













網絡安全大模型評測平臺SecBench發布
2024年1月19日,網絡安全大模型評測平臺SecBenc正式發布,該平臺由騰訊朱雀實驗室和騰訊安全科恩實驗室,聯合騰訊混元大模型、清華大學江勇教授/夏樹濤教授團隊、香港理工大學羅夏樸教授研究團隊、上海人工智能實驗室OpenCompass團隊共同建設,主要解決開源大模型在網絡安全應用中安全能力的評估難題,旨在為大模型在安全領域的落地應用選擇基座模型提供參考,加速大模型落地進程。同時,通過建設安全大模型評測基準,為安全大模型研發提供公平、公正、客觀、全面的評測能力,推動安全大模型建設。
行業首發,彌補大模型在網絡安全垂類領域評測空白
自2022年11月ChatGPT發布以來,AI大模型在全球范圍內掀起了有史以來規模最大的人工智能浪潮,大模型的落地進程也隨之加速。然而,在網絡安全應用中,大模型研發人員如何選擇合適的基座模型,當前大模型的安全能力是否已經達到業務應用需求,都成為亟待解決的問題。
SecBench網絡安全大模型評測平臺,將重點從能力、語言、領域、安全證書考試四個維度對大模型在網絡安全領域的各方面能力進行評估,為大模型研發人員、學術研究者提供高效、公正的基座模型選型工具和研究參考。
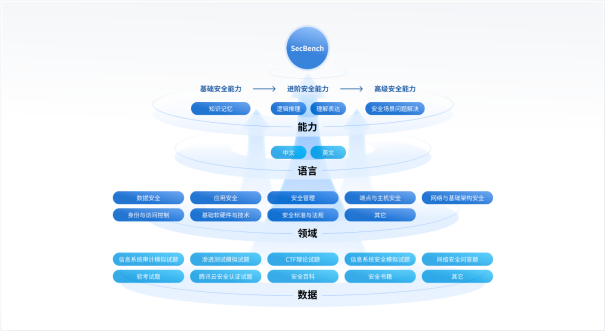
圖 1. SecBench網絡安全大模型評測整體設計架構
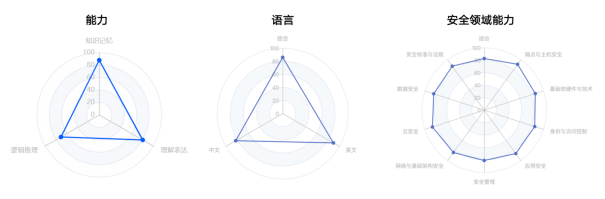
圖 2. GPT-4在能力維度、語言維度以及安全領域能力的評估結果
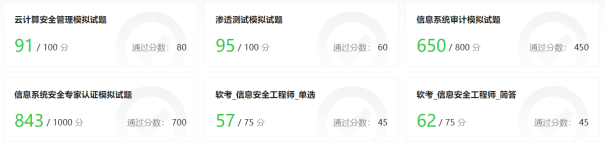
圖 3. GPT-4在各類安全證書考試中的評估結果(綠色為通過考試)
SecBench設計架構
圖1. 為SecBench網絡安全大模型評測初期規劃的架構,主要圍繞三個維度進行構建:
一是積累行業獨有的網絡安全評測數據集。評測數據是評測基準建設的基礎,也是大模型能力評測最關鍵的部分。目前行業內還沒有專門針對大模型在網絡安全垂類領域的評測基準/框架,主要原因也是由于評測收據缺失的問題。因此,構建網絡安全大模型評測基準的首要目標是積累行業內獨有的網絡安全評測數據集,覆蓋多語言、多題型、多能力、多領域,以全面地評測大模型安全能力。
二是搭建方便快捷的網絡安全大模型評測框架。“百模大戰”下,大模型的形態各異,有HuggingFace上不斷涌現的開源大模型,有類似GPT-4、騰訊混元、文心一言等大模型API服務,以及自研本地部署的大模型。評測框架如何支持各類大模型的快速接入、快速評測也很關鍵。此外,評測數據的多樣性也挑戰著評測框架的靈活性,例如,選擇題和問答題往往需要不同的prompt和評估指標,如何快速對比few shot和zero shot的差異。因此,需要搭建方便快捷的網絡安全大模型評測框架,以支持不同模型、不同數據、不同評測指標的靈活接入、快速評測。
三是輸出全面、清晰的評測結果。網絡安全大模型研發的不同階段其實對評測的需求不同。例如,在研發初期進行基座模型選型階段,通常只需要了解各類基座模型的能力排名、對比不同模型能力差異;而在網絡安全大模型研發階段,就需要了解每次迭代模型能力的變化,仔細分析評估結果等。因此,網絡大模型評測需要輸出全面、清晰的評測結果,如評測榜單、能力對比、中間結果等,以支持不同研發階段的需求。
SecBench除了圍繞上述三個目標進行建設外,還設計了兩個網絡安全特色能力:安全領域評測和安全證書考試評估。安全領域評測從垂類安全視角,評測大模型在九個安全領域的能力;安全證書考試評估支持經典證書考試評估,評測大模型通過安全證書考試的能力。
SecBench評測框架
SecBench網絡安全評測框架可以分為數據接入、模型接入、模型評測、結果輸出四個部分,通過配置文件配置數據源、評測模型、評估指標,即可快速輸出模型評測結果。
- 數據接入:在數據接入上,SecBench支持多類型數據接入,如選擇題、判斷題、問答題等,同時支持自定義數據接入及評測prompt模板定制化。
- 模型接入:在模型接入上,SecBench同時支持HuggingFace開源模型、大模型API服務、本地部署大模型自由接入,還支持用戶自定義模型。
- 模型評測:在模型評測上,SecBench支持多任務并行,加快評測速度。此外,SecBench已內置多個評估指標以支持常規任務結果評估,也支持自定義評估指標滿足特殊需求。
- 結果輸出:在結果輸出上,SecBench不僅可以將評測結果進行前端頁面展示,還可以輸出模型評測中間結果,如配置文件、輸入輸出、評測結果文件等,支持網絡安全大模型研發人員數據分析需求。
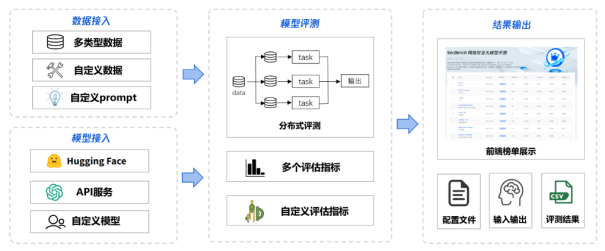
圖 4. SecBench網絡安全大模型評測框架
SecBench評測數據
網絡安全大模型的能力難以評測,主要原因之一還是網絡安全垂類數據的缺失。為了解決這一問題,SecBench目前已經收集整理了12個安全評測數據集,累計數據10000余條。
- 語言維度:覆蓋中文、英文兩類常見語言的評測。
- 能力維度:從安全視角,支持大模型對安全知識的知識記憶能力、邏輯推理能力、理解表達能力的評估。
- 領域維度:支持大模型在不同安全領域能力的評測,包括數據安全、應用安全、端點與主機安全、網絡與基礎架構安全、身份與訪問控制、基礎軟硬件與技術、安全管理等。
- 證書考試:SecBench還積累了各類安全證書模擬試題,可支持大模型安全證書等級考試評估。
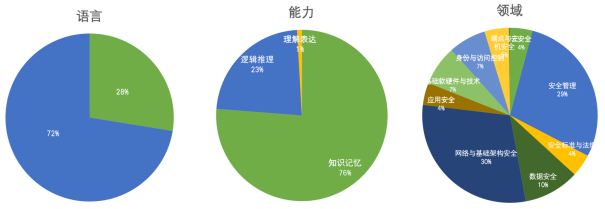
圖 5. SecBench網絡安全大模型評測數據分布
當前SecBench評測數據仍然存在多樣性不足、分布不均勻等問題,當前正在持續補充建設多題型、多能力、多維度的評測數據。
SecBench評測結果
SecBench正在逐步接入大模型進行網絡安全能力評測,目前主要針對經典GPT模型以及小規模開源模型進行評測榜單輸出。展示模型在能力、語言、安全領域不同能力維度的結果,同時支持安全等級證書考試結果輸出。后續將持續接入商用大模型、安全大模型,支持模型能力對比等能力。
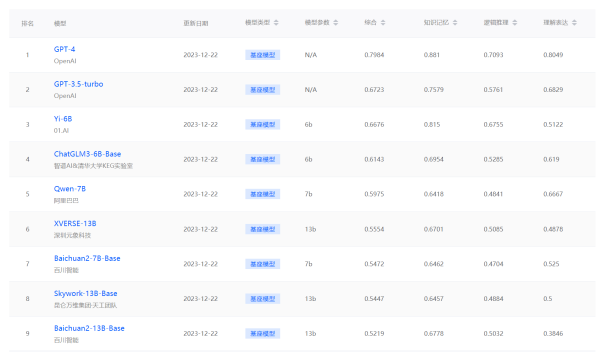
圖 6. SecBench網絡安全大模型評測榜單
隨著大模型在網絡安全領域的落地應用加速,網絡安全大模型的評測變得尤為關鍵。SecBecnch已初步建立起圍繞網絡安全垂類領域的評測能力,以更好地支持網絡安全大模型的研發及落地應用。此外為評估大模型在Prompt安全方面的表現,騰訊朱雀實驗室已聯合清華大學深圳國際研究生院,發布了《大語言模型(LLM) 安全性測評基準》。
未來展望
SecBecnch初步建立起圍繞網絡安全垂類領域的評測能力,然而還有許多需要優化迭代的地方:一是仍需持續補充構建高質量的網絡安全評測數據,覆蓋多領域、多題型,以更好地支持模型在網絡安全領域的全面評測;二是快速跟進大模型評測,對于新發布的大模型,能夠及時輸出評測結果;三是豐富模型結果呈現方式,支持模型對比、結果分析等功能,以滿足不同用戶的使用需求。SecBench也希望能夠引入更多的合作伙伴,包括學術界、工業界相關從業者,共創共贏,共同推動網絡安全大模型的發展。




















