Python提速秘籍:九個讓你的代碼飛速運行的巧妙技巧!
引言
“Python太慢了。”這種觀點在編程語言的討論中頻頻出現,常常使人忽視Python的眾多優點。
但事實真的如此嗎?與普遍看法相反,如果你掌握了Python式的編程技巧,Python其實可以像冠軍選手一樣快速奔跑。
在表面之下,精通Python的開發者們掌握著一系列微妙而強大的技巧,這些技巧能顯著提升他們代碼的性能,遠超常規水平。這些不僅僅是技巧,它們甚至改變了游戲規則。
今天,我們將揭示九種變革性的策略,這些策略可以徹底改變你對Python編程的看法。這些策略乍看之下或許很簡單,但它們具有強大的效力,能以你從未想象的方式提升效率。準備好給你的Python技能加速了嗎?讓我們深入了解并開始優化吧!
1.join 或 +:更快的字符串連接
如果你的程序中經常進行字符串操作,那么字符串連接可能會成為你的 Python 程序的瓶頸。
基本上,在 Python 中有兩種字符串連接的方法:
- 使用join()函數將一系列字符串合并為一個
- 使用+或+=符號逐一將每個字符串添加到一個中
那么哪種方法更快?廢話少說,下面我們使用3種不同的方式連接相同的字符串:
str_list = ['Facts', 'speak', 'louder', 'than', 'words!']
# 使用 + 號
def concat_plus(strings):
result = ''
for word in strings:
result += word + ' '
return result
# 使用 join() 方法
def concat_join(strings):
return ' '.join(strings)
# 直接連接
def concat_directly():
return 'Facts' + 'speak' + 'louder' + 'than' + 'words!'根據您那作為男士or女士神奇的第六感(????),悄悄告訴我您認為哪個函數速度最快,哪個最慢?實際結果可能會讓您感到驚訝哦??????:
import timeit
print(f'The plus symbol: {timeit.timeit(concat_plus, number=10000)}')
print(f'The join function: {timeit.timeit(concat_join, number=10000)}')
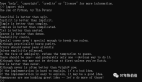
print(f'The direct concatenation: {timeit.timeit(concat_directly, number=10000)}') 圖片
圖片
如上所示,對于字符串連接,join() 方法比通過循環逐個添加字符串要快。
原因很簡單。一方面,在Python中,字符串是不可變數據,每個 += 操作都會伴隨新字符串變量的創建和舊字符串的復制,這會額外消耗更多的計算資源。另一方面,.join() 方法專門針對連接列表字符串進行了優化。它預先計算生成字符串的大小,然后一次性為其分配存儲空間。因此,它避免了循環中的 += 操作帶來的開銷,因此更快。
然而,在我們的測試中,最快的函數是直接連接字符串字面量。其高速度歸結于:
- Python 解釋器可以在編譯時優化字符串字面值的連接,將它們轉換為單個字符串字面值。這里沒有涉及到循環迭代或函數調用,因此操作效率非常高。
- 由于在編譯時已知所有字符串,Python 可以非常快速地執行此操作,比在循環中運行時連接甚至優化過的 .join() 方法都要快得多。
總之,如果您需要連接字符串列表,請選擇 join() 而不是 +=。如果您想直接連接字符串,只需使用 + 即可。
2.更快的列表創建:選擇“[]”而非“list()”
創建列表并不困難。兩種常見的方法是:
- 使用 list() 函數
- 直接使用 []:
import timeit
print('The List Creation:')
print(f"[]: {timeit.timeit('[]', number=10 ** 7)}")
print(f'The list function: {timeit.timeit(list, number=10 ** 7)}') 圖片
圖片
正如結果所示,直接使用 [] 比執行 list() 函數要快差不多2倍。這是因為 [] 是一種字面語法,而 list() 是一個構造函數調用。毫無疑問,調用函數需要額外的時間。相同的邏輯,在創建字典時,我們也應該利用 {} 而不是 dict()。
3.更快的成員檢查:用 Set 而不用 List
成員檢查操作的性能在很大程度上取決于底層數據結構,一起來看看下面這個例子:
import timeit
target_dataset = range(1000000)
search_element = 1314
target_list = list(target_dataset)
target_set = set(target_dataset)
def list_membership_test():
return search_element in target_list
def set_membership_test():
return search_element in target_set
print(f'The list membership test: {timeit.timeit(list_membership_test, number=1000)}')
print(f'The set membership test: {timeit.timeit(set_membership_test, number=1000)}') 圖片
圖片
結果顯示,在集合中進行成員檢查比在列表中快得多。我還發現一個問題,那就是搜索的元素越靠前則耗時越短,如果搜索一個不存在的元素則耗時最長。上面我們搜索的目標元素是1314,如果我們搜索一個不存在的元素1314520,則明顯耗時更多:
 圖片
圖片
因為搜索一個不存在的元素必須遍歷完整個列表或集合。By the way,從這個例子可以看出要做到一生一世(1314)很容易,因為每個人生來便有,但是要做到一生一世我愛你(1314520)卻并不簡單,因為需要付出更多的代價。哈哈??????,開個玩笑,扯遠了,權當是給您枯燥的閱讀帶來一點小樂趣!
回到主題,為什么成員檢查用集合比列表更快呢?
- 在Python列表中,成員檢查(element in list)是通過迭代每個元素直到找到所需元素或達到列表末尾來執行的。因此,這個操作的時間復雜度為O(n)。
- 在Python中,集合用哈希表實現。在檢查成員關系(element in set)時,Python使用哈希機制,其時間復雜度平均為O(1)。
這里的要點是在編寫程序時仔細考慮底層數據結構。利用正確的數據結構可以顯著加快我們的代碼速度。
4.更快的數據生成:用推導式而不用 for 循環
Python 中有四種推導式:列表、字典、集合和生成器。它們不僅提供更簡潔的語法來創建相關的數據結構,而且比使用 for 循環的性能更好。因為它們使用 C 語言實現的,性能進行了優化。
一起看看下面這個生成1-10000的立方示例:
import timeit
def generate_cubes_for_loop():
cubes = []
for i in range(10000):
cubes.append(i * i * i)
return cubes
def generate_cubes_comprehension():
return [i * i * i for i in range(10000)]
print(f'For loop: {timeit.timeit(generate_cubes_for_loop, number=10000)}')
print(f'Comprehension: {timeit.timeit(generate_cubes_comprehension, number=10000)}')上述代碼只是列表推導式和 for 循環之間的簡單速度比較。正如如結果所示,列表推導式更快。
5.更快的循環:優先用局部變量
在Python中,訪問局部變量比訪問全局變量或對象屬性要快。這里用一個簡單例子來證明這一點:
import timeit
class Test:
def __init__(self):
self.value = 0
obj = Test()
def access_global_variable():
for _ in range(1000):
obj.value += 1
def access_local_variable():
value = obj.value
for _ in range(1000):
value += 1
print(f'Access global variable: {timeit.timeit(access_global_variable, number=1000)}')
print(f'Access local variable: {timeit.timeit(access_local_variable, number=1000)}')這就是 Python 的工作原理。直觀地說,當函數編譯時,其中的局部變量是已知的,但其他外部變量則需要時間來檢索。
這只是一個很小的改良,但有時候我們缺可以利用它來優化我們的代碼,特別是在處理大數據集時。
6.更快的執行:優先使用內置模塊和庫
當工程師們說 Python 時,默認是指 CPython。因為 CPython 是 Python 語言的默認和最廣泛使用的實現。
考慮到大多數內置模塊和庫都是用更快速和更底層的語言 C 編寫的,我們應該盡可能利用這些內置工具并避免重復發明輪子。
import timeit
import random
from collections import Counter
def counter_custom(lst):
frequency = {}
for item in lst:
if item in frequency:
frequency[item] += 1
else:
frequency[item] = 1
return frequency
def counter_builtin(lst):
return Counter(lst)
target_dataset = [random.randint(0, 100) for _ in range(1000)]
print(f'Counter custom: {timeit.timeit(lambda: counter_custom(target_dataset), number=100)}')
print(f'Counter builtin: {timeit.timeit(lambda: counter_custom(target_dataset), number=100)}')這里比較了在列表中計算元素頻率的兩種方法。正如我們所看到的,利用 collections 模塊中的內置 Counter 比自己編寫 for 循環更快,更整潔,更好(但有時候自定義的性能又會比內置模塊更好,尚不知道原因)。
7.更快的函數調用:利用緩存裝飾器
緩存是一種常用的技術,用于避免重復計算并加快程序的運行速度。幸運的是,在大多數情況下,我們不需要編寫自己的緩存處理代碼,因為Python提供了一個用于此目的的開箱即用的裝飾器 — @functools.cache。
例如,以下代碼將執行兩個斐波那契數生成函數,一個帶有緩存裝飾器,而另一個沒有:
import timeit
from functools import cache
def fibonacci_norm(n):
if n <= 1:
return n
return fibonacci_norm(n - 1) + fibonacci_norm(n - 2)
@cache
def fibonacci_cached(n):
if n <= 1:
return n
return fibonacci_cached(n - 1) + fibonacci_cached(n - 2)
print(f'fibonacci normal: {timeit.timeit(lambda: fibonacci_norm(30), number=1)}')
print(f'fibonacci cached: {timeit.timeit(lambda: fibonacci_cached(30), number=1)}')結果顯示 cache 裝飾器版本比普通版本的速度快得多。
普通的斐波那契函數效率低下,因為在獲取 fibonacci(30) 的結果過程中,它多次重新計算相同的斐波那契數。
緩存版本明顯更快,因為它緩存了先前計算的結果。因此,每個斐波那契數它只計算一次,并且使用相同參數進行的后續調用都從緩存中獲取。
僅僅添加一個內置裝飾器就可以帶來如此大的性能提升,這就是 Pythonic 的意義所在。??
8.更快的無限循環: 優先選擇“while 1”而不是“while True”
要創建一個無限循環,我們可以使用 while True 或 while 1 。它們的性能差異通常是可以忽略的。但有趣的是 while 1 稍微更快。這源于 1 是字面值,而 True 是 Python 全局范圍內需要查找的全局名稱,因此需要微小的額外開銷。
我們也通過一個簡單的示例比較這兩種方式的性能:
import timeit
def infinite_loop_with_true():
result = 0
while True:
if result >= 10000:
break
result += 1
def infinite_loop_with_one():
result = 0
while 1:
if result >= 10000:
break
result += 1
print(f'Infinite loop with true: {timeit.timeit(infinite_loop_with_true, number=10000)}')
print(f'Infinite loop with one: {timeit.timeit(infinite_loop_with_one, number=10000)}')正如我們所看到的,while 1 確實略快。但是,現代 Python 解釋器(如CPython)經過高度優化,這樣的差異通常微不足道。因此,我們無需在意這種微不足道的差異。另外,從代碼可讀性角度來說,其實 while True 的可讀性比 while 1 更強。
9.更快的腳本啟動:智能導入Python模塊
通常情況下,我們都習慣在Python 腳本頂部導入所有模塊。事實上,有些時候不必這樣做。此外,如果模塊太大,則按需導入可能會是一個更好的主意。比如,在用到模塊的函數內部導入:
def target_function():
import specific_module
# rest of the function如上面的代碼所示,specific_module 在函數內部執行導入操作。這是“惰性加載”的思想,在函數調用時才導入指定模塊。
這種方法的好處是,如果在腳本執行期間從未調用 target_function,則永遠不會加載 specific_module,從而節省資源并減少腳本的啟動時間。