什么是最左前綴匹配?為什么要遵守?
在 MySQL 中,最左前綴匹配指的是在查詢時利用索引的最左邊部分進行匹配。當你執行查詢時,如果查詢條件涉及到組合索引的前幾個列,MySQL 就能夠利用該復合索引來進行匹配。
組合索引即由多個字段組成的聯合索引,比如 idx_col1_col2_col3 (col1,col2,col3)。
假設我們創建了一個組合索引 (col1, col2, col3),如果查詢條件是針對 col1、(col1, col2) 或者 (col1, col2, col3),那么 MySQL 就能利用該復合索引進行最左前綴匹配。
然而,如果查詢條件只涉及到 col2、只涉及到 col3 或者只涉及到 col2 和 col3,也就是沒有包含 col1,那么通常情況下(不考慮索引跳躍掃描等其他優化),就無法利用該索引進行最左前綴匹配。
值得注意的是,最左前綴匹配與查詢條件的順序無關。無論你寫的是 where col1 = "Paidaxing" and col2 = "666" 還是 where col2 = "666" and col1 = "Paidaxing",對結果都沒有影響,命中的結果仍然一樣。
此外,需要大家注意的是,許多人可能會誤以為創建一個組合索引 (col1, col2, col3) 時,數據庫會創建三個索引 (col1)、(col1, col2) 和 (col1, col2, col3),這樣的理解其實是不正確的。實際上,數據庫只會創建一棵 B+樹,只不過在這顆樹中,首先按照 col1 進行排序,然后在 col1 相同時再按照 col2 排序,col2 相同再按照 col3 排序。
另外,如果沒有涉及到聯合索引,單個字段的索引也需要遵守最左前綴原則。即當一個字段的值為"abc"時,當我們使用 like 進行模糊匹配時,like "ab%" 是可以利用索引的,而 "%bc"則不行,因為后者不符合最左前綴匹配的原則。
為什么要遵循最左前綴匹配
我們都了解,在 MySQL 的 InnoDB 引擎中,索引是通過 B+樹來實現的。不論是普通索引還是聯合索引,都必須構建 B+樹的索引結構。
針對普通索引,其存儲結構是在 B+樹的每個非葉子節點上記錄索引的值,而在 B+樹的葉子節點上,則記錄了索引的值和聚簇索引(主鍵索引)的值。
如:
 圖片
圖片
在聯合索引中,比如聯合索引 (age, name),同樣也是構建了一棵 B+樹。在這棵 B+樹中,非葉子節點中記錄的是 name 和 age 兩個字段的值,而在葉子節點中記錄的是 name、age 兩個字段以及主鍵 id 的值。
 圖片
圖片
在存儲過程中,如上所述,當 age 不同時,按照 age 排序;當 age 相同時,則按照 name 排序。
因此,了解了索引的存儲結構之后,我們就很容易理解最左前綴匹配了:由于索引底層是一棵 B+樹,如果是聯合索引的話,在構造 B+樹時,會先按照左邊的鍵進行排序,當左邊的鍵相同時,再依次按照右邊的鍵進行排序。
因此,在通過索引查詢時,也需要遵守最左前綴匹配的原則,即需要從聯合索引的最左邊開始進行匹配。這就要求查詢語句的 WHERE 條件中包含最左邊的索引值。
MySQL 索引一定遵循最左前綴匹配嗎?
因為索引底層是一個 B+樹,如果是聯合索引的話,在構造 B+樹的過程中,會先按照左邊的鍵進行排序。當左邊的鍵相同時,再依次按照右邊的鍵排序。
因此,在通過索引進行查詢時,也需要遵守最左前綴匹配的原則,即需要從聯合索引的最左邊開始進行匹配。這就要求查詢語句的 WHERE 條件中包含最左邊的索引值。這就是最左前綴匹配的概念。
在 MySQL 之前的版本中,一直都是遵循最左前綴匹配的原則,這句話在以前是正確的,沒有任何問題。但是在 MySQL 8.0 中,情況就有所不同了。因為在 8.0.13 中引入了索引跳躍掃描的特性。
補充知識
索引跳躍掃描
MySQL 8.0.13 版本引入了索引跳躍掃描(Index Skip Scan)優化,對于 range 查詢提供了支持。即使不符合組合索引最左前綴原則的條件下,SQL 依然能夠使用組合索引,從而減少不必要的掃描。
讓我們通過一個例子來解釋一下。首先,我們有下面這樣一張表(參考了 MySQL 官網的例子,但經過了一些改動和優化):
CREATE TABLE t1 (f1 INT NOT NULL, f2 INT NOT NULL);
CREATE INDEX idx_t on t1(f1,f2);
INSERT INTO t1 VALUES
(1,1), (1,2), (1,3), (1,4), (1,5),
(2,1), (2,2), (2,3), (2,4), (2,5);
INSERT INTO t1 SELECT f1, f2 + 5 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 10 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 20 FROM t1;
INSERT INTO t1 SELECT f1, f2 + 40 FROM t1;通過以下 SQL 語句,先創建一張名為 t1 的表,并將字段 f1 和 f2 設置為聯合索引。然后向其中插入一些記錄。
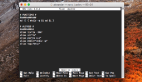
接著,分別在 MySQL 5.7.9 和 MySQL 8.0.30 上執行EXPLAIN SELECT f1, f2 FROM t1 WHERE f2 = 40;。
 圖片
圖片
可以看到,主要有以下幾個區別:
MySQL 5.7 中,type = index,rows=160,extra=Using where;Using index
MySQL 8.0 中,type = range,rows=16,extra=Using where;Using index for skip scan
type 字段表示掃描方式,其中 range 表示范圍掃描,而 index 表示索引樹掃描。通常情況下,范圍掃描要比索引樹掃描快得多。
通過 rows 字段也能夠觀察到這一點,使用索引樹掃描的方式共掃描了 160 行,而范圍掃描方式只掃描了 16 行。
然后,關鍵在于為什么 MySQL 8.0 中的掃描方式更快呢?這主要是因為采用了"Using index for skip scan"的技術。
換句話說,盡管我們的 SQL 沒有遵循最左前綴原則,僅僅使用了 f2 作為查詢條件,但經過 MySQL 8.0 的優化,仍然通過索引跳躍掃描的方式利用了索引。
優化原理
那么他是怎么優化的呢?在 MySQL 8.0.13 及以后的版本中,執行SELECT f1, f2 FROM t1 WHERE f2 = 40;的過程如下:
- 獲取 f1 字段的第一個唯一值,即 f1=1。
- 構造條件f1=1 and f2=40,進行范圍查詢。
- 獲取 f1 字段的第二個唯一值,即 f1=2。
- 構造條件f1=2 and f2=40,進行范圍查詢。
- 重復上述步驟,直到掃描完 f1 字段的所有唯一值。
- 最后將結果合并并返回。
換句話說,最終執行的 SQL 語句類似于下面的形式:
SELECT f1, f2 FROM t1 WHERE f1 =1 and f2 = 40
UNION
SELECT f1, f2 FROM t1 WHERE f1 =2 and f2 = 40;即,MySQL 的優化器幫我們把聯合索引中的 f1 字段作為查詢條件進行查詢了。
在了解了索引跳躍掃描的執行過程后,一些聰明的讀者可能會意識到,這種查詢優化更適用于具有較少取值范圍和低區分度的字段(比如性別),而當字段的區分度特別高時(比如出生年月日),這種查詢可能會變得更慢。
因此,是否使用索引跳躍掃描,實際上取決于 MySQL 優化器經過成本預估后做出的決定。
通常情況下,這種優化技術適用于聯合索引中第一個字段的區分度較低的情況。但需要注意的是,并非絕對如此。盡管一般情況下我們不太會將區分度較低的字段放在聯合索引的左邊,但 MySQL 提供了這樣的優化方案,這說明確實存在這樣的需求。
然而,我們不應該過度依賴這種優化。在建立索引時,仍然應優先考慮將區分度高且頻繁查詢的字段放置在聯合索引的左邊。
此外,在 MySQL 官網中還提到了索引跳躍掃描的其他一些限制條件:
- 表 T 必須至少有一個聯合索引,但對于聯合索引(A,B,C,D),A 和 D 可以為空,但 B 和 C 必須非空。
- 查詢只能依賴于單張表,不能進行多表連接。
- 查詢中不能使用 GROUP BY 或 DISTINCT 語句。
- 查詢的字段必須是索引中的列。