提升RAG檢索質量的三個高級技巧(查詢擴展、交叉編碼器重排序和嵌入適配器)
在現成的 RAG 實施過程中,經常會出現檢索的文檔缺少完整的答案或是包含冗余信息和無關的信息,以及文檔排序不同,導致生成的答案與用戶查詢的意圖不一致。
現介紹三種能夠有效提高檢索能力的技術,即查詢擴展(Query expansion),跨編碼器重排序(Cross-encoder re-ranking),嵌入適配器(Embedding adaptors),可以支持檢索到更多與用戶查詢密切匹配的相關文檔,從而提高生成答案的影響力。
1.查詢擴展
查詢擴展是指對原始查詢進行改寫的一系列技術。有兩種常見的方法:
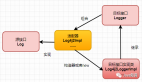
1) 使用生成的答案進行查詢擴展
給定輸入查詢后,這種方法首先會指示 LLM 提供一個假設答案,無論其正確性如何。然后,將查詢和生成的答案合并在一個提示中,并發送給檢索系統。
 圖片
圖片
這個方法的效果很好。基本目的是希望檢索到更像答案的文檔。假設答案的正確性并不重要,因為感興趣的是它的結構和表述。可以將假設答案視為一個模板,它有助于識別嵌入空間中的相關鄰域。具體可參考論文《Precise Zero-Shot Dense Retrieval without Relevance Labels【1】》
下面是用來增強發送給 RAG 的查詢的提示示例,該 RAG 負責回答有關財務報告的問題。
You are a helpful expert financial research assistant.
Provide an example answer to the given question, that might
be found in a document like an annual report.2)用多個相關問題擴展查詢
利用 LLM 生成 N 個與原始查詢相關的問題,然后將所有問題(加上原始查詢)發送給檢索系統。通過這種方法,可以從向量庫中檢索到更多文檔。不過,其中有些會是重復的,因此需要進行后處理來刪除它們。
 圖片
圖片
這種方法背后的理念是,可以擴展可能不完整或模糊的初始查詢,并納入最終可能相關和互補的相關方面。
下面是用來生成相關問題的提示:
You are a helpful expert financial research assistant.
Your users are asking questions about an annual report.
Suggest up to five additional related questions to help them
find the information they need, for the provided question.
Suggest only short questions without compound sentences.
Suggest a variety of questions that cover different aspects of the topic.
Make sure they are complete questions, and that they are related to
the original question.
Output one question per line. Do not number the questions.具體可參考論文《Query Expansion by Prompting Large Language Models【2】》。
上述方法有一個缺點就是會得到很多的文檔,這些文檔可能會分散 LLM 的注意力,使其無法生成有用的答案。這時候需要對文檔進行重排序,去除相關性不高的文檔。
2.交叉編碼器重排序
這種方法會根據輸入查詢與檢索到的文檔的相關性的分數對文檔進行重排序。為了計算這個分數,將會使用到交叉編碼器。

交叉編碼器是一種深度神經網絡,它將兩個輸入序列作為一個輸入進行處理。這樣,模型就能直接比較和對比輸入,以更綜合、更細致的方式理解它們之間的關系。
 圖片
圖片
交叉編碼器可用于信息檢索:給定一個查詢,用所有檢索到的文檔對其進行編碼。然后,將它們按遞減順序排列。得分高的文檔就是最相關的文檔。
詳情請參見 SBERT.net Retrieve & Re-rank【3】。
 圖片
圖片
下面介紹如何使用交叉編碼器快速開始重新排序:
pip install -U sentence-transformers
#導入交叉編碼器并加載
from sentence_transformers import CrossEncoder
cross_encoder = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
#對每一對(查詢、文檔)進行評分
pairs = [[query, doc] for doc in retrieved_documents]
scores = cross_encoder.predict(pairs)
print("Scores:") for score in scores:
print(score)
# Scores:
# 0.98693466
# 2.644579
# -0.26802942
# -10.73159
# -7.7066045
# -5.6469955
# -4.297035
# -10.933233
# -7.0384283
# -7.3246956
#重新排列文件順序:
print("New Ordering:")
for o in np.argsort(scores)[::-1]:
print(o+1)交叉編碼器重新排序可與查詢擴展一起使用:在生成多個相關問題并檢索相應的文檔(比如最終有 M 個文檔)后,對它們重新排序并選出前 K 個(K < M)。這樣,就可以減少上下文的大小,同時選出最重要的部分。
3.嵌入適配器
這是一種功能強大但使用簡單的技術,可以擴展嵌入式內容,使其更好地與用戶的任務保持一致,利用用戶對檢索文檔相關性的反饋來訓練適配器。
適配器是全面微調預訓練模型的一種輕量級替代方法。目前,適配器是以小型前饋神經網絡的形式實現的,插入到預訓練模型的層之間。訓練適配器的根本目的是改變嵌入查詢,從而為特定任務產生更好的檢索結果。嵌入適配器是在嵌入階段之后、檢索之前插入的一個階段。可以把它想象成一個矩陣(帶有經過訓練的權重),它采用原始嵌入并對其進行縮放。
 圖片
圖片
以下是訓練步驟:
1)準備訓練數據
要訓練嵌入適配器,需要一些關于文檔相關性的訓練數據。這些數據可以是人工標注的,也可以由 LLM 生成。這些數據必須包括(查詢、文檔)的元組及其相應的標簽(如果文檔與查詢相關,則為 1,否則為-1)。為簡單起見,將創建一個合成數據集,但在現實世界中,需要設計一種收集用戶反饋的方法(比如,讓用戶對界面上的文檔相關性進行評分)。
為了創建一些訓練數據,首先可利用LLM生成財務分析師在分析財務報告時可能會提出的問題樣本。
import os
import openai
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.environ['OPENAI_API_KEY']
PROMPT_DATASET = """
You are a helpful expert financial research assistant.
You help users analyze financial statements to better understand companies.
Suggest 10 to 15 short questions that are important to ask when analyzing
an annual report.
Do not output any compound questions (questions with multiple sentences
or conjunctions).
Output each question on a separate line divided by a newline.
"""
def generate_queries(model="gpt-3.5-turbo"):
messages = [
{
"role": "system",
"content": PROMPT_DATASET,
},
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
)
content = response.choices[0].message.content
content = content.split("\n")
return content
generated_queries = generate_queries()
for query in generated_queries:
print(query)
# 1. What is the company's revenue growth rate over the past three years?
# 2. What are the company's total assets and total liabilities?
# 3. How much debt does the company have? Is it increasing or decreasing?
# 4. What is the company's profit margin? Is it improving or declining?
# 5. What are the company's cash flow from operations, investing, and financing activities?
# 6. What are the company's major sources of revenue?
# 7. Does the company have any pending litigation or legal issues?
# 8. What is the company's market share compared to its competitors?
# 9. How much cash does the company have on hand?
# 10. Are there any major changes in the company's executive team or board of directors?
# 11. What is the company's dividend history and policy?
# 12. Are there any related party transactions?
# 13. What are the company's major risks and uncertainties?
# 14. What is the company's current ratio and quick ratio?
# 15. How has the company's stock price performed over the past year?然后,為每個生成的問題檢索文檔。為此,將查詢一個 Chroma 集合,在該集合中,以前索引過一份財務報告。
results = chroma_collection.query(query_texts=generated_queries, n_results=10, include=['documents', 'embeddings'])
retrieved_documents = results['documents']再次使用 LLM 評估每個問題與相應文檔的相關性:
PROMPT_EVALUATION = """
You are a helpful expert financial research assistant.
You help users analyze financial statements to better understand companies.
For the given query, evaluate whether the following satement is relevant.
Output only 'yes' or 'no'.
"""
def evaluate_results(query, statement, model="gpt-3.5-turbo"):
messages = [
{
"role": "system",
"content": PROMPT_EVALUATION,
},
{
"role": "user",
"content": f"Query: {query}, Statement: {statement}"
}
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
max_tokens=1
)
content = response.choices[0].message.content
if content == "yes":
return 1
return -1然后,將訓練數據結構化為問答元組。每個元組將包含查詢的嵌入、文檔的嵌入和評估標簽(1,-1)。
retrieved_embeddings = results['embeddings']
query_embeddings = embedding_function(generated_queries)
adapter_query_embeddings = []
adapter_doc_embeddings = []
adapter_labels = []
for q, query in enumerate(tqdm(generated_queries)):
for d, document in enumerate(retrieved_documents[q]):
adapter_query_embeddings.append(query_embeddings[q])
adapter_doc_embeddings.append(retrieved_embeddings[q][d])
adapter_labels.append(evaluate_results(query, document))最后,生成完訓練元組后,將其放入torch數據集,為訓練做準備。
2)定義模型
定義了一個以查詢嵌入、文檔嵌入和適配器矩陣為輸入的函數。該函數首先將查詢嵌入與適配器矩陣相乘,然后計算該結果與文檔嵌入之間的余弦相似度。
def model(query_embedding, document_embedding, adaptor_matrix):
updated_query_embedding = torch.matmul(adaptor_matrix, query_embedding)
return torch.cosine_similarity(updated_query_embedding, document_embedding, dim=0)3)定義損失(loss)
目標是最小化前一個函數計算出的余弦相似度。為此,將使用均方誤差(MSE)損失來優化適配器矩陣的權重。
def mse_loss(query_embedding, document_embedding, adaptor_matrix, label):
return torch.nn.MSELoss()(model(query_embedding, document_embedding, adaptor_matrix), label)4)訓練
初始化適配器矩陣,并完成訓練 100 次epochs。
# Initialize the adaptor matrix
mat_size = len(adapter_query_embeddings[0])
adapter_matrix = torch.randn(mat_size, mat_size, requires_grad=True)
min_loss = float('inf')
best_matrix = None
for epoch in tqdm(range(100)):
for query_embedding, document_embedding, label in dataset:
loss = mse_loss(query_embedding, document_embedding, adapter_matrix, label)
if loss < min_loss:
min_loss = loss
best_matrix = adapter_matrix.clone().detach().numpy()
loss.backward()
with torch.no_grad():
adapter_matrix -= 0.01 * adapter_matrix.grad
adapter_matrix.grad.zero_()訓練完成后,適配器可用于擴展原始嵌入,并適配用戶任務。
test_vector = torch.ones((mat_size,1))
scaled_vector = np.matmul(best_matrix, test_vector).numpy()
test_vector.shape
# torch.Size([384, 1])
scaled_vector.shape
# (384, 1)
best_matrix.shape
# (384, 384)在檢索階段,只需將原始嵌入輸出與適配器矩陣相乘,然后輸入檢索系統即可。
以上三種方法操作性較強,感興趣的讀者可以將其應用到現有的RAG應用中,來評估這些手段對于自己的場景有效性。
相關鏈接:
【1】https://arxiv.org/pdf/2212.10496.pdf
【2】https://arxiv.org/pdf/2305.03653.pdf
【3】https://www.sbert.net/examples/applications/retrieve_rerank/README.html
原文來自:Ahmed Besbes:3 Advanced Document Retrieval Techniques To Improve RAG Systems