被勸退后三月中旬到現(xiàn)在無(wú) offer,問(wèn)我如何設(shè)計(jì)一個(gè)高性能MySQL 主鍵,實(shí)現(xiàn)海量數(shù)據(jù)下的高效查詢
在脈脈上有一個(gè)熱度很高的帖子「碩 1.5,被勸退后三月中旬到現(xiàn)在無(wú) offer,不知道怎么破」。
 圖片
圖片
有網(wǎng)友說(shuō):「如果能約到面試,說(shuō)明簡(jiǎn)歷不差,但是 50 場(chǎng)都沒有 offer,說(shuō)明你的面試談判技巧出現(xiàn)了問(wèn)題,應(yīng)該總結(jié)一下,及時(shí)調(diào)整,心態(tài)不要崩」。
 圖片
圖片
由這個(gè)話題為引子,碼哥接下來(lái)給你分享一個(gè)知識(shí)點(diǎn):「如何設(shè)計(jì)一個(gè)高性能MySQL 主鍵,實(shí)現(xiàn)海量數(shù)據(jù)下的高效查詢」。
為什么需要主鍵
三個(gè)點(diǎn)。
- 數(shù)據(jù)記錄需具有唯一性(第一范式)
- 數(shù)據(jù)需要關(guān)聯(lián) join。
- 數(shù)據(jù)庫(kù)底層索引用于檢索數(shù)據(jù)所需數(shù)據(jù)。
為什么主鍵不宜過(guò)長(zhǎng)
這個(gè)問(wèn)題的點(diǎn)在長(zhǎng)上。那短比長(zhǎng)有什么優(yōu)勢(shì)?(嘿嘿嘿,內(nèi)涵)—— 短不占空間。
但這么點(diǎn)磁盤空間相對(duì)整個(gè)數(shù)據(jù)量來(lái)說(shuō)微不足道。
那么原因應(yīng)該在快上,而且和原始數(shù)據(jù)關(guān)系不大。以此自然得出和索引相關(guān),而且和索引讀取相關(guān)。那么為什么主鍵過(guò)大在索引中會(huì)影響性能?
 圖片
圖片
圖中是 MySQL Innodb 引擎的索引數(shù)據(jù)結(jié)構(gòu)。
左邊是聚簇索引,通過(guò)主鍵定位數(shù)據(jù)記錄。
右邊是普通索引,對(duì)列數(shù)據(jù)做索引,通過(guò)列數(shù)據(jù)查找數(shù)據(jù)主鍵。
如果通過(guò)普通查詢數(shù)據(jù),流程如圖所示,先從普通索引樹上搜索到主鍵,然后在聚簇索引上通過(guò)主鍵搜索到數(shù)據(jù)行。
其中普通索引的葉子節(jié)點(diǎn)是直接存儲(chǔ)的主鍵值,而不是主鍵指針。
所以如果主鍵太長(zhǎng),一個(gè)普通索引樹所能存儲(chǔ)的索引記錄就會(huì)變少,這樣在有限的索引緩沖中,需要讀取磁盤的次數(shù)就會(huì)變多,所以性能就會(huì)下降。
為什么建議使用遞增 ID
 圖片
圖片
InnoDB 使用聚簇索引,如上圖所示,數(shù)據(jù)記錄本身被存于索引(一顆 B+Tree)的葉子節(jié)點(diǎn)上有序存儲(chǔ)。
這就要求同一個(gè)葉子節(jié)點(diǎn)內(nèi)(大小為一個(gè)內(nèi)存頁(yè)或磁盤頁(yè))的各條數(shù)據(jù)記錄按主鍵順序存放。
因此每當(dāng)有一條新的記錄插入時(shí),MySQL 會(huì)根據(jù)其主鍵值將其插入適當(dāng)?shù)墓?jié)點(diǎn)和位置,如果頁(yè)面達(dá)到裝載因子(InnoDB 默認(rèn)為 15/16),則開辟一個(gè)新的頁(yè)(節(jié)點(diǎn))。
如果表使用自增主鍵,那么每次插入新的記錄,記錄就會(huì)順序添加到當(dāng)前索引節(jié)點(diǎn)的后續(xù)位置,當(dāng)一頁(yè)寫滿,就會(huì)自動(dòng)開辟一個(gè)新的頁(yè)。這樣就會(huì)形成一個(gè)緊湊的索引結(jié)構(gòu),近似順序填滿。
由于每次插入時(shí)也不需要移動(dòng)已有數(shù)據(jù),因此效率很高,也不會(huì)增加很多開銷在維護(hù)索引上,如下圖所示。
否則由于每次插入主鍵的值近似于隨機(jī),因此每次新記錄都要被插到現(xiàn)有索引頁(yè)的中間某個(gè)位置,MySQL 不得不為了將新記錄插到合適位置而移動(dòng)數(shù)據(jù),如下圖右側(cè)所示。
 圖片
圖片
ID 是否有需要具備業(yè)務(wù)含義
業(yè)務(wù) ID,即使用具有業(yè)務(wù)意義的 id,比如使用訂單流水號(hào)作為訂單表的主鍵 Key。
邏輯 ID,即無(wú)關(guān)業(yè)務(wù)的 id,按某種規(guī)則生成 id,如自增 ID。
業(yè)務(wù) ID 的優(yōu)點(diǎn)
- ID 具有業(yè)務(wù)意義,在查詢時(shí)可以直接作為搜索關(guān)鍵字使用。
- 不需要額外的列和索引空間。
- 可以減少一些 join 操作。
業(yè)務(wù) ID 的缺點(diǎn)
- 當(dāng)業(yè)務(wù)發(fā)生變化時(shí),有時(shí)需要變更主鍵。
- 涉及多列 ID 時(shí)比較難操作。
- 業(yè)務(wù) ID 往往比較長(zhǎng),所占空間更大,導(dǎo)致更大的磁盤 I/O。
- 在 ID 確定前不能持久化數(shù)據(jù),有時(shí)我們沒有在確定數(shù)據(jù) ID 。時(shí),就想先添加一條記錄,之后再更新業(yè)務(wù) ID。
- 設(shè)計(jì)一個(gè)兼具易用和性能的 ID 生成方案比較難。
邏輯 ID 的優(yōu)點(diǎn)
- 不會(huì)因?yàn)闃I(yè)務(wù)的變動(dòng)而需要修改 ID 邏輯。
- 操作簡(jiǎn)單,且易于管理。
- 邏輯 ID 往往更小,性能更優(yōu)。
- 邏輯 ID 更容易保證唯一性。
- 更易于優(yōu)化。
邏輯 ID 的缺點(diǎn)
- 查詢主鍵列和主鍵索引需要額外的磁盤空間。
- 在插入數(shù)據(jù)和更新數(shù)據(jù)時(shí)需要額外的 I/O。
- 更多的 join 可能。
- 如果沒有唯一性策略限制,容易出現(xiàn)重復(fù)的 ID。
- 測(cè)試環(huán)境和正式環(huán)境 ID 不一致,不利于排查問(wèn)題。
- ID 的值沒有和數(shù)據(jù)關(guān)聯(lián),不符合三范式。
- 不能用于搜索關(guān)鍵字。
- 依賴不同數(shù)據(jù)庫(kù)系統(tǒng)的具體實(shí)現(xiàn),不利于底層數(shù)據(jù)庫(kù)的替換。
主鍵 ID 生成方式有哪些?
一般情況下,我們都使用 MySQL 的自增 ID,來(lái)作為表的主鍵,這樣簡(jiǎn)單,而且從上面講到的來(lái)看,性能也是最好的。
但是在分庫(kù)分表的情況情況下,自增 ID 則不能滿足需求。我們可以來(lái)看看不同數(shù)據(jù)庫(kù)生成 ID 的方式,也看一些分布式 ID 生成方案。
MySQL 自增
MySQL 在內(nèi)存中維護(hù)一個(gè)自增計(jì)數(shù)器,每次訪問(wèn) auto-increment 計(jì)數(shù)器的時(shí)候, InnoDB 都會(huì)加上一個(gè)名為AUTO-INC 鎖直到該語(yǔ)句結(jié)束(注意鎖只持有到語(yǔ)句結(jié)束,不是事務(wù)結(jié)束)。
AUTO-INC 鎖是一個(gè)特殊的表級(jí)別的鎖,用來(lái)提升包含 auto_increment 列的并發(fā)插入性。
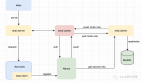
在分布式的情況下,其實(shí)可以獨(dú)立一個(gè)服務(wù)和數(shù)據(jù)庫(kù)來(lái)做 ID 生成,依舊依賴 MySQL 的表 ID 自增能力來(lái)為第三方服務(wù)統(tǒng)一生成 id。
Mongodb ObjectId
Mongodb 為防止主鍵沖突,設(shè)計(jì)了一個(gè) ObjectId 作為主鍵 id。它由一個(gè) 12 字節(jié)的十六進(jìn)制數(shù)字組成,其中包含以下幾部分:
- Time:時(shí)間戳。4 字節(jié)。秒級(jí)。
- Machine:機(jī)器標(biāo)識(shí)。3 字節(jié)。一般是機(jī)器主機(jī)名的散列值,這樣就確保了不同主機(jī)生成不同的機(jī)器 hash 值,確保在分布式中不造成沖突,同一臺(tái)機(jī)器的值相同。
- PID:進(jìn)程 ID。2 字節(jié)。上面的 Machine 是為了確保在不同機(jī)器產(chǎn)生的 objectId 不沖突,而 pid 就是為了在同一臺(tái)機(jī)器不同的 mongodb 進(jìn)程產(chǎn)生的 objectId 不沖突。
- INC:自增計(jì)數(shù)器。3 字節(jié)。前面的九個(gè)字節(jié)保證了一秒內(nèi)不同機(jī)器不同進(jìn)程生成的 objectId 不沖突,自增計(jì)數(shù)器,用來(lái)確保在同一秒內(nèi)產(chǎn)生的 objectId 也不會(huì)發(fā)現(xiàn)沖突,允許 256 的 3 次方等于 16777216 條記錄的唯一性。
開源框架實(shí)現(xiàn)
- 百度 UidGenerator:基于snowflake算法。
- 美團(tuán) Leaf:同時(shí)實(shí)現(xiàn)了基于 MySQL 自增(優(yōu)化)和 snowflake 算法的機(jī)制。
博主簡(jiǎn)介
碼哥,9 年互聯(lián)網(wǎng)公司后端工作經(jīng)驗(yàn),InfoQ 簽約作者、51CTO Top 紅人,阿里云開發(fā)者社區(qū)專家博主,目前擔(dān)任后端架構(gòu)師主責(zé),擅長(zhǎng) Redis、Spring、Kafka、MySQL 技術(shù)和云原生微服務(wù)。