面試被問(wèn)到MySQL中一條SQL語(yǔ)句的執(zhí)行過(guò)程
MySQL作為最常用的關(guān)系型數(shù)據(jù)庫(kù),無(wú)論是在應(yīng)用還是在面試中都是必須掌握的技能。
要印在腦子里面的東西
- DDL:數(shù)據(jù)定義,它用來(lái)定義數(shù)據(jù)庫(kù)對(duì)象,包括庫(kù),表,列,通過(guò)ddl我們可以創(chuàng)建,刪除,修改數(shù)據(jù)庫(kù)和表結(jié)構(gòu);
- DML:數(shù)據(jù)操作語(yǔ)言,增加刪除修改數(shù)據(jù)表中的記錄;
- DCL:數(shù)據(jù)控制語(yǔ)言,定義訪(fǎng)問(wèn)權(quán)限和安全級(jí)別;
- DQL:數(shù)據(jù)查詢(xún)語(yǔ)言,用它來(lái)查詢(xún)想要的記錄。
SQL執(zhí)行順序:
- from;
- join
- on
- where;
- group by;
- avg,sum.... 使用聚集函數(shù)進(jìn)行計(jì)算;
- having;
- select;
- distinct;
- order by;
- limit;
接下來(lái)我們就來(lái)鳥(niǎo)瞰msyql查詢(xún)的全貌,以下面這條sql為例。
select * from T where ID=1000;引用極客時(shí)間的這張生動(dòng)的圖:
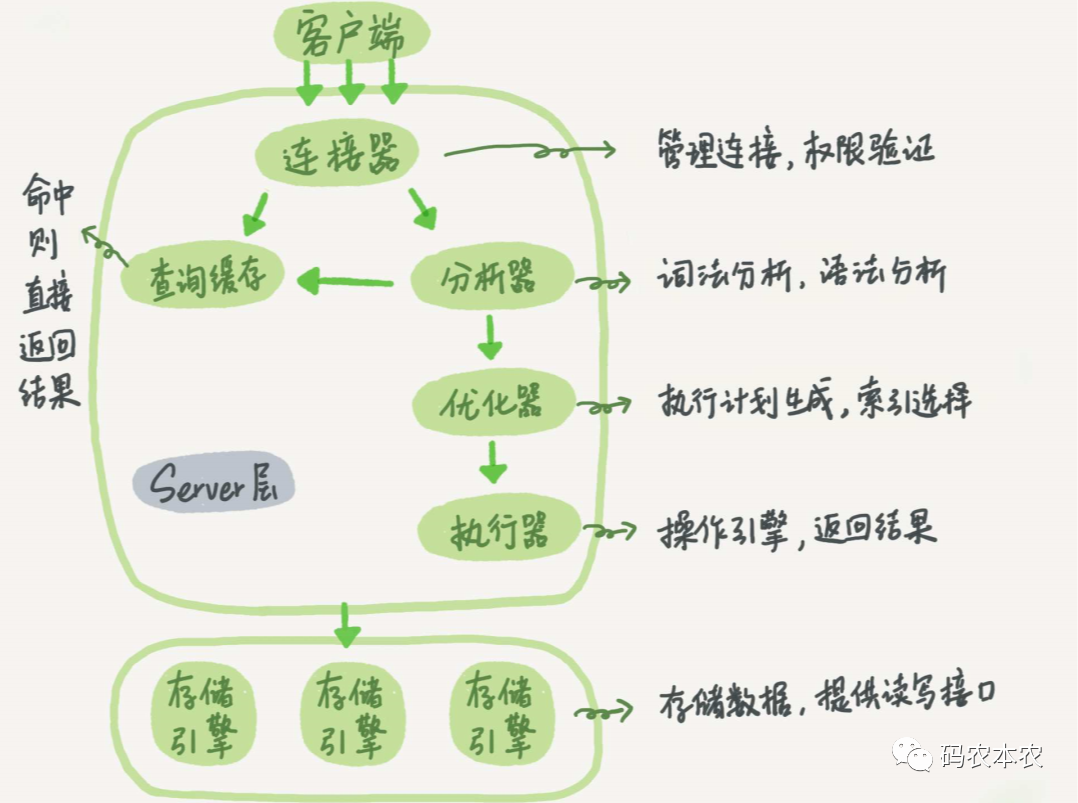
MySQL分為server層和存儲(chǔ)引擎層
1.Server層
server層實(shí)際上就是對(duì)sql語(yǔ)句進(jìn)行檢查,分析,優(yōu)化,執(zhí)行,完成這些就必須擁有一些工具:連接器,查詢(xún)緩存,分析器,優(yōu)化器,執(zhí)行器。
server層還包括我們使用的所有內(nèi)置函數(shù),比如日期相關(guān)函數(shù),時(shí)間相關(guān)函數(shù),數(shù)學(xué)相關(guān)函數(shù),加密相關(guān)函數(shù)等等。
server層還包含跨存儲(chǔ)引擎的功能,包括存儲(chǔ)過(guò)程,觸發(fā)器,視圖。
總之除了存儲(chǔ),其他功能都是server層干的。
(1) 連接器
連接器負(fù)責(zé)跟客戶(hù)端建立連接、獲取權(quán)限、維持和管理連接,當(dāng)一個(gè)連接請(qǐng)求過(guò)來(lái)后,首先迎接的就是連接器,連接器除了校驗(yàn)密碼外還要去獲取當(dāng)前賬號(hào)所擁有的權(quán)限并保存起來(lái),供后續(xù)流程使用,這樣一來(lái),只要鏈接不斷開(kāi),就算你修改了密碼也不會(huì)影響到當(dāng)前已經(jīng)建立的連接。
連接又分為長(zhǎng)連接和短連接,長(zhǎng)連接一般會(huì)一直維持,如果長(zhǎng)時(shí)間不操作,mysql就會(huì)判斷靜止時(shí)間是否超過(guò)參數(shù)wait_timeout配置的時(shí)間,如果超過(guò)就主動(dòng)斷開(kāi),這個(gè)參數(shù)默認(rèn)是8小時(shí);短連接是指每次執(zhí)行完很少的幾次查詢(xún)后就斷開(kāi),下次查詢(xún)就會(huì)再重新建立鏈接。
對(duì)于到底要使長(zhǎng)連接還是短連接也是一個(gè)值得思考的問(wèn)題,長(zhǎng)連接可以避免頻繁創(chuàng)建連接帶來(lái)的性能消耗,因?yàn)楫吘菇⑦B接過(guò)程還是比較復(fù)雜的,但是長(zhǎng)連接中,隨著執(zhí)行sql的數(shù)量,可能會(huì)導(dǎo)致緩存增多,這些緩存只能等到連接關(guān)閉才能釋放,所以如果長(zhǎng)連接很多,也會(huì)有內(nèi)存被占用過(guò)多的風(fēng)險(xiǎn),從而導(dǎo)致OOM,進(jìn)而導(dǎo)致進(jìn)程被系統(tǒng)殺死。
那么短連接的好處和壞處就不言而喻了。
如果你用的是MySQL 5.7或更新版本,可以在每次執(zhí)行一個(gè)比較大的操作后,通過(guò)執(zhí)行mysql_reset_connection來(lái)重新初始化連接資源。這個(gè)過(guò)程不需要重連和重新做權(quán)限驗(yàn)證,但是會(huì)將連接恢復(fù)到剛剛創(chuàng)建完時(shí)的狀態(tài)。
(2) 查詢(xún)緩存
mysq建立連接后,mysql會(huì)先查詢(xún)緩存,如果開(kāi)啟緩存,mysql就會(huì)把查過(guò)的sql以key-value對(duì)的形式緩存起來(lái),sql語(yǔ)句是key,查詢(xún)結(jié)果是value。
mysql的緩存其實(shí)并不友好,對(duì)于一個(gè)變化比較頻繁的表,前一秒查詢(xún)?cè)摫恚呀Y(jié)果緩存起來(lái),后一秒對(duì)該表做了更新操作,那么緩存就會(huì)被清空,就造成辛辛苦苦保存的緩存還沒(méi)使用就被清空了,這樣給整個(gè)工作沒(méi)有帶來(lái)效率反而帶來(lái)消耗。
因此只有靜態(tài)表才適合使用緩存,靜態(tài)表一般不怎么變化,但是查詢(xún)又比較頻繁,比如配置表。
但是一般配置表本身就不會(huì)太大,不用緩存也不會(huì)看出有明顯效率問(wèn)題,這也許就是MySQL 8.0版本直接將查詢(xún)緩存的整塊功能刪掉的原因吧。
(3) 分析器
如果沒(méi)有命中緩存,那就需要去執(zhí)行sql語(yǔ)句了,我們寫(xiě)了一條查詢(xún)語(yǔ)句,看起來(lái)實(shí)際就是一串字符串,那mysql怎么知道這一串字符串是符合要求且能執(zhí)行的sql語(yǔ)句呢?分析器就是負(fù)責(zé)做這件事。
分析器先會(huì)做“詞法分析”。你輸入的是由多個(gè)字符串和空格組成的一條SQL語(yǔ)句,MySQL需要識(shí)別出里面的字符串分別是什么,代表什么。 MySQL從你輸入的"select"這個(gè)關(guān)鍵字識(shí)別出來(lái),這是一個(gè)查詢(xún)語(yǔ)句。它也要把字符串“T”識(shí)別成“表名T”,把字符串“ID”識(shí)別成“列ID”。
做完了這些識(shí)別以后,就要做“語(yǔ)法分析”。根據(jù)詞法分析的結(jié)果,語(yǔ)法分析器會(huì)根據(jù)語(yǔ)法規(guī)則,判斷你輸入的這個(gè)SQL語(yǔ)句是否滿(mǎn)足MySQL語(yǔ)法。如果你的語(yǔ)句不對(duì),就會(huì)收到“You have an error in your SQL syntax”的錯(cuò)誤提醒。
一般語(yǔ)法錯(cuò)誤會(huì)提示第一個(gè)出現(xiàn)錯(cuò)誤的位置,所以你要關(guān)注的是緊接“use near”的內(nèi)容。
(4) 優(yōu)化器
解析器已經(jīng)知道這條sql語(yǔ)句要做什么?能不能做?接下來(lái)就是優(yōu)化器來(lái)決定怎么做,一條sql語(yǔ)句是可以很復(fù)雜的,各種表連接和子查詢(xún)等等,優(yōu)化器要做的就是給這條復(fù)雜的sql尋找一個(gè)優(yōu)化成查詢(xún)效率相對(duì)高的策略,比如使用哪個(gè)索引,表連接的順序等等都是在這里確認(rèn),一條sql的查詢(xún)性能和優(yōu)化器的處理是分不開(kāi)的。
總之優(yōu)化器處理完,查詢(xún)方案就已經(jīng)確定了。mysql的優(yōu)化器里面涉及到很多的算法,算是比較復(fù)雜的一個(gè)模塊,后面我們?cè)趕ql優(yōu)化里面單獨(dú)討論。
(5) 執(zhí)行器
MySQL通過(guò)分析器知道了你要做什么,通過(guò)優(yōu)化器知道了該怎么做,于是就進(jìn)入了執(zhí)行器階段,開(kāi)始執(zhí)行語(yǔ)句:
- 第一步就是校驗(yàn)權(quán)限,看當(dāng)前用戶(hù)是否對(duì)當(dāng)前查詢(xún)的表具有查詢(xún)權(quán)限。
- 第二步如果權(quán)限校驗(yàn)通過(guò),就開(kāi)始調(diào)用存儲(chǔ)引擎的接口取出表的第一行數(shù)據(jù),然后判斷id是不是1000,如果是就存到結(jié)果集中,如果不是則跳過(guò)。
- 第三步再調(diào)用存儲(chǔ)引擎引擎接口取出表的第二行數(shù)據(jù),再進(jìn)行上述判斷,直到查到最后一行數(shù)據(jù)。
如果表中有索引,無(wú)非是在上述流程加一些索引的邏輯,后續(xù)會(huì)詳細(xì)說(shuō)明,但是整體的邏輯原理是沒(méi)有變的。
2.存儲(chǔ)引擎層
存儲(chǔ)引擎顧名思義就是和存儲(chǔ)有關(guān),必然要和磁盤(pán)交互,msyql的存儲(chǔ)引擎是插件式的架構(gòu)模式,這就使得mysql的存儲(chǔ)引擎可以單獨(dú)實(shí)現(xiàn),也使得msyq的存儲(chǔ)引擎可以不止一種類(lèi)型,mysql常用的存儲(chǔ)引擎是InnoDB、MyISAM、Memory,在MySQL 5.5.5版本InnoDB成為mysql的默認(rèn)存儲(chǔ)引擎。當(dāng)然在創(chuàng)建sql語(yǔ)句的時(shí)候也是可以指定使用哪一種存儲(chǔ)引擎的。
存儲(chǔ)引擎主要是提供存取功能,主要是通過(guò)自身提供的api供server層調(diào)用,從而是實(shí)現(xiàn)存取功能。
為了提高效率,不同的引擎會(huì)有不同的策略,InnoDB的索引結(jié)構(gòu)就是為了提高查詢(xún)效率的一種數(shù)據(jù)結(jié)構(gòu)。