Meta普林斯頓提出LLM上下文終極解決方案!讓模型化身自主智能體,自行讀取上下文節點樹
到底什么才是LLM長上下文模型的終極解決方案?
最近由普林斯頓大學和Meta AI的研究者提出了一種解決方案,將LLM視為一個交互式智能體,讓它決定如何通過迭代提示來讀取文本。

論文地址:https://arxiv.org/abs/2310.05029
他們設計了一種名為MemWalker的系統,可以將長上下文處理成一個摘要節點樹。
收到查詢時,模型可以檢索這個節點樹來尋找相關信息,并在收集到足夠信息后做出回應。在長文本問答任務中,這個方法明顯優于使用長上下文窗口、遞歸和檢索的基線方法。
LeCun也在推上轉發對他們的研究表示了支持。

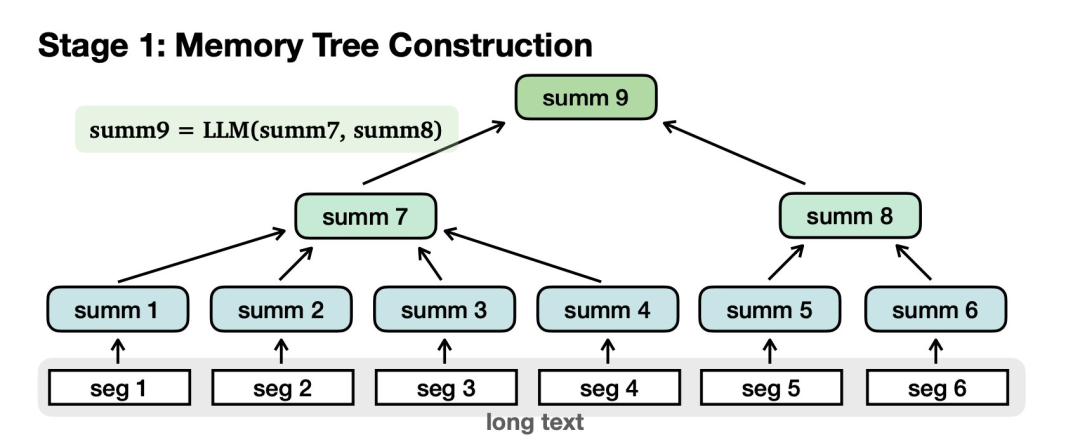
MemWalker主要由兩個部分構成:
首先需要構建記憶樹:
對長文本進行切分,歸納為摘要節點。匯總節點進一步匯總為更高級別的節點,最后到達根。
第二部分是導航(Navigation):
在接受查詢后,LLM會在樹中導航以查找相關信息并進行適當的響應。LLM通過推理來完成這一過程——可能會致力于找到某個答案,選擇沿著一條路走得更遠,或者發現自己誤入歧途,就原路撤回。
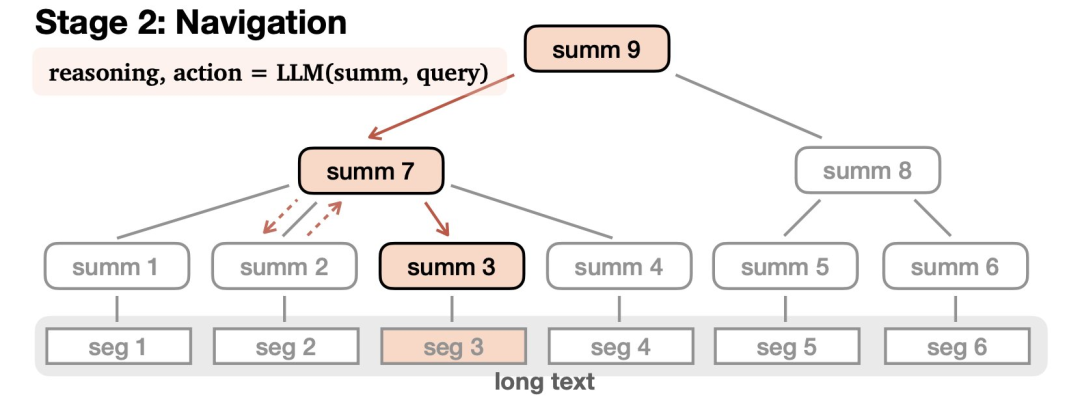
這個導航過程可以通過零樣本提示來實現,并且很容易適用于指定的的任何一個大語言模型。

研究團隊表明,通過對這個模型構建的記憶樹的交互式讀取,MemWalker 優于其他長上下文基線以及檢索和循環變體,特別對于更長的例子,效果更好。
MemWalker的有效性取決于兩個關鍵部分:
1) 工作內存大小 ——當允許 LLM 沿著其檢索的路徑能夠獲取跟多信息時,LLM 擁有更好的全局上下文能力。
2)LLM的推理能力高低——當LLM達到推理閾值時,MemWalker是有效的。當推理能力低于閾值時,導航過程中錯誤率就會很高。
MEMWALKER: 一個可互動讀取器
研究團隊研究與長上下文問答相關的任務——給定長文本x和查詢q,模型的目標是生成響應r。
MEMWALKER遵循兩個步驟:
1) 內存樹構建,其中長上下文被拆分成樹形數據結構。這種構建不依賴于查詢,因此如果事先有序列數據,可以提前計算。
2) 導航,模型在接收到查詢時導航此結構,收集信息以制定合適的響應。
MEMWALKER假定可以訪問基礎LLM,并且通過迭代LLM提示實現構建和導航。
導航
在接收到查詢q后,語言模型從根節點 開始導航樹以生成響應r。
開始導航樹以生成響應r。
在LLM遍歷的節點 處,它觀察到下一級節點
處,它觀察到下一級節點 的摘要。
的摘要。
LLM決定在 + 1個動作中選擇一個 - 選擇一個子節點以進一步檢查,或者返回到父節點。
+ 1個動作中選擇一個 - 選擇一個子節點以進一步檢查,或者返回到父節點。
在葉節點 處,LLM可以決定兩個動作中的一個:提交葉節點并響應查詢,或者如果葉節點中的信息
處,LLM可以決定兩個動作中的一個:提交葉節點并響應查詢,或者如果葉節點中的信息
(即 )不足,則返回到父節點
)不足,則返回到父節點 。
。
為了做出導航決定,研究團隊也可以通過提示要求LLM首先以自然語言生成一個理由來證明動作,然后是動作選擇本身。
具體地說,在每個節點,模型生成響應r ~ LLM(r | s, q),其中響應是兩個元組中的一個:1) 當LLM位于葉節點時,r = (reasoning, action, answer) 或 2) 當LLM位于非葉節點時,r = (reasoning, action)。
導航提示設計
研究團隊通過零樣本提示啟用LLM導航。具體需要兩種類型的提示:
1) 分診提示和2) 葉提示(在下表中高亮顯示)。

分診提示包含查詢、子節點的摘要和LLM應遵循的指令。分診提示用于非葉節點。
葉提示包含段落內容、查詢(和選項)以及要求LLM生成答案或返回到父節點的指令。
分診提示和葉提示都指定了LLM需要遵循的輸出格式。不遵守格式會導致無效動作,LLM需要重新生成。如果LLM連續三次未能生成可解析的輸出,導航終止并返回「無答案」。
工作內存
當LLM檢索完樹時,它可以在導航軌跡中保持信息,并將其添加到上下文中。
準確地說,LLM生成響應r ~ LLM(r | s, q, m),其中額外的工作內存
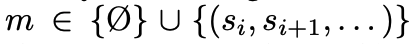
要么為空,要么包含來自先前訪問過的節點的內容。
研究團隊截斷工作內存,使其可以適應LLM的上下文窗口。
上表也展現了如何通過[WORKING MEMORY]在提示中添加工作記憶的方式。
實驗性配置
數據集和評估
研究團隊使用了三個數據集:QuALITY、SummScreenFD和GovReport,這些來自SCROLLS基準測試。研究團隊展示了所有數據集的準確性。
QuALITY
QuALITY是多項選擇題問答數據集。
該數據集包含了來自Project Gutenberg的長篇故事和由人類注釋員注釋的問題。研究團隊使用了187個示例的子集進行實驗。
SummScreenFD
SummScreenFD是一個包含電視和電影劇本的數據集,原本是為了總結而設計的。
這些劇本以演員之間的對話形式呈現。研究團隊將該數據集轉換為問答任務,其中原始提供的基本真實摘要文本被用來使用Stable Beluga 2生成一個「誰」的問題,然后由人類專家檢查答案。
與原始長文本配對的問題成為重新定位的QA任務的306個示例。
GovReport
GovReport數據集匯集了來自國會研究服務和美國政府問責辦公室的文檔,以及由專家提供的摘要。
研究團隊以與SummScreenFD相同的方式將該數據集轉換為包含101個示例的問答數據集。
所有三個數據集都以不同長度的長上下文作為示例特征 ,有些是較短的示例,有些是較長的序列。
因此,研究團隊既展示了原始數據集上的結果,也展示了每個任務中僅包含較長序列的子集上的結果,以便更好地評估在更困難、更長的上下文情況下的內存訪問。
門檻值分別是QuALITY的8000個token,SummScreenFD的6000個token和GovReport的12000個token。
模型
研究團隊在大多數實驗中使用Stable Beluga 2作為基礎LLM,因為與其他幾種LLM變體相比,它提供了最先進的性能,研究團隊將展示這一點。
Stable Beluga 2是一個基于70B LLaMA-2的指令調整模型,其中微調與研究團隊的評估任務不重疊。
它的最大上下文長度為4,096個token。研究團隊在沒有進一步微調或在上下文中為研究團隊的任務提供少量示例的情況下,以零射提示的方式使用該模型。
研究團隊使用頂部p采樣來進行內存樹構建以及生成導航的動作和推理。
研究團隊分別為QuALITY、SummScreenFD和GovReport設置節點的最大數量maxt Mt = 8, 5, 8和段大小|c| = 1000, 1000, 1200。
基準
研究團隊將三種基于相同底層LLM的內存技術與Stable Beluga 2進行比較:
1) 全上下文窗口
2) 遞歸
3) 檢索
全上下文窗口基線使用全部4,096個token來處理長輸入文本和生成。由于數據集中的實例經常超過上下文限制,研究團隊對長度進行截斷,將文本的右側(最近)或左側(最不近)作為輸入,并評估這兩種方法。
對于檢索,研究團隊使用Contriever(Izacard等人,2022)根據查詢從長上下文中選擇段落。得分最高的段落被連接為LLM的輸入上下文,直到它們填滿上下文。
最后,研究團隊實現了一個基線,該基線通過摘要將先前段落token中的信息循環傳遞到當前段落,其中每個段落為2,500個token,最大摘要大小為500個token。
結果與分析
主要結果
下表2展示了MEMWALKER與其他基線之間的比較。
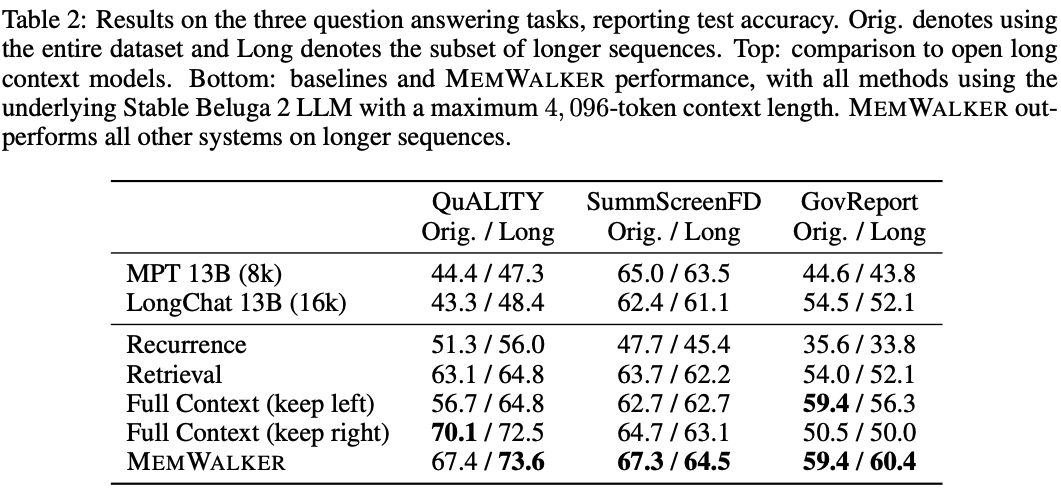
MEMWALKER在所有任務中都大幅度超越了遞歸基線。
這顯示了遞歸的限制,即查詢的相關信息在幾步之后會丟失。
MEMWALKER也超越了檢索,其中段落來自連貫的長篇故事,而不是單獨的文檔。
在這些任務中,全上下文基線可以在「原始」任務設置中表現良好,該設置可能包含相對較短的序列,盡管選擇左或右截斷以獲得最佳性能似乎取決于數據集。
然而,除了QuALITY上的保持右側變量和GovReport上的保持左側變量外,MEMWALKER在原始設置中實現了比全上下文基線更高的性能,這可能是由于數據集中的位置偏差,其中相關段落通常出現在文本的開頭或末尾。
然而,在所有三個任務的長版本上,MEMWALKER均超越所有基線,即在內存訪問變得更為關鍵時,它表現出強勁的性能。
MEMWALKER還超越了其他公開可用的模型,包括LongChat和MPT。
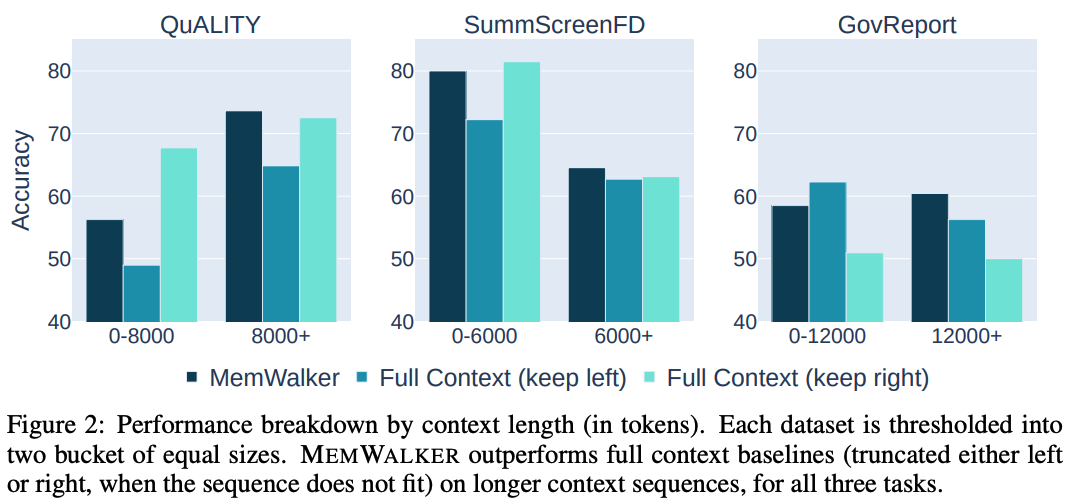
MEMWALKER提高了長序列上的性能。研究團隊在上圖2中為每個任務提供了輸入序列長度的性能細分。
當文本長度較短時,MEMWALKER不如全上下文(左或右截斷)基線,但在所有任務的較長序列上都優于兩種截斷類型。
交互式讀取的好處在于文本長度適當增加后顯現出來,即一旦序列長度明顯大于LLM上下文長度的4,096,就會顯示出更好的性能。
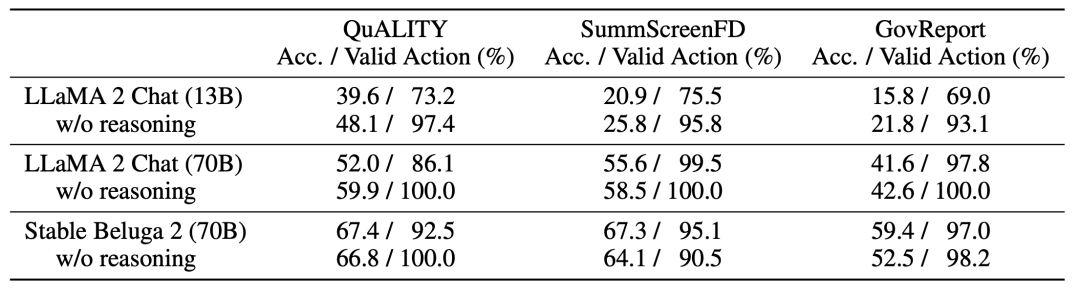
推理能力對于內存樹導航至關重要。
MEMWALKER的有效性高度依賴于底層LLM的推理能力。對于每個導航決策,研究團隊使用一個LLM提示,要求LLM首先以自然語言生成一個理由來證明接下來的預測動作,參見下表1。

研究團隊在下表3中展示了通過比較Llama 2 Chat(13B和70B參數變體)和Stable Beluga 2(70B),并通過從提示中刪除「在做出決定之前首先提供推理......」這行來展示推理如何影響性能。
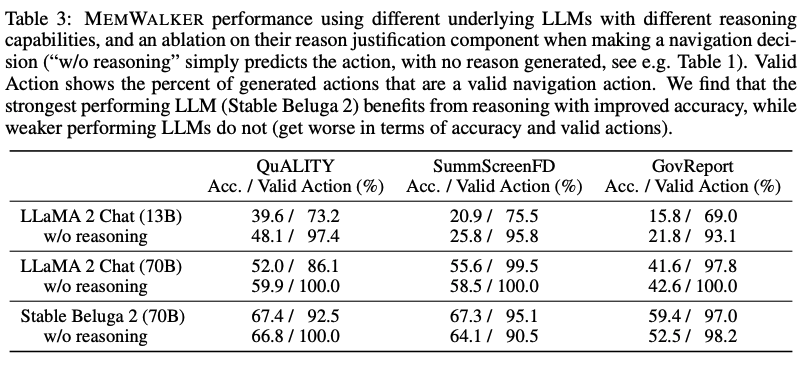
對于較小、能力較差的模型(13B),由于無法遵循指令,性能大幅落后于70B模型。實際上,為較弱的模型要求推理理由會降低性能,可能是因為它們無法生成和利用這些理由。
Stable Beluga 2的表現優于同一LLM大小的Llama 2 Chat,并且還顯示出增強的推理能力。
對于Stable Beluga 2,在所有任務中要求推理理由都會提高性能。這突顯了MEMWALKER的主要特點:如果LLM通過了關鍵推理能力閾值,它可以在多輪中對長輸入進行推理,而不會在各輪之間迅速產生錯誤。
對于不能做出良好導航決策的較弱LLM,錯誤可能會累積,總體性能會受損。
隨著LLM在未來幾年的推理能力的不斷提高,研究團隊期望像MEMWALKER這樣的方法會變得越來越有效。
導航內存樹需要工作內存。當MEMWALKER做出決策以遍歷內存樹并讀取相關段落時,它可能會失去對整體上下文的了解。
因此,模型將沿導航路徑從節點中攜帶信息作為工作內存,其中工作內存的內容在模型選擇下一路徑時更新。
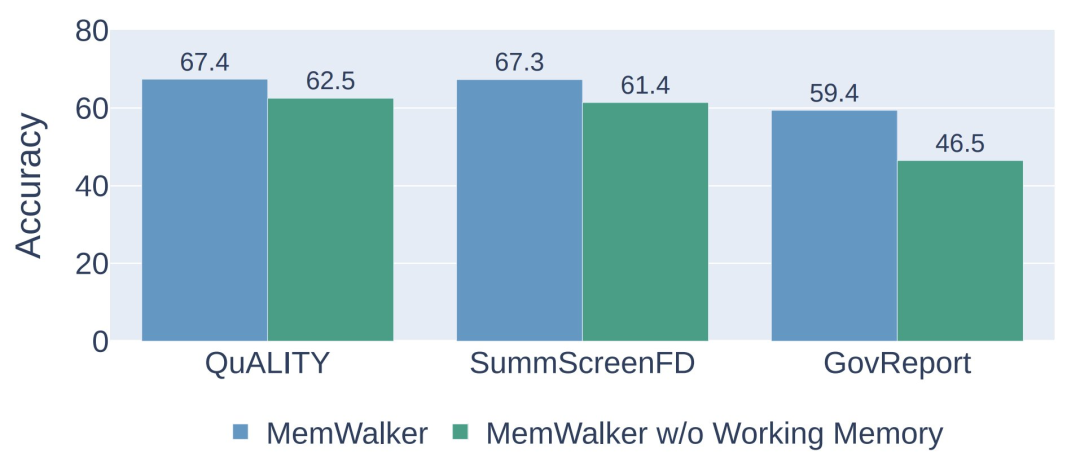
研究團隊評估了有無工作內存的MEMWALKER的性能,結果顯示在下圖3中。
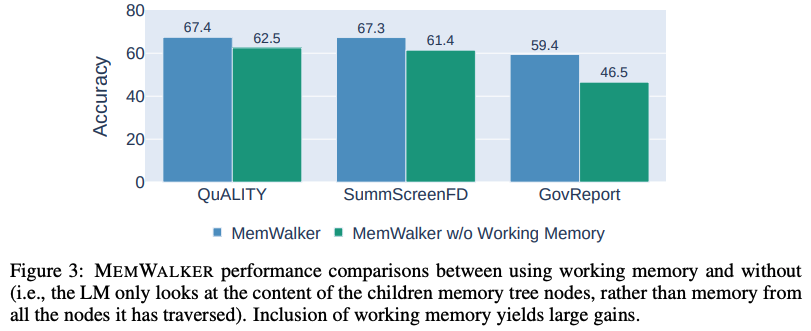
研究團隊發現在所有任務中,工作內存耗盡會導致性能顯著下降,準確率下降5-13%,顯示了這一組件的重要性。
MEMWALKER可以從錯誤的路徑中恢復。
當MEMWALKER導航內存樹時,它不僅需要找到通往最相關段落的路徑,而且可能需要從全部檢索錯誤中恢復。
研究團隊在下表4中展示了恢復統計數據。MEMWALKER對大約15% - 20%的示例執行恢復導航操作(因此更改路徑),但是在這些示例中可以恢復并在QuALITY中70%的時間內正確獲得這些示例,60%適用于SummScreenFD,和~ 80%適用于GovReport。

MEMWALKER實現了高效讀取。由于MEMWALKER確定了需要讀取長文本的哪些部分,因此需要讀取的有效內容可能小于整個序列。
研究團隊展示了所有示例的長上下文讀取百分比的平均值,對于三個任務中的每一個,見下圖4。研究團隊發現,平均只需要讀取63%-69%的文本就可以回答問題,包括樹節點的內容。

在成功的路徑中,所需的閱讀進一步減少到59% - 64%。
內存樹構建的權衡
當研究團隊構建內存樹時,會出現一個基本的權衡——將更大的段落總結為節點以減少樹的深度,但可能會失去內容的準確性。
類似地,將許多較低級別的節點連接到上面的節點可以幫助展平樹,但可能會使每個節點上的LLM導航任務變得更為困難。
下圖5顯示了QuALITY上內存樹的不同配置的性能。總結較大段落通常比總結較小段落以及將更多子節點連接到父節點更為有益。
然而,隨著節點最大數量的增加,性能趨于平穩,顯示了在內存樹構建過程中可以將多少信息打包到節點中的權衡。