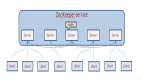
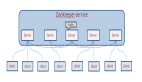
Hadoop高可用集群部署
背景
生產(chǎn)中Hadoop分布式集群中可能存在著單點(diǎn)故障問(wèn)題,如果Namenode宕機(jī)或是軟硬件升級(jí),集群將無(wú)法使用,所以進(jìn)行搭建高可用的來(lái)消除單點(diǎn)故障。
Hadoop介紹
Hadoop集群一般為一個(gè)NameNode和ResourceManager,但在實(shí)際生產(chǎn)環(huán)境中,若恰好具有NameNode和ResourceManager的節(jié)點(diǎn)出現(xiàn)故障,那么整個(gè)Hadoop集群將會(huì)崩潰,這是因?yàn)樵贖DFS中NameNode是系統(tǒng)的核心節(jié)點(diǎn),ResourceManager負(fù)責(zé)整個(gè)系統(tǒng)的資源管理和分配。
為了解決單點(diǎn)故障問(wèn)題,在Hadoop2后中引入了高可用機(jī)制,支持NameNode和ResourceManager一個(gè)主節(jié)點(diǎn)和一個(gè)備用節(jié)點(diǎn),而在Hadoop3中繼續(xù)對(duì)其進(jìn)行了優(yōu)化和提升,它支持一個(gè)主節(jié)點(diǎn)和多個(gè)備用節(jié)點(diǎn)。所謂高可用(High Availability, HA)就是7*24 小時(shí)不中斷服務(wù),消除單點(diǎn)故障。
Hadoop HA嚴(yán)格來(lái)說(shuō)應(yīng)該分成各個(gè)組件的HA機(jī)制:HDFS的HA和YARN的HA,可以通過(guò)配置多個(gè)NameNode和ResourceManager(Active/Standby)實(shí)現(xiàn)在集群中的熱備來(lái)解決上述問(wèn)題。
環(huán)境準(zhǔn)備:
 圖片
圖片
節(jié)點(diǎn)相關(guān)進(jìn)程如下:
 圖片
圖片
- 操作系統(tǒng):centos8
- 內(nèi)存:4G
- Java 版本:jdk8
HDFS和YARN HA集群搭建
3.1 下載hadoop安裝包
官網(wǎng)https://hadoop.apache.org/下載hadoop 3.3.0安裝包解壓至/usr/local下3臺(tái)機(jī)器需修改的配置文件目錄為/usr/local/hadoop/etc/hadoop下。
3.2 hadoop.env
export JAVA_HOME=/usr/local/jdk #配置jdk路徑
#添加兩行
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root3.3 core-site.xml
<?xml versinotallow="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- hdfs分布式文件系統(tǒng)名字/地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!--存放namenode、datanode數(shù)據(jù)的根路徑 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<!-- 存放journalnode數(shù)據(jù)的地址 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/tmp/jn</value>
</property>
<!-- 列出運(yùn)行 ZooKeeper 服務(wù)的主機(jī)端口對(duì) -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop:2181,k8s-2:2181,k8s-3:2181</value>
</property>
</configuration>3.4 hdfs-site.xml
<?xml versinotallow="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/dfs/journalnode</value>
<description>The path where the JournalNode daemon will store its local state.</description>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns</value>
<description>The logical name for this new nameservice.</description>
</property>
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2,nn3</value>
<description>Unique identifiers for each NameNode in the nameservice.</description>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>hadoop:8020</value>
<description>The fully-qualified RPC address for nn1 to listen on.</description>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>k8s-2:8020</value>
<description>The fully-qualified RPC address for nn2 to listen on.</description>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn3</name>
<value>k8s-3:8020</value>
<description>The fully-qualified RPC address for nn3 to listen on.</description>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>hadoop:9870</value>
<description>The fully-qualified HTTP address for nn1 to listen on.</description>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>k8s-2:9870</value>
<description>The fully-qualified HTTP address for nn2 to listen on.</description>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn3</name>
<value>k8s-3:9870</value>
<description>The fully-qualified HTTP address for nn3 to listen on.</description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop:8485;k8s-3:8485;k8s-2:8485/ns</value>
<description>The URI which identifies the group of JNs where the NameNodes will write/read edits.</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>The Java class that HDFS clients use to contact the Active NameNode.</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
<description>
A list of scripts or Java classes which will be used to fence the Active NameNode during a failover.
sshfence - SSH to the Active NameNode and kill the process
shell - run an arbitrary shell command to fence the Active NameNode
</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<description>Set SSH private key file.</description>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>Automatic failover.</description>
</property>
</configuration>3.5 mapred-site.xml
<?xml versinotallow="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>3.6 yarn-site.xml
<?xml versinotallow="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>Enable RM HA.</description>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
<description>Identifies the cluster.</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
<description>List of logical IDs for the RMs. e.g., "rm1,rm2".</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop</value>
<description>Set rm1 service addresses.</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>k8s-2</value>
<description>Set rm2 service addresses.</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>k8s-3</value>
<description>Set rm3 service addresses.</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hadoop:8088</value>
<description>Set rm1 web application addresses.</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>k8s-2:8088</value>
<description>Set rm2 web application addresses.</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>k8s-3:8088</value>
<description>Set rm3 web application addresses.</description>
</property>
<property>
<name>hadoop.zk.address</name>
<value>hadoop:2181,k8s-2:2181,k8s-3:2181</value>
<description>Address of the ZK-quorum.</description>
</property>
</configuration>3.7 workers
hadoop
k8s-2
k8s-3安裝zookeeper
版本:zookeeper-3.6.4
通過(guò)https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.6.4/apache-zookeeper-3.6.4-bin.tar.gz 下載安裝包,3臺(tái)機(jī)器進(jìn)行解壓配置安裝。
echo "1" > /data/zookeeperdata/myid #不同機(jī)器id不同zoo.cfg配置如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeperdata #數(shù)據(jù)目錄
dataLogDir=/data/zookeeperdata/logs #日志目錄
clientPort=2181 #端口
server.1=192.xxx.xxx.128:2888:3888
server.2=192.xxx.xxx.132:2888:3888
server.3=192.xxx.xxx.131:2888:3888環(huán)境變量配置
vi /etc/profile
export JAVA_HOME=/usr/local/jdk
export HAD00P_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CLASSPATH=`hadoop classpath`source /etc/profile啟動(dòng)集群
在所有節(jié)點(diǎn)上使用rm -rf /usr/local/hadoop/dfs命令,刪除之前創(chuàng)建的存儲(chǔ)路徑,同時(shí)在master節(jié)點(diǎn)上執(zhí)行mkdir -p /usr/local/hadoop/dfs/name /usr/local/hadoop/dfs/data /usr/local/hadoop/dfs/journalnode,再次創(chuàng)建存儲(chǔ)路徑。
在所有節(jié)點(diǎn)上使用rm -rf /usr/local/hadoop/tmp /usr/local/hadoop/logs && mkdir -p /usr/local/hadoop/tmp /usr/local/hadoop/logs命令,重置臨時(shí)路徑和日志信息。
通過(guò)以上步驟,Hadoop HA集群就配置完成了,當(dāng)?shù)谝淮螁?dòng)HA集群時(shí)需要依次執(zhí)行以下命令:
$ZOOKEEPER_HOME/bin/zkServer.sh start # 開(kāi)啟Zookeeper進(jìn)程(所有節(jié)點(diǎn)上執(zhí)行)
$HADOOP_HOME/bin/hdfs --daemon start journalnode # 開(kāi)啟監(jiān)控NameNode的管理日志的JournalNode進(jìn)程(所有節(jié)點(diǎn)上執(zhí)行)
$HADOOP_HOME/bin/hdfs namenode -format # 命令格式化NameNode(在master節(jié)點(diǎn)上執(zhí)行)
scp -r /usr/local/hadoop/dfs k8s-2:/usr/local/hadoop # 將格式化后的目錄復(fù)制到slave1中(在master節(jié)點(diǎn)上執(zhí)行)
scp -r /usr/local/hadoop/dfs k8s-3:/usr/local/hadoop # 將格式化后的目錄復(fù)制到slave2中(在master節(jié)點(diǎn)上執(zhí)行)
$HADOOP_HOME/bin/hdfs zkfc -formatZK # 格式化Zookeeper Failover Controllers(在master節(jié)點(diǎn)上執(zhí)行)
start-dfs.sh&&start-yarn.sh # 啟動(dòng)HDFS和Yarn集群(在master節(jié)點(diǎn)上執(zhí)行)若不是第一次啟動(dòng)HA集群(常規(guī)啟動(dòng)HA集群),則只需要依次執(zhí)行以下命令:
$ZOOKEEPER_HOME/bin/zkServer.sh start # 開(kāi)啟Zookeeper進(jìn)程(所有節(jié)點(diǎn)上執(zhí)行)
start-all.sh或者$HADOOP_HOME/sbin/start-dfs.sh && $HADOOP_HOME/sbin/start-yarn.sh # 啟動(dòng)HDFS和Yarn集群(在master節(jié)點(diǎn)上執(zhí)行)啟動(dòng)完成后每個(gè)節(jié)點(diǎn)使用jps命令會(huì)出現(xiàn)NameNode、DataNode、ResourceManager、NodeManager、JournalNode、DFSZKFailoverController、QuorumPeerMain和Jps 8個(gè)進(jìn)程。
 圖片
圖片
 圖片
圖片
通過(guò)頁(yè)面訪問(wèn)查看:
http://192.xxx.xxx.128:9870/
 圖片
圖片
http://192.xxx.xxx.128:8088/cluster/nodes
 圖片
圖片
hdfs HA驗(yàn)證
6.1 查看各個(gè)節(jié)點(diǎn)NameNode狀態(tài)
 圖片
圖片
6.2 驗(yàn)證hdfs的高可用
在開(kāi)啟HA集群并成功啟動(dòng)的情況下,在master節(jié)點(diǎn)中使用hdfs haadmin -getAllServiceState命令查看各個(gè)節(jié)點(diǎn)NameNode狀態(tài),接下來(lái)停止active狀態(tài)節(jié)點(diǎn)的NameNode進(jìn)程。
 圖片
圖片
Namenode active自動(dòng)跳轉(zhuǎn)其他節(jié)點(diǎn),集群仍可用。
 圖片
圖片
 圖片
圖片
隨后再啟動(dòng)該節(jié)點(diǎn)NameNode進(jìn)程,最后再次查看狀態(tài),可以發(fā)現(xiàn)HDFS HA是正常的,并且沒(méi)有發(fā)生搶占。
 圖片
圖片
驗(yàn)證yarn 高可用
在master節(jié)點(diǎn)中使用yarn rmadmin -getAllServiceState命令查看各個(gè)節(jié)點(diǎn)ResourceManager狀態(tài),接下來(lái)停止active狀態(tài)節(jié)點(diǎn)的ResourceManage進(jìn)程,ResourceManage active自動(dòng)跳轉(zhuǎn)到其他節(jié)點(diǎn),集群仍可用,隨后再啟動(dòng)該節(jié)點(diǎn)ResourceManager進(jìn)程,最后再次查看狀態(tài),F(xiàn)ailed狀態(tài)恢復(fù)為standby。
 圖片
圖片
若要關(guān)閉集群可以master使用$HADOOP_HOME/sbin/stop-yarn.sh && $HADOOP_HOME/sbin/stop-dfs.sh命令或者stop-all.sh 即可關(guān)閉hadoop集群,然后關(guān)閉zookeeper,三臺(tái)機(jī)器分別執(zhí)行/data/apache-zookeeper-3.6.4-bin/bin/zkServer.sh stop。