螞蟻關于 TuGraph-DB 圖數據庫高可用架構介紹
一、高可用架構介紹
1. 高可用架構是什么
首先來看一個問題,正常訪問網絡上一個服務的流程是,提交一個 request,然后服務進行一定的處理,返回給我們一個 success 的 response。但有時會因為網絡阻塞、資源不足,甚至黑客網絡攻擊或硬件毀損等原因,導致服務不能返回一個正確的 response,那么這時作為一個線上的業務,就是不可用的,可能會造成非常巨大的損失。

2. 高可用性代表系統的可用性程度,是進行系統設計時的準則之一
怎樣去衡量系統的可用性和不可用性呢?這就引出了高可用性的概念。高可用性代表系統的可用性程度,是進行系統設計的準則之一。高可用性,是系統的一個非常重要的能力,通常是通過提高系統的容錯能力來實現的。可用性的一個度量方式是根據系統損毀無法提供服務的時間和系統正常運行時間的比值來得到的。下圖右側表格展示了衡量一個系統可用性和不可用性的等級。
TuGraph-DB 對于可用性的要求,至少是 4 個 9 級別,也就是一年之內宕機時間不能超過 53 分鐘。我們在開源之前服務的一個銀行用戶就已經達到了一個極高可用的等級,也就是 5 個 9 的等級。

3. 常用高可用架構--主備復制
以上是高可用性的定義,為了達到高可用性,就需要去設計高可用架構。比較簡單的高可用架構,就是主備復制模式。主備復制模式有一個對外提供服務的主服務器,其它服務器作為其備機。主備復制模式最重要的特點是定期復制主機的數據給備機,比如一個小時、一天。當主機宕機之后,可以通過人工手段,也可以通過 NGINX 做請求轉發等自動的方式,讓備節點成為主節點。
這種模式非常簡單,只復制數據,也因為客戶只通過 URL 訪問對應的服務,因此是沒有感知的。但其弊端是需要人工干預,而更重要的問題是可能會丟失部分數據。不管以多快的頻率進行備份,一個小時,甚至十幾分鐘,都可能會丟失一部分數據,也就無法達成高可用的要求。這種模式比較適合于管理系統,比如學生管理系統,沒有高頻率的寫更新。MySQL、Redis、Mongodb 的高可用架構,基本上官方開源提供的都是這種模式。

4. TuGraph-DB 高可用架構—Raft 共識算法
針對上述缺點,我們選用了 Raft 算法來實現高可用架構。Raft 算法的優點包括:
- 首先,它保持了一主多備的易用性。它有一個強 leader 可以對外提供服務。
- 第二是一致性。一主多備的模式是通過定期復制的方式去進行數據備份。但是 Raft 算法采用的是日志復制方式,復制的是日志并不是數據,當寫請求的日志到來之后,會逐個按順序發送給每一個節點,當超過半數的節點達成一致之后才會提交,所以它不僅不會丟失數據,甚至也不會存在日志空洞或亂序的情況。
- 有了一致性的保證后,安全性也就有了保證,當超過半數的節點達成一致之后,才應用日志,這樣就能解決網絡分區延遲、丟包、冗余和亂序的錯誤。
- 基于一致性和安全性,它的可用性也就得到了保證,只要少于半數的節點宕機,即使主機宕機,也可以快速恢復應用,通過一次選舉的時間就可以重新選出一個 leader 對外提供服務。
PPT 右下角的表格是國標對于高可用系統的指標評估,RTO 和 RPO 分別是恢復時間指標和恢復點目標,有 6 個等級,TuGraph-DB 已經達到了最高等級。當少量節點故障時,RPO 是 0,也就是沒有數據損失,數據恢復時間點指標是小于 15 秒。即使是在部署的時候,無論是在同城的兩中心、三中心,還是多地的多中心,都可以達成 RTO 小于 15 秒的標準。

二、TuGraph-DB 高可用架構與規劃
1. Server 架構設計—啟動集群
上面是我們選擇的一個基礎算法,下面介紹 TuGraph-DB 具體的高可用架構是怎樣設計的。通過一個 CASE 來進行講解。
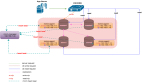
首先建立一個集群,啟動集群的方式跟單機版幾乎是一致的,只不過要加上 enable_ha 參數和 ha_conf 參數去指定集群里面所有節點的 URL,并且要保證三個或者五個節點是可以進行通信的。在三個節點同時啟動后,最先啟動的節點的計時器會超時,把自己選成一個候選者,之后向其它節點發送一個投票請求,其它節點接收到請求之后,會返回給候選者一個 success 的 response,當超過半數之后,這個 leader 就當選了。一般來說,在同城的情況下,延遲不會超過 2 毫秒,在兩地的情況下,比如上海到深圳,最高延遲不會超過 30 毫秒,所以集群建立的時間和選舉的時間是非常快的。

2. Server 架構設計—請求同步
集群建立好之后,可以向其發送讀寫請求。發送讀請求非常簡單,client 發送一個讀請求給 TuGraph server,server 接到讀請求之后,去進行處理。圖中給出的一個 cypher 語句,是查詢圖中邊的 label 的數量。在 server 端,會對 cypher 語句進行解析,辨別它是一個只讀的請求,一旦確定就會直接發送給 TuGraph-DB,由 TuGraph-DB 進行響應。

寫請求會涉及到 DB 數據的變化。Client 發送給 server 之后,server 會通過一些自有的邏輯去判斷,如果是一個寫請求,那么它會傳給內部的一個 raft node,這個 raft node 可以看作是一個 client。因為是三個節點,每個節點持有其它節點的一個 client,每個節點既是 server,也是 client。當收到這個請求之后,只有 leader 節點會處理寫請求。它并不會直接應用到 TuGraph-DB 上面,而是先調用客戶端把日志去發送給其它節點,當超過半數的節點響應之后,才會應用到 TuGraph-DB 內部,保證寫請求日志的一致性。
在高可用集群使用過程中,有很多不可預知的情況,比如正好在應用日志的時候,集群突然掛了或者突然重啟了。即使這種情況發生的概率非常低,但在大規模應用中仍然有可能發生。因此,寫請求必須是冪等的,請求的 log index 必須是一致的,當它應用到 DB 里時,不能產生重復的提交。所以我們在 DB 內部持有 log 的 index,當 client 由于超時重發或節點的狀態發生變化而重復提交時,都不會對 DB 狀態產生污染。

3. Server 架構設計—集群成員變更
接下來要考慮的是集群成員變更的情況。首先來看增加節點。增加的節點以 follower 的角色加入集群,和啟動的命令一致就可以將節點加入集群。增加節點時還需要同步日志。
再來看刪除節點的情況。我們如果使用 Meta Server 去控制集群成員的變更,那么這個 Meta Server 也要是高可用的。如果這個 Meta Server 發生了宕機,會導致整體的不可用。為了簡化設計,我們直接讓 leader 去控制集群成員的變更。
要刪除節點時,可以直接調用下圖中給出的命令,讓節點離開集群。正常情況下是由 leader 向 follower 發送心跳,為了維護集群正常的狀態,follower 也會向 leader 發送心跳,讓 leader 感知到它的存在。當 follower 超過一定的時間沒有給 leader 發送心跳時,就會把這個 follower 從集群中去除,從而完成了集群成員的變更。
當然需要注意的是,比如有 7 個節點,不能同時刪掉 4 個節點,這就相當于有 4 個節點宕機了。

4. Server 架構設計—快照
前文中提到,加入 follower 時,需要同步日志。但是一個集群經過長期的服務,日志一定是非常多的,如果每加入一個 follower,都從一年之前、兩年之前的日志開始同步,同步過來除了 Append,還需要應用到 Server 里面,是非常耗時的。所以需要定期對節點打快照,對數據庫狀態做一個保存。再去加入 follower 時,直接傳輸快照就可以了。
Tugraph-DB 不管是安裝快照還是打快照,都是非常快速的。因為 Tugraph-DB 底層支持 MVCC 多版本,生成快照的時候并不會去阻塞讀寫請求。

5. Client 架構設計
以上對 server 端的設計進行了介紹,接下來介紹 client 端的設計。Client 端最重要的有兩點,第一點是 client 必須持有集群中所有節點的連接,不能只有一個節點。既然持有所有節點的連接,也就是連接池,那么它必須要知道誰是 leader,所以 client 必須要支持在連接上這個集群的時候,自動定位到 leader,通過這種方式,只需要去指定集群中任意一個節點的 URL,就可以連接上整個集群,并自動找到集群中的 leader。
第二個重要的點就是負載均衡。因為 leader 數據是最全的,并且只有它能寫。但是整個高可用架構,并不只提供數據的安全性,還要提供讀寫的功能,并且能更好的利用硬件資源,所以我們要對讀請求做負載均衡,以輪詢的方式去循環地發送給每一個節點,來提高訪問性能。

6. 未來規劃
未來規劃,主要有三個方面。
第一個是 Witness 角色。這個角色起源于一個場景,假如一個企業沒有很多機器,比如只有兩臺機器,但是它又想用高可用的架構,那應該怎么辦?引入 Raft 擴展角色,就是 witness 角色,這個角色有一個特點,它只參與選舉,但是不參與日志復制。也就是可以在一個機器里面運行兩個節點,一個節點不復制日志,只參與選舉。那么在另外一個機器里面去運行一個節點,這樣兩臺機器就可以啟動高可用集群了。這樣不僅可以減少數據的傳輸量,而且可以提高可用性和性能,因為它不用應用日志了。
第二個是按需快照。大家在使用圖數據庫的時候,數據量可能是非常龐大的。比如我們內部有一個 1.2T 的線上業務,當它去打 snapshot 的時候,時間非常長,大概要兩個小時。雖然它并不阻塞讀寫請求,但對性能的影響還是非常嚴重的,并且會放大存儲空間,原來數據是 1.2T,打完之后可能就變成 2.4T 了。所以我們希望改造 Raft 協議,去提供按需生成快照的功能,只有在 follower 加入節點的時候才進行快照,因為只有 follower 加入這個節點時需要快照來加速數據同步。
第三個是高可用工具鏈。因為 TuGraph-DB 的高可用功能是 3.6 版本才開源,它提供的工具鏈現在還有一些待完善的地方,比如在線導入,只提供了單機的功能,我們希望可以提供一個集群在線導入,這樣就不用去對多機執行在線導入的功能了。還有快照生成工具,client 的接口完善等等。

三、TuGraph-DB 高可用集群部署與應用
1. TuGraph-DB 高可用(V3.6)
關于 TuGraph-DB 高可用集群的部署方式和 client 應用,相關文檔已經放到了 tugraph-db.readthedocs.io 網站上。
現在支持 C++、Java 和 Python 多種版本的 client SDK。
2. 高可用集群部署
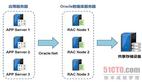
當原始數據一致的時候,可以直接指定 HA configure 參數啟動集群。當初始數據不一致的時候,假如有一個節點有數據,其它節點沒有數據,需要把數據同步到其它節點,但是又不能通過 SCP 傳,那么就可以通過初始數據不一致的方式去啟動。有數據的節點用 bootstrap 方式啟動,預先生成一個快照,然后其它節點以 follower 的身份加入集群,加入集群時會安裝快照,安裝快照之后才會進行選舉和 follower 身份的確認。

3. Client 連接應用
啟動完集群之后,前端會有一個高可用的列表,client 有直接方式和間接方式連接的區別,主要是考慮到在亞馬遜云部署和阿里云部署的區別。連接完了之后就可以去執行請求,比如執行寫請求的時候,要先寫到 leader 再同步到 follower,可以看到是有日志同步的。