自己發基準自己第一,Anyscale行為惹社區吐槽
前一天發布 LLMPerf 排行榜,宣稱要推動大型語言模型推理領域的發展,鼓勵創新與超越。
第二天就收獲 AI 社區的大量吐槽,原因是排行榜的「基準甚至沒有得到很好的校準」。
這是 Anyscale 這家初創公司正在經歷的事情。
Anyscale 是一家專注分布式計算領域的美國初創公司,雖然創立僅三年時間,但卻收獲了不少的關注。
首先就是 Anyscale 旗下開源項目 Ray 帶來的光環。Ray 是一個開源的分布式計算框架,可以將 AI/ML 和 Python 的 workload 從單機拓展至多臺計算機上,從而提高 workload 的運行效率,目前已經在 Github 上收獲了兩萬多個 Star。帶動了最新一波大模型熱潮的 ChatGPT,也是基于 Ray 框架訓練的。
還有一部分原因是創始團隊的光環。這家初創公司的創始人之一、UC 伯克利教授 Ion Stoica 是市值 310 億美元的數據巨頭 Databricks 的聯合創始人,他在十年前帶領學生創立了 Databricks,收獲了商業上的巨大成功。在 2019 年,他又一次做出了創業的決定 ——Anyscale 誕生了。公司創始團隊中的 CEO Robert Nishihara 和 CTO Philipp Moritz ,也都是他在伯克利的學生。此外,伯克利教授 Michael I. Jordan 也參與了 Anyscale 的創業。
這些要素,都讓人們在 Anyscale 身上看到了 Databricks 的影子,一些投資者將 Anyscale 描述為充滿希望的「下一個 Databricks」
2021 年 12 月,Anyscale 完成了 1 億美元的 C 輪融資,估值達到 10 億美元,投資者包括 a16z、Addition、NEA、Intel 等。今年 8 月,Addition 和 Intel 又共同牽頭追加了新一輪 9,900 萬美元投資。

這應該是一個前景光明的技術團隊。而此次被吐槽事件的經過是這樣的:
11 月初,Anyscale 發布過一個開源大模型推理基準,叫做「LLMPerf」。這個基準是為了方便廣大研究者評估 LLM API 性能。
三天前,Anyscale 在上述工作的基礎上,推出了 LLMPerf 排行榜。

排行榜地址:https://github.com/ray-project/llmperf-leaderboard
Anyscale 稱,他們已經利用 LLMPerf 對一些 LLM 推理提供商進行了基準測試,評估大模型性能、可靠性、效率的關鍵指標包括以下三點:
- 第一個 token 的時間(TTFT),表示 LLM 返回第一個 token 的持續時間。TTFT 對于聊天機器人等流媒體應用尤為重要。
- token 間延遲:連續 token 之間的平均時間。
- 成功率:推理 API 在無錯誤的情況下成功響應的比例。由于服務器問題或超出速率限制,可能會出現失敗,這反映了 API 的可靠性和穩定性。
但 Anyscale 曬出的這些測評結果引發了不小的爭議,比如 TTFT 這一項指標,對于不同規模的模型,Anyscale 都是第一名。
70B Models:
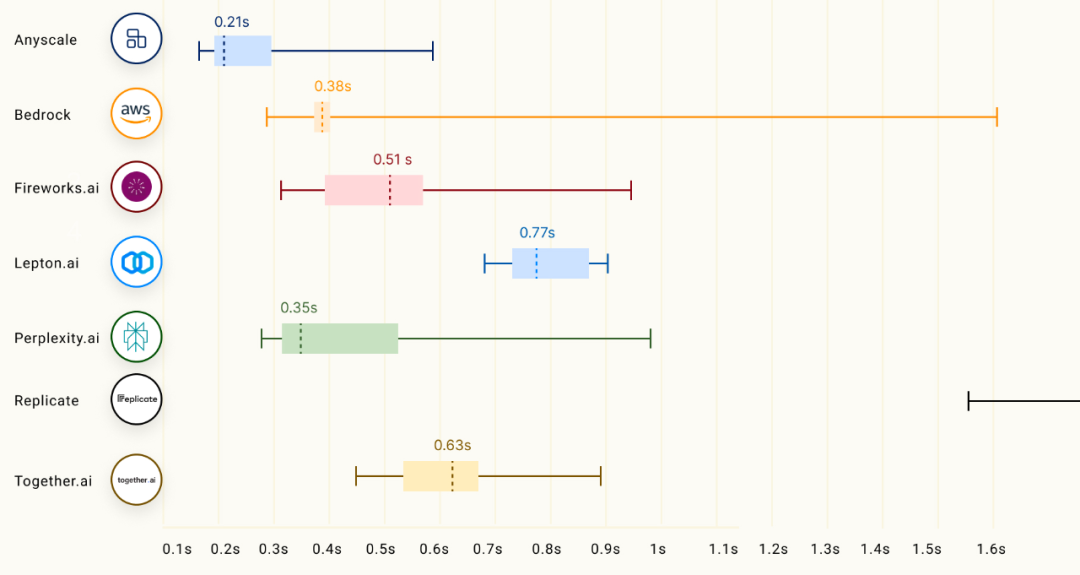
13B Models:
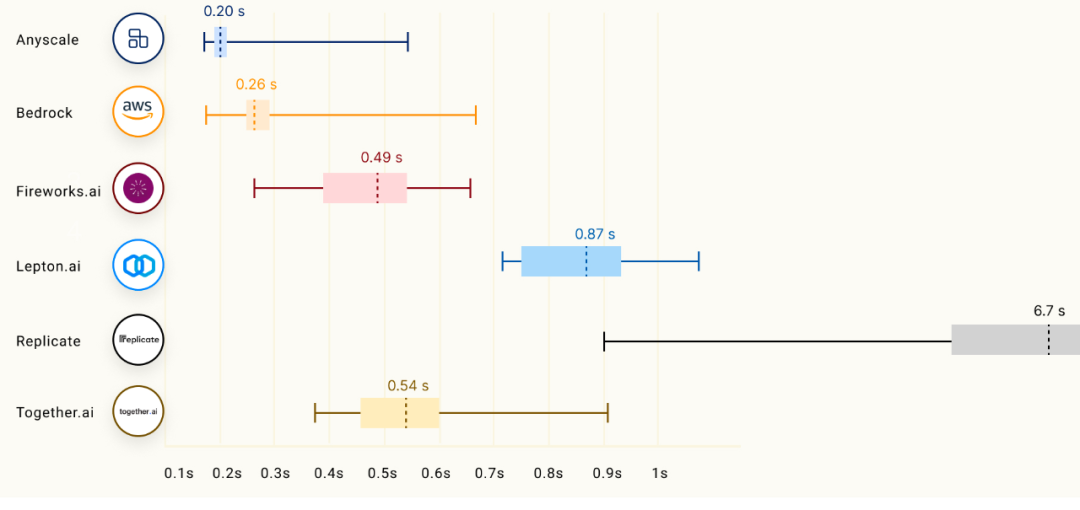
7B Models:
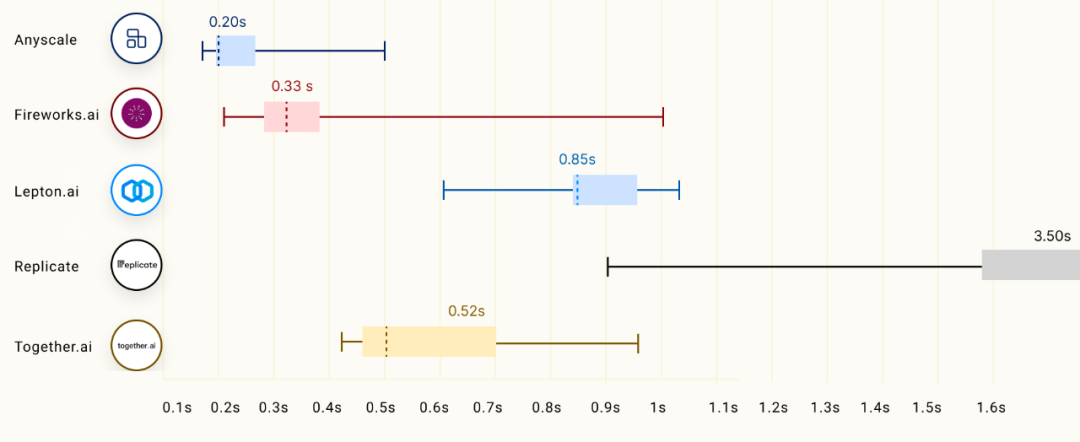
后兩項指標的測評結果中,Anyscale 也顯示出「遙遙領先」的水準。
面對這么多優秀對手,Anyscale 真的能實現「吊打」嗎?圖中結果令人懷疑。
對此,PyTorch 創始人 Soumith Chintala 表示:「看到來自可靠來源的構建不佳的基準讓我感到痛苦。我希望 Anyscale 能夠解決問題,并在發布此類基準之前咨詢其他利益相關者。如果我不是很了解 Anyscale,我會認為這是惡意行為。」
問題出在哪里呢?Soumith Chintala 認為,這個基準沒有得到很好的校準,「它僅在很短的時間內展示了復雜問題的一個方面」。
至少,用戶需要了解多個附加因素:1. 服務的每個 token 成本;2. 吞吐量,而不僅僅是延遲;3. 在一段時間內測量的可靠性、延遲和吞吐量,而不僅僅是突發可靠性,突發可靠性可能會根據一天中的時間而有很大變化。
此外,Anyscale 應該明確標記該基準是有偏見的,因為 Anyscale 正在管理它,或者向其他利益相關者開放基準的設計和治理,即開放治理,而不僅僅是開源。試圖制定和控制標準并不好。
「基準游戲」并不新鮮,曾經的數據庫之戰、大數據之戰、機器學習框架之戰都涉及到各種投機取巧的基準測試,僅僅為了更好地展示自己。
兩位 AI 學者陳天奇和賈揚清也回憶起,那些年關于「基準游戲」的故事:

作為 LeptonAI 的創始人,賈揚清還分析了 Anyscale 發布的大模型推理排行榜為什么不夠合理:
作為 AI 框架領域的資深人士,請允許我分享一個故事。在圖像模式時代,每個人都想成為 「最快的框架」,為了讓自己的速度快上 2%,不惜犧牲很多其他因素。
有一個框架從來都不是最快的。猜猜它是什么?
這個框架的名字叫 PyTorch。直到今天,PyTorch 仍然不是最快的框架,這是我從同事 Soumith Chintala 身上學到的重要一課。這是一個有意識的選擇,以確保不會過度優化單一(或少數)標準。
我為 Anyscale 制作基準測試而鼓掌,恕我直言,這是一個誠實、用心良苦的基準測試,卻存在嚴重錯誤和不明確的參數。比如,在引擎蓋下運行這些服務的是什么 GPU?
但是,既然性能比較不可避免,那我就把結果公布出來吧。
在 Anyscale 在 10 月份發布的一篇帖子中,曾對比過三家 API 的推理性能。賈揚清曬出了一張 Lepton API 與這三家 API 的對比圖片:
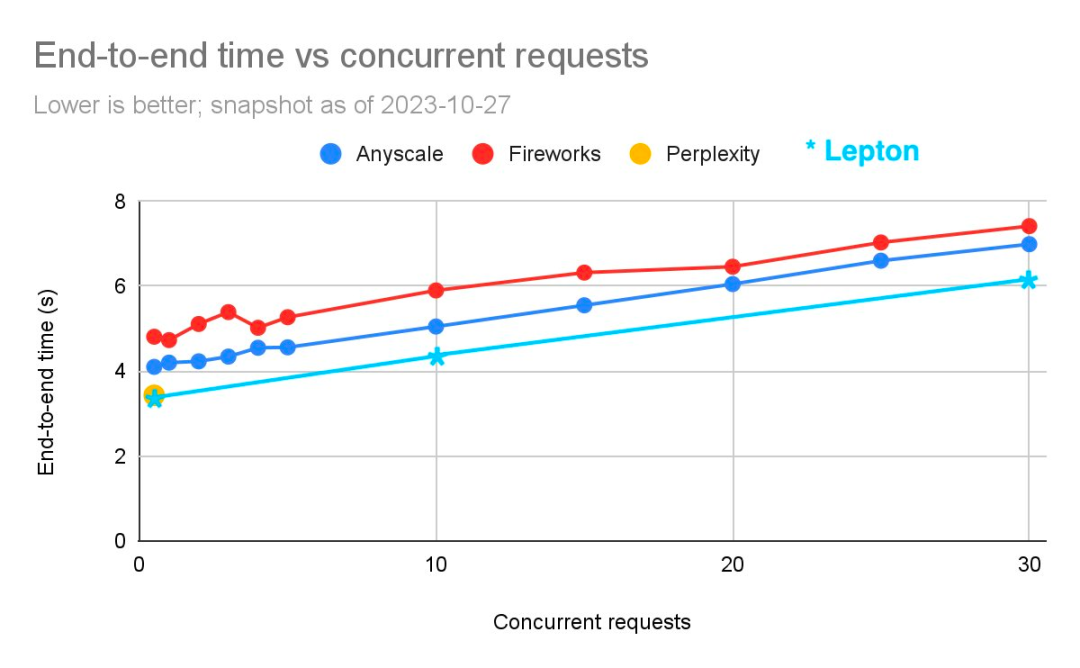
基準數據來源:https://anyscale.com/blog/reproducible-performance-metrics-for-llm-inference
「原始數據不是由 Anyscale 發布的,因此我們不得不在帖子中的原始圖片上疊加圖表。很抱歉把這些東西拼湊在一起。」賈揚清表示:「我們并不打算用它來衡量誰是最快的,只是想證明我們是名列前茅的。」
除了賈揚清,其他「被上榜」的 API 所屬團隊也提出了質疑。
比如 FireworksAI 聯合創始人、CTO Dmytro Dzhulgakov:
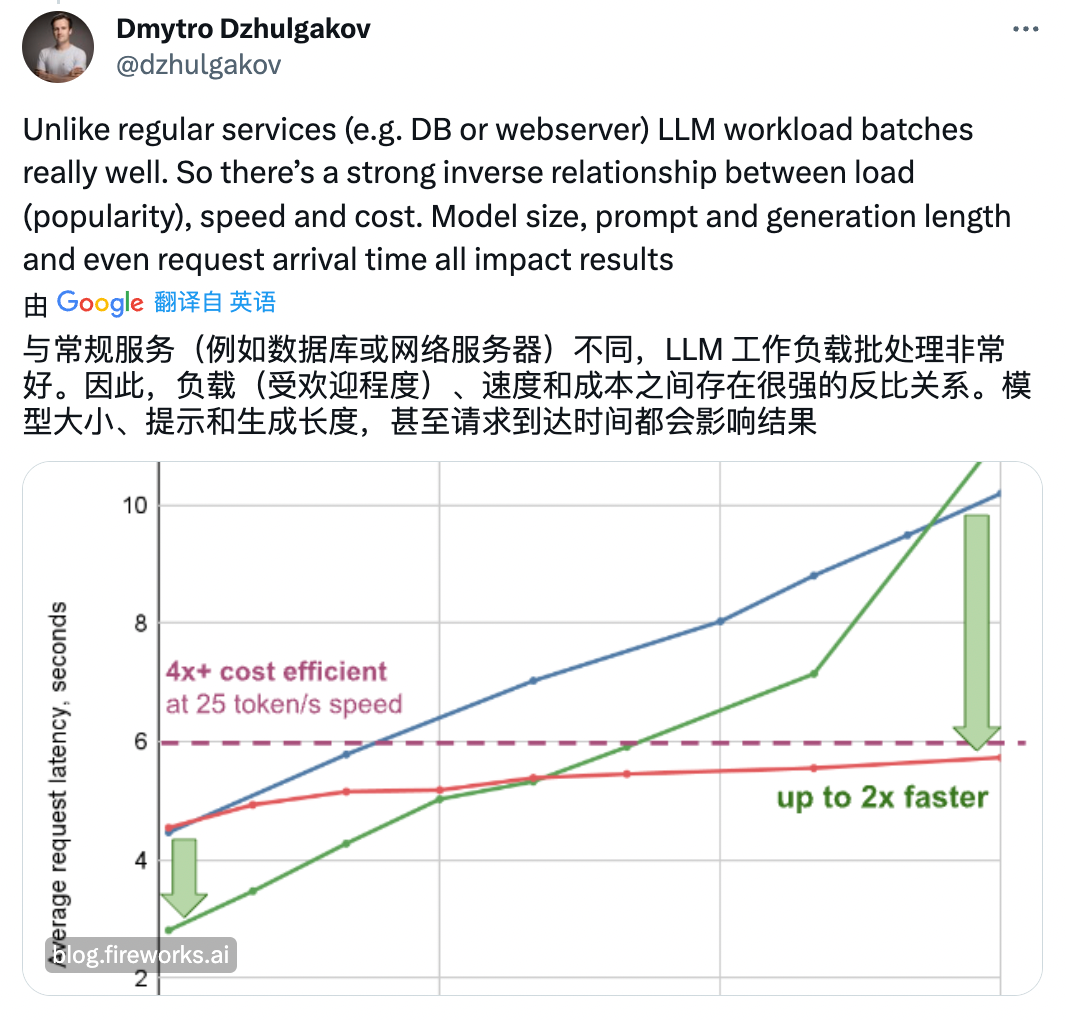
TogetherAI 的 CEO 表示:「Anyscale 是為了清洗他們 API 糟糕性能進行的基準測試。」

多方質疑之下,Anyscale 的 CEO 親自回應了基準的缺陷問題:
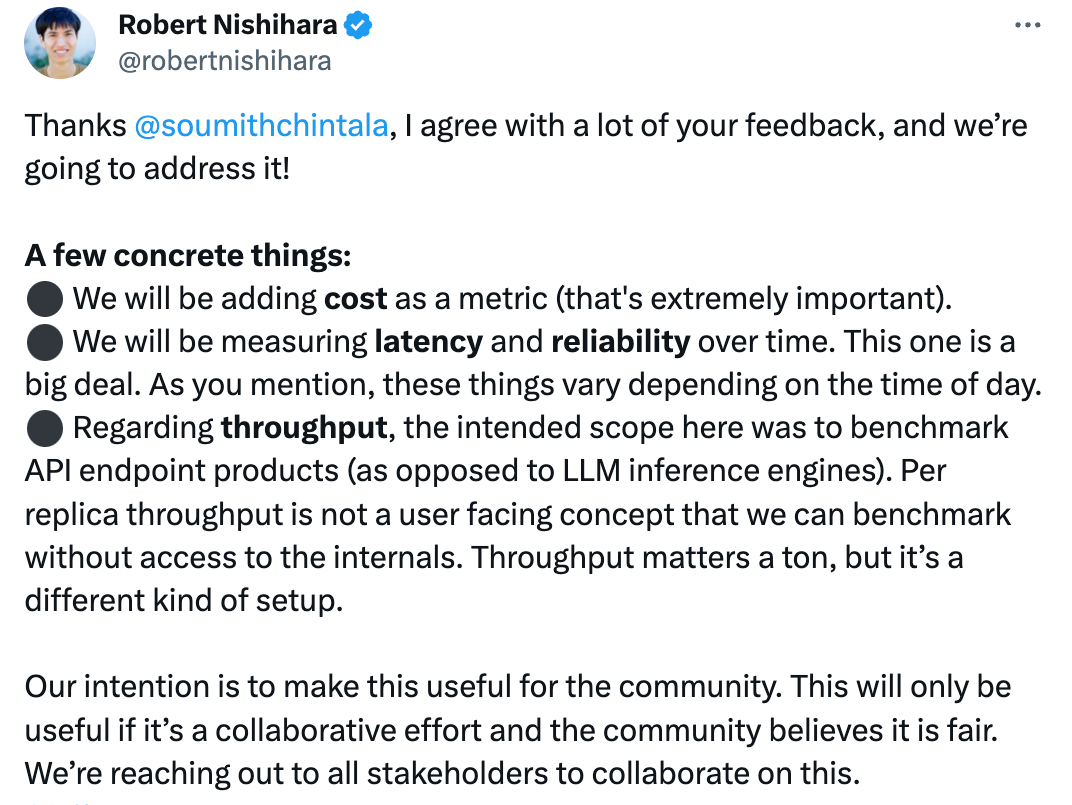
我同意你的很多反饋,我們將解決它!
一些具體的事情:
我們將添加成本作為一個指標(這非常重要)。
我們將隨著時間的推移測量延遲和可靠性。正如您提到的,這些事情根據一天中的時間而變化。
關于吞吐量,此處的預期范圍是對 API 端點產品進行基準測試(而不是 LLM 推理引擎)。每個副本的吞吐量不是一個面向用戶的概念,我們可以在不訪問內部的情況下進行基準測試。吞吐量非常重要,但這是一種不同的設置。
我們的目的是使其對社區有用。僅當其成為共同努力并且社區認為這是公平時,它才會有用。我們正在與所有利益相關者聯系以就此進行合作。
與此同時,Anysacle 也在邀請各位 API 提供商共同參于排行版的「修正」:


對于此事,你怎么看?