細說 MySQL 的三種表關聯設計

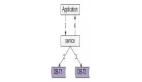
一、通過關聯表(N-N)
正常兩張表進行關聯,我們可以采用中間表的方式,這是最靈活的方式,它可以直接將兩張表的數據根據某個字段直接關聯起來。
下面是一個簡單的例子來解釋這個概念: 假設我們有兩個表:students(學生)和 courses(課程)。一個學生可以選修多門課程,同時一門課程也可以被多個學生選修。這就是一個典型的多對多關系。
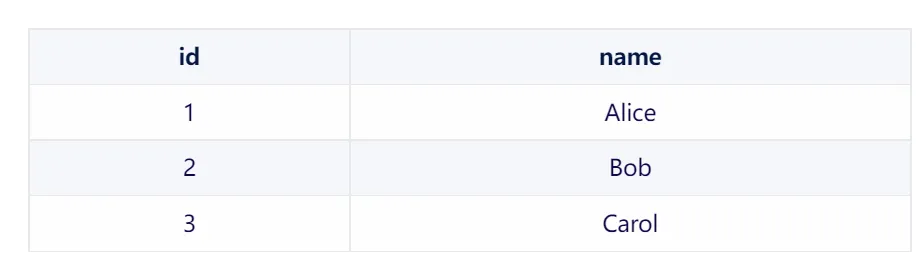
1.students 表
2.courses 表
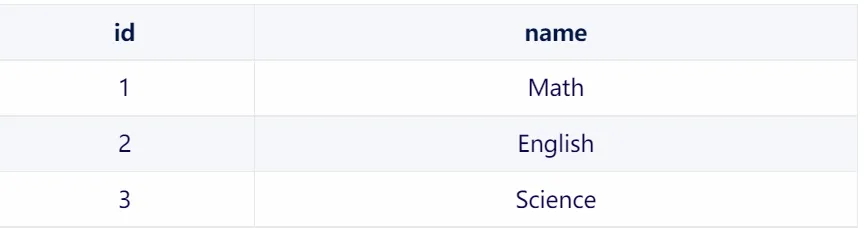
為了表示學生和課程之間的多對多關系,我們可以使用一個中間表 student_courses:
3.student_courses 表
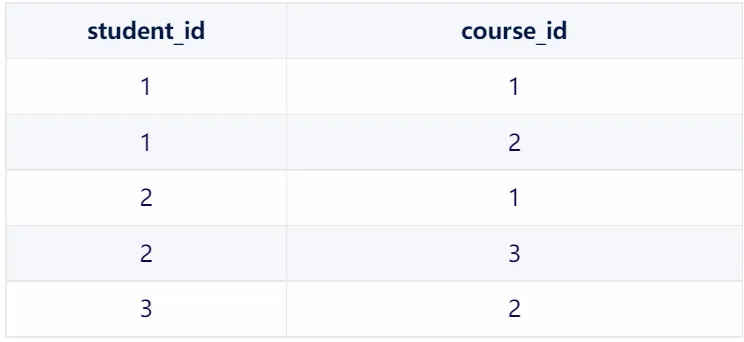
在這個中間表中,每一行都表示一個學生和一門課程之間的關聯。例如,第一行表示 Alice(學生ID為1)選修了 Math(課程ID為1)。 通過查詢這個中間表,我們可以輕松地獲取某個學生選修的所有課程,或者獲取選修了某門課程的所有學生。 這種使用中間表的方式非常靈活,因為它允許我們輕松地添加、刪除或修改學生和課程之間的關聯,而不需要修改原始的 students 或 courses 表。
二、主從設計(1-N)
除了上面那種方式,還有一種主從設計,就是一張主表,一張明細表(或者叫做從表)。
主從設計或稱為父子表設計是數據庫中常見的另一種表關聯方式。在這種設計中,主表通常存儲主要實體的信息,而明細表或從表則存儲與主表實體相關的詳細或子項信息。這種設計常用于一對多關系,即一個主表記錄對應多個明細表記錄。 以下是一個主從設計的例子:
1.主表:orders(訂單)
order_id | customer_id | order_date | total_amount |
1 | 101 | 2023-04-01 | 100.00 |
2 | 102 | 2023-04-02 | 150.00 |
2.明細表:order_items(訂單項)
item_id | order_id | product_id | quantity | unit_price |
1 | 1 | 1001 | 2 | 50.00 |
2 | 1 | 1002 | 1 | 20.00 |
3 | 2 | 1003 | 3 | 50.00 |
在這個例子中:
- orders 表是主表,它存儲了訂單的基本信息,如訂單ID、客戶ID、訂單日期和總金額。
- order_items 表是明細表或從表,它存儲了每個訂單的詳細項,如訂單項ID、所屬的訂單ID、產品ID、數量和單價。
通過 order_id 字段,order_items 表與 orders 表建立了關聯。這樣,我們可以輕松地查詢某個訂單的所有項,或者查詢某個產品的所有訂單項。 主從設計的優點是:
- 結構清晰:主表和明細表各司其職,主表存儲總體信息,明細表存儲詳細信息。
- 靈活擴展:如果需要添加更多的與主表相關的詳細信息,可以在明細表中添加更多字段,而不會影響主表的結構。
- 易于維護:由于主表和明細表是分離的,所以對其中一個表的修改不會影響到另一個表。
需要注意的是,在設計數據庫時,應根據實際業務需求和數據關系來選擇合適的表關聯方式。有時,可能需要結合使用中間表、主從設計或其他設計模式來滿足復雜的業務需求。
三、關聯設計(1-N)
除了上面說的主從設計,還有一些情況,就是兩張表并非主從關系,但是也有一定的邏輯關聯性。比如一個手機生產訂單,我們要根據這個訂單生成一個多個工單,分為原料采購工單,組裝工單,包裝工單等。這種也是一對多的關系,但并非主從關系,針對這種情況,我們需要做關聯設計。
我們可以為手機訂單表和工單表創建相應的數據庫表結構,并模擬一些基礎數據。以下是使用SQL語言創建表和插入數據的示例:
- 創建手機訂單表 (phone_orders)
CREATE TABLE phone_orders (
sid INT PRIMARY KEY NOT NULL,
phone_name VARCHAR(100) NOT NULL,
phone_quantity INT NOT NULL
);- 創建工單表 (work_orders)
CREATE TABLE work_orders (
sid INT PRIMARY KEY NOT NULL,
sSrcSlaveId INT NOT NULL, -- 源單號,即手機訂單表的sid
dProductPQty INT NOT NULL, -- 產品數量
FOREIGN KEY (sSrcSlaveId) REFERENCES phone_orders(sid) ON DELETE CASCADE
);這里,我們為work_orders表的sSrcSlaveId字段設置了外鍵約束,以確保它引用的是phone_orders表中存在的sid。使用ON DELETE CASCADE選項意味著當刪除一個手機訂單時,與該訂單相關聯的所有工單也會被自動刪除。
3. 模擬基礎數據
首先,向手機訂單表中插入一些數據:
INSERT INTO phone_orders (sid, phone_name, phone_quantity) VALUES
(1, 'iPhone 13', 0),
(2, 'Galaxy S22', 0),
(3, 'Pixel 6', 0);然后,向工單表中插入與手機訂單相關聯的數據:
INSERT INTO work_orders (sid, sSrcSlaveId, dProductPQty) VALUES
(1, 1, 20), -- 對應phone_orders中sid為1的訂單,產品數量為20
(2, 1, 30), -- 同一個訂單的另一個工單,產品數量為30
(3, 2, 50), -- 對應phone_orders中sid為2的訂單,產品數量為50這里的sid字段在兩張表中都是唯一的,但在各自的表中可以重復。對于work_orders表,sSrcSlaveId字段對應于phone_orders表的sid,用于表示工單與哪個手機訂單相關聯。 手機訂單的總數量為0,我們一般需要在生成工單的時候,去回填訂單表的數量字段,這是很常見的需求。 嘗試寫sql如下:
update phone_orders A join (
SELECT sSrcSlaveId,SUM(dProductPQty) dProductPQty from work_orders GROUP BY sSrcSlaveId
) B on A.sid = B.sSrcSlaveId
set A.phone_quantity = B.dProductPQty
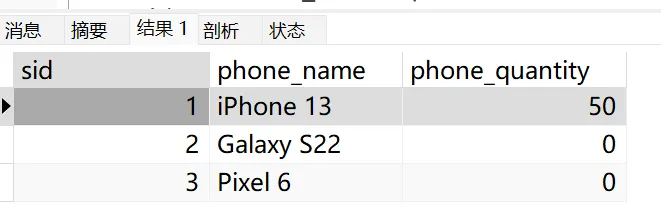
where A.sid = 1;基于您提供的SQL更新語句,這條語句的目的是更新phone_orders表中sid為1的記錄,將其phone_quantity字段設置為與該訂單相關聯的所有工單的產品數量之和。
首先,我們來分析這條SQL語句的各個部分:
4.子查詢:
SELECT sSrcSlaveId, SUM(dProductPQty) dProductPQty
FROM work_orders
GROUP BY sSrcSlaveId這個子查詢從work_orders表中選取sSrcSlaveId(即源單號,對應于phone_orders表的sid)和每個源單號對應的所有工單的產品數量之和(通過SUM(dProductPQty)計算)。結果集包含兩列:sSrcSlaveId和計算后的產品數量dProductPQty。
5.JOIN操作:
UPDATE phone_orders A
JOIN (
...子查詢...
) B
ON A.sid = B.sSrcSlaveId這里使用了JOIN操作來連接phone_orders表(別名為A)和子查詢的結果集(別名為B)。連接條件是A.sid = B.sSrcSlaveId,即phone_orders表的唯一鍵sid與子查詢結果集中的sSrcSlaveId相匹配。
6.SET操作:
SET A.phone_quantity = B.dProductPQty此部分將phone_orders表(別名為A)中的phone_quantity字段更新為子查詢結果集(別名為B)中對應的dProductPQty值。
7.WHERE條件:
WHERE A.sid = 1這個條件限制了更新的范圍,只更新phone_orders表中sid為1的記錄。
這條SQL語句的作用是:找出所有與phone_orders表中sid為1的訂單相關聯的工單,計算這些工單的產品數量之和,然后將phone_orders表中sid為1的記錄的phone_quantity字段更新為這個總和。
執行后得到結果:
思考題
上面的例子,如果我們換成left join,并且去查詢A.sid = 3會發生什么?
update phone_orders A left join (
SELECT sSrcSlaveId,SUM(dProductPQty) dProductPQty from work_orders GROUP BY sSrcSlaveId
) B on A.sid = B.sSrcSlaveId
set A.phone_quantity = B.dProductPQty
where A.sid = 3;