面試官:如果單表數據量過大怎么辦?
作者:剽悍一小兔
大部分情況,我們做數據歸檔就足以解決單表數據量過大這個問題。只有那些全部很重要的業務數據,才需要做分庫分表。
要回答這個問題,首先我們要明確這個表的數據是否全部有用?使用MySQL的過程,經常會遇到一個問題,比如說某張”log”表,用于保存某種記錄,隨著時間的不斷的累積數據,但是只有最新的一段時間的數據是有用的;這個時候會遇到性能和容量的瓶頸,需要將表中的歷史數據進行歸檔。
也就是說,大部分情況,我們做數據歸檔就足以解決這個問題。只有那些全部很重要的業務數據,才需要做分庫分表。

利用存儲過程和事件來定期進行數據的導出刪除操作
創建一個新表,表結構和索引與舊表一模一樣:
create table table_new like table_old;新建存儲過程,查詢30天的數據并歸檔進新數據庫,然后把30天前的舊數據從舊表里刪除:
delimiter $
create procedure sp()
begin
insert into tb_new select * from table_old where rectime < NOW() - INTERVAL 30 DAY;
delete from db_smc.table_old where rectime < NOW() - INTERVAL 30 DAY;
end創建EVENT,每天晚上凌晨00:00定時執行上面的存儲過程:
create event if not exists event_temp
on schedule every 1 day
on completion preserve
do call sp();備注:第一次執行存儲過程的時候因為歷史數據過大, 可能發生意外讓該次執行沒有成功。重新執行時會遇到報錯ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction,應急解決方案如下:
- 執行show full processlist;查看所有MySQL線程。
- 執行SELECT * FROM information_schema.INNODB_TRX; 查看是否有錯誤線程,即線程id在show full processlist;的結果中,狀態為sleep的線程。
- kill進程id。
另外寫存儲過程的時候可以控制事務的大小,比如說可以根據時間字段每次歸檔一天或者更小時間段的數據,這樣就不會有大事務的問題,里面還可以加入日志表,每次歸檔操作的行為都寫入日志表,以后查起來也一目了然。
實戰
首先,查看一下哪些表數據量特別大:
SELECT
TABLE_NAME AS '表名',
TABLE_ROWS AS '記錄數'
FROM
information_schema.TABLES
WHERE
TABLE_SCHEMA = 'tms' and TABLE_ROWS > 1000; -- 這里替換為你的數據庫名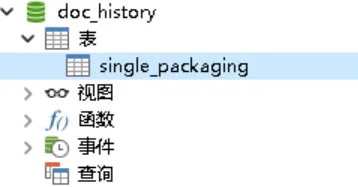
如圖,我要對原數據庫中的single_packaging表進行歸檔,就先新建一個用于歸檔的數據庫doc_history:
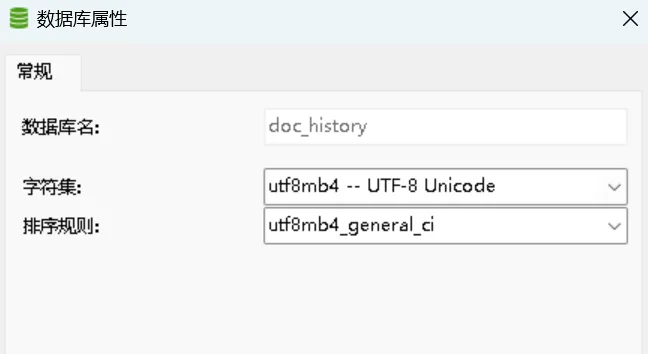
然后建一張一模一樣的表在這個數據庫,編寫歸檔的存儲過程:
delimiter $
create procedure sp()
begin
insert into doc_history.single_packaging select * from old_schema.single_packaging where create_time < NOW() - INTERVAL 7 DAY;
delete from old_schema.single_packaging where create_time < NOW() - INTERVAL 7 DAY;
end注意老庫和新庫的區別。
最后,設置事件,每天定時跑:
create event if not exists event_temp
on schedule every 1 day
on completion preserve
do call sp();
這樣就OK了。
責任編輯:趙寧寧
來源:
java小白翻身