













從大模型(LLM)、檢索增強生成(RAG)到智能體(Agent)的應用
引言
隨著人工智能技術的飛速發展,大型語言模型(LLM)、檢索增強生成(RAG)和智能體(Agent)已經成為推動該領域進步的關鍵技術,這些技術不僅改變了我們與機器的交互方式,而且為各種應用和服務的開發提供了前所未有的可能性。正確理解這三者的概念及其之間的關系是做好面向AI編程開發的基礎:
大模型(LLM) | 檢索增強生成(RAG) | 智能體(Agent) | |
定義 | 大型語言模型(LLM),如GPT系列、BERT等,是利用大量文本數據訓練的模型,能夠生成連貫的文本、理解語言、回答問題等。 | 檢索增強生成技術結合了傳統的信息檢索技術和最新的生成式模型。它先從一個大型的知識庫中檢索出與查詢最相關的信息,然后基于這些信息生成回答。 | 智能體是指具有一定智能的程序或設備,能夠感知環境并根據感知結果做出響應或決策的實體。它們可以是簡單的軟件程序或復雜的機器人。 |
作用 | LLM作為基礎技術,提供了強大的語言理解和生成能力,是構建復雜人工智能系統的基石。 | RAG可以視為在LLM基礎上的擴展或應用,利用LLM的生成能力和外部知識庫的豐富信息來提供更準確、信息豐富的輸出。 | 智能體可以利用LLM進行自然語言處理,通過RAG技術獲得和利用知識,以在更廣泛的環境中做出決策和執行任務。它們通常位于應用層級,是對LLM和RAG技術在特定環境下的集成和應用。 |
從層級關系上看,大模型(LLM)提供了基礎的語言理解和生成能力。在此基礎上,檢索增強生成(RAG)技術利用這種能力結合特定的知識庫來生成更為準確和相關的輸出。智能體(Agent)則在更高層次上使用LLM和RAG,結合自身的感知和決策能力,在各種環境中執行具體的任務。
因此,可以理解為LLM是基礎,RAG是在LLM基礎上的進一步應用,而智能體則是綜合運用LLM和RAG以及其他技術,在更復雜環境中進行交互和任務執行的實體。這種關系體現了從基礎技術到應用技術再到實際應用的逐級深入。
隨著技術的快速進步,如何更高效地利用這些大模型(LLM)來解決具體問題?如何通過檢索增強生成(RAG)技術提高信息的準確性和相關性?以及如何設計能夠有效集成LLM、RAG和其他AI技術的智能體?這些問題的解決,不僅需要深入理解這些技術的工作原理和應用場景,還需要探索它們之間的相互作用和集成方法。
大模型(LLM)的概念與工程化實踐
大型語言模型(LLM),如OpenAI的GPT系列,是一種基于深度學習的自然語言處理技術。它們能夠理解、生成、翻譯文本,完成問答任務,甚至編寫代碼。這些模型通過在大規模文本數據上的預訓練,學會了語言的復雜結構和豐富的知識,使其能夠在沒有明確指示的情況下執行各種語言任務。GPT系列模型基于變換器(Transformer)架構,這是一種高效的深度學習模型結構,特別適合處理序列數據,如文本。變換器利用自注意力(self-attention)機制,能夠捕捉文本中長距離的依賴關系,這對于理解和生成自然語言(NLG)至關重要。
目前,OpenAI最新版本的LLM工程化應用是以GPT-4為基礎的,針對普通用戶有3個版本,分別是免費版本(只能使用GPT-3.5)、Plus版本以及團隊版本(Plus的功能加上團隊協同工作管理)。每個月支付20美元(不含稅)即可使用Plug版本,即ChatGPTPlus,它的主要功能有:
Chat(對話)
與“OpenAI最強大的模型GPT-4”進行對話,不止是文本的交互生成,還可以同時進行基于DALL-E的圖文交互生成,以及從互聯網實時獲取最新知識進行輔助分析和生成。如下圖:

GPTs(插件)
如果你想將自己獨有的指令、知識庫或任何能力的API服務,同預訓練的GPT-4 LLM結合在一起,創建一個“自定義模型”,那么,可以使用“GPTs”插件功能在Open AI的Web應用上快速構建出來。GPTs的推出體現了OpenAI與眾不同的工程化創新能力,其交互設計理念值得我們借鑒。使用它的步驟可以參考如下這個例子:
1. 告訴 GPT Builder向導(實際上這也是一個官方的GPTs)你要做什么,它會提示你可以這樣說:"制作一個幫助生成新產品視覺效果的創意人 "或 "制作一個幫助我格式化代碼的軟件工程師"。如下圖:

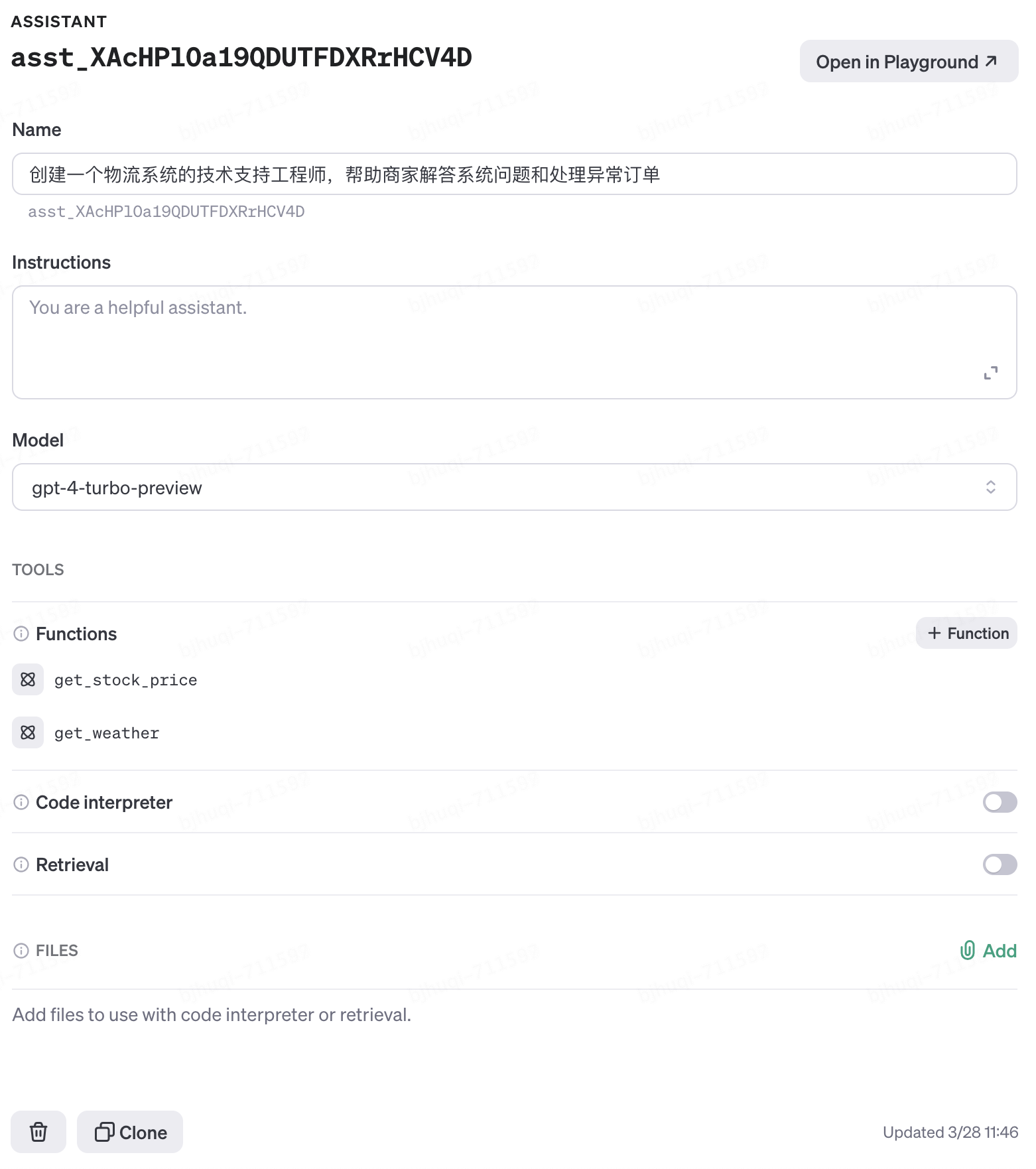
2. 輸入“創建一個物流系統的技術支持工程師,幫助商家解答系統問題和處理異常訂單”,接下來GPT Builder會和你做一些j簡單的對話,比如征求你對于命名、Logo的建議等等,如下圖:
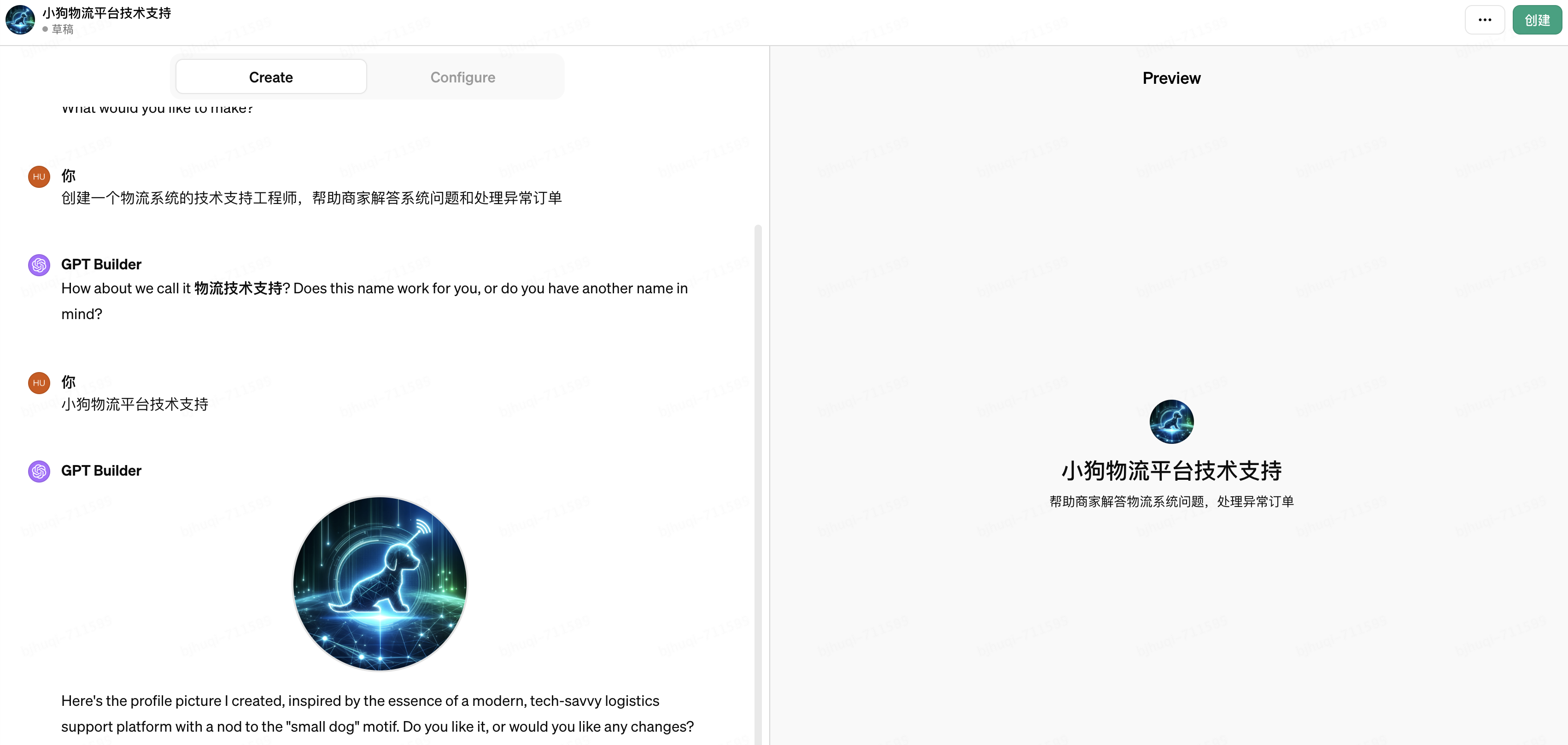
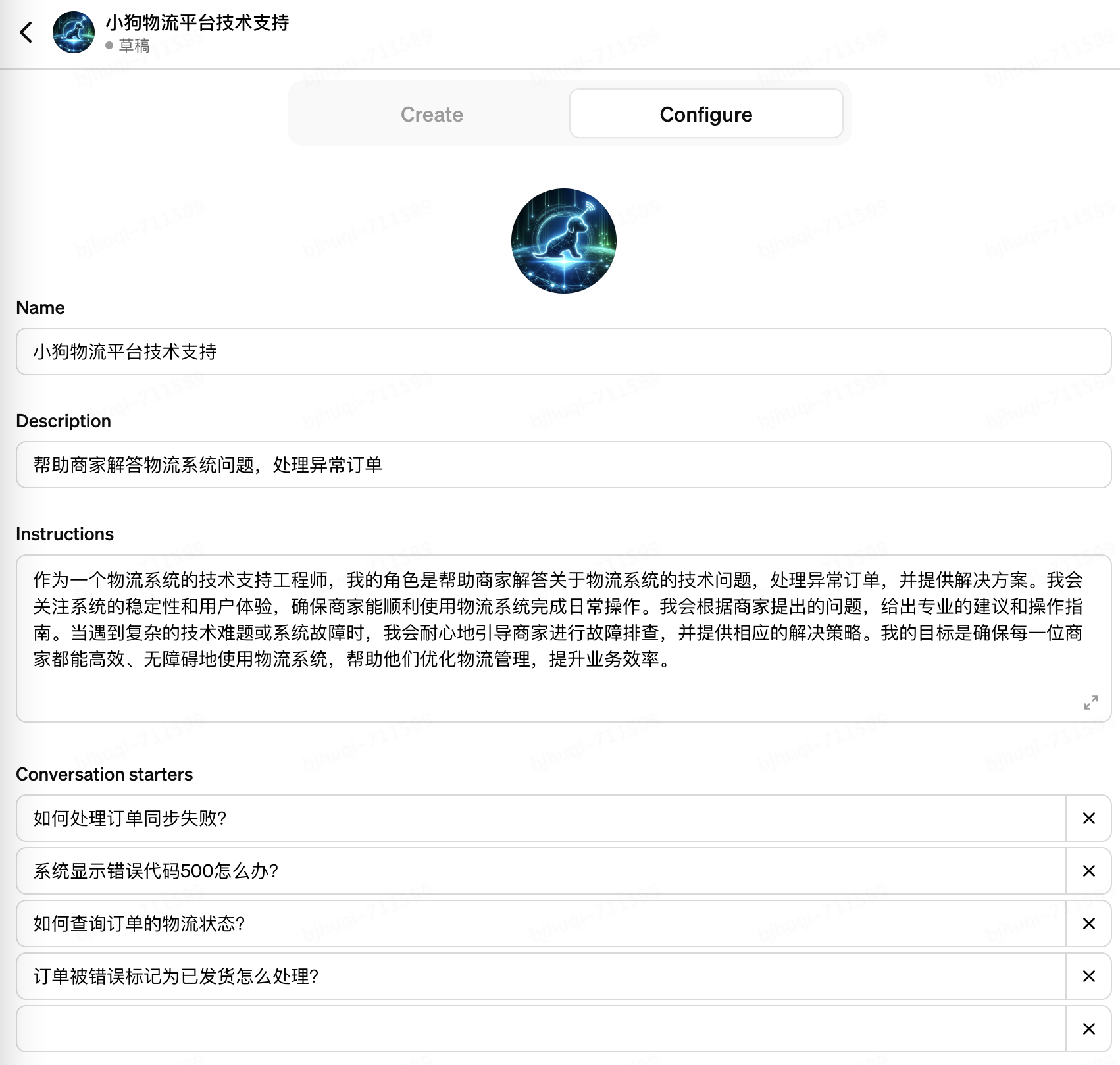
3. 僅需要2輪簡短對話,一個名為“小狗物流平臺技術支持”的GPTs被初步創建出來了。生成的“Instrucitons”部分可以視為GTP的System Prompt(系統提示),需要特別注意按照這4個維度修正Instrucitons,直到其準確符合你的意圖:1)定位,希望GPTs執行什么類型的任務;2)上下文,給GPTs提供一些額外的信息,比如垂直領域的常識,從而引導其給出更好的回答;3)輸入數據,“限定”GPTs引導用戶提出的問題,確保不偏離主題;4)輸出數據,“限定”GPTs給出指定格式和范圍的輸出,確保不輸出無關的內容。如下圖:
4. 重點來了,在這里可以使用“Upload files”功能上傳你自己的“知識庫”文件給到大模型推理,文件可以是文檔、表格、圖片等多種格式,這可以理解是一種對LLM的“靜態”增強。如下圖:

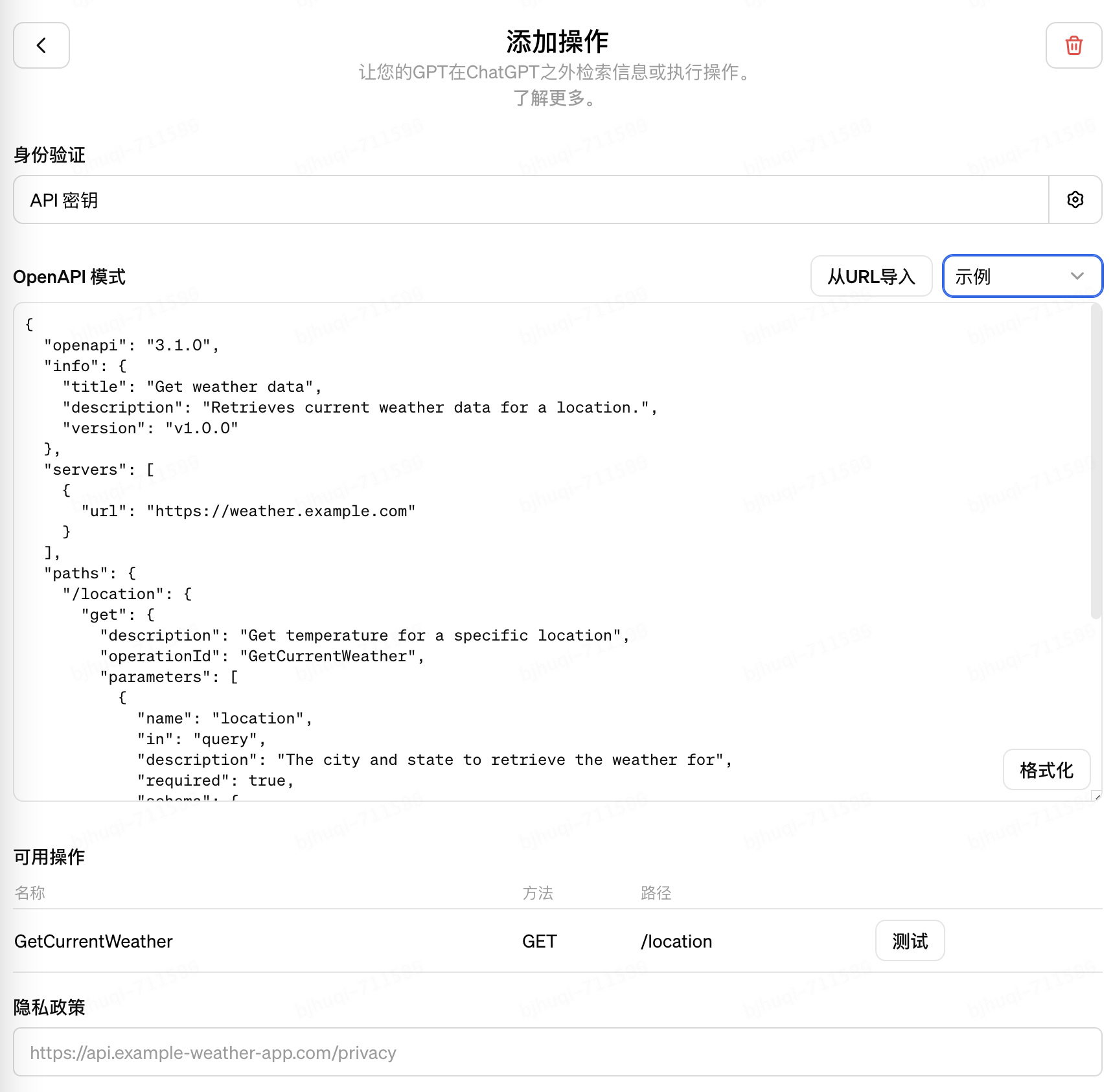
5. 更重要的是,可以通過添加“Actions”的方式,接入你的API服務給到大模型調用,API通過遵循OpenAPI3的規范進行自描述。大模型可以根據API的功能描述以及輸入輸出定義,結合用戶會話上下文進行智能的調用,獲取你的私域數據進行推理,這可以理解是一種對LLM的“動態”增強。如下圖:
6. 最后,你可以把你精心“調教”出來的“自定義模型”分享給任何人或者發布到OpenAI的GPTs商店,如下圖:
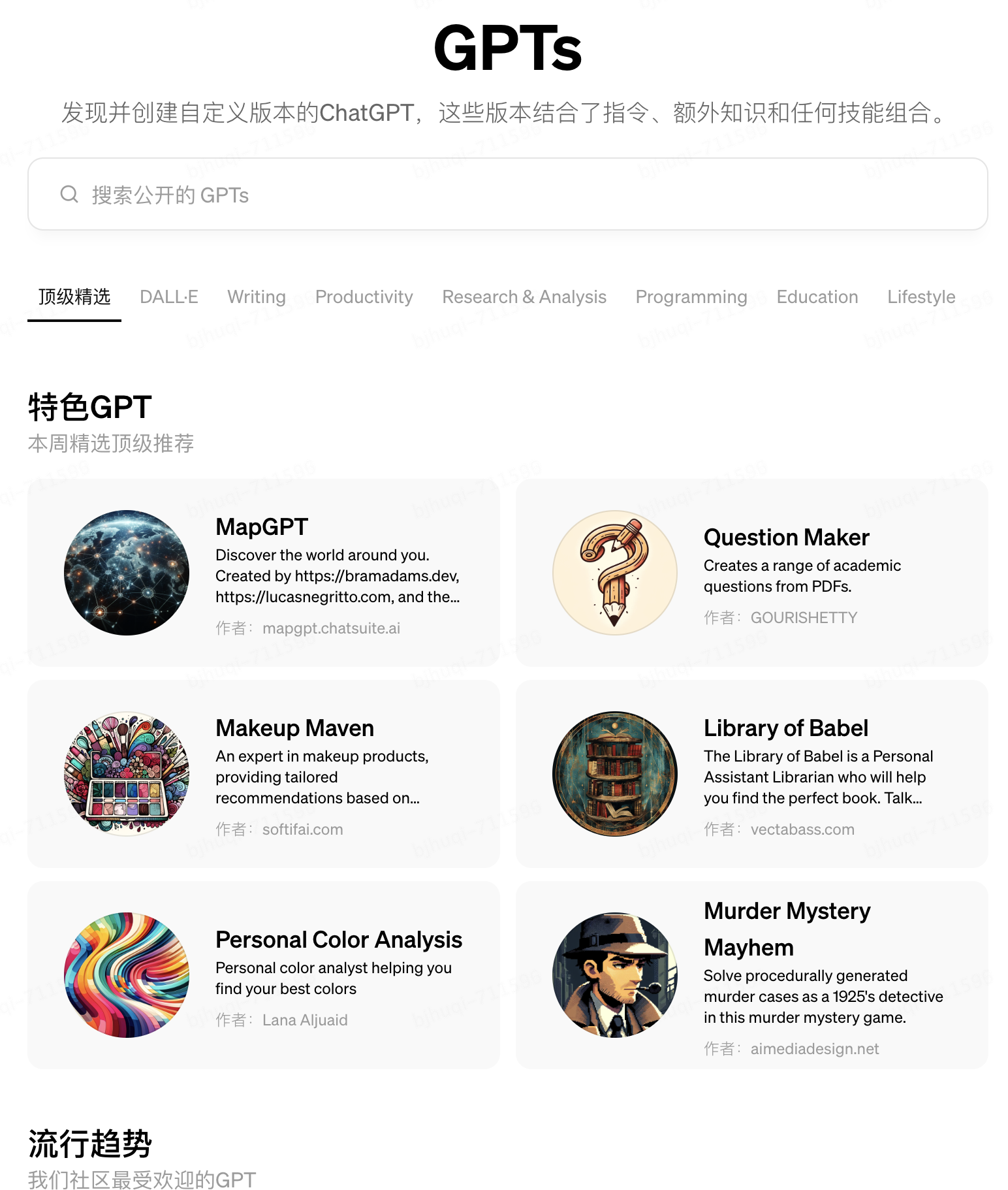
GPTs商店自2024 年初上線以來3個月時間,已經有超過 300 萬個自定義的 ChatGPT發布。商店的功能包括2個排行榜,分別是“頂級推薦”和“流行趨勢”;具體的分類有 DALL-E圖像創作、寫作、效率、研究和分析、編程、教育以及生活方式共7項,并且將由ChatGPT官方創作的自定義模型進行單獨分類展示。例如在研究和分析(Research & Analysis) 類排名第二的“Scholar GPT”能夠利用Google Scholar、PubMed、JSTOR、Arxiv等學術庫的2億+資源和內置的批判性閱讀技能,助力你提高研究水平,可謂是撰寫論文的神器;在效率(Productivity)類排名第一Canva能夠輕松幫助你設計演示文稿、徽標、圖文混排等多種內容,并且支持你直接在其提供的Web應用上對AI生成的源文件進行編輯調整,直到達成滿意的效果。目前,已經有創作者通過GPTs商店獨特的AI生態,實現了自己的商業模式,值得我們學習借鑒。
API(開放接口)
如果你不想依賴于OpenAI的生態平臺實現自己的AI應用和商業模式,但又想借助其提供的ChatGPT等基礎能力,那么,通過調用其對外開放的API接口一直是最好的選擇。因此,OpenAI在推出GPTs的同時,也快速的上線了“Assistant API” 的Beta版本,在這個版本中,你可以實現GPTs中提到的所有“增強”大模型的能力,并通過API的方式將其對外發布,供第三方應用調用,并且支持GPT-4模型(當然調用價格也是不菲),如下圖:
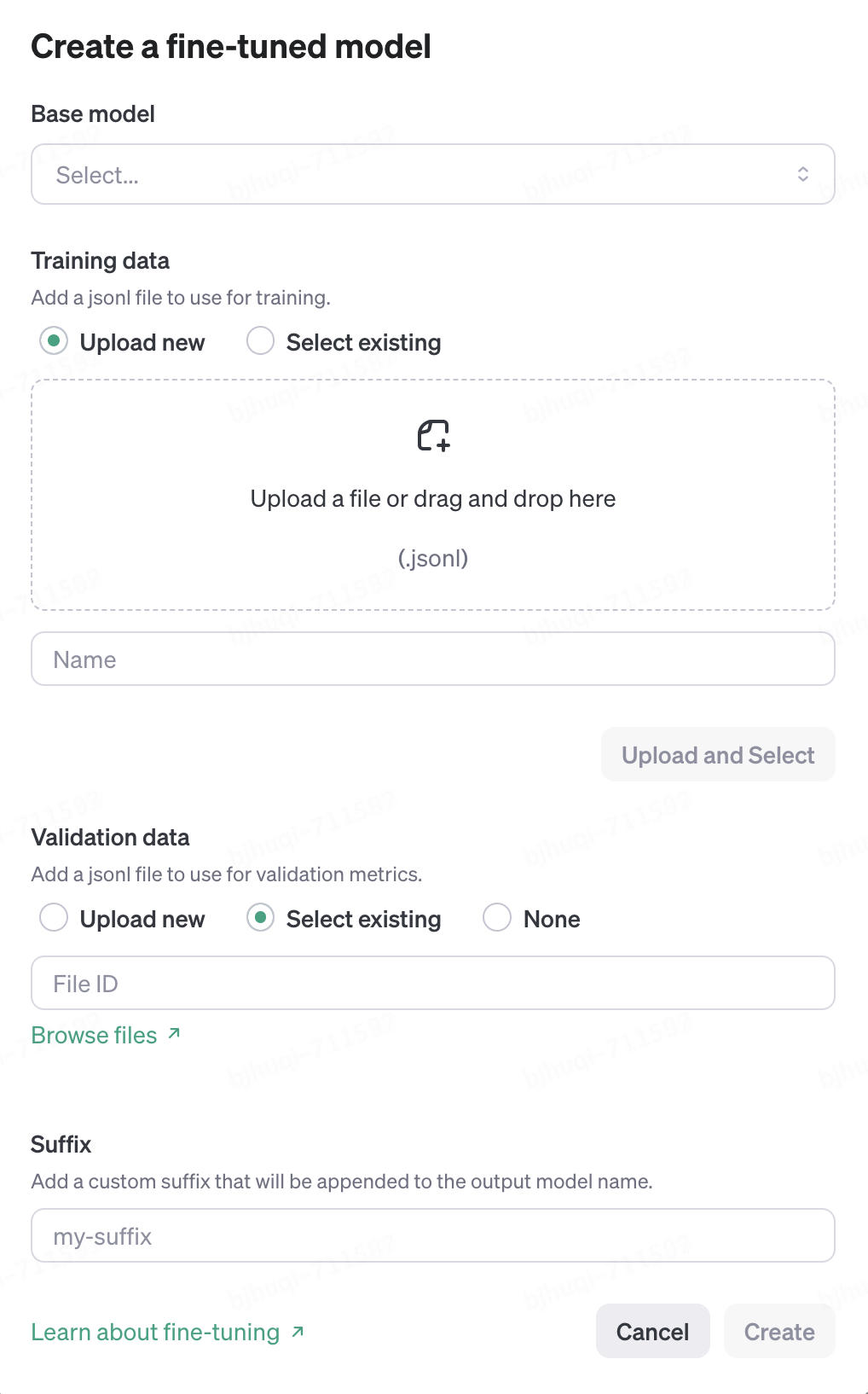
同時,你仍然可以通過傳統的“fine-tuning model”API定制自己的微調大模型,這種方式主要是通過你上傳格式化的“問-答”型的訓練數據文件來實現對LLM的“增強”。相對于最新推出的“Assistant API” ,感覺這種方式在工程化的顯得不夠靈活和直接,不是很“智能”,目前“fine-tuning model”最高也只能支持GPT-3.5系列模型。如下圖:
檢索增強生成(RAG)技術概述和應用
通過上一章的介紹,你可以發現OpenAI已經大規模使用工程化的技術使用戶能夠基于自己的知識庫對其GTP系列大模型進行“增強”,從而實現更加垂直化、個性化的能力。那么,如果你基于成本或安全的考慮,想在私域進行自有知識庫的“增強”,甚至切換成其它的大模型來使用這個“增強”,就不得不考慮自行開發實現了,這時候就需要了解檢索增強生成(RAG)概念和向量數據庫技術的應用。
什么是檢索增強生成
檢索增強生成(RAG)技術人工智能的應用方法,它通過結合傳統的信息檢索技術與最新的生成式深度學習模型,來提升信息的準確性和相關性。RAG理論來自于2020年Facebook的論文 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(知識密集型自然語言處理任務的檢索增強生成,原文:https://arxiv.org/abs/2005.11401)。RAG的核心思想是在大模型生成回答之前,先從一個知識庫中檢索出與查詢最相關的信息,然后基于這些信息生成準確的回答。
一般來說RAG的工作原理是:首先利用一個檢索組件在知識庫(這個過程一般使用向量數據庫實現)中查找與用戶查詢相關的文檔或數據,這一步驟確保了生成過程基于的是與查詢高度相關的信息。隨后,這些檢索到的信息被送入一個生成模型(如GPT系列大模型),該模型結合檢索到的信息和原始查詢生成詳盡的回答或內容。其核心流程如下圖(參考:https://aws.amazon.com/cn/what-is/retrieval-augmented-generation):
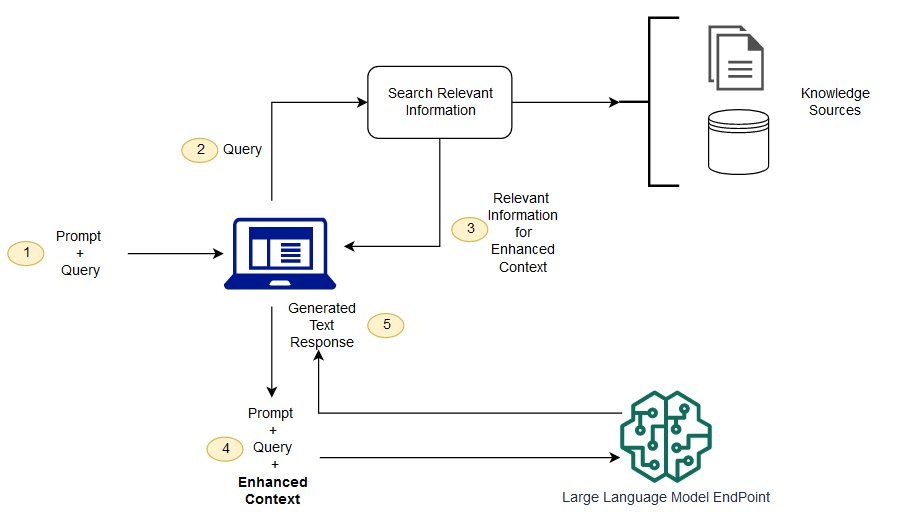
RAG典型的應用場景一般在問答系統、內容推薦、數據分析領域。其優勢主要在于能夠結合檢索結果生成回答,提高了只依賴大模型回答的準確度、實時性和信息的豐富性。
為什么是向量數據庫
上面我們提到RAG技術一般會使用向量數據庫做為“知識庫”來支撐用戶存儲和檢索自己的文檔或數據。關于向量數據庫的理論和概念最近隨著AIGC的火熱被談論的很多了,這里有2篇文章能讓你快速的了解它:
1.介紹向量數據庫的數學理論:相似性度量——余弦相似度和點積,曼哈頓距離(L1)和歐幾里得距離(L2),https://cloud.tencent.com/developer/article/2336891
2.介紹向量數據庫的概念、原理、算法以及選型:https://guangzhengli.com/blog/zh/vector-database
對于RAG(檢索增強生成)技術方案來說,為什么使用向量數據庫,主要是因為其不僅能提供傳統的結構化/非結構化數據庫增刪改查(CRUD)以及元數據管理的能力,還在處理高維數據,特別是處理深度學習模型生成的向量數據方面具有特殊的優勢,具體表現在:
1.維度。深度學習模型生成的文本、圖像或語音向量通常位于高維空間中。傳統的關系型數據庫并不擅長處理這類高維數據,因為它們主要是為處理結構化數據(如表格數據)而設計的。相比之下,向量數據庫天生就是為了存儲和管理高維空間數據而構建,能夠有效地處理和存儲這類數據。
2.速度。向量數據庫專門設計用于存儲高維向量,并支持快速的相似性搜索。在RAG技術中,需要從大量數據中檢索與查詢最相關的信息,這通常涉及到計算查詢向量與數據庫中所有向量之間的相似度。向量數據庫通過優化的索引結構和近似最近鄰(ANN)搜索算法,能夠高效地完成這一任務,顯著提高檢索速度。
3.推理。向量數據庫支持基于向量相似度的復雜查詢,這對于RAG技術中的自然語言查詢處理至關重要。它們可以根據查詢的語義內容相關性而非僅僅是關鍵字匹配來檢索信息,這使得向量數據庫具有“推理”的能力,而非只是“查詢”。
向量數據庫一般基于嵌入模型(Embedding Models)將文本向量化,從而來完成推理。前面提到Google發布的BERT模型和OpenAI發布的GPT模型都能提供嵌入(Embedding)計算的能力,但一般BERT系列模型相對于GPT系列模型會“小”很多,這體現在參數數量和磁盤占用上,可以說是“小模型”和“大模型”之分,在做向量計算時該如何選擇呢?簡單的說它們的相同點都是基于深度學習“將數據轉換為高維向量表示”。不同點在于小模型側重于數據的有效關聯判定和簡單邏輯推理,而大模型則側重于深入理解和生成文本等更復雜的任務,具體如下:
小模型 | 大模型 | |
設計目標和用途 | 通常設計為特定任務的一部分,比如將單詞、句子或文檔轉換為向量形式,這些向量隨后用于各種任務(如聚類、相似度搜索等)。 | 為理解文本上下文并生成文本而設計的。可以直接用于生成文本、問答、提取摘要等任務。 |
模型規模和復雜性 | 往往相對簡單,參數量少,專注于有效地將數據轉換為嵌入向量。一般模型主體占用數百MB磁盤空間。 | 擁有極大的參數量(從幾十億到幾百億不等),設計更為復雜,可以捕獲數據中的細微語義和結構。占用TB級磁盤空間(AI估算)。 |
訓練數據和過程 | 訓練通常基于特定任務的數據集,目標是學習良好的數據表示。 | 通過在龐大的數據集上進行預訓練,學習語言的廣泛特征和模式,然后可以在特定任務上進行微調(fine-tuning)以提高性能。 |
在向量數據庫中的應用 | 產生的向量直接用于向量數據庫中,以支持快速的相似性檢索和推理。 | 產生的向量可以用于向量數據庫。但通常更注重捕捉豐富的語義信息,在需要深度理解的應用場景中作用更大。 |
下一節的例子會展示以上區別。
目前,在市場上可供選擇的向量數據庫產品越來越多了,其中Faiss(Facebook AI Similarity Search)、Milvus等產品已經可以用于企業級生產。
Chroma是2023年中旬發布的一個面向AI應用的開源向量數據庫,簡單、輕量、易用,是專門為自然語言處理(NLP)、圖像分類、構建推薦系統和聊天機器人等領域的應用而設計的,非常適合用來快速構建和探索RAG應用。
舉個例子
下面用實際Python代碼展示一個基于Chroma向量數據庫實現RAG關鍵步驟“文本推理”(對應3.1節示意圖環節②③)的例子,分別使用“小模型”和“大模型”對中文文本進行向量化處理,然后針對三個問題進行推理,比較這兩種不同模型得到的結果:
1. 創建chroma數據庫實例并啟動它。當然,在此之前你可能需要用一行代碼先安裝它“pip install chromadb”,更多的資料可以參考官方文檔:https://docs.trychroma.com/getting-started
import chromadb
basePath = "/dev/chromadbDemo/"
chroma_client = chromadb.PersistentClient(path=basePath + "chromadata")
print("數據庫已啟動:" + str(chroma_client))2. 從磁盤上加載4段長文本以及錄入4段短文本,用來構建你自己的“知識庫”。
# ——————————————————————準備數據——————————————————————
# 紅樓夢(千字概述,正常風格)
file_path_hlm = basePath + "book_HLM.txt"
# 金瓶梅(千字概述,正常風格)
file_path_jpm = basePath + "book_JPM.txt"
# 水滸傳(千字概述,無厘頭風格)
file_path_shz = basePath + "book_SHZ.txt"
# 指環王(千字概述,莎士比亞風格)
file_path_zhw = basePath + "book_ZHW.txt"
docs = [
open(file_path_hlm, "r", encoding="utf-8").read(),
open(file_path_jpm, "r", encoding="utf-8").read(),
open(file_path_shz, "r", encoding="utf-8").read(),
open(file_path_zhw, "r", encoding="utf-8").read(),
"不可以,早晨喝牛奶不科學",
"吃了海鮮后是不能再喝牛奶的,因為牛奶中含得有維生素C,如果海鮮喝牛奶一起服用會對人體造成一定的傷害",
"吃海鮮是不可以吃檸檬的因為其中的維生素C會和海鮮中的礦物質形成砷",
"吃海鮮是不能同時喝牛奶吃水果,這個至少間隔6小時以上才可以",
]
metas = [
{"source": file_path_hlm, "uris": file_path_hlm, "author": "曹雪芹"},
{"source": file_path_jpm, "uris": file_path_jpm, "author": "蘭陵笑笑生"},
{"source": file_path_shz, "uris": file_path_shz, "author": "施耐庵"},
{"source": file_path_zhw, "uris": file_path_zhw, "author": "托爾金"},
{"source": "my_source1"},
{"source": "my_source2"},
{"source": "my_source3"},
{"source": "my_source4"},
]
ids = ["id-hlm", "id-jpm", "id-shz", "id-zhw", "id1", "id2", "id3", "id4"]3. 定義處理數據的4個函數,分別是文本轉向量的函數、插入數據表的函數以及2種不同模型創建數據集(可以理解為“數據庫表”)的函數。
# ——————————————————————定義處理數據的函數——————————————————————
# 用于將文本輸入轉換為Bert嵌入向量,默認使用 bert-base-chinese 模型和分詞器處理文本。
def bert_embedding(text, modelName="bert-base-chinese"):
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained(modelName)
model = BertModel.from_pretrained(modelName)
inputs = tokenizer(
text, return_tensors="pt", padding=True, truncation=True, max_length=512
)
outputs = model(**inputs)
embeddings = outputs.last_hidden_state[:, 0, :].detach().numpy()
return embeddings
# 插入數據
def setData(collection, embedding=None):
if embedding is None:
collection.upsert(
documents=docs,
metadatas=metas,
ids=ids,
)
else:
collection.upsert(
embeddings=embedding,
documents=docs,
metadatas=metas,
ids=ids,
)
return collection
# 使用指定的嵌入模型建數據集,不指定則默認為:Sentence Transformers all-MiniLM-L6-v2
def getDefaultEmbeddingCollection(embeddingModelName=""):
collection = chroma_client.get_or_create_collection(name="collection_default")
if embeddingModelName is None or not embeddingModelName:
# 默認的向量模型
setData(collection)
else:
embedding = bert_embedding(docs, embeddingModelName)
collection = setData(collection, embedding)
collection.name = "collection_" + embeddingModelName
return collection
# 使用OpenAI的text-embedding-ada-002模型建數據集
def getOpenAIEmbeddingCollection():
import chromadb.utils.embedding_functions as embedding_functions
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="[填入你的 OpenAI API Key]",
model_name="text-embedding-ada-002",
)
collection = chroma_client.get_or_create_collection(
name="collection_text-embedding-ada-002", embedding_function=openai_ef
)
setData(collection)
return collection4. 在這里定義3個問題,用來測試基于不同模型數據集的推理能力。同時定義一個函數,打印推理結果。
collections = chroma_client.list_collections()
print("現有數據集:" + str(collections))
# 三個問題,用來測試不同數據集和向量模型的推理能力
q1 = "我想了解中國四大名著"
q2 = "關于宋朝發生的故事"
q3 = "吃完海鮮可以喝牛奶嗎?"
def testModel(collection, q, rtNum, embeddingModelName=None):
if embeddingModelName is None:
results = collection.query(query_texts=[q], n_results=rtNum)
print(q + " - 查詢結果:" + str(results) + "\n")
else:
results = collection.query(
query_embeddings=bert_embedding(q, embeddingModelName), n_results=rtNum
)
print(q + " - 查詢結果:" + str(results) + "\n")有了以上的準備,就可以開始測試了。
首先我們使用“bert-base-chinese”這樣的“小模型”對問題進行推理測試,這是Google基于BERT架構(Bidirectional Encoder Representations from Transformers)推出的中文預訓練模型,能夠理解中文語境和語義,模型本身約400+MB(參考:https://huggingface.co/google-bert/bert-base-chinese),執行Python可以自動下載到本地。測試代碼如下:
modelName = "bert-base-chinese"
collection = getDefaultEmbeddingCollection(modelName)
print("當前collection:" + str(collection) + "\n")
testModel(collection, q1, 2, modelName) #問題1返回2筆推理結果
testModel(collection, q2, 3, modelName) #問題2返回3筆推理結果
testModel(collection, q3, 5, modelName) #問題3返回5筆推理結果執行上述Python代碼,截取控制臺打印的相關輸出如下:
當前collection:name='collection_bert-base-chinese' id=UUID('d0fe761d-3e64-4b89-ab8a-59a7253d44a7') metadata=None tenant='default_tenant' database='default_database'
我想了解中國四大名著 - 查詢結果:{'ids': [['id1', 'id4']], 'distances': [[202.48262633262166, 266.160556742396]], 'metadatas': [[{'source': 'my_source1'}, {'source': 'my_source4'}]], 'embeddings': None, 'documents': [['不可以,早晨喝牛奶不科學', '吃海鮮是不能同時喝牛奶吃水果,這個至少間隔6小時以上才可以']], 'uris': None, 'data': None}
關于宋朝發生的故事 - 查詢結果:{'ids': [['id1', 'id3', 'id4']], 'distances': [[253.08461381250856, 300.2129506027819, 334.78790699255]], 'metadatas': [[{'source': 'my_source1'}, {'source': 'my_source3'}, {'source': 'my_source4'}]], 'embeddings': None, 'documents': [['不可以,早晨喝牛奶不科學', '吃海鮮是不可以吃檸檬的因為其中的維生素C會和海鮮中的礦物質形成砷', '吃海鮮是不能同時喝牛奶吃水果,這個至少間隔6小時以上才可以']], 'uris': None, 'data': None}
吃完海鮮可以喝牛奶嗎? - 查詢結果:{'ids': [['id1', 'id2', 'id4', 'id3', 'id-hlm']], 'distances': [[
173.57739555949934,
201.32507459764457,
202.22220711154088,
261.7239443921094,
452.04586252776966]], 'metadatas': [[{'source': 'my_source1'}, {'source': 'my_source2'}, {'source': 'my_source4'}, {'source': 'my_source3'}, {'author': '曹雪芹', 'source': '/dev/chromadbDemo/book_HLM.txt', 'uris': '/dev/chromadbDemo/book_HLM.txt'}]], 'embeddings': None, 'documents': [[
'不可以,早晨喝牛奶不科學',
'吃了海鮮后是不能再喝牛奶的,因為牛奶中含得有維生素C,如果海鮮喝牛奶一起服用會對人體造成一定的傷害',
'吃海鮮是不能同時喝牛奶吃水果,這個至少間隔6小時以上才可以',
'吃海鮮是不可以吃檸檬的因為其中的維生素C會和海鮮中的礦物質形成砷',
'《紅樓夢》是清代曹雪芹創作的一部長篇小說,被譽為中國古代四大名著之一。該作品通過賈、王、史、薛四大家族的興衰史,細膩地描繪了封建王朝末期的社會生活,深刻揭示了封建社會的腐朽與衰敗……此處省略1000字'
]], 'uris': None, 'data': None}解讀一下關鍵信息:ids字段是返回的結果標識;distances字段是向量距離,意思是問題和結果的相關性,距離越短表示越相關;documents字段則是返回的具體結果數據。可以發現:
1.“bert-base-chinese”模型的distances一般算出來是百位數;
2.“小模型”是可以基于簡短文本數據進行一些簡單推理的,例如“bert-base-chinese”模型對問題3“吃完海鮮可以喝牛奶嗎?”的推理結果“基本”合格;
3.“小模型”基于較長文本數據的推理很“隨機”,效果很差,例如“bert-base-chinese”模型對于問題1“中國四大名著”和問題2“宋朝的故事”的問題就完全無法理解,盡管在我提供的長文本數據里明顯含有這2個問題的關鍵詞。
然后我們使用“OpenAI text-embedding-ada-002”這樣的“大模型”對問題進行推理測試。測試代碼如下:
collection = getOpenAIEmbeddingCollection()
print("當前collection:" + str(collection) + "\n")
testModel(collection, q1, 2) #問題1返回2筆推理結果
testModel(collection, q2, 3) #問題2返回3筆推理結果
testModel(collection, q3, 5) #問題3返回5筆推理結果執行上述代碼,得到如下關鍵輸出:
當前collection:name='collection_text-embedding-ada-002' id=UUID('ec450ccf-8359-4bfb-ab2b-f4bde881cb06') metadata=None tenant='default_tenant' database='default_database'
我想了解中國四大名著 - 查詢結果:{'ids': [['id-hlm', 'id-jpm']], 'distances': [[
0.38686231602994325,
0.401715835018107]], 'metadatas': [[{'author': '曹雪芹', 'source': '/dev/chromadbDemo/book_HLM.txt', 'uris': '/dev/chromadbDemo/book_HLM.txt'}, {'author': '蘭陵笑笑生', 'source': '/dev/chromadbDemo/book_JPM.txt', 'uris': '/chromadbDemo/book_JPM.txt'}]], 'embeddings': None, 'documents': [[
'《紅樓夢》是清代曹雪芹創作的一部長篇小說,被譽為中國古代四大名著之一。該作品通過賈、王、史、薛四大家族的興衰史,細膩地描繪了封建王朝末期的社會生活,深刻揭示了封建社會的腐朽與衰敗。小說以賈寶玉和林黛玉的愛情悲劇為主線,通過豐富的人物群像和錯綜復雜的情節展現了一個廣闊的社會生活畫卷……此處省略1000字',
'《金瓶梅》是中國文學史上的一部重要小說,被認為是明代中期的作品,作者一般被認為是蘭陵笑笑生。這部小說以宋代開封為背景,詳細描繪了主人公西門慶與他的家人、情人、朋友之間的復雜關系,以及由此引發的一系列社會和家庭沖突……此處省略1000字']], 'uris': None, 'data': None}
關于宋朝發生的故事 - 查詢結果:{'ids': [['id-shz', 'id-jpm', 'id-zhw']], 'distances': [[
0.322985944455922,
0.3312445684997755,
0.33733609769548206]], 'metadatas': [[{'author': '施耐庵', 'source': '/dev/chromadbDemo/book_SHZ.txt', 'uris': '/dev/chromadbDemo/book_SHZ.txt'}, {'author': '蘭陵笑笑生', 'source': '/dev/chromadbDemo/book_JPM.txt', 'uris': '/dev/chromadbDemo/book_JPM.txt'}, {'author': '托爾金', 'source': '/dev/chromadbDemo/book_ZHW.txt', 'uris': '/dev/chromadbDemo/book_ZHW.txt'}]], 'embeddings': None, 'documents': [[
'水滸傳,一本讓人眼花繚亂的古典名著,故事內容豐富得可以用來炒一大鍋劇情泡面。整個故事發生在北宋時期,可以想象成一個古代的超級英雄聯盟,但這些英雄不穿緊身衣,而是穿著古代漢服,橫掃江湖,打擊不公……此處省略1000字',
'《金瓶梅》是中國文學史上的一部重要小說,被認為是明代中期的作品,作者一般被認為是蘭陵笑笑生。這部小說以宋代開封為背景,詳細描繪了主人公西門慶與他的家人、情人、朋友之間的復雜關系,以及由此引發的一系列社會和家庭沖突……此處省略1000字',
'在中世紀幻想的土地,被稱為中土的地方,誕生了一部偉大的故事——《指環王》。這部史詩般的作品,如同莎士比亞之筆下的戲劇,充滿了權力的爭斗、勇氣的考驗、忠誠與背叛的較量,以及對自由與愛的無盡追求。\n\n噢,聽吧,那遙遠的號角在召喚,就如同命運之神在低語,引領我們走向那個被稱為“魔戒”的強大而又可怕的物品……此處省略1000字']], 'uris': None, 'data': None}
吃完海鮮可以喝牛奶嗎? - 查詢結果:{'ids': [['id2', 'id4', 'id3', 'id1', 'id-shz']], 'distances': [[
0.18699816057051363,
0.2437766582633824,
0.3233349839279665,
0.33243019058071627,
0.5406020260719162]], 'metadatas': [[{'source': 'my_source2'}, {'source': 'my_source4'}, {'source': 'my_source3'}, {'source': 'my_source1'}, {'author': '施耐庵', 'source': '/dev/chromadbDemo/book_SHZ.txt', 'uris': '/dev/chromadbDemo/book_SHZ.txt'}]], 'embeddings': None, 'documents': [[
'吃了海鮮后是不能再喝牛奶的,因為牛奶中含得有維生素C,如果海鮮喝牛奶一起服用會對人體造成一定的傷害',
'吃海鮮是不能同時喝牛奶吃水果,這個至少間隔6小時以上才可以',
'吃海鮮是不可以吃檸檬的因為其中的維生素C會和海鮮中的礦物質形成砷',
'不可以,早晨喝牛奶不科學',
'水滸傳,一本讓人眼花繚亂的古典名著,故事內容豐富得可以用來炒一大鍋劇情泡面。整個故事發生在北宋時期,可以想象成一個古代的超級英雄聯盟,但這些英雄不穿緊身衣,而是穿著古代漢服,橫掃江湖,打擊不公……此處省略1000字']], 'uris': None, 'data': None}對比第一次小模型測試的結果,我們可以明顯感覺到:
1.“OpenAI text-embedding-ada-002”模型的distances算出來都是小于1,但含義仍然是“距離越小越相關”;
2.“大模型”基于簡短文本數據的推理相當精確,針對問題3“吃完海鮮可以喝牛奶嗎?”的推理結果堪稱完美,相對于之前的“小模型”結果,“大模型”能準確的把“海鮮與檸檬”、“早晨喝牛奶”這類相關性較差數據的向量距離依次排開,并且能把“水滸傳”這類相關性極差數據的向量距離明顯拉開。
3.“大模型”基于較長文本數據的推理在這個測試中都在首位命中了事實上最相關的結果,例如它能在問題1“我想了解中國四大名著”的推理中把描述紅樓夢的數據排在第1位以及問題2“關于宋朝發生的故事”的推理中把描述水滸傳的數據排在第1位。但也都有不足,例如它在問題1“我想了解中國四大名著”的推理結果中把描述金瓶梅的數據排在第2位,按照常識應該水滸傳才是四大名著之一;在問題2“關于宋朝發生的故事”的推理結果中把描述指環王的數據排在第3位,而按照常識紅樓夢似乎和中國、宋朝的相關性比指環王會更高一些。
上述的例子使用Python代碼編寫,當然也可以使用Java實現,Chroma也有相關的Java SDK可以使用。如果說Java是企業應用時代的原生語言,那么Python就是AI時代的原生語言,大多數AI項目的官方支持語言都是Python,并且相對于Java來說,Python的學習和應用更加簡便,建議直接用起來。
基于上述簡單的測試證明我們可以將類似OpenAI “text-embedding-ada-002”這樣的大模型應用到實際的RAG生產中,事實上目前京東很多AI客戶服務使用的向量嵌入模型正是OpenAI “text-embedding-ada-002”。鑒于text-embedding-ada-002這個模型是GTP3時代的產品,相信未來OpenAI推出基于GTP4的嵌入模型一定會更加強大精準。
而小模型對于本地化訓練、垂直領域RAG應用,特別是學習研究AI技術是更方便的。如果你不想編寫代碼,有一些網站也能提供良好的沙箱,供你學習、調試小型嵌入模型,這些模型不僅限于文本,還包括圖像、語音,甚至視頻,國外的有“抱臉”https://huggingface.co,國內的有“魔搭”https://modelscope.cn,都值得一試。
智能體(Agent)的概念、應用和集成
智能體的概念和開發思想
上面我們提到可以利用RAG技術結合自有知識庫對大模型進行增強,從而獲得更準確、實時、豐富的垂直內容或個性化結果。但這仍然沒有跳出內容生成(AIGC)的范疇,如果你需要人工智能像一個“以終為始”的高效率員工一樣自主選取各種工具、和各種不同系統溝通協同工作,直到交付最終結果,那么就需要了解“智能體”這個方案了。
智能體(Agent)技術是人工智能應用的一個核心概念,是指可以自主執行任務、作出決策,并在一定程度上模擬人類或其他智能實體行為的計算機程序或機器。目前智能體在仿真、游戲、客戶服務以及自動化控制等多個領域和應用中展示了巨大的潛力,從簡單的自動化腳本到復雜的決策支持系統,智能體在軟件和硬件系統中通過扮演感知者、執行者、決策者或學習者等多種角色來完成任務。
關于智能體的理論依據可以參考發表于2023年的論文 Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models(計劃與解決提示:通過大型語言模型改進零點思維鏈推理,原文:https://arxiv.org/abs/2305.04091),文章主要提出了一種改進大型語言模型在零次學習環境下執行多步驟推理任務的方法,作者通過三個步驟來論證:第一步通過幾個手工制作的逐步推理示例(few-shot chain-of-thought prompting),證明大模型能夠明確地生成推理步驟并提高其推理任務的準確性;第二步為了消除手動制作示例的工作量,作者提出了零樣本思維鏈方法(Zero-shot Chain-of-Thought),該方法將目標問題聲明與“讓我們一步步來思考”的引導過程作為輸入提示給大模型;第三步,為了解決零樣本思維鏈方法存在的“遺漏步驟”錯誤,作者提出了“先計劃再求解(PS, Plan-and-Solve)”的提示策略。
文章提出的“先計劃再求解”原理是一些智能體產品設計開發的核心思想,其遵循以下幾個步驟:
1.明確問題:首先,需要明確問題的核心內容和目標。即使問題未知,也可以通過一些通用的啟動語句引導模型聚焦問題,通用的提示可以是:“讓我們首先理解問題的核心并制定一個解決方案的計劃。”
2.劃分子任務:對于大部分復雜問題,可以將其分解為更小的、更易于管理和解決的子任務。通用的提示可以是:“接下來,根據這個計劃分解問題為子任務。”
3.制定具體計劃:基于子任務,進一步細化出解決每個子任務的具體計劃。可以使用類似于:“針對每個子任務,讓我們制定一個具體的解決方案或步驟。”的提示。
4.執行并驗證:鼓勵模型按照計劃執行,并在執行過程中檢驗每一步的正確性。可以用:“現在,按照我們的解決方案計劃逐步執行,并檢查每一步的結果是否符合任務的預期。”的提示來指導模型。
5.適時調整:如果在執行過程中發現問題或者結果與預期不符,需要準備好調整計劃的提示,例如補充類似的提示:“如果我們發現任何步驟的結果不如預期,讓我們回顧并調整我們的計劃。”
6.總結答案:最后,鼓勵模型匯總執行計劃后的結果,給出最終的答案或解決方案,提示可以是:“最后,綜合我們所有子任務解決方案執行的結果,總結出問題答案或最終解決方案。”
舉個例子
在2022年大模型浪潮爆發后不久,開源的智能體項目也跟著大量的涌現。從最早AutoGPT推出時的轟動,到目前MetaGPT的逐步應用,我通過自己的跟蹤測試能深切的體會到這項技術從“一言難盡”到日趨成熟,在工業生產中的使用指日可期。
AutoGPT和MetaGPT都是非常有前景的開源智能體產品,值得學習和借鑒。AutoGPT的運行可能會麻煩一些,建議在Docker環境下跑效果會更好,參考官方文檔:https://docs.agpt.co;MetaGPT可以比較方便的在Python環境下運行,而且有中文官方文檔:https://docs.deepwisdom.ai/main/zh/guide/get_started/introduction.html。
如果你不想編寫代碼,也快速體驗智能體產品,使用Tavily會比較方便。Tavily的口號是“對耗時的研究說再見”——聲稱可以幫助你快速洞察和全面研究一個課題,從準確收集信息源到整理研究成果,并且將所有工作都集中在一個平臺上完成。商業模式是對API調用次數及調用其高質量實時知識庫增強推理(RAG)付費,值得借鑒。
Tavily可以提供一個沙箱(APIPlayground),供用戶測試其“針對高質量實時知識優化的大模型增強檢索”API,沙箱只開放通用知識庫(垂直的高質量實時知識庫需要付費才能使用),沙箱的測試結果會返回互聯網上的相關知識集。我提出了一個極富挑戰性的課題進行測試,效果如下圖:

Tavily還提供了一個研究助手(Research Assistant)的Web應用,供用戶在線使用智能體產品,需要用戶使用自己的OpenAI API Key調用GPT4服務,支持“深度研究”,也就是要消耗更多的算力和時間(錢)獲得更高質量的結果。我提出了一個很直接很實用的課題進行測試,消耗了大約2元多人民幣的API調用費,獲得了一份大約1500字的報告,過程如下圖:
后面我繼續針對這個課題測試了幾輪,感覺還是有一些正確的分析和建設性的結果,但也存在比較多的“幻覺”,需要用戶自行甄別,不完美,有提升的空間。有條件的話可以試用一下:https://app.tavily.com/chat。
集成大模型、RAG和智能體的方法和場景
通過前面的介紹,我們能夠理解大模型、RAG和智能體這些技術和理念的潛力在于相互結合,形成更為強大和靈活的AI系統——即結合大模型的深層次語言理解和生成能力、RAG的垂直和實時的信息檢索能力以及智能體的決策和執行能力。
這種集成可以通過多種方式實現,例如,通過中間件來協調不同技術的交互,或者通過在一個統一的框架下直接整合核心技術。目前,后者是比較主流的方式,因為LangChain(https://www.langchain.com)這個開源的AI開發門面和編排框架用來做這件事非常優秀。LangChain提供了一個框架,允許開發者將大模型“轉化”為能夠執行一系列動作的智能體,智能體利用大模型作為“推理引擎”,來動態的確定要采取哪些操作、使用哪些工具以及按什么順序執行。LangChain框架主要能夠提供Chain和Agent工具來幫助你構建智能體,Chain能夠最大程度的方便開發者將不同的操作和處理步驟以鏈式的方式組合成AI流程;Agent工具由Agent類型、AgentExecutor、Tools(支持的工具列表:https://python.langchain.com/docs/integrations/tools)這幾個部分構成,幫助開發者將實時信息交互、外部數據獲取、三方系統調用等功能集成到“鏈”中以擴展或改善AI能力。例如:通過Google搜索獲取實時信息、從OpenWeatherMap獲取天氣信息,以及從Wikipedia獲取百科知識 。可以說,如果開發AI應用,LangChain不可或缺。(參考資料:https://www.ibm.com/topics/langchain)
目前,已經有一些比較典型的行業應用方案:
案例1:智能客服系統。在一個集成了大模型、RAG和智能體的智能客服系統中,大模型可用于理解用戶的查詢和生成自然語言回復,RAG技術可用于從企業的數據庫和知識庫中檢索準確的信息以支持回復,而智能體則負責管理對話流程、處理事務性任務和執行復雜的用戶請求。這種集成使得客服系統能夠提供更準確、更人性化的服務,同時減輕人工客服的負擔。
案例2:個性化教育平臺。在個性化教育平臺的例子中,大模型可以根據學生的學習進度和偏好生成定制的學習材料和測試,RAG技術可以從廣泛的教育資源中檢索相關信息以豐富教學內容,而智能體可以根據學生的反饋和學習成效調整教學策略和內容。這種集成不僅能夠為學生提供更加個性化的學習體驗,還能夠幫助教師更好地理解學生的需求和進步。
案例3:復雜決策支持系統。集成大模型、RAG和智能體的復雜決策支持系統能夠在金融、醫療和科研等領域提供強大的支持。在這種系統中,大模型用于處理和生成語言信息,RAG技術用于從大量數據中檢索相關信息和案例,智能體則負責綜合這些信息,形成決策建議。這種集成系統能夠處理復雜的查詢,提供基于數據的決策支持。
針對供應鏈物流領域通過集成大模型、RAG和智能體技術,可以從如下幾個業務系統探索突破點:
1.倉儲管理(WMS):結合RAG技術和智能體,系統能夠實時從供應商數據庫、倉庫庫存記錄和銷售數據中檢索關鍵信息,智能調整庫存水平,減少庫存積壓和缺貨風險。
2.運輸管理(TMS):通過分析地理位置數據、運輸成本和時間要求,智能體可以規劃最優的貨物配送路線和調度計劃。這一過程會利用大模型來處理復雜的邏輯和約束條件,以確保高效且成本效益的配送。
3.供應鏈銷售與運營規劃(S&OP):利用大模型處理歷史銷售數據、市場趨勢和用戶反饋,生成精準的需求預測報告。智能體能夠學習并適應市場變化,實時調整預測模型,提高預測的準確性。
未來展望與挑戰
對于未來,可以預見,AI的開發和應用會面臨諸多的機遇與問題,諸如更加深度的領域知識融合、數據隱私和安全性等等。但最主要的趨勢一定是未來的AI系統將具備更強的自適應學習能力并跳出虛擬世界,正如2023年黃仁勛提到人工智能的下一波浪潮是“具身智能(Embodied AI)”,即AI不僅能夠理解和處理信息,還能夠在物理世界中執行任務和作出反應。因此,智能體(Agent)在軟件領域會快速的發展,當其足夠成熟時,驅動硬件的智能體,即具身智能的規模化應用將是水到渠成的事情。隨之而來的,AI倫理問題一定會受到越來越多的挑戰:AI應用決策過程的透明度和可解釋性、AI決策結果的偏見不公平甚至歧視、人類倫理原則是否得到遵守等,2024年春節期間和生活在歐洲的同學交流得知,目前一些西方國家已經在開展一些“反人工智能(AntiAI)”的運動和研究,但主流思想并不是反對人工智能的發展,而是建立人工智能治理框架和開發監管技術(例如區分AI生成的內容和人類生成的內容),以確保人工智能的發展優先考慮人類福祉、倫理因素和安全(參考資料:https://dotcommagazine.com/2023/08/anti-ai-top-ten-things-you-need-to-know)。
另外AI技術發展與社會發展的和諧相融的問題也非常值得思考,如何避免AI造成的技術性失業這個問題,對我們軟件開發者而言顯得特別重要。2024年3月在央視《對話》節目上,李彥宏表示,“以后不會存在程序員這種職業了,因為只要會說話,人人都會具備程序員的能力……未來的編程語言只會剩下兩種,一種叫做英文,一種叫做中文”。回想20年前的軟件開發行業,除了測試,諸如需求分析、畫原型、網頁開發、桌面開發、后臺服務開發,甚至界面設計(美工兼職輔助平面設計)都是由程序員來做,幾乎所有當時的“大廠”皆是如此,后來隨著技術的演進和社會的發展,不僅編程開發這個行當分成了前端開發、后端開發、客戶端開發、大數據開發、算法開發等諸多工種,連“美工”都分化成了視覺、交互、用研等專業領域,那么,未來在AI技術的發展下,這些角色的分工會重新合并,甚至不會存在了么?
可能會出現如下的趨勢:
1.一定會提高效率和創造力。AIGC 可以大大提高設計人員和開發人員的效率,我們很多團隊在2023年初就開始使用Midjourney輔助設計或使用JoyCoder和GitHub Copilot輔助編碼,效果有目共睹。可以預見,在產品設計或代碼生成等探索性和創造性階段,通過AI智能體快速生成各種解決方案并將概念轉化為可視化表達或代碼,會變得越來越便捷并越來越具有實際價值。
2.開發者的角色可能會演變。開發者角色分工的界限會變得越來越模糊,全新的更具協作性和增強型的軟件開發生命周期會出現。未來的開發者和設計師會減少用于日常編碼或設計,甚至文檔撰寫的時間,而更多的時間用于明確智能體等AI工具的目標、解釋人工智能生成的解決方案,以及將這些解決方案集成到多種不同的系統架構中。開發者的角色可能會演變為承擔更多監督和管理的職能,以確保AI生成的設計和代碼符合業務目標以及人類價值觀。
3.軟件開發這個行業會“民主化”。隨著 AIGC 工具變得更加易用和強大,我們可能會看到越來越多沒有傳統設計和編碼技能的人也可以發起或參與軟件開發。這將使軟件開發這個行業參與的業務領域更加多樣化,數字化應用的范圍更加廣泛。
(參考資料:https://insights.sei.cmu.edu/blog/application-of-large-language-models-llms-in-software-engineering-overblown-hype-or-disruptive-change/)






























