?Alluxio SDK 在 Presto/Trino 中的應用

一、Alluxio Edge 產生的背景
首先來介紹一下現代數據技術棧的演變歷程。

10 年前,Hadoop 擁有一個緊密耦合的 MapReduce 和 HDFS 架構。HDFS 在本地部署,計算資源多由 YARN 管理。今天,技術棧的豐富帶給我們更多的選擇,并讓不同的架構具備了可能性。我們現在看到了越來越多的計算與存儲的解耦和分離;有了云和數據湖,而且越來越多的數據湖放在了云上;資源管理和編排則由 Kubernetes+ 容器來承擔。所有這些技術的改變讓我們的系統有了更好的彈性、更高的可擴展性、更便捷的管理。然而,這些好處也伴隨著一個問題,即數據本地性的喪失。數據本地性就是計算引擎在本地(比如本節點、本集群)就可以訪問數據的特性,其好處是高效的數據訪問性能和低廉的數據訪問開銷。

在失去數據本地性以后,我們發現,數據的訪問性能變得緩慢且不穩定,用戶的查詢運行時間變得更長,因此需要更長的時間來獲取業務洞察。不僅如此,查詢運行的時間越長,云上集群消耗的時間和資源就越多,導致集群成本增加。很多企業想要加快任務的執行速度,一部分原因是想讓業務分析變得更加敏捷,另一部分原因是想節省計算資源的開銷。
在使用云上對象存儲的情況下,由于數據量的快速增長,我們發現數據的出口開銷(也就是 egress cost)變成企業使用云成本的重要組成部分。盡管云上的對象存儲的單位字節的存儲成本很低,但數據就像被“綁架”了,當你想要從云上訪問數據時,會產生各種額外開銷,例如 API 調用開銷和數據傳輸開銷。如果這些開銷發生在同一批數據上(比如熱數據的反復讀取),會帶來巨大的成本。因此,有些用戶會選擇把要分析的數據一次性拷貝到計算集群附近的存儲系統中,然后進行分析。這個方案需要人們建設和維護多個存儲集群,并打造和維護數據拷貝任務的 pipeline。此外,數據的改動、數據生產和消費的變化等都容易引起拷貝錯誤,需要排查和解決。
Alluxio System 作為分布式的數據編排系統,具有緩存功能,能夠解決上面的痛點。同時,我們在思考,如何把緩存這個最基本、最常用的功能做得更極致化。計算機領域有句著名的話,“在計算機科學中只有兩件難事:緩存失效和命名”。于是,就誕生了 Alluxio Edge。
二、Alluxio Edge 概要介紹
Alluxio 是一個滿足不同用戶需求的數據平臺。它包括兩大類產品線,分別為Alluxio System 和 Alluxio Edge。

Alluxio System 作為一個開源項目,已廣為人知。簡單地說,它是一個獨立的分布式系統,其緩存容量可以水平擴展,并具備數據編排系統的其他功能,例如接口轉換、統一命名空間等。本次分享的重點是 Alluxio Edge。
1、Alluxio Edge 是什么
Alluxio Edge 是一個庫,可以放在如 PrestoDB 和 Trino 的應用程序的進程中運行。它可以利用 PrestoDB 或者 Trino 集群的本地存儲空間(比如 SSD 或內存)來緩存數據。當大部分熱數據能夠放在本地磁盤或者內存中時,它是最理想的選擇。
為什么我們需要一個緩存呢?主要有下面幾個原因:
- 對很多查詢來說,IO 是排在第一位的性能瓶頸。
- 對于有些存儲系統,特別是 HDFS,Datanode 的性能波動會對 Presto 或者 Trino 等查詢引擎的 IO 性能造成影響,讓寶貴的 CPU 資源空轉。
- 分布式計算引擎工作需要消耗較大的網絡資源,比如 shuffle。
引入緩存能夠很好地解決上述 IO 瓶頸、存儲系統性能波動的問題,還能節約寶貴的網絡資源。

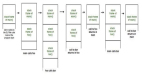
上圖顯示了 Alluxio Edge 的參考架構。當有一個 Trino 工作節點時,Alluxio Edge 會在 Trino 工作節點嵌入一個本地緩存。Trino 工作節點和 Alluxio Edge 在數量上是一一對應的。通常,一個 Trino 集群中包含很多 Trino Worker 節點,所以也會有多個 Alluxio Edge。Alluxio Edge 會利用本地節點的存儲資源緩存數據,因此當 Trino 從 S3 等存儲系統訪問數據時,數據會經過 Alluxio Edge,并被 Alluxio Edge 自動緩存在本地的存儲中。Alluxio Edge 提供了一個 Dashboard,來匯總整個 Trino 集群中所有 Alluxio Edge 的統計信息,并在儀表板中匯總、顯示諸如集群信息、成本節約、資源狀態之類的內容。
經過測試發現,Alluxio Edge 使端到端查詢的性能提高了大約 1.5 倍到 10 倍。在僅有 IO 的查詢上,能夠觀察到 10 到 50 倍的 IO 速度提升。不僅如此,我們還看到,云存儲 API 的調用在使用 Alluxio Edge 后減少了 50% 到 90%。有的時候,如果有大量請求同時發送到 S3,S3 可能會出現流量限制,其他的對象存儲也會有相同的限流行為來保證系統的整體公平性和穩定性。當限流出現時,查詢性能會變得不穩定。通過使用 Alluxio Edge 數據緩存,有助于減少網絡擁塞和存儲系統需要接受的請求數量,因此也有助于減輕底層存儲的負載。
2、Alluxio Edge 的主要功能

Alluxio Edge 的設計目標是提供一個數據處理和分析場景下的邊緣緩存解決方案。主要功能如下:
- 利用本地 SSD 或內存進行數據緩存,以提供更快的數據訪問速度。當數據緩存在本地磁盤或者內存中時,數據的重復讀取將不再訪問底層存儲。底層存儲的性能不穩定或者強負載已經嚴重影響它的性能的時候,本地緩存的效果會非常明顯。
- Alluxio Edge 支持多種現代數據湖連接器,包括 Iceberg、Hudi、DeltaLake 和 Hive。這意味著,無論您的數據是存儲在哪個數據湖解決方案中,Alluxio Edge 都能與之兼容。這個功能大大擴展了 Alluxio Edge 的使用場景和可用范圍。
- Alluxio Edge 支持廣泛的數據格式,圖中只列出了一部分,其實 Alluxio Edge可以支持任何 PrestoDB 和 Trino 所支持的數據格式。這為用戶提供了巨大的靈活性,使用戶能夠在不同的數據格式之間進行選擇。
- Alluxio Edge 支持靈活的緩存驅逐和使用策略。默認情況下,它支持 LRU 和 FIFO 策略。LRU (Least Recently Used) 是一個常見的緩存替換策略,當緩存空間占滿時,這個策略會驅逐最近最少使用的數據。FIFO (First-In-First-Out) 如其名所示,會驅逐最先進入緩存的數據。用戶還可以根據其特定的需求和場景定義自己的緩存替換策略。Alluxio Edge 也支持 TTL (Time To Live)。使用 TTL 后,過期數據會被優先驅逐。Alluxio Edge 的“數據配額”功能可以確保緩存不會超出為其分配的特定大小或配額的存儲空間。
3、Alluxio Edge 是如何工作的

Alluxio Edge 的大致工作原理如下(以 Trino 為例):
當 Trino 通過連接器(比如 Hudi)嘗試訪問數據時,它將請求 AlluxioCachingFileSystem。如果 AlluxioCachingFileSystem 檢查后發現緩存被命中了,那么,它會通過緩存管理器(AlluxioCacheManager)從本地 SSD 或內存中訪問數據;如果緩存并未命中,請求則會被發送到 UnderFileSystem 中,UnderFileSystem 負責從存儲系統中(例如 S3、HDFS 等)訪問數據。在數據被讀取后,AlluxioCachingFileSystem 會通過 AlluxioCacheManager 異步緩存數據。
此外,這里提到的對象如 AlluxioCachingFileSystem、AlluxioCacheManager 都是在集群啟動過程中,加載到 Trino Worker 進程中的,它們成為了 Alluxio Trino Worker 進程的一部分。所以,計算節點對緩存的讀取完全是在進程內部進行的,效率非常高。
4、Alluxio Edge 相關的技術挑戰

- 數據一致性
底層存儲中的文件在被緩存后,有可能被更新。Hive 上的文件出現不一致的情況比較少,但是在使用了 Hudi 等組件后,upsert 操作的頻率大大增加,使得文件更新的頻率加快,底層存儲和緩存中的數據一致性問題亟待解決。為了解決數據一致性的問題,引入了 page versioning 的概念,把文件的 modification time 作為文件的 page 的版本號。在使用緩存數據之前,Alluxio Edge 會檢查 page 的版本號,只有在版本一致的情況下,緩存數據才被使用。
- 數據本地性
默認情況下,數據會被緩存在任意的 worker 節點上。如果緩存的位置是不固定的,Coordinator 很難判斷應該把 split 派給哪個 worker。“軟親和”用來解決這個問題。軟親和開啟后,數據可以固定地緩存在某個節點上。Coordinator 在分派 split 的時候,優先選擇可能會有緩存數據的 worker。由于是“軟”親和,所以這個分派不是固定的:如果可能會有緩存數據的 worker 比較繁忙,coordinator 會選擇最“閑”的 worker 分派 split,這樣雖然損失了數據本地性,但是平衡了 worker 之間的工作負載。另外,即使緩存能夠穩定地找到某個 worker 節點,也要考慮 worker 節點變化的情況。比如,原來的 worker 下線了,或者新的 worker 上線了,要避免其他 worker 重新緩存數據。一致性哈希技術用來解決 worker 節點變化的問題。
- 緩存利用率
由于一段時期內需要訪問的全量數據總是遠遠大于熱數據,而緩存的資源又是有限的,如果對所有的數據不加限制地進行緩存,會造成數據頻繁被驅逐,緩存命中率不高的結果。解決這個問題的辦法是使用緩存過濾策略。即用戶在緩存過濾策略中定義“庫、表、分區的 TTL”。只有滿足策略的數據才被緩存。通過這個辦法,緩存資源可以有效地存放熱數據,大大增加了緩存命中率。
5、TPC-DS Benchmark 測試

對 Alluxio Edge 的效果,我們首先做了充分的內部測試。測試時,我們使用了TPC-DS 作為測試數據集和 SQL 集。在所有其他條件都相同的情況下,我們比較了使用 Alluxio Edge 和直接讀 S3 兩種方式,結果顯示:
在性能方面,所有查詢時間大于 2 秒的 73 個查詢中,70 個查詢有明顯的加速效果;所有查詢執行時間的平均值提高了 63%。左圖中,紅色部分是 S3 直讀的查詢運行時間,藍色部分是使用了 Alluxio Edge 作為本地緩存后查詢的運行時間,藍色部分明顯小于紅色部分。
在成本節約方面,S3 API 的請求數和數據傳輸量有肉眼可見的減少。右圖來自 AWS CloudWatch 監控系統提供的 S3 對象存儲的相關指標,每個圖中有兩部分線段,前一部分的線段是使用 Alluxio Edge 時,API 調用和下載數據量的指標,后一部分是 S3 直讀的(API 調用和下載數據量)指標。可以看到,這些 Alluxio Edge 對應的指標遠遠優于直讀 S3 對應的指標。
6、應用實例

Uber 在三個集群,共 1500 個節點上部署了 Alluxio Edge。在他們的使用中,觀察到端到端的輸入-讀取性能提高了 50%,而對 HDFS 的數據讀取流量減少了 10%。到 GCS 的讀取請求有 80% 被避免了。而且,查詢延遲的 90 分位數從 228 秒減少到了 50 秒。

在新加坡某電商用戶的測試環境中,Alluxio Edge 使查詢延遲降低了 40%,同時 IO 吞吐量增加了 10 倍。
7、Alluxio Edge Dashboard

Alluxio Edge 為用戶提供了一個本地部署的 dashboard。這個 dashboard 對 Trino/PrestoDB 上所有的 Alluxio Edge 節點收集的指標進行集中化匯總和展示。提供的信息包括集群摘要、成本節省、資源使用狀態等。通過使用這個 Dashboard,用戶可以了解當前 Alluxio Edge 的狀態,比如緩存空間有多少、使用了多少;Alluxio Edge 幫助用戶節約了多少數據訪問成本,比如一共多少 S3 API 被調用、多少 S3 API 調用實際產生了費用;還有資源狀態指標,如果看到峰值,可能會發現系統出了問題。有了這個儀表板,用戶可以輕松地了解節約的成本,并獲得具有洞察力的調優信息。
三、Alluxio Edge 最佳實踐場景

- 用戶需要正在或者準備使用 Trino 或者 PrestoDB。
- 用戶想要提升性能或者控制成本。
- 探索如何優化 Trino 或者 PrestoDB 的時候,不要忘記考慮 Alluxio Edge。
四、Alluxio Edge 使用流程
Alluxio Edge 的使用非常簡便,基本流程如下:
第一步
- 從網站(www.alluxio.com.cn)下載 Alluxio Edge 的 tarball
- 將其放入計算引擎的相關路徑中
- 運行查詢并比較查詢性能的變化
- 啟動本地 dashboard 查看成本節省指標
第二步
- 使用本地儀表板進行持續的觀測和優化
五、問答環節
Q1:小規模的集群、數據量的場景下,是不是推薦使用 Alluxio Edge 呢?
A1:在剛才我們分享的實戰場景中,比如 Uber 的例子和新加坡電商的例子,那些用戶的體量都很大,具體來說,他們的集群大小、數據量、任務數等都很大。所以,一方面,Alluxio Edge 是經受過大規模實戰場景的打磨的。另一方面,對于這些用戶,10% 甚至 1% 的性能提升或者成本控制都非常可觀。而 Alluxio Edge 為這些用戶實際帶來了遠超 10% 的增益,結果是非常令人激動的。在小規模的場景中,用戶可以分析一下自己的數據類型,比如熱數據的占比是否可觀,看一下自己的可用資源的情況,比如 SSD 的可用資源和熱數據的大小的比例。如果熱數據有一定的占比,并且有足夠的本地緩存資源,用戶應該嘗試一下 Alluxio Edge,畢竟 Alluxio Edge 的使用非常簡單。一旦任務的規模增加,它的價值能夠很快體現。:
Q2:如果 Trino 或者 PrestoDB 的本地資源有限怎么辦?
A2:在這種情況下,您可以考慮使用多級緩存。例如,使用 Alluxio System 作為 L2 緩存,配合 Alluxio Edge 一起工作。和 Alluxio Edge 相比,Alluxio System 的特點是:(1)它是一個獨立的系統并且可以橫向擴展,所以它可以緩存比 Alluxio Edge 更多的數據;(2) 它的數據可以被不同的 worker 節點或不同的 Trino 或 Presto DB 集群共享,甚至被其他計算引擎共享。即使 Alluxio System 存在的情況下,Alluxio Edge 仍然有優勢,因為它是計算引擎的一部分(嵌入式緩存),緩存性能更高。
Q3:緩存空間的大小如何影響緩存的性能和成本節約的增益?
A3:如果緩存大小太小,緩存未命中率會更高,緩存數據會被更頻繁地驅逐,從而收益會減少。理想情況下,本地存儲容量應該能夠容納在一段時間內訪問的大部分熱數據。如果熱數據存在并且可以被識別,那么可以相應地分配或調整緩存存儲大小。