













系統設計:通過示例理解 MapReduce
一、問題:如何分析海量數據集
想象一下,您有數千億字節的網站日志,跟蹤每位訪問者的互動,現在您希望從中篩選出一些信息,比如哪些頁面最受歡迎,訪問者在購買流程中的流失情況等。
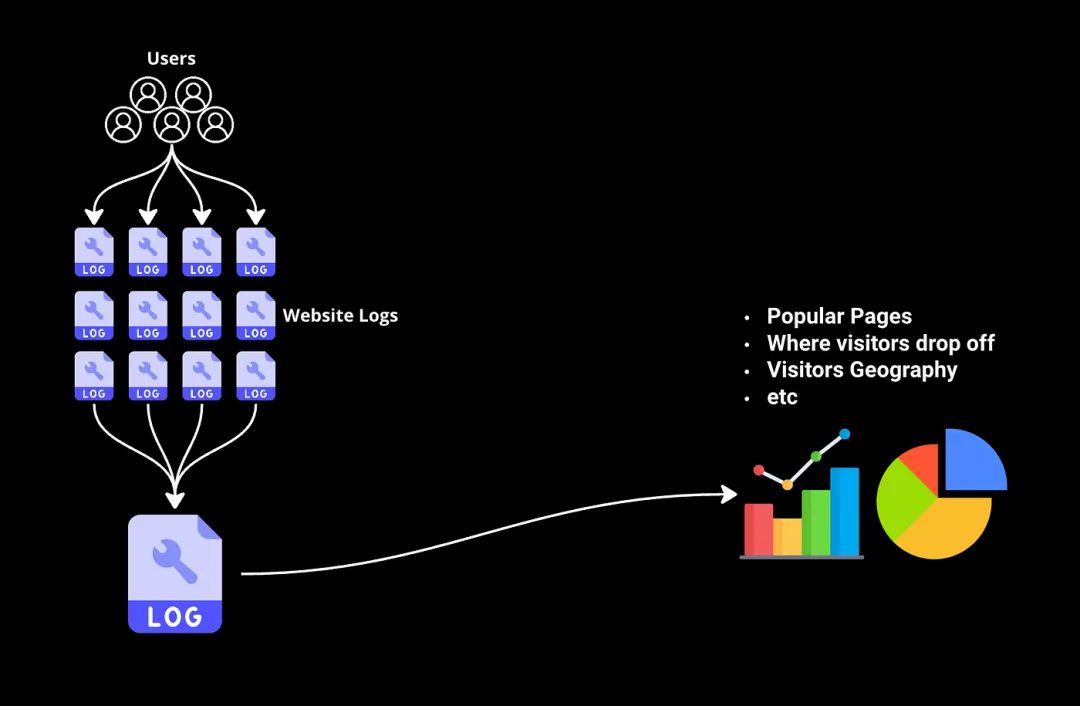
傳統工具和數據庫簡直無法處理這種規模的數據集。這就是MapReduce派上用場的地方。
什么是MapReduce?
MapReduce是一種專門設計用于處理無法在單臺計算機上處理的大規模數據挑戰的編程模型。它由Google于2004年提出,旨在解決這類場景。讓我們通過網站日志示例看看它是如何工作的…
二、MapReduce如何處理大數據
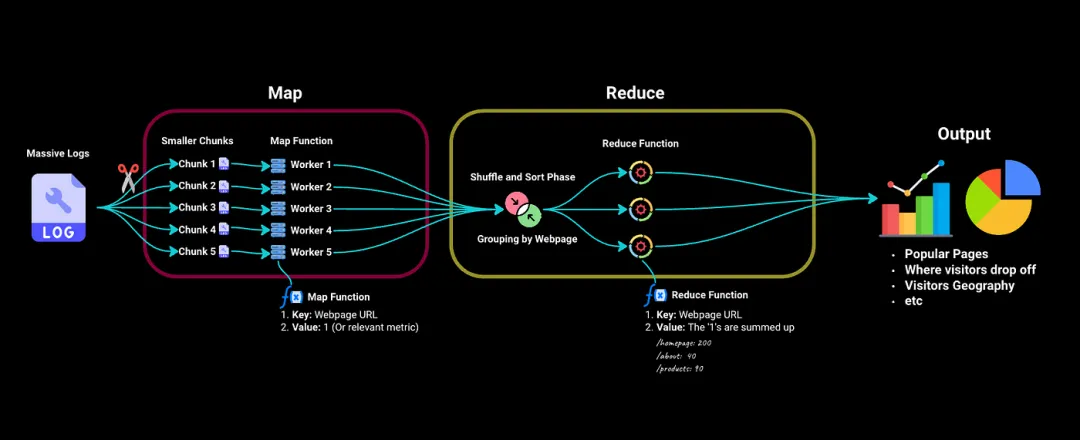
MapReduce分為兩個主要階段 —— Map階段和Reduce階段。
1.Map階段
在Map階段,我們首先將這些龐大的日志拆分為更小且易處理的塊。然后將這些塊發送到集群中的不同工作計算機。
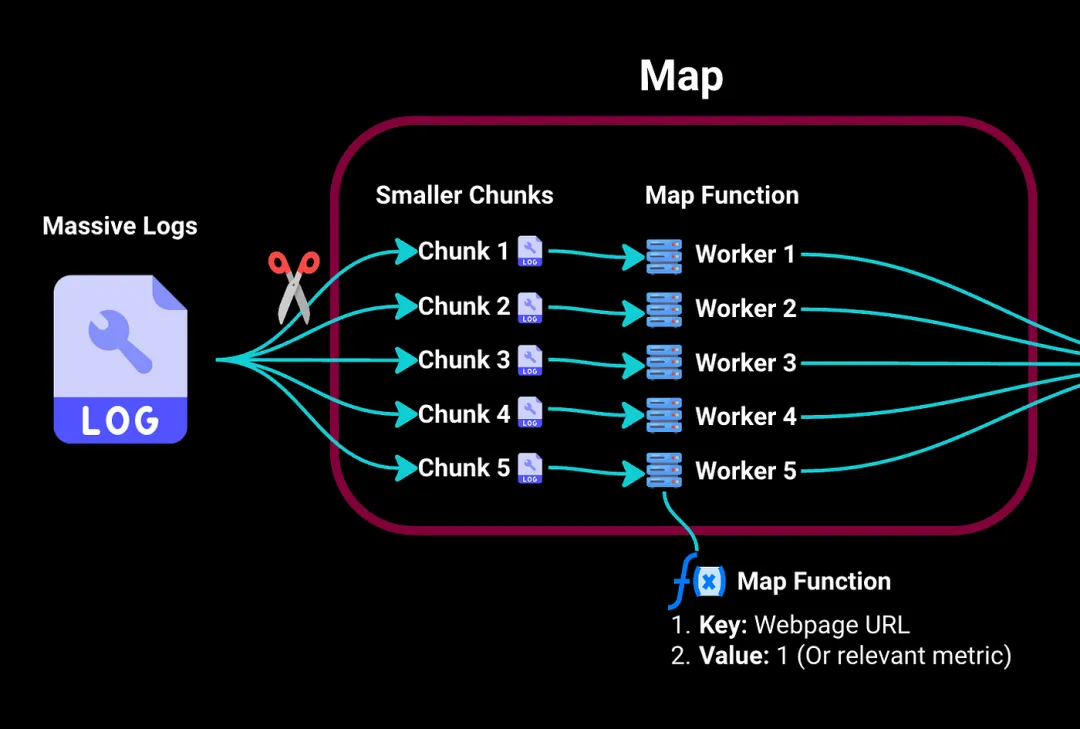
將每個工作計算機視為處理其分配塊的獨立服務器。它具有一個映射函數,用于提取關鍵信息:在我們的示例中,它將鍵(即特定訪問的網頁)映射到值,例如,如果我們要計算訪問次數,值可以是訪問該頁面的次數(例如,1)。
2.Reduce階段
然后,我們進入Reduce階段,其中由Map階段生成的所有鍵值對都會按網頁('key')進行排序和分組。
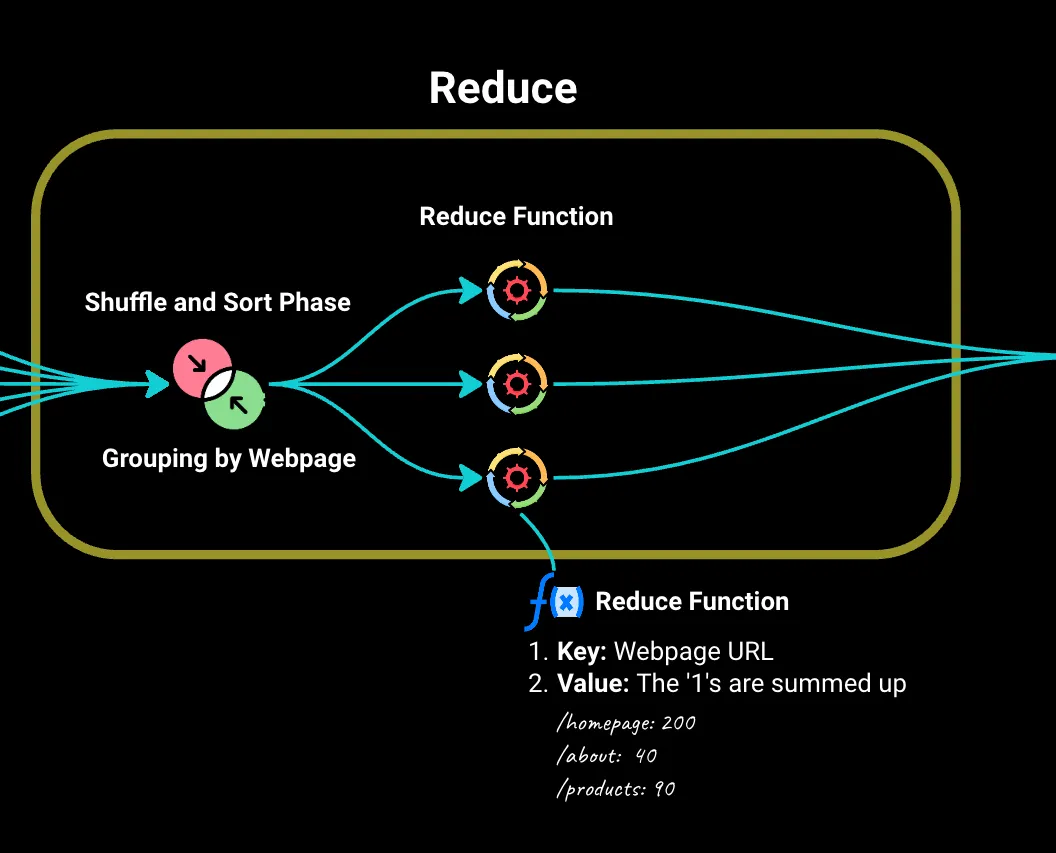
我們將這些發送到Reduce函數。對于每個唯一的網頁,它會將‘1’值相加以找到總訪問量。它還可以處理更復雜的問題,如平均停留時間、訪客人口統計等。
現在,使用這些信息,我們可以通過圖表和其他可視化方式展示。
MapReduce在日志分析中的優勢:
- 并行處理能力: 分發工作使處理速度比單臺計算機更快。
- 可擴展性: 有更多的日志數據?只需向集群中添加更多計算機,MapReduce就可以跟上。
- 容錯性: 如果計算機在作業過程中發生故障,MapReduce會自動將其工作重新分配給網絡中的其他計算機。這確保所有任務都能成功完成,而不會中斷。
三、批處理與流處理
為了理解MapReduce的獨特之處,讓我們簡要談談批處理與流處理:
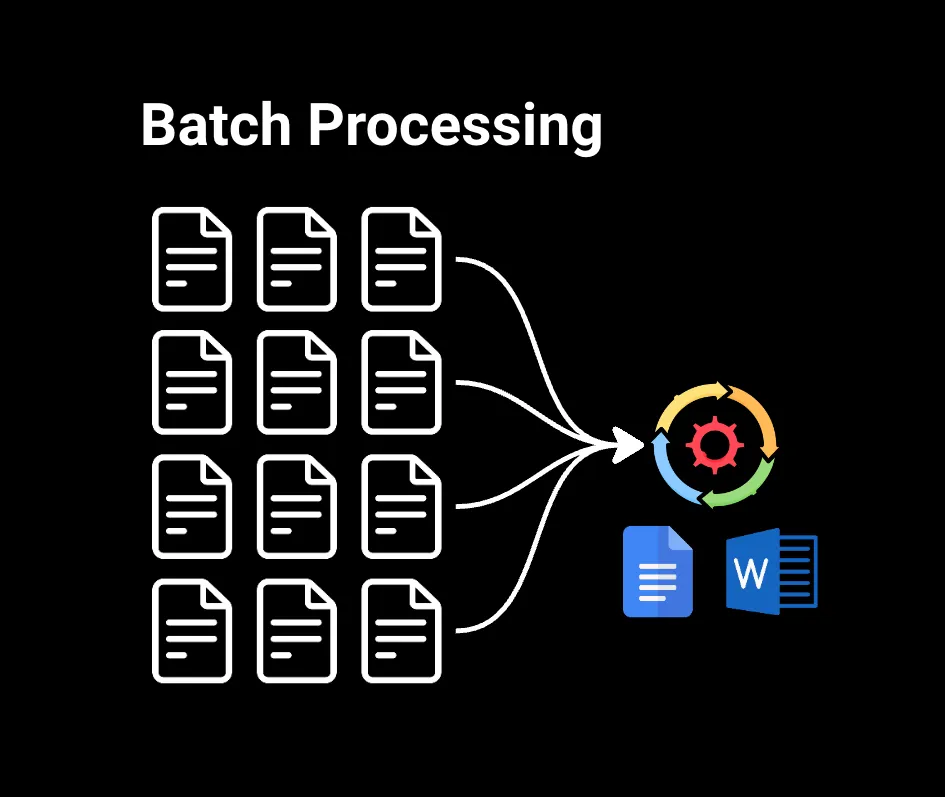
1.批處理
批處理處理已收集的大塊數據。例如,如果您在Google Docs或Microsoft Word中搜索大型文件中的單詞,數據已經準備好,因此可以立即進行處理。這對于需要處理大型數據集且不需要立即結果的情況非常有用,比如生成月度銷售報告、分析客戶購買歷史記錄或對數據進行機器學習模型訓練。
2.流處理
流處理以連續流的形式處理數據。例如,觀看YouTube視頻時,您點擊‘播放’,視頻幾乎立即開始播放。這是因為視頻的微小片段以連續流的方式發送到您的計算機,讓您在其余視頻還在傳輸中時即可觀看。
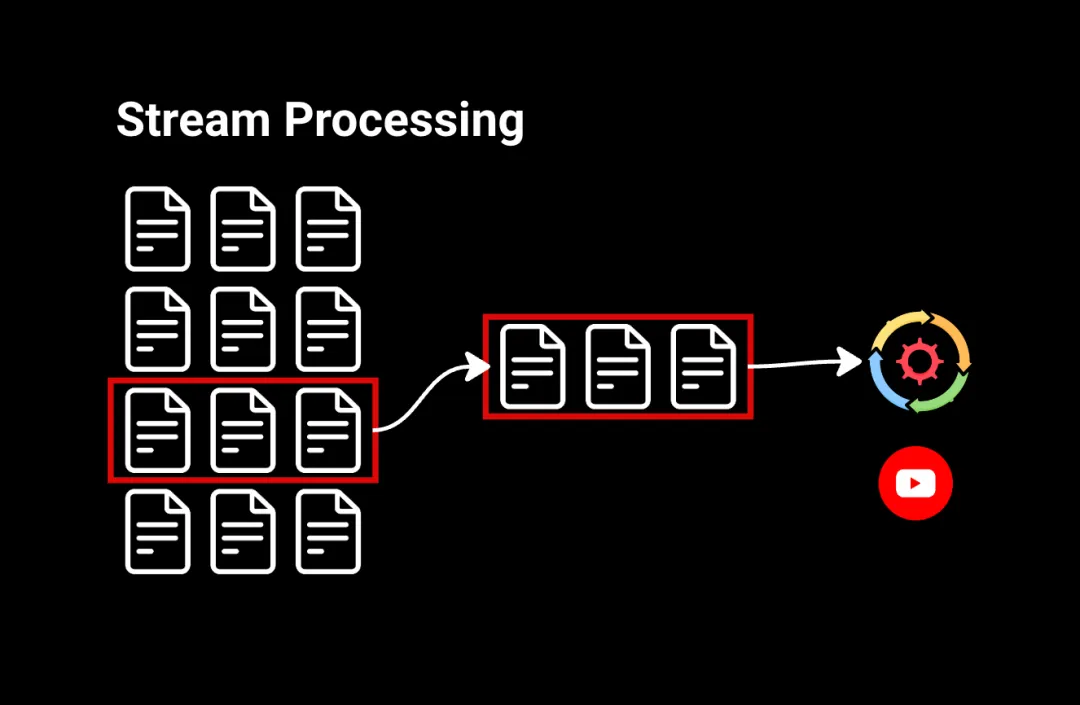
流處理適用于需要對數據流進行即時操作的情況,比如識別金融交易中的可疑活動或在社交媒體信息流中進行實時分析。
3.微批處理
我們還有微批處理,這是一種混合方法,彌合了傳統批處理和流處理之間的差距。
微批處理不是將所有數據一次性處理,而是將數據拆分為非常小的批次。這些批次在短時間的固定間隔內(通常是幾秒或幾分鐘)進行處理。
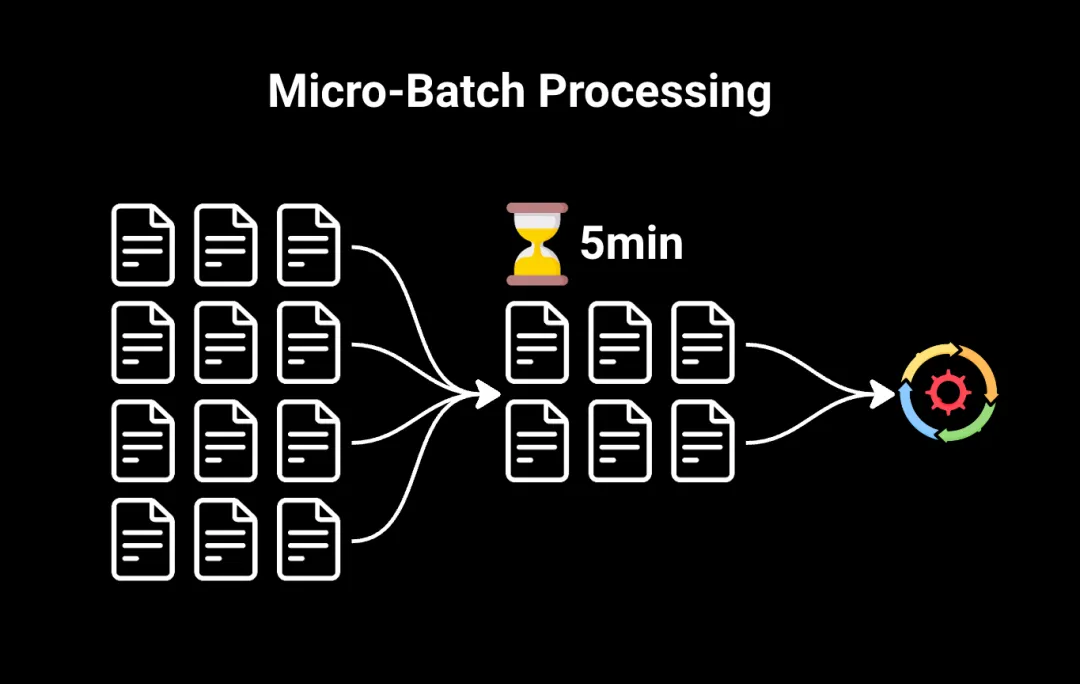
微批處理通常是需要比傳統批處理更快結果的情況下的首選方法,但不需要完全的流處理。
4.MapReduce使用的處理方法是什么?
MapReduce是一種批處理模型,因為它處理的是已經存儲的數據,而不是實時連續流的數據。在MapReduce的Map階段開始之前,輸入數據需要被劃分和分發。
可以想象,批處理比流處理更慢,因為需要在處理之前積累數據。但是,批處理通常更簡單易用,而流處理可能更復雜,因為數據不斷流動,存在錯誤或不一致性的可能性。
四、MapReduce的局限性和現代替代方案
盡管MapReduce具有革命性,但在迭代和復雜數據處理任務的速度和靈活性方面存在局限性。這就是Apache Spark等工具發揮作用的地方。
1.Apache Spark
Spark利用內存處理,即將數據保留在RAM中進行非常快速的計算,與MapReduce依賴磁盤存儲相比。它處理更廣泛的任務,包括SQL查詢、機器學習和實時數據處理(流處理)。
2.Apache Flink
Apache Flink是另一個用于實時數據處理(流處理)的強大框架。它提供類似于Spark Streaming的功能,允許在數據到達時立即進行分析。這是專門用于需要實時數據分析的場景的工具,通常與Spark配合使用,構建完整的大數據處理工具包。
3.Hadoop
Hadoop是一個更廣泛的生態系統,為Spark和MapReduce等工具提供運行基礎。它包括一個分布式文件系統(HDFS)用于在多臺計算機上存儲大型數據集,以及一個資源管理系統(YARN**)用于將資源(CPU、內存)分配給應用程序,如Spark或MapReduce。
可以將其視為Spark和其他工具用于管理和存儲大數據的基礎設施。
4.云服務(AWS、Azure、GCP)
AWS、Azure和Google等云提供商提供托管的數據處理解決方案,通常簡化了MapReduce框架的使用。這些包括支持Hadoop的AWS EMR、Azure HDInsight和Google Cloud Dataflow(Google對經典MapReduce的后繼產品,旨在處理批處理和流處理數據)。
五、總結
盡管對于大多數現代大數據批處理任務來說,Spark取代了MapReduce,但理解MapReduce仍然很重要,因為它為理解這些強大工具的工作原理提供了堅實的基礎。
















