













解讀AI通用計算芯片:GPU訓練CPU推理,用最優的成本降低AI算力支出
原創當前,人工智能已經成為推動企業業務創新和可持續發展的核心引擎。我們知道,算力、算法和數據是人工智能的三大核心要素,缺一不可。今天,筆者就從通用計算芯片這個維度出發,跟大家詳細聊聊關于算力的相關技術與市場競爭態勢。
所謂AI計算芯片(也稱邏輯芯片),就是指包含了各種邏輯門電路,即能夠進行運算,又能夠進行邏輯判斷的數字芯片,包括CPU、GPU、FPGA、ASIC等。這里,我們將通過一些比喻重點跟大家介紹一下CPU與GPU這兩種通用計算芯片,希望大家看完本篇文章,能夠真正了解CPU與GPU的主要差異,以及相互之間的優劣勢。
計算機基本架構及原理
要了解CPU與GPU的本質區別,首先要簡單地認識一下計算機的基本架構。
從數據輸入到結果輸出,現在的計算機大都是基于1940年代誕生的馮·諾依曼架構演進而來。在這個架構中,主要有輸入設備、存儲器、運算器(ALU,也稱邏輯運算單元)、控制器(CU)、輸出設備組成。
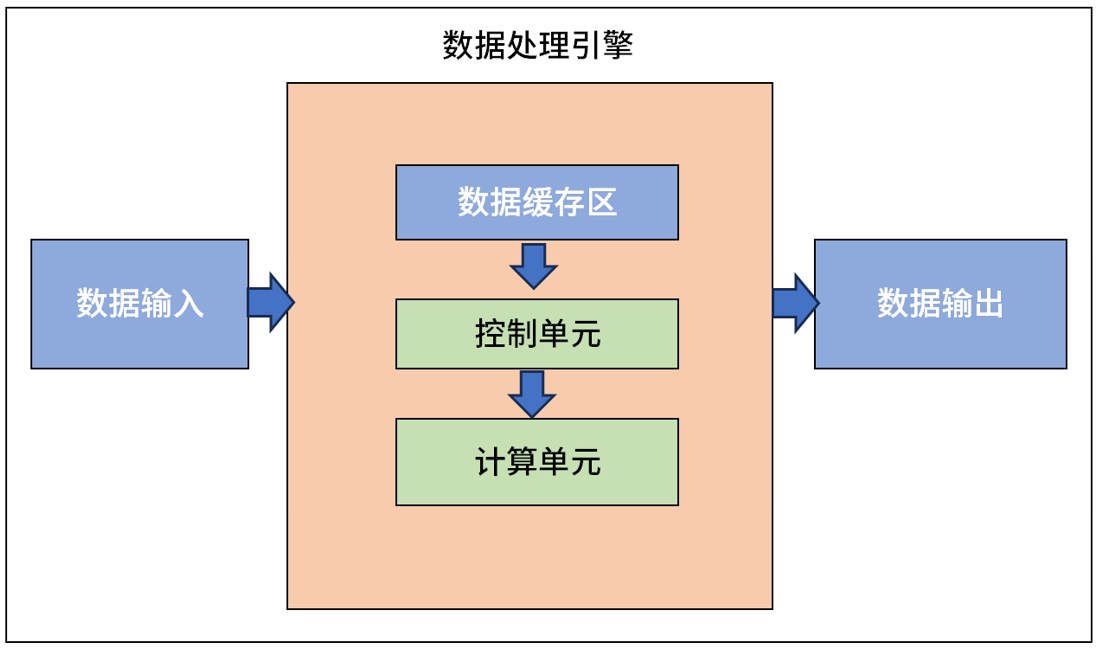
數據輸入:將外部數據輸入到數據處理引擎中;
數據緩存區:負責計算過程中臨時數據的存儲與讀取,主要用來提高數據的讀寫效率;
控制單元:負責接收數據處理的控制命令,并且執行對整個處理引擎的控制和狀態進行實時反饋;
計算單元:即數據處理的核心;
數據輸出:輸出處理好的數據,與外界進行交互。
本質上,CPU與GPU都是從馮·諾依曼架構演進而來,但由于采用了不同的架構,因此雙方在計算性能上存在著較大的差異。接下來,我們就通過以英特爾為代表的x86架構和以英偉達為代表的CUDA(NV-RSIC)架構,來介紹一下兩者的不同之處。
架構設計不同帶來的差異
1)CPU:串行計算
作為計算機中的核心部件,CPU就像我們人類的大腦一樣,它不僅僅要執行各種復雜的計算任務,還要負責控制其它部件之間的協作。因此,除了計算單元外,控制單元也在CPU中扮演著重要的角色。(CPU架構示意如下圖)
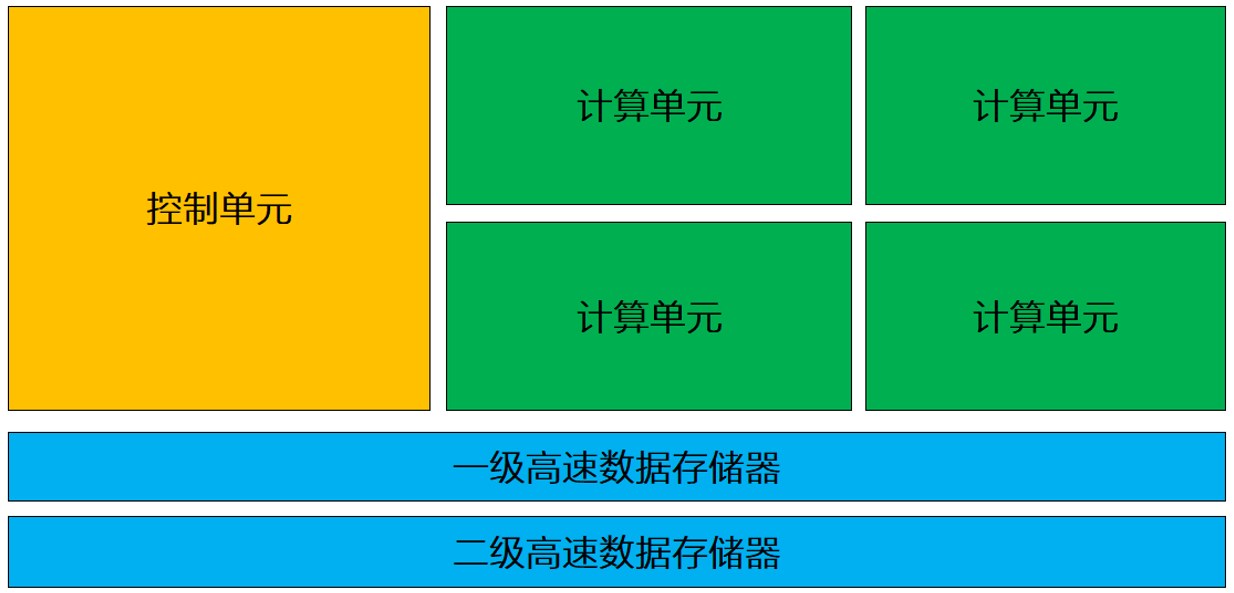
上圖可以看到,在整個CPU架構中,負責計算的綠色區域占的面積相對并不算大,反而黃色區域的控制單元占據了不少的空間。因此,除了計算之外,CPU也比較擅長邏輯控制。
和我們的大腦一樣,CPU只能同時完成一件事情,是以串行方式進行計算的。指令在CPU中執行的過程就像一個工廠生產車間中的一條流水線,即先讀取指令,之后通過指令總線送到控制器中進行譯碼,并發出相應的操作控制信號;然后運算器按照操作指令對數據進行計算,并通過數據總線將得到的數據存入數據緩存器,完成一條指令的計算過程。(如下圖)
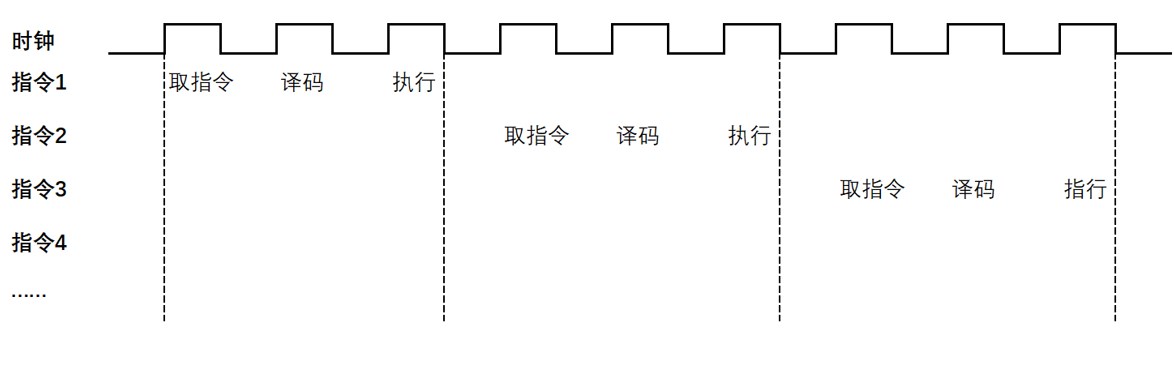
在取指令 ->指令譯碼 ->指令執行這個過程中,只有在指令執行的時候計算單元才發揮作用,這樣取指令和指令譯碼的兩段時間,計算單元就不會工作,這就會造成計算效率不高。
為了提高指令執行的效率,在不同的指令之間,通過預先讀取后面的幾條指令,使得指令流水處理,這樣就減少了指令等待的過程,提高了指令執行效率。(如下圖)
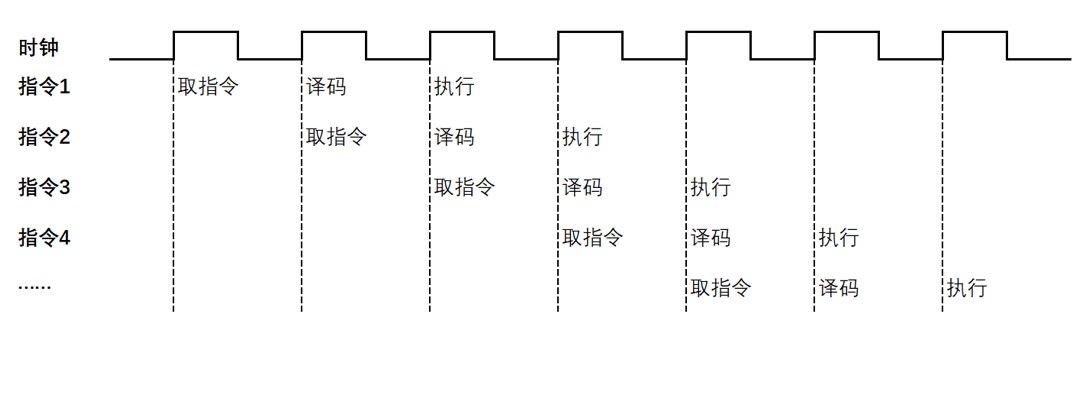
當然,提高時鐘頻率、增加更多的核心數量,也能夠有效地提高CPU的計算效率,但隨著技術瓶頸的出現,提高核心數量和提高時鐘頻率的難度越來越大,且帶來的性能提升比例越來越小。
不難發現,受架構影響,CPU有著很強的邏輯運算能力,但并不擅長1+1=2的大量數據的并行計算。因此,在AI訓練過程中,需要大規模并行計算時,CPU的優勢就非常不明顯了。
2)GPU:并行計算
在計算機中,GPU最初設計的初衷是加速圖形圖像處理,即專用加速器。因此,GPU內部采用了并行計算的設計,控制單元僅占很小的一部分。(見下圖)

上圖可以看到,GPU內部擁有大量的計算單元。由于采用了并行架構設計,每一組計算單元都有單獨的緩存和控制器。
由于具有大量的計算單元,僅用來進行圖形圖像處理,應用范圍過于狹窄,也無法真正發揮GPU的價值。于是,NVIDIA提前感知到AI將成為未來的主要技術趨勢,并將GPU內部的計算單元進行了通用化的重新設計,GPU變成了GPGPU,即通用并行計算平臺,也就是今天我們所指的GPU。
GPU不僅能夠處理圖形數據,還可以處理非圖形化數據,特別是在運算量遠大于數據調度和傳輸的計算時,GPU的性能遠遠大于CPU,因此在進行大量數據的訓練時,GPU有著更強的優勢。
當然,由于控制單元并不占優勢,因此在進行邏輯運算時,GPU并不占優勢。也就是說,讓GPU進行大量數據的簡單運算,速度更快,就像把大量的土豆全部切成片,GPU會更快。但是,如果讓它執行將一小部分土豆切成絲,一大部分切成片這樣的任務時,GPU就不占優勢了。
CPU vs GPU:合理搭配降低AI總體成本
通過以上介紹不難發現,由于底層架構存在著較大的差異,因此雙方在AI運算中也扮演著不同的角色。
舉個例子,CPU具備更強的邏輯運算能力,就好像一位資深的老教授;GPU并行計算能力更優,就好像很多小學生同時進行1+1的簡單計算。在同時進行大量簡單的計算任務時,人數越多越占優勢,完成的時間就越短;但是,如果在進行微積分等更加復雜的計算任務時,CPU就更加占有優勢。
具體到AI計算方面,由于CPU有著更強的邏輯運算能力,就更加適合推理;而GPU擁有大量的計算單元,就更適合訓練。
當然,無論是英特爾還是英偉達,都在通過不斷進行架構優化,來提高AI的計算能力。例如英特爾,在最新推出的第五代至強可擴展處理器中,通過在每個內核中都內置英特爾AMX加速AI模塊器的方式,讓AVX-512和AMX都可以在CPU上使用,以提高AI推理的性能。根據官方給出的數據,基礎平均性能較上一代提升21%,而AI推理性能的提升則高達42%。同時,得益于內置的英特爾高級矩陣擴展功能,第五代至強處理器無需搭配獨立的AI加速器,就可以直接應付嚴苛的AI工作負載。
英偉達GTC2024上發布的全新B200 GPU,采用了兩個GPU die集成在同一芯片上的設計,并配備了192GB的HBM3e超大內存。基于GB200 NVL72打造的MGX系統,能夠實現30TB的統一內存,130TB/s的總帶寬,甚至是單機柜exaFLOP級(FP4精度)的AI算力。英偉達表示,即便面對1.8萬億參數的GPT-MoE-1.8T超大模型,也可以實現比同數量H100 GPU高出4倍的訓練性能。
雖然目前GPU的熱度遠高于CPU,但在筆者看來CPU仍然不可替代。原因在于,CPU不但具備更強的推理能力,并且擁有更高的性價比。這是因為,目前大部分數據中心中并不缺少CPU計算資源,且相對部署已經更加完善和成熟。因此,考慮到成本因素,包括采購成本、部署成本、使用成本(功耗)等,也成為眾多廠商選擇CPU進行推理的重要原因。



















