MySQL 模糊查詢(xún)?cè)僖膊挥胠ike+%了
我們都知道 InnoDB 在模糊查詢(xún)數(shù)據(jù)時(shí)使用 "%xx" 會(huì)導(dǎo)致索引失效,但有時(shí)需求就是如此,類(lèi)似這樣的需求還有很多。
例如,搜索引擎需要根基用戶(hù)數(shù)據(jù)的關(guān)鍵字進(jìn)行全文查找,電子商務(wù)網(wǎng)站需要根據(jù)用戶(hù)的查詢(xún)條件,在可能需要在商品的詳細(xì)介紹中進(jìn)行查找,這些都不是 B+ 樹(shù)索引能很好完成的工作。

通過(guò)數(shù)值比較,范圍過(guò)濾等就可以完成絕大多數(shù)我們需要的查詢(xún)了。但是,如果希望通過(guò)關(guān)鍵字的匹配來(lái)進(jìn)行查詢(xún)過(guò)濾,那么就需要基于相似度的查詢(xún),而不是原來(lái)的精確數(shù)值比較,全文索引就是為這種場(chǎng)景設(shè)計(jì)的。
全文索引(Full-Text Search)是將存儲(chǔ)于數(shù)據(jù)庫(kù)中的整本書(shū)或整篇文章中的任意信息查找出來(lái)的技術(shù)。它可以根據(jù)需要獲得全文中有關(guān)章、節(jié)、段、句、詞等信息,也可以進(jìn)行各種統(tǒng)計(jì)和分析。
在早期的 MySQL 中,InnoDB 并不支持全文檢索技術(shù),從 MySQL 5.6 開(kāi)始,InnoDB 開(kāi)始支持全文檢索。
一、倒排索引
全文檢索通常使用倒排索引(inverted index)來(lái)實(shí)現(xiàn),倒排索引同 B+Tree 一樣,也是一種索引結(jié)構(gòu)。它在輔助表中存儲(chǔ)了單詞與單詞自身在一個(gè)或多個(gè)文檔中所在位置之間的映射。
這通常利用關(guān)聯(lián)數(shù)組實(shí)現(xiàn),擁有兩種表現(xiàn)形式:
- inverted file index:{單詞,單詞所在文檔的id}
- full inverted index:{單詞,(單詞所在文檔的id,再具體文檔中的位置)}
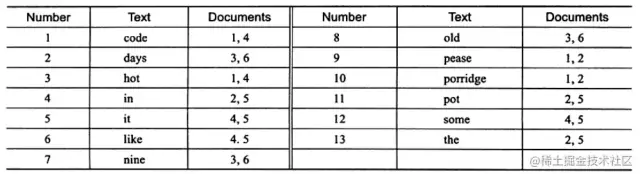
上圖為 inverted file index 關(guān)聯(lián)數(shù)組,可以看到其中單詞"code"存在于文檔1,4中,這樣存儲(chǔ)再進(jìn)行全文查詢(xún)就簡(jiǎn)單了,可以直接根據(jù) Documents 得到包含查詢(xún)關(guān)鍵字的文檔。
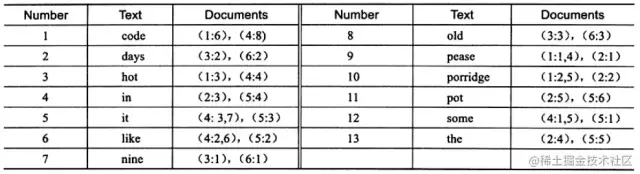
而 full inverted index 存儲(chǔ)的是對(duì),即(DocumentId,Position),因此其存儲(chǔ)的倒排索引如下圖,如關(guān)鍵字"code"存在于文檔 1 的第 6 個(gè)單詞和文檔 4 的第 8 個(gè)單詞。
相比之下,full inverted index 占用了更多的空間,但是能更好的定位數(shù)據(jù),并擴(kuò)充一些其他搜索特性。
二、全文檢索
1.創(chuàng)建全文索引
(1) 創(chuàng)建表時(shí)創(chuàng)建全文索引語(yǔ)法如下:
CREATE TABLE table_name ( id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY, author VARCHAR(200),
title VARCHAR(200), content TEXT(500), FULLTEXT full_index_name (col_name) ) ENGINE=InnoDB;輸入查詢(xún)語(yǔ)句:
SELECT table_id, name, space from INFORMATION_SCHEMA.INNODB_TABLES
WHERE name LIKE 'test/%';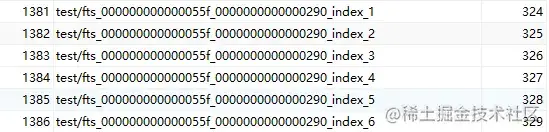
上述六個(gè)索引表構(gòu)成倒排索引,稱(chēng)為輔助索引表。當(dāng)傳入的文檔被標(biāo)記化時(shí),單個(gè)詞與位置信息和關(guān)聯(lián)的 DOC_ID,根據(jù)單詞的第一個(gè)字符的字符集排序權(quán)重,在六個(gè)索引表中對(duì)單詞進(jìn)行完全排序和分區(qū)。
(2) 在已創(chuàng)建的表上創(chuàng)建全文索引語(yǔ)法如下:
CREATE FULLTEXT INDEX full_index_name ON table_name(col_name);2.使用全文索引
MySQL 數(shù)據(jù)庫(kù)支持全文檢索的查詢(xún),全文索引只能在 InnoDB 或 MyISAM 的表上使用,并且只能用于創(chuàng)建 char,varchar,text 類(lèi)型的列。
其語(yǔ)法如下:
MATCH(col1,col2,...) AGAINST(expr[search_modifier])
search_modifier:
{
IN NATURAL LANGUAGE MODE
| IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
| IN BOOLEAN MODE
| WITH QUERY EXPANSION
}全文搜索使用 MATCH() AGAINST() 語(yǔ)法進(jìn)行,其中,MATCH() 采用逗號(hào)分隔的列表,命名要搜索的列。
AGAINST() 接收一個(gè)要搜索的字符串,以及一個(gè)要執(zhí)行的搜索類(lèi)型的可選修飾符。全文檢索分為三種類(lèi)型:自然語(yǔ)言搜索、布爾搜索、查詢(xún)擴(kuò)展搜索,下面將對(duì)各種查詢(xún)模式進(jìn)行介紹。
(1) Natural Language
自然語(yǔ)言搜索將搜索字符串解釋為自然人類(lèi)語(yǔ)言中的短語(yǔ),MATCH() 默認(rèn)采用 Natural Language 模式,其表示查詢(xún)帶有指定關(guān)鍵字的文檔。
接下來(lái)結(jié)合 demo 來(lái)更好的理解 Natural Language:
SELECT
count(*) AS count
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( 'MySQL' );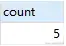
上述語(yǔ)句,查詢(xún) title,body 列中包含 'MySQL' 關(guān)鍵字的行數(shù)量。上述語(yǔ)句還可以這樣寫(xiě):
SELECT
count(IF(MATCH ( title, body )
against ( 'MySQL' ), 1, NULL )) AS count
FROM
`fts_articles`;上述兩種語(yǔ)句雖然得到的結(jié)果是一樣的,但從內(nèi)部運(yùn)行來(lái)看,第二句 SQL 的執(zhí)行速度更快些,因?yàn)榈谝痪?SQL(基于 where 索引查詢(xún)的方式)還需要進(jìn)行相關(guān)性的排序統(tǒng)計(jì),而第二種方式是不需要的。
還可以通過(guò) SQL 語(yǔ)句查詢(xún)相關(guān)性:
SELECT
*,
MATCH ( title, body ) against ( 'MySQL' ) AS Relevance
FROM
fts_articles;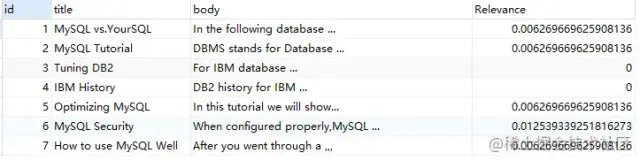
相關(guān)性的計(jì)算依據(jù)以下四個(gè)條件:
- word 是否在文檔中出現(xiàn)
- word 在文檔中出現(xiàn)的次數(shù)
- word 在索引列中的數(shù)量
- 多少個(gè)文檔包含該 word
對(duì)于 InnoDB 存儲(chǔ)引擎的全文檢索,還需要考慮以下的因素:
- 查詢(xún)的 word 在 stopword 列中,忽略該字符串的查詢(xún)
- 查詢(xún)的 word 的字符長(zhǎng)度是否在區(qū)間 [innodb_ft_min_token_size,innodb_ft_max_token_size] 內(nèi)
如果詞在 stopword 中,則不對(duì)該詞進(jìn)行查詢(xún),如對(duì) 'for' 這個(gè)詞進(jìn)行查詢(xún),結(jié)果如下所示:
SELECT
*,
MATCH ( title, body ) against ( 'for' ) AS Relevance
FROM
fts_articles;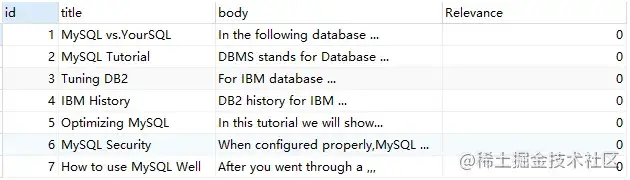
可以看到,'for'雖然在文檔 2,4 中出現(xiàn),但由于其是 stopword,故其相關(guān)性為 0。
參數(shù) innodb_ft_min_token_size 和 innodb_ft_max_token_size 控制 InnoDB 引擎查詢(xún)字符的長(zhǎng)度。
當(dāng)長(zhǎng)度小于 innodb_ft_min_token_size 或者長(zhǎng)度大于 innodb_ft_max_token_size 時(shí),會(huì)忽略該詞的搜索。
在 InnoDB 引擎中,參數(shù) innodb_ft_min_token_size 的默認(rèn)值是 3,innodb_ft_max_token_size 的默認(rèn)值是 84。
(2) Boolean
布爾搜索使用特殊查詢(xún)語(yǔ)言的規(guī)則來(lái)解釋搜索字符串,該字符串包含要搜索的詞,它還可以包含指定要求的運(yùn)算符,例如匹配行中必須存在或不存在某個(gè)詞,或者它的權(quán)重應(yīng)高于或低于通常情況。
例如,下面的語(yǔ)句要求查詢(xún)有字符串"Pease"但沒(méi)有"hot"的文檔,其中+和-分別表示單詞必須存在,或者一定不存在。
select * from fts_test where MATCH(content) AGAINST('+Pease -hot' IN BOOLEAN MODE);Boolean 全文檢索支持的類(lèi)型包括:
- +:表示該 word 必須存在
- -:表示該 word 必須不存在
- (no operator):表示該 word 是可選的,但是如果出現(xiàn),其相關(guān)性會(huì)更高
- @distance:表示查詢(xún)的多個(gè)單詞之間的距離是否在 distance 之內(nèi),distance 的單位是字節(jié),這種全文檢索的查詢(xún)也稱(chēng)為 Proximity Search,如 MATCH(context) AGAINST('"Pease hot"@30' IN BOOLEAN MODE)語(yǔ)句表示字符串 Pease 和 hot 之間的距離需在 30 字節(jié)內(nèi)
- >:表示出現(xiàn)該單詞時(shí)增加相關(guān)性
- <:表示出現(xiàn)該單詞時(shí)降低相關(guān)性
- ~:表示允許出現(xiàn)該單詞,但出現(xiàn)時(shí)相關(guān)性為負(fù)
- * :表示以該單詞開(kāi)頭的單詞,如 lik*,表示可以是 lik,like,likes
- " :表示短語(yǔ)
下面是一些 demo,看看 Boolean Mode 是如何使用的。
① demo1:+ -
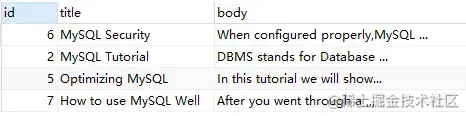
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( '+MySQL -YourSQL' IN BOOLEAN MODE );上述語(yǔ)句,查詢(xún)的是包含 'MySQL' 但不包含 'YourSQL' 的信息。
② demo2:no operator
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( 'MySQL IBM' IN BOOLEAN MODE );上述語(yǔ)句,查詢(xún)的 'MySQL IBM' 沒(méi)有 '+','-'的標(biāo)識(shí),代表 word 是可選的,如果出現(xiàn),其相關(guān)性會(huì)更高。
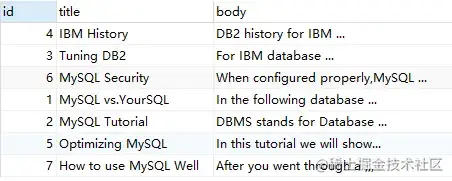
③ demo3:@
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( '"DB2 IBM"@3' IN BOOLEAN MODE );上述語(yǔ)句,代表 "DB2" ,"IBM"兩個(gè)詞之間的距離在 3 字節(jié)之內(nèi)。

④ demo4:> <
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( '+MySQL +(>database <DBMS)' IN BOOLEAN MODE );上述語(yǔ)句,查詢(xún)同時(shí)包含 'MySQL','database','DBMS' 的行信息,但不包含'DBMS'的行的相關(guān)性高于包含'DBMS'的行。

⑤ demo5: ~
SELECT
*
FROM
`fts_articles`
WHERE上述語(yǔ)句,查詢(xún)包含 'MySQL' 的行,但如果該行同時(shí)包含 'database',則降低相關(guān)性。

⑥ demo6:*
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( 'My*' IN BOOLEAN MODE );上述語(yǔ)句,查詢(xún)關(guān)鍵字中包含'My'的行信息。
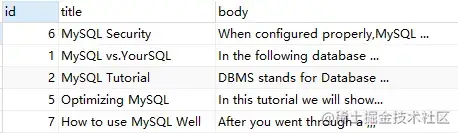
⑦ demo7:"
SELECT
*
FROM
`fts_articles`
WHERE
MATCH ( title, body ) AGAINST ( '"MySQL Security"' IN BOOLEAN MODE );上述語(yǔ)句,查詢(xún)包含確切短語(yǔ) 'MySQL Security' 的行信息。
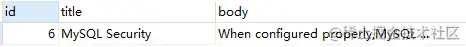
(3) Query Expansion
查詢(xún)擴(kuò)展搜索是對(duì)自然語(yǔ)言搜索的修改,這種查詢(xún)通常在查詢(xún)的關(guān)鍵詞太短,用戶(hù)需要 implied knowledge(隱含知識(shí))時(shí)進(jìn)行。
例如,對(duì)于單詞 database 的查詢(xún),用戶(hù)可能希望查詢(xún)的不僅僅是包含 database 的文檔,可能還指那些包含 MySQL、Oracle、RDBMS 的單詞,而這時(shí)可以使用 Query Expansion 模式來(lái)開(kāi)啟全文檢索的 implied knowledge。
通過(guò)在查詢(xún)語(yǔ)句中添加 WITH QUERY EXPANSION / IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION 可以開(kāi)啟 blind query expansion(又稱(chēng)為 automatic relevance feedback)。
該查詢(xún)分為兩個(gè)階段:
- 第一階段:根據(jù)搜索的單詞進(jìn)行全文索引查詢(xún)
- 第二階段:根據(jù)第一階段產(chǎn)生的分詞再進(jìn)行一次全文檢索的查詢(xún)
接著來(lái)看一個(gè)例子,看看 Query Expansion 是如何使用的。
-- 創(chuàng)建索引
create FULLTEXT INDEX title_body_index on fts_articles(title,body);
-- 使用 Natural Language 模式查詢(xún)
SELECT
*
FROM
`fts_articles`
WHERE
MATCH(title,body) AGAINST('database');使用 Query Expansion 前查詢(xún)結(jié)果如下:
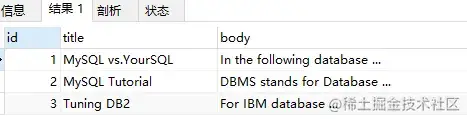
-- 當(dāng)使用 Query Expansion 模式查詢(xún)
SELECT
*
FROM
`fts_articles`
WHERE
MATCH(title,body) AGAINST('database' WITH QUERY expansion);使用 Query Expansion 后查詢(xún)結(jié)果如下:
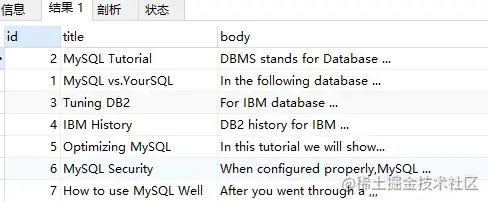
由于 Query Expansion 的全文檢索可能帶來(lái)許多非相關(guān)性的查詢(xún),因此在使用時(shí),用戶(hù)可能需要非常謹(jǐn)慎。
3.刪除全文索引
①直接刪除全文索引語(yǔ)法如下:
DROP INDEX full_idx_name ON db_name.table_name;②使用 alter table 刪除全文索引語(yǔ)法如下:
ALTER TABLE db_name.table_name DROP INDEX full_idx_name;小結(jié)
本文從理論與實(shí)踐結(jié)合的角度對(duì) fulltext index 做了介紹。InnoDB 的全文檢索在一些簡(jiǎn)單的搜索場(chǎng)景下還是比較實(shí)用的,可以替代 like+%,并且不需要額外依賴(lài)其他服務(wù)。復(fù)雜搜索場(chǎng)景的話(huà),我們還是需要使用 ES 這類(lèi)搜索引擎。