Flink程序宕機后,數據會丟失嗎
Apache Flink 是一種高性能、高吞吐量的流處理框架,它具有強大的容錯機制,可以保證在程序宕機后不會丟失數據。
Flink 通過將數據流分為一個個的小數據塊( 界線),在每個小數據塊上進行計算,并將結果存儲在內存中。當程序發生宕機時,Flink 會根據數據塊的大小和狀態,自動將數據回溯到上一個已經成功處理完的數據塊,并重新開始處理。

同時,Flink 還提供了檢查點(Checkpoint)機制,可以在程序運行過程中對數據進行備份和恢復。通過將數據狀態存儲在持久化存儲中,當程序發生故障時,可以從最后一個檢查點開始重新處理數據流,保證數據的完整性和一致性。
因此,使用 Flink 編寫程序時,需要開啟容錯機制和檢查點機制,以保證在程序宕機后不會丟失數據。同時,為了更好地保證數據的安全性和可靠性,建議使用持久化存儲來保存 Flink 的數據和狀態信息。
1、Chandy-Ricard算法
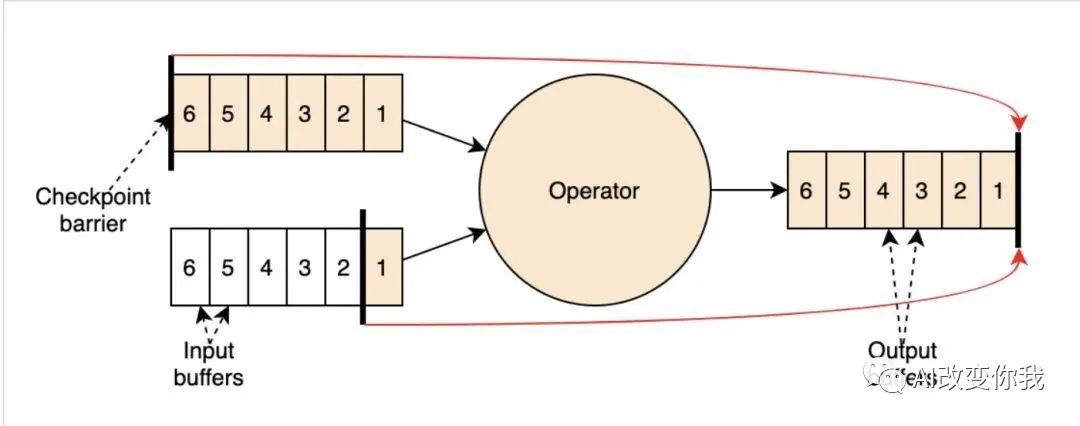
Flink的Chandy-Ricard算法是一種用于異步分布式快照(Asynchronous Distributed Snapshots)的算法,用于在分布式流處理系統中實現狀態一致性和容錯性。
在Flink中,Chandy-Ricard算法被用于實現狀態一致性,確保在分布式流處理過程中,所有任務和狀態副本都達到一致的狀態。它通過定期在各個任務之間交換快照數據來實現狀態同步,同時使用異步方式進行數據傳輸和處理,以避免阻塞和等待。
Chandy-Ricard算法的核心思想是將系統狀態劃分為全局狀態和局部狀態。全局狀態包括所有任務的狀態副本,而局部狀態僅包括每個任務自身的狀態。通過定期生成全局狀態快照,并將快照數據分發到各個任務,可以實現各個任務的狀態一致性。
在Flink中,Chandy-Ricard算法的實現包括以下步驟:
(1) 全局狀態快照的生成
每個TaskManager會定期生成自身的全局狀態快照(包含所有任務的狀態數據),并將快照數據發送給JobManager。
(2) 全局狀態快照的存儲
JobManager接收到各個TaskManager的全局狀態快照后,將它們合并成一個全局狀態快照,并將其存儲在穩定存儲設備上(例如硬盤)。
(3) 狀態一致性檢查
JobManager會定期向各個TaskManager發送一致性檢查請求,檢查它們的狀態是否與全局狀態快照一致。如果存在不一致的情況,JobManager會要求相應的TaskManager重新生成全局狀態快照。
(4) 狀態恢復
如果發生故障導致某個TaskManager失效,JobManager會使用最近一次成功的全局狀態快照來恢復該TaskManager的狀態。JobManager會將快照數據分發給其他可用的TaskManager,并重新執行計算任務,以保證分布式流處理的連續性和一致性。
總之,Chandy-Ricard算法是Flink中用于實現分布式流處理任務狀態一致性和容錯性的重要算法之一。它通過定期生成全局狀態快照并存儲在穩定存儲設備上,以及使用異步方式進行數據傳輸和處理,實現了高效的分布式狀態管理和容錯處理。
2、Checkpoint機制
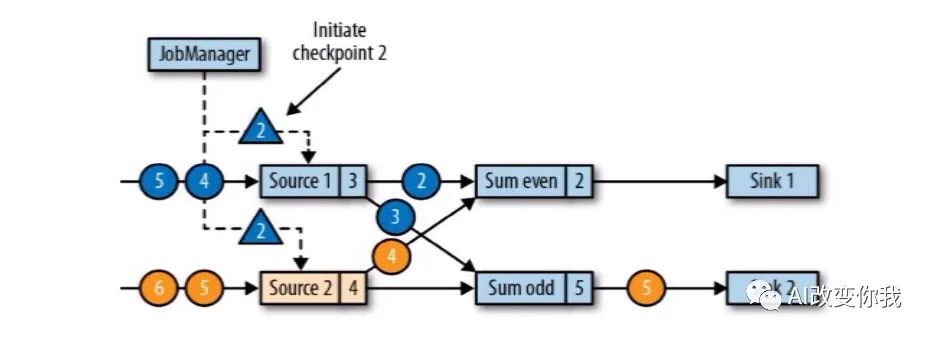
Flink的checkpoint機制是Flink可靠性的一種重要基石。它可以保證Flink集群在某個算子因為某些原因(如異常退出)出現故障時,能夠將整個應用流圖的狀態恢復到故障之前的某一狀態,保證應用流圖狀態的一致性。
具體來說,checkpoint機制是由JobMaster發起的。當程序啟動時,JobMaster會創建一個CheckpointCoordinator,周期性按照順序向下游算子發送barrier,對每個算子的計算狀態數據進行備份。當最后一個算子的計算狀態數據備份成功,那么本次的checkpoint完成。這樣,如果發生故障,程序只需讀取最近一個成功checkpoint的備份數據進行算子計算狀態恢復。