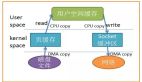
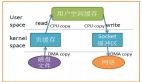
使用懶加載 + 零拷貝后,程序的秒開率提升至99.99%

一、5秒鐘加載一個頁面的真相
今天在修改前端頁面的時候,發現程序中有一個頁面的加載速度很慢,差不多需要5秒,這其實是難以接受的,我也不知道為什么上線這么長時間了,沒人提過這個事兒。
我記得有一個詞兒,叫秒開率。
秒開率是指能夠在1秒內完成頁面的加載。
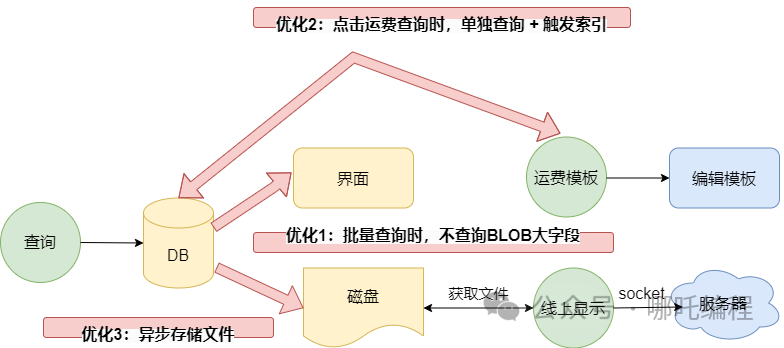
查詢的時候,會訪問后臺數據庫,查詢前20條數據,按道理來說,這應該很快才對。
追蹤代碼,看看啥問題,最后發現問題有三:
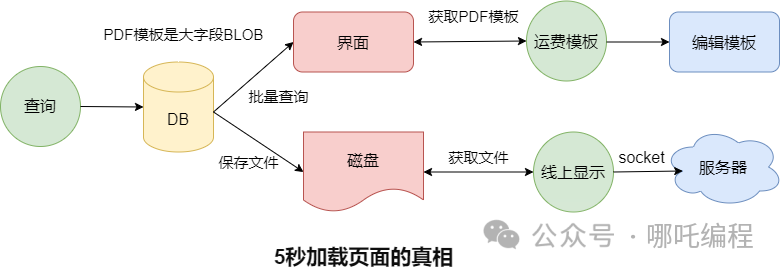
- 表中有一個BLOB大字段,存儲著一個PDF模板,也就是上圖中的運費模板。
- 查詢后會將這個PDF模板存儲到本地磁盤。
- 點擊線上顯示,會讀取本地的PDF模板,通過socket傳到服務器。
大字段批量查詢、批量文件落地、讀取大文件并進行網絡傳輸,不慢才怪,這一頓騷操作,5秒能加載完畢,已經燒高香了。
二、優化四步走
1、“懶加載”
經過調查發現,這個PDF模板只有在點擊運費模板按鈕時才會使用。
- 優化1: 在點查詢按鈕時,不查詢PDF模板。
- 優化2: 點擊運費模板時,根據uuid去查詢,這樣既能觸發索引,也不用按時間排序,只是查詢單條,速度快了很多很多,我愿稱你為“懶加載”。
- 優化3: 通過異步,將文件保存到磁盤中。
2、線上顯示 = 就讀取一個文件,為什么會慢呢?
打開代碼一看,居然是通過FileReader讀取的,我了個乖乖~
這有什么問題嗎?都是從百度拷貝過來的,百度還會有錯嗎?而且也測試了,沒問題啊。
嗯,對,是沒問題,是可以實現需求,可是,為什么用這個?不知道。更別說效率問題了~
優化4:通過緩沖流讀取文件。
三、先從上帝視角,了解一下啥子是IO流
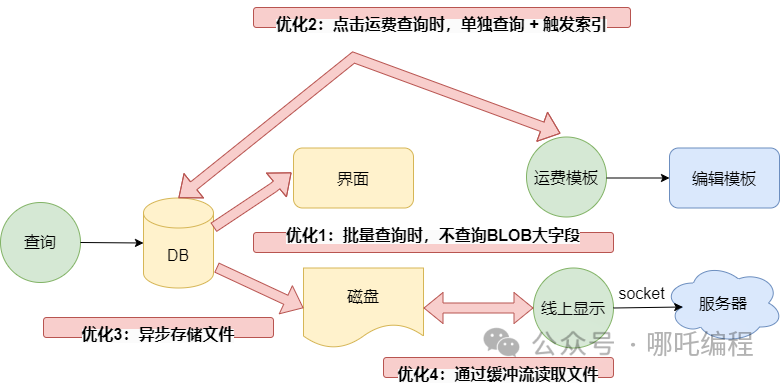
Java I/O (Input/Output) 是對傳統 I/O 操作的封裝,它是以流的形式來操作數據的。
- InputStream 代表一個輸入流,它是一個抽象類,不能被實例化。InputStream 定義了一些通用方法,如 read() 和 skip() 等,用于從輸入流中讀取數據。
- OutputStream 代表一個輸出流,它也是一個抽象類,不能被實例化。OutputStream 定義了一些通用方法,如 write() 和 flush() 等,用于向輸出流中寫入數據。
- 除了字節流,Java 還提供字符流,字符流類似于字節流,不同之處在于字符流是按字符讀寫數據,而不是按字節。Java 中最基本的字符流是 Reader 和 Writer,它們是基于 InputStream 和 OutputStream 的轉換類,用于完成字節流與字符流之間的轉換。
- BufferedInputStream 和 BufferedOutputStream 是 I/O 包中提供的緩沖輸入輸出流。它們可以提高 I/O 操作的效率,具有較好的緩存機制,能夠減少磁盤操作,縮短文件傳輸時間。使用 BufferedInputStream 和 BufferedOutputStream 進行讀取和寫入時,Java 會自動調整緩沖區的大小,使其能夠適應不同的數據傳輸速度。
- 可以讀取或寫入 Java 對象的流,比較典型的對象流包括ObjectInputStream 和 ObjectOutputStream,將 Java 對象轉換為字節流進行傳輸或存儲。
在上一篇 《增加索引 + 異步 + 不落地后,從 12h 優化到 15 min》中,提到了4種優化方式,數據庫優化、復用優化、并行優化、算法優化。
其中Buffered緩沖流就屬于復用優化的一種,這個頁面的查詢完全可以通過復用優化優化一下。
四、寫個栗子,測試一下
1、通過字符輸入流FileReader讀取
FileReader連readLine()方法都沒有,我也是醉了~
private static int readFileByReader(String filePath) {
int result = 0;
try (Reader reader = new FileReader(filePath)) {
int value;
while ((value = reader.read()) != -1) {
result += value;
}
} catch (Exception e) {
System.out.println("readFileByReader異常:" + e);
}
return result;
}2、通過緩沖流BufferedReader讀取
private static String readFileByBuffer(String filePath) {
StringBuilder builder = new StringBuilder();
try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {
String data = null;
while ((data = reader.readLine())!= null){
builder.append(data);
}
}catch (Exception e) {
System.out.println("readFileByReader異常:" + e);
}
return builder+"";
}通過循環模擬了150000個文件進行測試,FileReader耗時8136毫秒,BufferedReader耗時6718毫秒,差不多相差1秒半的時間,差距還是相當大的,俗話說得好,水滴石穿。
同樣是read方法,只不過是包了一層,有啥不同呢?
BufferedReader 是一個緩沖字符輸入流,可以對 FileRead 進行包裝,提供了一個緩存數組,將數據按照一定規則讀取到緩存區中,輸入流每次讀取文件數據時都需要將數據進行字符編碼,而 BufferedReader 的出現,降低了輸入流訪問數據源的次數,將一定大小的數據一次讀取到緩存區并進行字符編碼,從而提高 IO 的效率。
如果沒有緩沖,每次調用 read() 或 readLine() 都可能導致從文件中讀取字節,轉換為字符,然后返回,這可能非常低效。
就像取快遞一樣,在取快遞的時候,肯定是想一次性的取完,避免再來一趟。
- FileReader就相當于一件一件的取,樂此不疲;
- BufferedReader就相當于,你盡可能多的拿你的快遞,可是這也有個極限,比如你一次只能拿5件快遞,這個 5 就相當于緩沖區,效率上,提升數倍。
對 FileRead 進行包裝變成了BufferedReader緩沖字符輸入流,其實,Java IO流就是最典型的裝飾器模式,裝飾器模式通過組合替代繼承的方式在不改變原始類的情況下添加增強功能,主要解決繼承關系過于復雜的問題,之前整理過一篇裝飾器模式,這里就不論述了。
3、再點進源碼瞧瞧。
(1)FileReader.read()源碼很簡單,就是直接讀取
public int read(char cbuf[], int off, int len) throws IOException {
return in.read(cbuf, off, len);
}(2)BufferedReader.read()的源碼就較為復雜了,看一下它的核心方法fill()
private void fill() throws IOException {
int dst;
if (markedChar <= UNMARKED) {
/* No mark */
dst = 0;
} else {
/* Marked */
int delta = nextChar - markedChar;
if (delta >= readAheadLimit) {
/* Gone past read-ahead limit: Invalidate mark */
markedChar = INVALIDATED;
readAheadLimit = 0;
dst = 0;
} else {
if (readAheadLimit <= cb.length) {
/* Shuffle in the current buffer */
System.arraycopy(cb, markedChar, cb, 0, delta);
markedChar = 0;
dst = delta;
} else {
/* Reallocate buffer to accommodate read-ahead limit */
char ncb[] = new char[readAheadLimit];
System.arraycopy(cb, markedChar, ncb, 0, delta);
cb = ncb;
markedChar = 0;
dst = delta;
}
nextChar = nChars = delta;
}
}
int n;
do {
n = in.read(cb, dst, cb.length - dst);
} while (n == 0);
if (n > 0) {
nChars = dst + n;
nextChar = dst;
}
}核心方法fill():
- 字符緩沖輸入流,底層有一個8192個元素的緩沖字符數組,當緩沖區的內容讀完時,將使用 fill() 方法從硬盤中讀取數據填充緩沖數組。
- 字符緩沖輸出流,底層有一個8192個元素的緩沖字符數組,使用flush方法將緩沖數組中的內容寫入到硬盤當中。
- 使用緩沖數組之后,程序在運行的大部分時間內都是內存和內存直接的數據交互過程。內存直接的操作效率是比較高的。并且降低了CPU通過內存操作硬盤的次數。
- 關閉字符緩沖流,都會首先釋放對應的緩沖數組空間,并且關閉創建對應的字符輸入流和字符輸出流。
既然緩沖這么好用,為啥jdk將緩沖字符數組設置的這么小,才8192個字節?
這是一個比較折中的方案,如果緩沖區太大的話,就會增加單次讀寫的時間,同樣內存的大小也是有限制的,不可能都讓你來干這個一件事。
很多小伙伴也肯定用過它的read(char[] cbuf),它內部維護了一個char數組,每次寫/讀數據時,操作的是數組,這樣可以減少IO次數。
(3)buffer四大屬性
- mark:標記。
- position:位置,下一個要被讀或寫的元素的索引, 每次讀寫緩沖區數據時都會改變改值, 為下次讀寫作準備。
- limit:表示緩沖區的當前終點,不能對緩沖區 超過極限的位置進行讀寫操作。且極限 是可以修改的。
- capacity:容量,即可以容納的最大數據量;在緩 沖區創建時被設定并且不能改變。
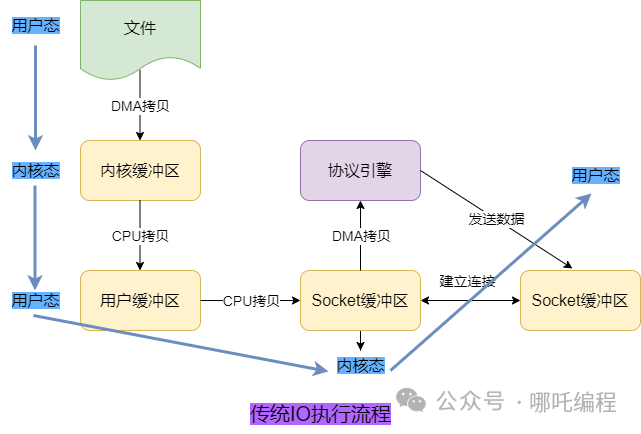
4、緩沖流:4 次上下文切換 + 4 次拷貝
傳統 IO 執行的話需要 4 次上下文切換(用戶態 -> 內核態 -> 用戶態 -> 內核態 -> 用戶態)和 4 次拷貝。
- 磁盤文件 DMA 拷貝到內核緩沖區。
- 內核緩沖區 CPU 拷貝到用戶緩沖區。
- 用戶緩沖區 CPU 拷貝到 Socket 緩沖區。
- Socket 緩沖區 DMA 拷貝到協議引擎。
五、NIO之FileChannel
NIO中比較常用的是FileChannel,主要用來對本地文件進行 IO 操作。
1、FileChannel 常見的方法有
- read,從通道讀取數據并放到緩沖區中。
- write,把緩沖區的數據寫到通道中。
- transferFrom,從目標通道 中復制數據到當前通道。
- transferTo,把數據從當 前通道復制給目標通道。
2、關于Buffer 和 Channel的注意事項和細節
- ByteBuffer 支持類型化的put 和 get, put 放入的是什么數據類型,get就應該使用 相應的數據類型來取出,否則可能有 BufferUnderflowException 異常。
- 可以將一個普通Buffer 轉成只讀Buffer。
- NIO 還提供了 MappedByteBuffer, 可以讓文件直接在內存(堆外的內存)中進 行修改, 而如何同步到文件由NIO 來完成。
- NIO 還支持 通過多個 Buffer (即 Buffer 數組) 完成讀寫操作,即 Scattering 和 Gathering。
3、Selector(選擇器)
- Java 的 NIO,用非阻塞的 IO 方式。可以用一個線程,處理多個的客戶端連 接,就會使用到Selector(選擇器)。
- Selector 能夠檢測多個注冊的通道上是否有事件發生,如果有事件發生,便獲取事件然 后針對每個事件進行相應的處理。這樣就可以只用一個單線程去管理多個 通道,也就是管理多個連接和請求。
- 只有在 連接/通道 真正有讀寫事件發生時,才會進行讀寫,就大大地減少了系統開銷,并且不必為每個連接都創建一個線程,不用去維護多個線程。
- 避免了多線程之間的上下文切換導致的開銷。
4、selector的相關方法
- open();//得到一個選擇器對象。
- select(long timeout);//監控所有注冊的通道,當其 中有 IO 操作可以進行時,將 對應的 SelectionKey 加入到內部集合中并返回,參數用來 設置超時時間。
- selectedKeys();//從內部集合中得 到所有的 SelectionKey。
六、內存映射技術mmap
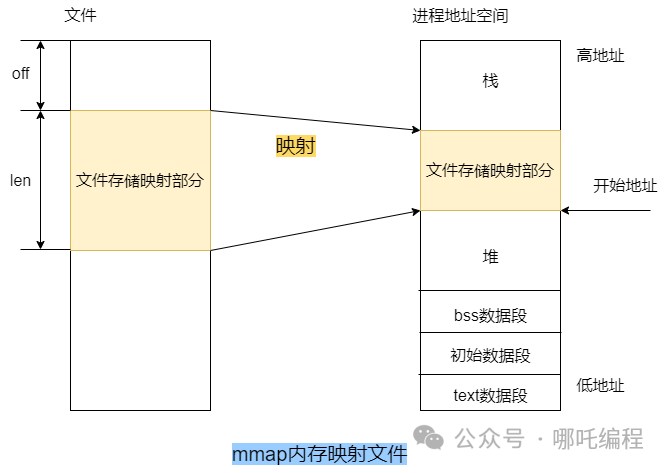
1、文件映射
傳統的文件I/O操作可能會變得很慢,這時候mmap就閃亮登場了。
mmap(Memory-mapped files)是一種在內存中創建映射文件的機制,它可以使我們像訪問內存一樣訪問文件,從而避免頻繁的文件I/O操作。
使用mmap的方式是在內存中創建一個虛擬地址,然后將文件映射到這個虛擬地址上,這個映射的過程是由操作系統完成的。
實現映射后,進程就可以采用指針的方式讀寫操作這一段內存,系統會自動回寫到對應的文件磁盤上,這樣就完成了對文件的讀取操作,而不用調用 read、write 等系統函數。
內核空間對這段區域的修改也會直接反映用戶空間,從而可以實現不同進程間的文件共享。
2、Java中使用mmap
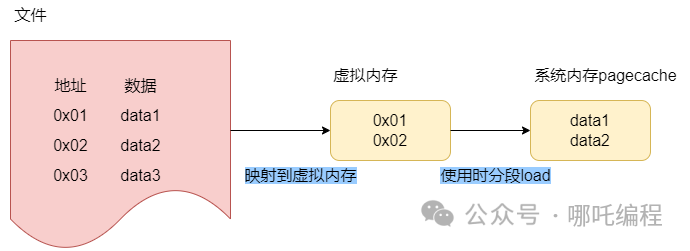
在 Java 中,mmap 技術主要使用了 Java NIO (New IO)庫中的 FileChannel 類,它提供了一種將文件映射到內存的方法,稱為 MappedByteBuffer。MappedByteBuffer 是 ByteBuffer 的一個子類,它擴展了 ByteBuffer 的功能,可以直接將文件映射到內存中。
根據文件地址創建了一層緩存當作索引,放在虛擬內存中,使用時會根據的地址,直接找到磁盤中文件的位置,把數據分段load到系統內存(pagecache)中。
public static String readFileByMmap(String filePath) {
File file = new File(filePath);
String ret = "";
StringBuilder builder = new StringBuilder();
try (FileChannel channel = new RandomAccessFile(file, "r").getChannel()) {
long size = channel.size();
// 創建一個與文件大小相同的字節數組
ByteBuffer buffer = ByteBuffer.allocate((int) size);
// 將通道上的所有數據都讀入到buffer中
while (channel.read(buffer) != -1) {}
// 切換為只讀模式
buffer.flip();
// 從buffer中獲取數據并處理
byte[] data = new byte[buffer.remaining()];
buffer.get(data);
ret = new String(data);
} catch (IOException e) {
System.out.println("readFileByMmap異常:" + e);
}
return ret;
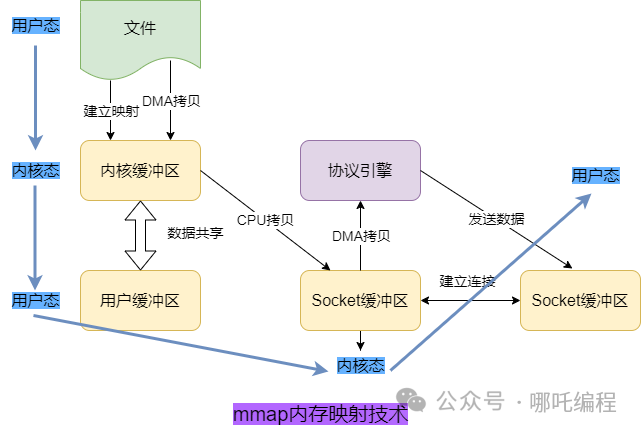
}3、內存映射技術mmap:4 次上下文切換 + 3 次拷貝
mmap 是一種內存映射技術,mmap 相比于傳統的 緩沖流 來說,其實就是少了 1 次 CPU 拷貝,變成了數據共享。
雖然減少了一次拷貝,但是上下文切換的次數還是沒變。
因為存在一次CPU拷貝,因此mmap并不是嚴格意義上的零拷貝。
RocketMQ 中就是使用的 mmap 來提升磁盤文件的讀寫性能。
七、sendFile零拷貝
零拷貝將上下文切換和拷貝的次數壓縮到了極致。
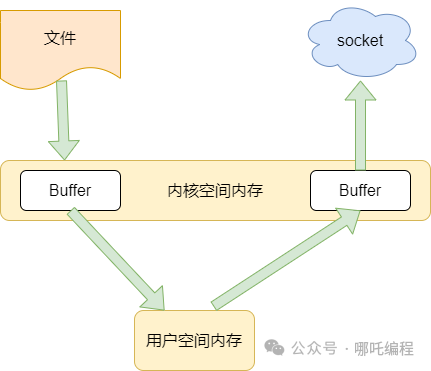
1、傳統IO流
- 將磁盤中的文件拷貝到內核空間內存。
- 將內核空間的內容拷貝到用戶空間內存。
- 用戶空間將內容寫入到內核空間內存。
- socket讀取內核空間內存,將內容發送給第三方服務器。
2、sendFile零拷貝
在內核的支持下,零拷貝少了一個步驟,那就是內核緩存向用戶空間的拷貝,這樣既節省了內存,也節省了 CPU 的調度時間,讓效率更高。
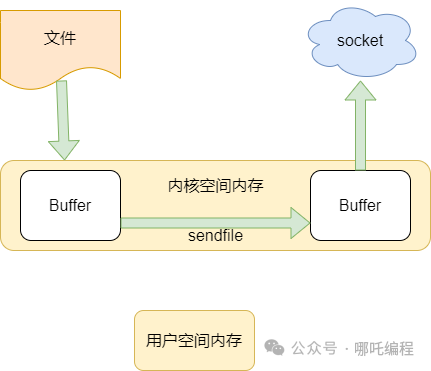
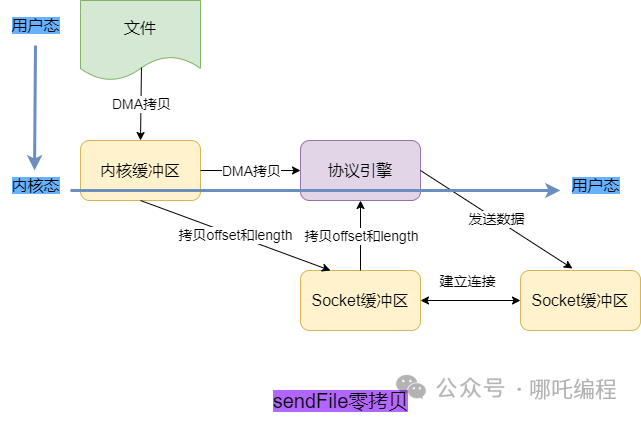
3、sendFile零拷貝:2 次上下文切換 + 2次拷貝
直接將用戶緩沖區干掉,而且沒有CPU拷貝,故得名零拷貝。
重置優化4:通過零拷貝讀取文件

八、總結
經過4次優化,將頁面的加載時間控制在了1秒以內,實打實的提升了程序的秒開率。
- 批量查詢時,不查詢BLOB大字段。
- 點擊運費查詢時,單獨查詢+觸發索引,實現“懶加載”。
- 異步存儲文件。
- 通過 緩沖流 -> 內存映射技術mmap -> sendFile零拷貝 讀取本地文件。
通過一次頁面優化,收獲頗豐:
- 通過業務優化,將BLOB大字段進行“懶加載”。
- 異步存儲文件。
- 系統的學習了Java IO流,輸入輸出流、字符流、字符流、轉換流。
- 通過NIO的FileChannel讀取文件時,較于緩沖流性能上顯著提升。
- 內存映射技術mmap 相比于傳統的 緩沖流 來說,其實就是少了 1 次 內核緩沖區到用戶緩沖區的CPU 拷貝,將其變成了數據共享。
- sendFile零拷貝,舍棄了用戶空間內存,舍棄了CUP拷貝,完美的零拷貝方案。
- 通過代碼實例,橫向對比了FileReader、BufferedReader、NIO之FileChannel、內存映射技術mmap、sendFile零拷貝之間的性能差距。