探索智能體的邊界:AgentQuest,一個全面衡量和提升大型語言模型智能體性能的模塊化基準框架
隨著大模型的不斷進化,LLM智能體——這些強大的算法實體已經展現出解決復雜多步驟推理任務的潛力。從自然語言處理到深度學習,LLM智能體正逐漸成為研究和工業界的焦點,它們不僅能夠理解和生成人類語言,還能在多變的環境中制定策略、執行任務,甚至使用API調用和編碼來構建解決方案。
在這樣的背景下,AgentQuest框架的提出具有里程碑意義,它不僅為LLM智能體的評估和進步提供了一個模塊化的基準測試平臺,而且通過其易于擴展的API,為研究人員提供了一個強大的工具,以更細粒度地跟蹤和改進這些智能體的性能。AgentQuest的核心在于其創新的評估指標——進展率和重復率,它們能夠揭示智能體在解決任務過程中的行為模式,從而指導架構的優化和調整。
4月10日發表的論文《AgentQuest: A Modular Benchmark Framework to Measure Progress and Improve LLM Agents》由一支多元化的研究團隊撰寫,他們來自NEC歐洲實驗室、都靈理工大學和北馬其頓的圣西里爾與美多德大學。這篇論文并將在計算語言學協會北美分會2024年會議(NAACL-HLT 2024)上展示,這標志著該團隊在人類語言技術領域的研究成果得到了同行的認可,這不僅是對AgentQuest框架價值的認可,也是對LLM智能體未來發展潛力的肯定。
AgentQuest框架作為衡量和改進大型語言模型(LLM)智能體性能的工具,其主要貢獻在于提供了一個模塊化、可擴展的基準測試平臺。這一平臺不僅能夠評估智能體在特定任務上的表現,還能夠通過進展率和重復率等指標,揭示智能體在解決問題過程中的行為模式。AgentQuest的優勢在于其靈活性和開放性,使得研究人員可以根據自己的需求定制基準測試,從而推動LLM智能體技術的發展。
AgentQuest框架概述
AgentQuest框架是一個創新的研究工具,旨在衡量和改進大型語言模型(LLM)智能體的性能。它通過提供一系列模塊化的基準測試和評估指標,使研究人員能夠系統地跟蹤智能體在執行復雜任務時的進展,并識別改進的潛在領域。
AgentQuest是一個支持多種基準測試和代理架構的模塊化框架,它引入了兩個新的指標——進展率和重復率——來調試代理架構的行為。這個框架定義了一個標準接口,用于將任意代理架構與多樣的基準測試連接起來,并從中計算進展率和重復率。
在AgentQuest中實現了四個基準測試:ALFWorld、側面思維謎題(Lateral Thinking Puzzles)、Mastermind和數獨。后兩者是AgentQuest新引入的。可以輕松添加額外的基凌測試,而無需對測試中的代理進行更改。
 圖片
圖片
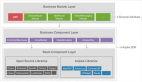
圖1:現有框架和AgentQuest中的智能體基準交互概述。AgentQuest定義了一個通用接口,用于與基準交互和計算進度指標,從而簡化了新基準的添加,并允許研究人員評估和調試其智能體架構。
基本構成和功能
AgentQuest框架的核心是其模塊化設計,它允許研究人員根據需要添加或修改基準測試。這種靈活性是通過將基準測試和評估指標分離成獨立的模塊來實現的,每個模塊都可以單獨開發和優化。框架的主要組件包括:
基準測試模塊:這些是預定義的任務,智能體必須執行。它們涵蓋了從簡單的文字游戲到復雜的邏輯謎題等多種類型。
評估指標模塊:提供了一套量化智能體性能的工具,如進展率和重復率,這些指標幫助研究人員理解智能體在任務中的行為模式。
API接口:允許研究人員將自己的智能體架構與AgentQuest框架連接,以及與外部數據源和服務交互。
模塊化基準測試和指標的重要性
模塊化基準測試的一個關鍵優勢是它們提供了一種標準化的方法來評估不同智能體的性能。這意味著研究人員可以在相同的條件下比較不同智能體的結果,從而確保結果的一致性和可比性。此外,模塊化設計還允許研究人員根據特定研究的需求定制基準測試,這在傳統的基準測試框架中往往難以實現。
評估指標同樣重要,因為它們提供了對智能體性能的深入洞察。例如,進展率可以顯示智能體在解決任務過程中的效率,而重復率則揭示了智能體是否在某些步驟上陷入重復,這可能表明需要改進決策過程。
AgentQuest的擴展性
AgentQuest的API接口是其擴展性的關鍵。通過API,研究人員可以輕松地將AgentQuest集成到現有的研究工作流中,無論是添加新的基準測試、評估指標,還是連接到外部數據源和服務。這種擴展性不僅加速了研究的迭代過程,還促進了跨學科合作,因為來自不同領域的專家可以共同工作,利用AgentQuest框架解決共同的研究問題。
AgentQuest框架通過其模塊化的基準測試和評估指標,以及通過API實現的擴展性,為LLM智能體的研究和開發提供了一個強大的平臺。它不僅促進了研究的標準化和可復制性,還為智能體未來的創新和合作鋪平了道路。
基準測試與評估指標
在AgentQuest框架中,基準測試是評估LLM智能體性能的關鍵組成部分。這些測試不僅提供了一個標準化的環境來比較不同智能體的能力,而且還能夠揭示智能體在解決特定問題時的行為模式。
AgentQuest公開了一個單一的統一Python界面,即驅動程序和兩個反映代理-環境交互組件的類(即觀察和行動)。觀察類有兩個必需屬性:(i)輸出,一個字符串,報告環境狀態的信息;(ii)完成,一個布爾變量,指示最終任務當前是否完成。行動類有一個必需屬性,行動值。這是智能體直接輸出的字符串。一旦處理并提供給環境,它就會觸發環境變化。為了定制交互,開發者可以定義可選屬性。
Mastermind基準測試
Mastermind是一個經典的邏輯游戲,玩家需要猜測一個隱藏的顏色代碼。在AgentQuest框架中,這個游戲被用作基準測試之一,智能體的任務是通過一系列的猜測來確定正確的代碼。每次猜測后,環境會提供反饋,告訴智能體有多少個顏色是正確的,但位置錯誤,以及有多少個顏色和位置都正確。這個過程持續進行,直到智能體猜出正確的代碼或達到預設的步數限制。
 圖2:我們在這里提供了一個Mastermind實現交互的示例。
圖2:我們在這里提供了一個Mastermind實現交互的示例。
Sudoku基準測試
Sudoku是另一個流行的邏輯謎題,它要求玩家在9x9的網格中填入數字,使得每一行、每一列以及每個3x3的子網格中的數字都不重復。在AgentQuest框架中,Sudoku被用作基準測試,以評估智能體在空間推理和規劃方面的能力。智能體必須生成有效的數字填充策略,并且在有限的步數內解決謎題。
評估指標:進展率和重復率
AgentQuest引入了兩個新的評估指標:進展率(PR)和重復率(RR)。進展率是一個介于0到1之間的數值,用來衡量智能體在完成任務過程中的進展。它是通過將智能體達到的里程碑數量除以總里程碑數量來計算的。例如,在Mastermind游戲中,如果智能體猜出了兩個正確的顏色和位置,而總共需要猜出四個,那么進展率就是0.5。
重復率則衡量智能體在執行任務過程中重復相同或相似動作的傾向。在計算重復率時,會考慮到智能體之前的所有動作,并使用相似性函數來確定當前動作是否與之前的動作相似。重復率是通過將重復動作的數量除以總動作數量(減去第一步)來計算的。
通過指標評估和改進LLM智能體性能
這些指標為研究人員提供了一個強有力的工具,用于分析和改進LLM智能體的性能。通過觀察進展率,研究人員可以了解智能體在解決問題方面的效率,并識別可能的瓶頸。同時,重復率的分析可以揭示智能體在決策過程中可能存在的問題,如過度依賴某些策略或缺乏創新。
 表1:AgentQuest中提供的基準概覽。
表1:AgentQuest中提供的基準概覽。
總的來說,AgentQuest框架中的基準測試和評估指標為LLM智能體的發展提供了一個全面的評估體系。通過這些工具,研究人員不僅能夠評估智能體的當前性能,還能夠指導未來的改進方向,從而推動LLM智能體在各種復雜任務中的應用和發展。
AgentQuest的應用案例
AgentQuest框架的實際應用案例提供了對其功能和效果的深入理解,通過Mastermind和其他基準測試,我們可以觀察到LLM智能體在不同場景下的表現,并分析如何通過特定策略來改進它們的性能。
Mastermind的應用案例
在Mastermind游戲中,AgentQuest框架被用來評估智能體的邏輯推理能力。智能體需要猜測一個由數字組成的隱藏代碼,每次猜測后,系統會提供反饋,指示正確數字的數量和位置。通過這個過程,智能體學習如何根據反饋調整其猜測策略,以更有效地達到目標。
在實際應用中,智能體的初始表現可能并不理想,經常重復相同或相似的猜測,導致重復率較高。然而,通過分析進展率和重復率的數據,研究人員可以識別出智能體決策過程中的不足,并采取措施進行改進。例如,通過引入記憶組件,智能體可以記住之前的猜測,并避免重復無效的嘗試,從而提高效率和準確性。
其他基準測試的應用案例
除了Mastermind,AgentQuest還包括其他基準測試,如Sudoku、文字游戲和邏輯謎題等。在這些測試中,智能體的表現同樣受到進展率和重復率指標的影響。例如,在Sudoku測試中,智能體需要填寫一個9x9的網格,使得每行、每列和每個3x3的子網格中的數字都不重復。這要求智能體具備空間推理能力和策略規劃能力。
在這些測試中,智能體可能會遇到不同的挑戰。有些智能體可能在空間推理方面表現出色,但在策略規劃方面存在缺陷。通過AgentQuest框架提供的詳細反饋,研究人員可以針對性地識別問題所在,并通過算法優化或訓練方法的調整來提高智能體的整體性能。
記憶組件的影響
記憶組件的加入對智能體的性能有顯著影響。在Mastermind測試中,加入記憶組件后,智能體能夠避免重復無效的猜測,從而顯著降低重復率。這不僅提高了智能體解決問題的速度,也提高了成功率。此外,記憶組件還使智能體能夠在面對類似問題時更快地學習和適應,從而在長期內提高其學習效率。
總體而言,AgentQuest框架通過提供模塊化的基準測試和評估指標,為LLM智能體的性能評估和改進提供了強有力的工具。通過實際應用案例的分析,我們可以看到,通過調整策略和引入新的組件,如記憶模塊,可以顯著提高智能體的性能。
實驗設置與結果分析
在AgentQuest框架的實驗設置中,研究人員采用了一種參考架構,該架構基于現成的聊天智能體,由GPT-4等大型語言模型(LLM)驅動。這種架構的選擇是因為它直觀、易于擴展,并且是開源的,這使得研究人員能夠輕松地集成和測試不同的智能體策略。
 圖片
圖片
圖4:Mastermind和LTP的平均進度率PRt和重復率RRt。Mastermind:一開始RRt很低,但在第22步后會增加,同時進度也會停滯在55%。LTP:起初,更高的RRt允許代理通過進行小的變化來取得成功,但后來這種變化趨于平穩。
實驗設置
實驗的設置包括了多個基準測試,如Mastermind和ALFWorld,每個測試都旨在評估智能體在特定領域的性能。實驗中設定了執行步驟的最大數量,通常為60步,以限制智能體在解決問題時可以嘗試的次數。這種限制模擬了現實世界中資源有限的情況,并迫使智能體必須在有限的嘗試中找到最有效的解決方案。
實驗結果分析
在Mastermind基準測試中,實驗結果顯示,智能體在沒有記憶組件的情況下,其重復率相對較高,進展率也受到限制。這表明智能體在嘗試解決問題時,往往會陷入重復無效的猜測。然而,當引入記憶組件后,智能體的性能得到顯著提升,成功率從47%提高到60%,重復率降至0%。這說明記憶組件對于提高智能體的效率和準確性至關重要。
 圖片
圖片
圖5:Mastermind和LTP中重復操作的示例。Mastermind:一開始有一系列獨特的動作,但后來卻被困在一遍又一遍地重復相同的動作。LTP:重復的動作是同一問題的微小變化,會導致進步。
在ALFWorld基準測試中,智能體需要在一個文本世界中探索以定位對象。實驗結果表明,盡管智能體在探索解決方案空間時限制了行動重復(RR60 = 6%),但它未能解決所有游戲(PR60 = 74%)。這種差異可能是由于智能體在發現對象時需要更多的探索步驟。當將基準測試的運行時間延長到120步時,成功率和進展率都有所提高,這進一步證實了AgentQuest在理解智能體失敗方面的用處。
智能體架構的調整
根據AgentQuest的指標,研究人員可以對智能體架構進行調整。例如,如果發現智能體在某個基準測試中重復率較高,可能需要改進其決策算法,以避免重復無效的嘗試。同樣,如果進展率低,可能需要優化智能體的學習過程,以更快地適應環境并找到解決問題的方法。
AgentQuest框架提供的實驗設置和評估指標為LLM智能體的性能提供了深入的洞察。通過分析實驗結果,研究人員可以識別智能體的強項和弱點,并據此調整智能體架構,以提高其在各種任務中的表現。
討論與未來工作
AgentQuest框架的提出,為大型語言模型(LLM)智能體的研究和發展開辟了新的道路。它不僅提供了一個系統的方法來衡量和改進LLM智能體的性能,而且還推動了研究社區對于智能體行為的深入理解。
AgentQuest在LLM智能體研究中的潛在影響
AgentQuest通過其模塊化的基準測試和評估指標,使研究人員能夠更精確地衡量LLM智能體在特定任務上的進展和效率。這種精確的評估能力對于設計更高效、更智能的智能體至關重要。隨著LLM智能體在各個領域的應用越來越廣泛,從客戶服務到自然語言處理,AgentQuest提供的深入分析工具將幫助研究人員優化智能體的決策過程,提高其在實際應用中的表現。
AgentQuest在促進透明度和公平性方面的作用
AgentQuest的另一個重要貢獻是提高了LLM智能體研究的透明度。通過公開的評估指標和可復制的基準測試,AgentQuest鼓勵了開放科學的實踐,使研究結果更容易被驗證和比較。此外,AgentQuest的模塊化特性允許研究人員自定義基準測試,這意味著可以根據不同的需求和背景設計測試,從而促進了研究的多樣性和包容性。
AgentQuest未來的發展和研究社區的可能貢獻
緊跟技術的推進,AgentQuest框架有望繼續擴展和完善。隨著新的基準測試和評估指標的加入,AgentQuest將能夠覆蓋更多類型的任務和場景,為LLM智能體的評估提供更全面的視角。此外,隨著人工智能技術的進步,AgentQuest也可能會集成更先進的功能,如自動調整智能體架構的能力,以實現更高效的性能優化。
研究社區對AgentQuest的貢獻也是其發展不可或缺的一部分。開源的特性意味著研究人員可以共享他們的改進和創新,從而加速AgentQuest框架的進步。同時,研究社區的反饋和實踐經驗將幫助AgentQuest更好地滿足實際應用的需求,推動LLM智能體技術向前發展。
參考資料:https://arxiv.org/abs/2404.06411