時(shí),Ocrad的準(zhǔn)確性可能會(huì)降低。
GOCR- 是在GNU通用公共許可證下開(kāi)發(fā)的開(kāi)源OCR引擎。
傳送門:https://jocr.sourceforge.net/
 GOCR 官網(wǎng)
GOCR 官網(wǎng)
GOCR是在GNU通用公共許可證下開(kāi)發(fā)的開(kāi)源OCR引擎。它能夠識(shí)別各種圖像文件格式中的文本內(nèi)容,并支持多種語(yǔ)言和操作平臺(tái)。
雖然它的準(zhǔn)確性可能無(wú)法超過(guò)其他OCR引擎,但GOCR的優(yōu)勢(shì)是非常簡(jiǎn)單易用。
優(yōu)勢(shì)
- 簡(jiǎn)單性:GOCR的主要優(yōu)勢(shì)在于它的簡(jiǎn)單性。該軟件提供了一個(gè)簡(jiǎn)單易用的界面,適合那些喜歡簡(jiǎn)單OCR解決方案而不需要大量配置或復(fù)雜設(shè)置的用戶。
- 多語(yǔ)言支持:GOCR支持多種語(yǔ)言,允許用戶從包含不同語(yǔ)言內(nèi)容的圖像中提取文本。
缺點(diǎn)
- 準(zhǔn)確性:雖然GOCR提供了基本的OCR功能,但其準(zhǔn)確性可能無(wú)法與其他更高級(jí)的OCR引擎相媲美。
- 高級(jí)功能:GOCR專注于簡(jiǎn)單的OCR任務(wù),可能缺乏布局分析或?qū)I(yè)識(shí)別算法等高級(jí)功能。因此,如果您需要高級(jí)功能,這個(gè)工具并不是很適合。
Ocrad.js - 是一個(gè)基于Ocrad的瀏覽器的OCR軟件。
傳送門:https://antimatter15.com/ocrad.js/demo.html
 Ocrad.js 官網(wǎng)
Ocrad.js 官網(wǎng)
Ocrad.js是一個(gè)基于Ocrad的瀏覽器的OCR軟件。在JavaScript中使用它。支持的圖像格式包括JPEG、PNG、GIF、BMP、SVG、NetBPM等。
它非常簡(jiǎn)單易用,只需要通過(guò)調(diào)用OCRAD的函數(shù)即可實(shí)現(xiàn)對(duì)img標(biāo)簽的識(shí)別。雖然在識(shí)別精度方面比Tesseract.js遜色,但Ocard的優(yōu)勢(shì)是它的模型文件比Tesseract小30倍以上。
Capture2Text- 是一個(gè)基于命令行的Windows OCR軟件。
傳送門:https://capture2text.sourceforge.net/
 Capture2Text 官網(wǎng)
Capture2Text 官網(wǎng)
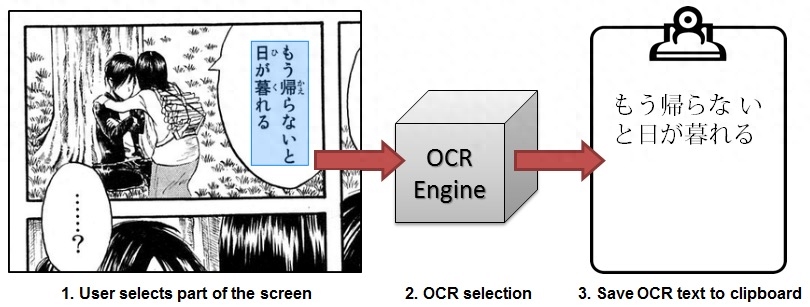
Capture2Text是一個(gè)基于命令行的Windows OCR軟件。它支持多種語(yǔ)言,包括日語(yǔ)。它不僅能識(shí)別水平的字符,還能識(shí)別垂直的字符。可以在你需要的時(shí)候使用windows命令行調(diào)用OCR命令,識(shí)別出的文本將被保存進(jìn)剪貼板。
GImage Reader- 它能夠識(shí)別多種語(yǔ)言以及各種圖像文件格式的文本。
Github:https://github.com/manisandro/gImageReader
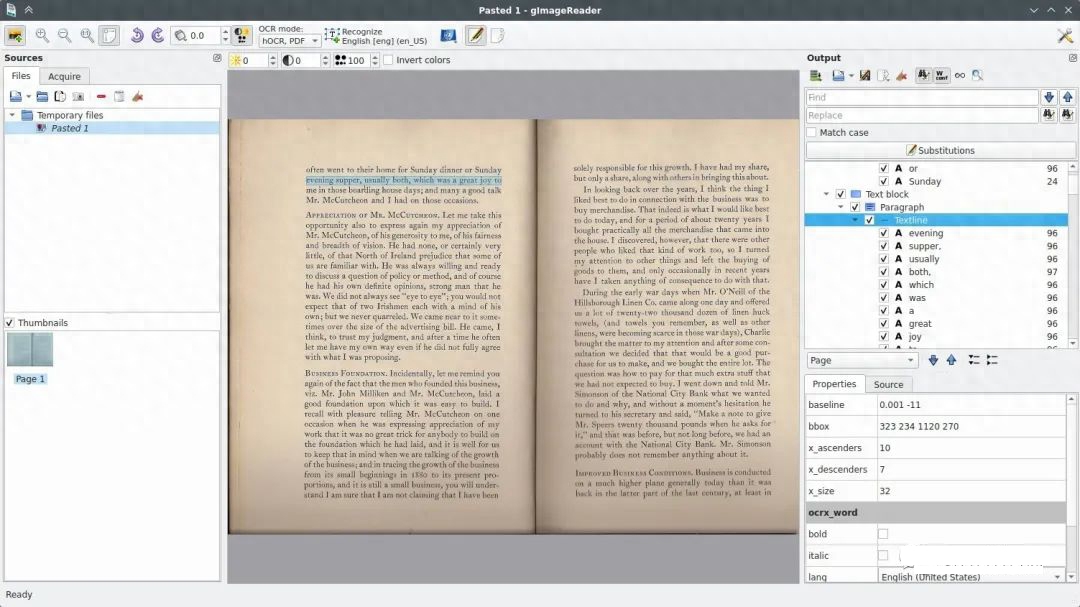
 GImage Reader 官網(wǎng)
GImage Reader 官網(wǎng)
GImage Reader工具它能夠識(shí)別多種語(yǔ)言以及各種圖像文件格式的文本,使其適合從掃描的文檔、屏幕截圖或者照片中提取文本;并且它提供了一個(gè)簡(jiǎn)單直觀的用戶界面,允許您快速加載圖像并獲得文本結(jié)果。
優(yōu)勢(shì)
- 友好的用戶界面:GImage Reader的界面非常直觀易用,用戶可以輕松訪問(wèn),能夠輕松加載圖像并獲取結(jié)果。
- 多語(yǔ)言支持:GImage Reader支持多種語(yǔ)言,允許您從包含不同語(yǔ)言內(nèi)容的圖像中提取文本。
缺點(diǎn)
- 缺乏高級(jí)功能:GImage Reader主要專注于比較基本的OCR任務(wù),如果需要更加專業(yè)的內(nèi)容識(shí)別,它就不適合了。
- 準(zhǔn)確度和性能:雖然GImage Reader可用于基本的OCR任務(wù),但其準(zhǔn)確性和性能可能會(huì)受到圖像質(zhì)量和文本復(fù)雜性的影響。
OCRmyPDF-是一個(gè)專門用于PDF的OCR識(shí)別軟件。
Github:https://github.com/ocrmypdf/OCRmyPDF
") OCRmyPDF 官網(wǎng)
OCRmyPDF 官網(wǎng)
OCRmyPDF是一個(gè)專門用于PDF的OCR識(shí)別軟件,它能夠?qū)⒆R(shí)別到的文本信息作為透明的文本添加到PDF中。因此,您可以在PDF中搜索文本。
如果您將其用于沒(méi)有文本信息的PDF,則可以進(jìn)行搜索,從而增加了方便性。由于它基于Tesseract OCR引擎進(jìn)行文本識(shí)別,因此也支持中文。
PaddleClas - 是飛槳為工業(yè)界和學(xué)術(shù)界所準(zhǔn)備的一個(gè)圖像識(shí)別和圖像分類任務(wù)的工具集。
Github:https://github.com/PaddlePaddle/PaddleClas
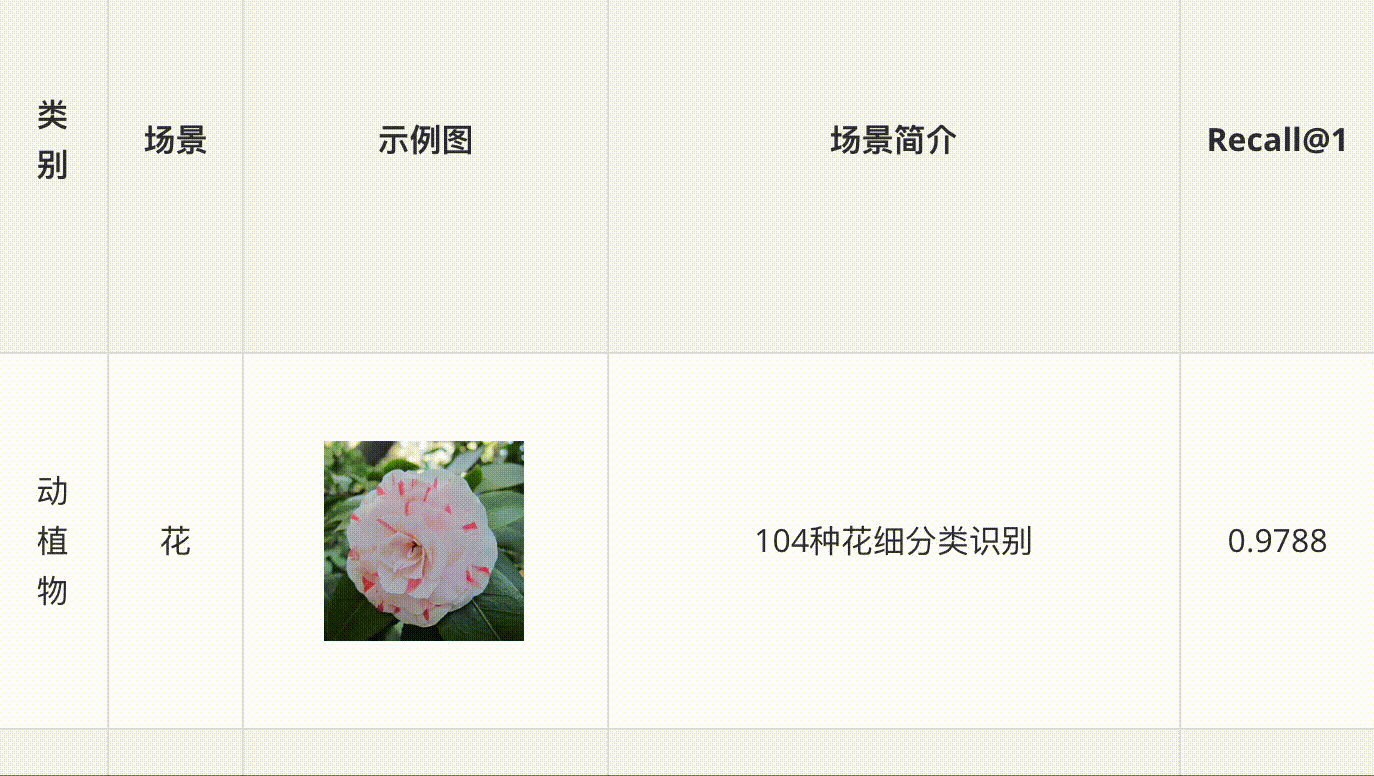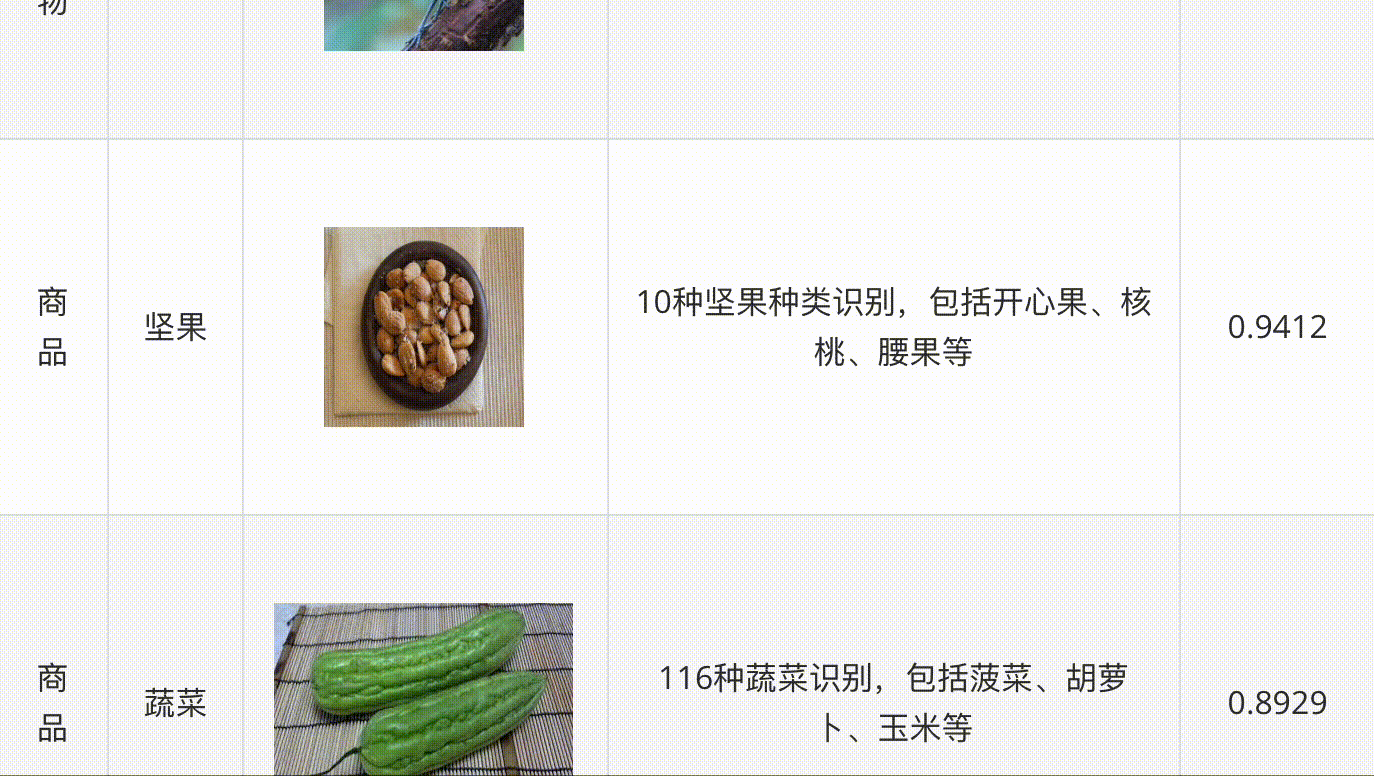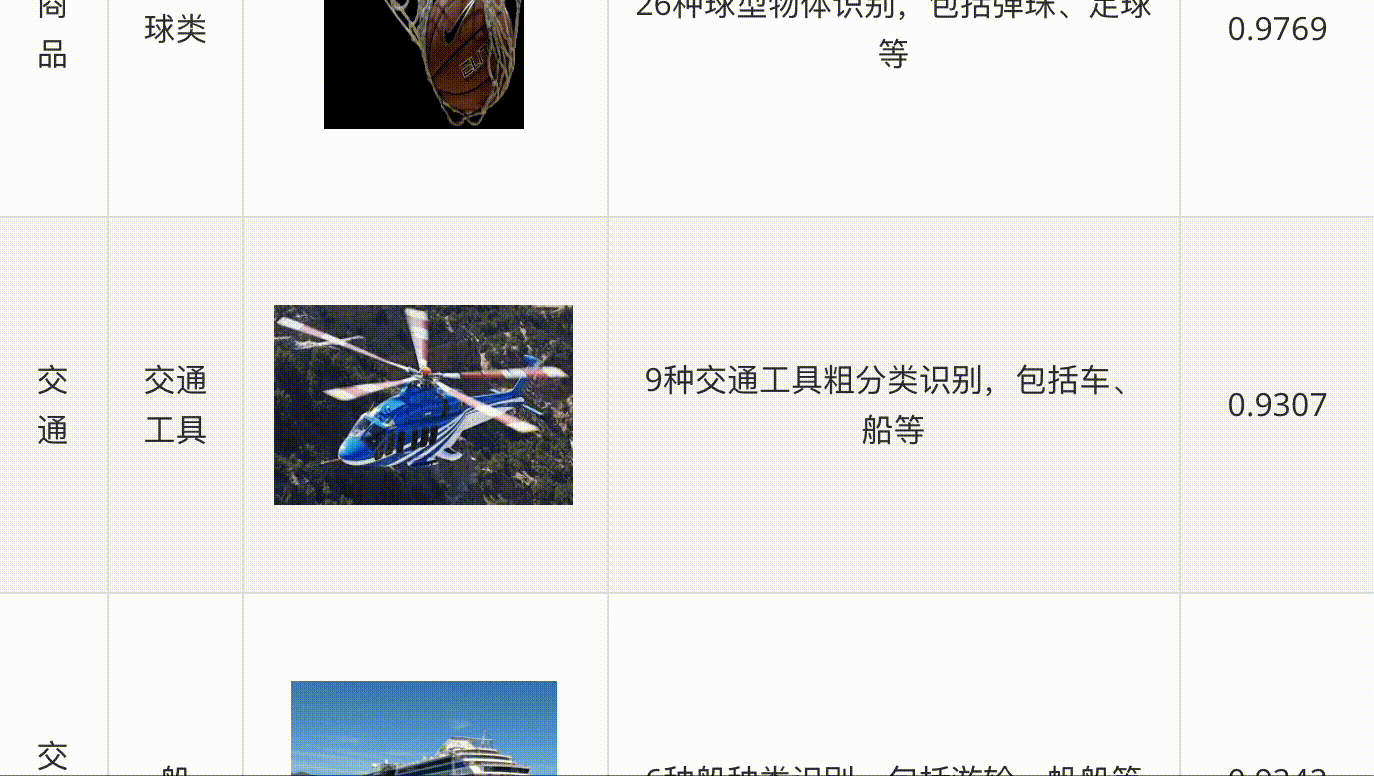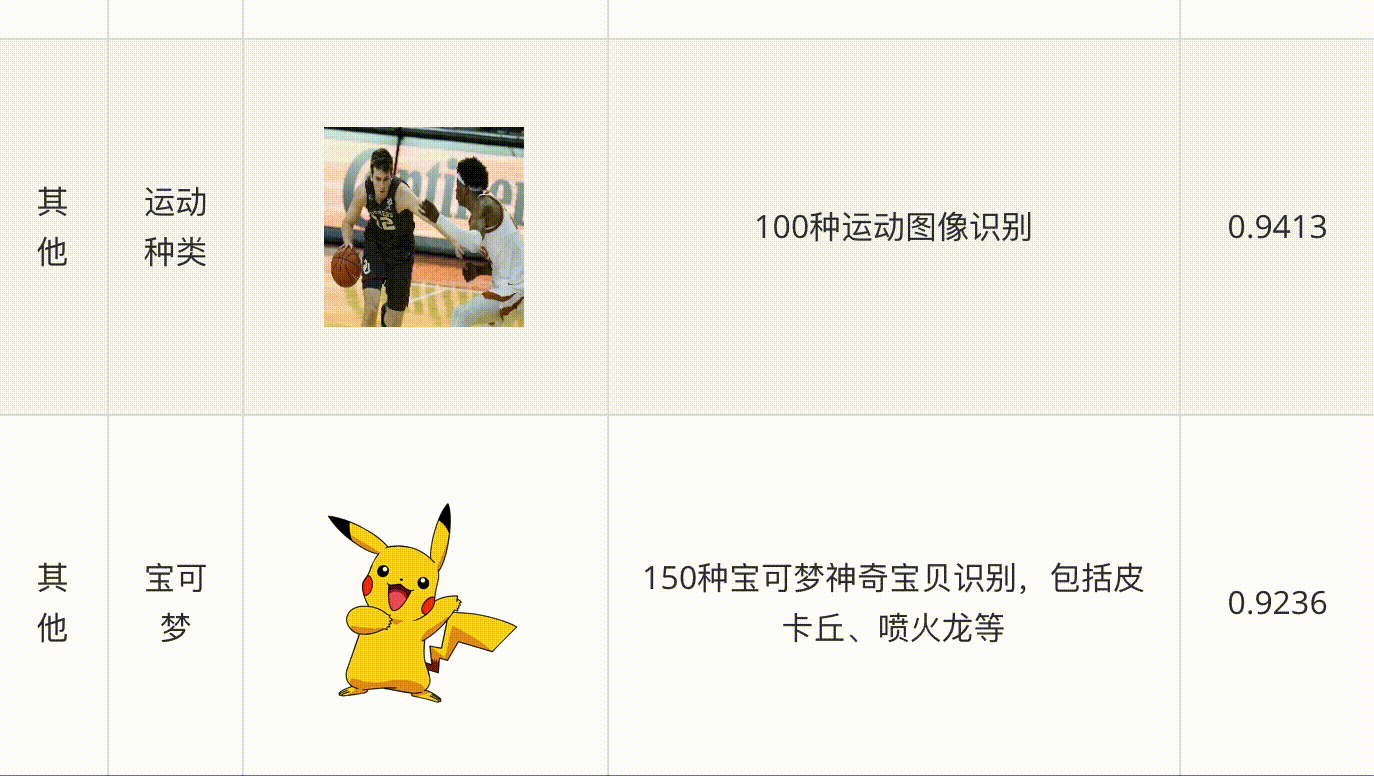
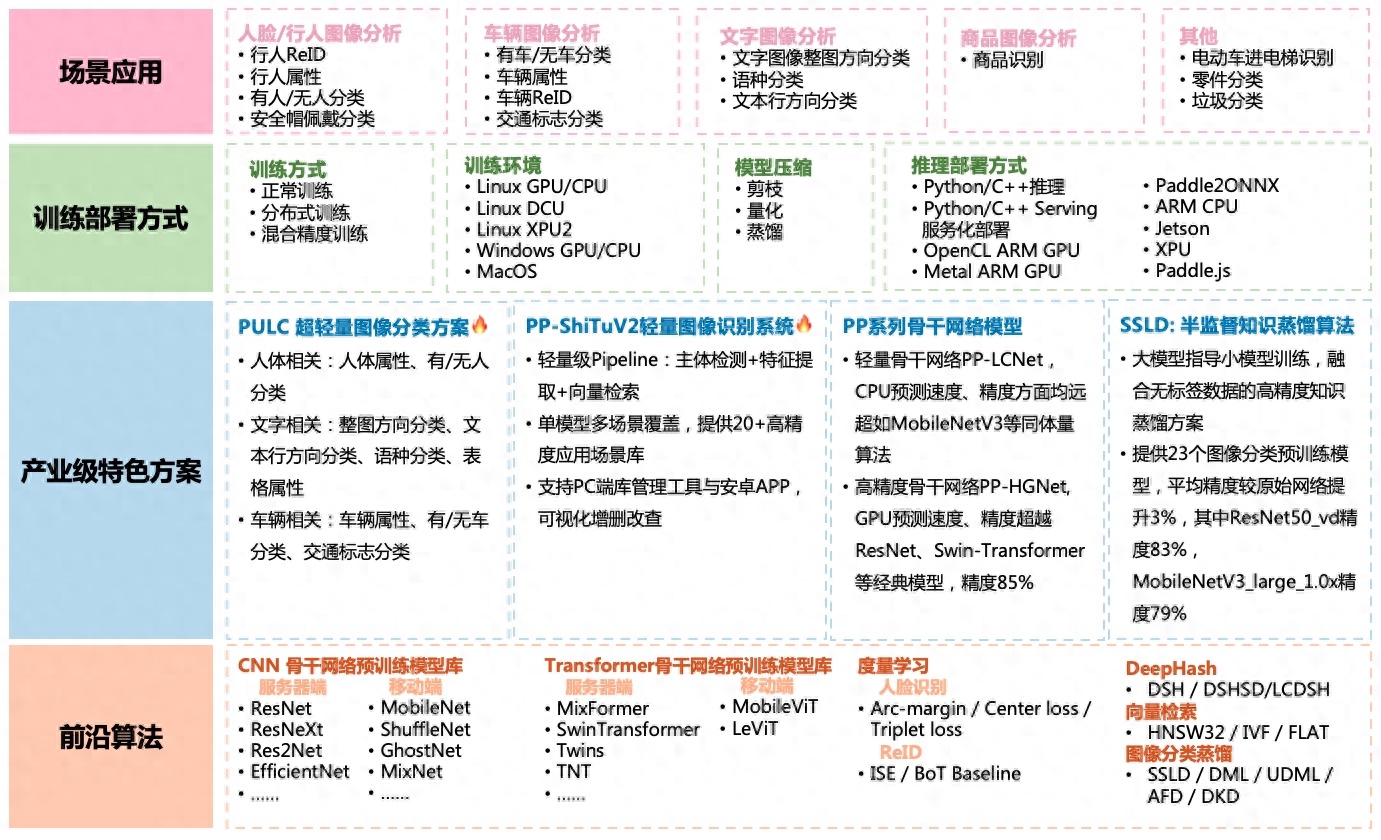
飛槳圖像識(shí)別套件PaddleClas是飛槳為工業(yè)界和學(xué)術(shù)界所準(zhǔn)備的一個(gè)圖像識(shí)別和圖像分類任務(wù)的工具集,助力使用者訓(xùn)練出更好的視覺(jué)模型和應(yīng)用落地。
特性
PaddleClas支持多種前沿圖像分類、識(shí)別相關(guān)算法,發(fā)布產(chǎn)業(yè)級(jí)特色骨干網(wǎng)絡(luò)PP-HGNet、PP-LCNetv2、 PP-LCNet和SSLD半監(jiān)督知識(shí)蒸餾方案等模型,在此基礎(chǔ)上打造PULC超輕量圖像分類方案和PP-ShiTu圖像識(shí)別系統(tǒng)。


kraken - 一個(gè)由Python開(kāi)發(fā)的OCR軟件,主要用于非拉丁字符的識(shí)別。
Github:https://github.com/mittagessen/kraken
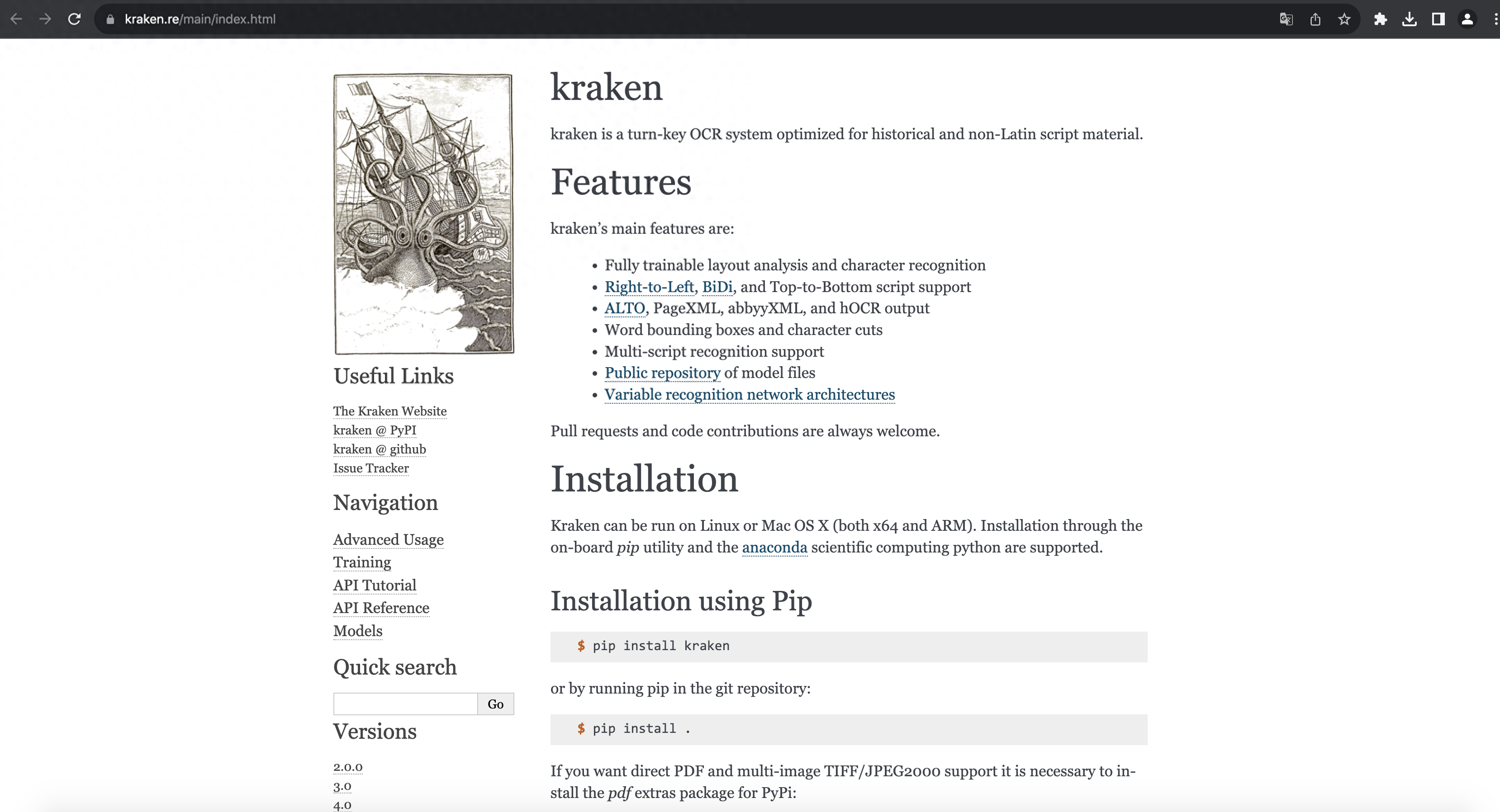
kraken 官網(wǎng)
kraken是一個(gè)由Python開(kāi)發(fā)的OCR軟件,主要用于非拉丁字符的識(shí)別。它支持從右到左書(shū)寫(xiě)的語(yǔ)言,例如阿拉伯語(yǔ),也支持從上到下書(shū)寫(xiě)的語(yǔ)言,例如日語(yǔ)。可以從命令行運(yùn)行OCR識(shí)別PDF、JPEG和TIFF等格式的文件。
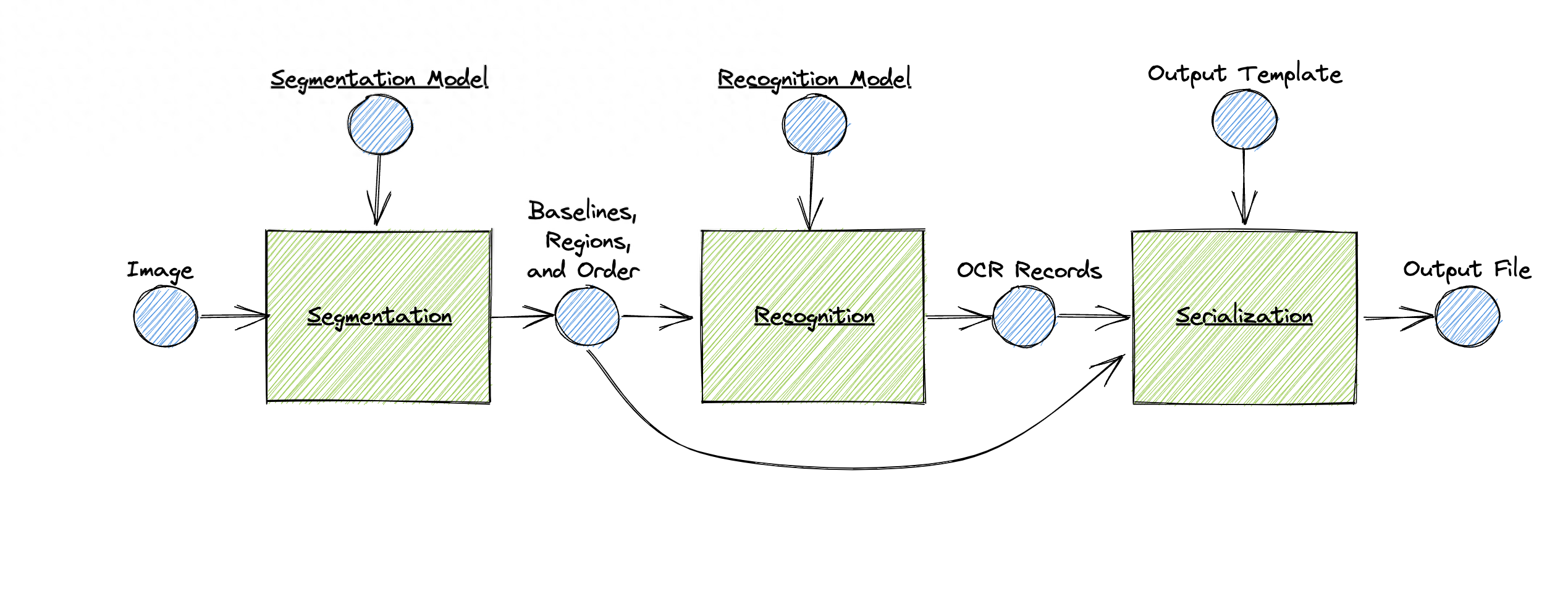
它的特點(diǎn)包括:
- 支持自定義訓(xùn)練的布局分析和字符識(shí)別
- 支持從右到左, 自上而下的識(shí)別
- 提供ALTO、PageXML、abbyyXML和hOCR 格式輸出
- 能夠識(shí)別單詞邊界框,支持字符剪切
- 多腳本識(shí)別支持
- 模型文件的公共存儲(chǔ)庫(kù)
- 動(dòng)圖識(shí)別網(wǎng)絡(luò)架構(gòu)
EasyOCR- 基于機(jī)器學(xué)習(xí)(CRNN)實(shí)現(xiàn)OCR功能。
Github :https://github.com/JaidedAI/EasyOCR
EasyOCR基于機(jī)器學(xué)習(xí)(CRNN)實(shí)現(xiàn)OCR功能。它能夠識(shí)別超過(guò)80種語(yǔ)言的文字,包括簡(jiǎn)體中文和繁體中文。它是使用python開(kāi)發(fā)的,因此使用Python調(diào)用也非常簡(jiǎn)單。例如:
識(shí)別包含中文的圖片
import easyocr
reader = easyocr.Reader(['ch_sim','en']) # this needs to run only once to load the model into memory
reader.readtext('chinese.jpg', detail = 0)識(shí)別結(jié)果為:
['愚園路', '西', '東', '315', '309', 'Yuyuan Rd.', 'W', 'E']