一圖勝千言!深度掌握 Python 繪圖
據可視化是數據科學家傳達洞見和講述數據故事的關鍵工具。作為 Python 開發者,我們擁有豐富的可視化庫和工具,能夠創建各種引人入勝的圖表。本文將探索一些鮮為人知但實用的可視化類型,如桑基圖(Sankey Diagrams)、脊線圖(Ridge Plots)、內嵌圖(Insets)、雷達圖(Radar Chart)和詞云圖(Word Cloud Plots)。我們將主要使用流行的 Matplotlib、Seaborn 和 Plotly 這些 Python 庫來實現這些有趣的可視化效果,讓你的數據講述更加生動有趣。
我們將使用形狀、大小、顏色、方向、面積和標記符號等屬性,為十種不同的使用案例創建繪圖。在每個使用案例中,我們的目標都是創建有效、高效和美觀的可視化效果。描述這些詞語在圖表中的含義如下:
(a) 有效:圖表中包含了所有需要傳達的信息(b) 高效:圖表中沒有多余的數據(c) 美觀:圖表以清晰的方式展示數據,吸引注意力
所有圖表都是二維圖,因為從效率和效果的角度來看,二維圖比三維圖更清晰易懂,同時更容易描繪距離。文中還將介紹每個用例的代碼,并討論代碼和圖表中的要點。
用例 1
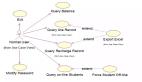
描述大學之間學生交流流動的桑基圖。
這些圖展示了資源流動的情況,下面的代碼展示了用例的實現。 字符 "A" 代表第一所大學,字符 "B" 代表第二所大學。 數字 3、4、5 分別代表不同的系,即{Statistics, Math, Physics}。第 25 行創建了一個圖表,其中 node 和 link是字典。 node 使用的 label 對象由唯一的 Depts 院系組成,而 link 使用的兩個列表分別由 sending"院系的索引和 acepting 院系的索引組成。
import pandas as pd
import plotly.graph_objects as gr
data = {
'Sending_Dept': ['5A', '4A', '5B', '5A', '4B', '4A', '3A', '3B', '3A', '3B', '3A', '3B'],
'Accepting_Dept': ['4B', '5B', '5A', '5B', '4A', '4B', '5B', '5A', '4B', '4A', '3B', '3A'],
'FlowValue': [1, 3, 4, 3, 4, 4, 1, 1, 3, 2, 5, 3]
}
df = pd.DataFrame(data)
unique_departments = set(df['Sending_Dept']).union(set(df['Accepting_Dept']))
Depts = list(unique_departments)
Dept_indices = {}
for i, dept in enumerate(Depts):
Dept_indices[dept] = i
sending_indices = []
for dept in df['Sending_Dept']:
dept_index = Dept_indices[dept]
sending_indices.append(dept_index)
print(f"Sending indices are: {sending_indices}")
accepting_indices = []
for dept in df['Accepting_Dept']:
dept_index = Dept_indices[dept]
accepting_indices.append(dept_index)
flowvalues = df['FlowValue'].tolist()
# Sankey diagram
fig = gr.Figure(data=[gr.Sankey(
node=dict( pad=10,thickness=25,line=dict(color="red", width=0.8),label=Depts,),
link=dict(source=sending_indices,target=accepting_indices,value=flowvalues
))])
fig.update_layout(title_text="Sankey Diagram of exchange students flow between University Depts", font_size=12)
fig.show()生成的"桑基圖"圖(1)中,節點3A旁的橙色矩形顯示了光標放置在節點上時的情況。當光標位于節點"3A"上時,我們可以看到A大學3系接受和派遣交換生的頻率。它接受學生1次,派遣學生3次。我們還可以從上面代碼片段中的 data 字典推斷出這一點,因為"3A"在Sending_Dept列表中出現了3次,在Accepting_Dept列表中出現了1次。節點 "3A" 左邊的數字9是它向B大學派出的交換生總數。我們還可以通過在Sending_Dept列表中添加與3A相對應的FlowValues來推斷。
我們還注意到,當我們點擊節點 "3A" 時,從它發出的箭頭會變暗,并顯示出與 "3A" 交換學生的其他節點。箭頭的粗細與 FlowValues 相對應。總之,桑基圖利用箭頭的方向和粗細來傳遞流動信息,并以文字為基礎為每個節點形成累積流動。
 圖 1. 桑基圖顯示了兩所大學各系之間的學生交流流
圖 1. 桑基圖顯示了兩所大學各系之間的學生交流流
用例 2
繪制一家房地產中介公司的房屋銷售數據。
一位數據科學家在房地產中介公司工作,機構要求繪制上個月售出房屋信息的二維圖。每棟售出的房屋需包含房價、距離市中心、方向、代理傭金和銷售代理的公司級別(助理、副總裁、合伙人)的信息。二維圖形信息量大,可使用復雜對象描述地塊上的每棟房屋。具體來說,使用“笑臉表情符號”實現方法的代碼片段如下。
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(125)
num_houses = 10
distances = np.random.uniform(0, 30, num_houses) # distance from city center
prices = np.random.uniform(400, 2000, num_houses) * 1000 # sale price in thousands
directions = np.random.choice(['N', 'S', 'E', 'W'], num_houses) # direction from city center
agent_levels = np.random.choice([1, 2, 3], num_houses) # agent's level
def get_emoji_size(level):
size_map = {1: 250, 2: 380, 3: 700}
return size_map.get(level, 120) # Increased size for better visibility
def get_emoji_color_new(price):
if price < 600000:
return 'white' # Light yellow for $400k-$600k
elif price < 800000:
return 'yellow' # White for $600k-$800k
elif price < 1000000:
return 'pink' # Pink for $800k-$1 million
else:
return 'lime' # Lime for $1 million-$2 million
def rotate_smiley(direction):
rotation_map = {'N': 0, 'E': 270, 'S': 180, 'W': 90}
return rotation_map.get(direction, 0) # default no rotation if direction not found
plt.figure(figsize=(12, 8))
for i in range(num_houses):
plt.scatter(distances[i], prices[i], s=get_emoji_size(agent_levels[i]),\
c=get_emoji_color_new(prices[i]),
marker='o', edgecolors='black', alpha=0.8)
plt.text(distances[i], prices[i], "??", fnotallow=agent_levels[i]*10,
rotatinotallow=rotate_smiley(directions[i]), ha='center', va='center',\
fnotallow='bold')
plt.xlabel('Distance from City Center (km)')
plt.ylabel('Sale Price ($)')
plt.title('House Sales Data for 10 Houses: Price vs Distance with New Color Scheme')
plt.grid(True)
plt.show()如上面的代碼和下面圖 2 中的散點圖所示,X 軸和 Y 軸分別對應于與市中心的距離和銷售價格。以下是一些要點:
- 表情符號的大小用于描述銷售代理的級別。尺寸越大,代理人的級別越高
- 表情符號微笑的位置(頂部、底部、左側、右側)表示從市中心出發的方向。例如,如果微笑在頂部,房子就在市中心的北面。
- 表情符號的顏色表示中介的傭金。例如,石灰色的傭金為 6%,粉紅色的傭金為 5%(房地產中介的傭金政策是,售價越高,傭金越高)。
作為本使用案例的結論,我們使用散點圖和表情符號的形狀、顏色和大小,在二維圖中表達了已售房屋的五個屬性。使用復雜的對象(如笑臉)來表示數據點,確實有助于在圖中包含大量信息。
 圖 2. 房屋銷售數據散點圖
圖 2. 房屋銷售數據散點圖
用例 3.在旭日圖中顯示某大學各學院和系的組成。還必須表達各學院和部門的規模信息。
這是一種不同組成部分具有層次結構的情況。在這種情況下,旭日圖是理想的選擇。下面的代碼片段展示了實現過程。第一個數組 labels 包含旭日圖的名稱。第二個數組 parents 包含層次結構,而數組 values 包含段的大小。
import plotly.graph_objects as go
labels = ["PineForest University",
"College of Engineering", "Natural Sciences", "Medical School",
"Chemical Engineering", "Mechanical Engineering", "Computer Science", "Electrical Engineering",\
"Biomedical Engineering",
"Astronomy", "Biology", "Mathematics", "Physics","Chemistry","Statistics","EarthSciences",\
"Emergency Medicine", "Neurology", "Cardiology", "Pediatrics", "Pathology","Family Medicine", \
"Orthopedics", "Obstetrics", "Anesthesiology", "Anatomy", "Physiology",\
"Microbiology","Immunology"]
parents = ["",
"PineForest University", "PineForest University", "PineForest University",
"College of Engineering", "College of Engineering", "College of Engineering",\
"College of Engineering","College of Engineering",
"Natural Sciences","Natural Sciences","Natural Sciences","Natural Sciences","Natural Sciences",\
"Natural Sciences","Natural Sciences",
"Medical School", "Medical School", "Medical School", "Medical School","Medical School", \
"Medical School","Medical School", "Medical School", "Medical School",\
"Medical School", "Medical School", "Medical School","Medical School"]
values = [0,
50, 30, 200,
85, 100, 180, 163,120,
90,70 ,104,54,180,100,70,
70,180,200, 85,170,89,75,120,76,150,67,56,239]
fig = go.Figure(go.Sunburst(
labels=labels,
parents=parents,
values=values,
))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0))
fig.show()圖 3 顯示了上述算法的輸出結果。請注意,每個片段的大小與 "值 "數組中的相應數字成正比。下圖顯示,當我們點擊一個片段時,它的大小就會顯示出來(Immunology 239)。
旭日圖使用大小、顏色和文本來描述大學不同實體的層次結構。
 圖 3. 旭日圖顯示了一所大學不同學院和系的結構
圖 3. 旭日圖顯示了一所大學不同學院和系的結構
用例 4
我們的房地產客戶需要一張二維圖,顯示上個月售出房屋的信息: (a) 售價,(b) 面積,(c) 海邊距離,(d) 火車站距離。必須放大已售出最多房屋的圖段。
本用例與用例 2 類似,但數據科學家有新任務:創建一個放大版的最繁忙圖段。這就是插圖。插圖可以放大圖表的重要部分,提高效果。下面的代碼片段顯示了插圖的實現。
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
np.random.seed(0)
size_of_house = np.random.uniform(1000, 4000, 100) # Size in square feet
price = size_of_house * np.random.uniform(150, 350) + np.random.normal(0, 50000, 100) # Price
distance_from_train = np.random.uniform(0.5, 5, 100) # Distance from train in miles
distance_from_ocean = np.random.uniform(0.1, 10, 100) # Distance from ocean in miles
df = pd.DataFrame({
'Size of House': size_of_house,
'Price': price,
'Distance from Train': distance_from_train,
'Distance from Ocean': distance_from_ocean
})
# Sample 10 points for a less cluttered plot
sampled_df = df.sample(10)
# Adding the inset
# Filtering sampled data for the inset plot
#inset_data = sampled_df[(sampled_df['Size of House'] >= 2000) & (sampled_df['Size of House'] <= 3000) & (sampled_df['Price'] >= 250000) & (sampled_df['Price'] <= 600000)]
inset_data=sampled_df
inset_ax = ax.inset_axes([0.7, 0.05, 0.25, 0.25]) # Inset axes
# Scatter plot in the inset with filtered sampled data
sns.scatterplot(data=inset_data, x='Size of House', y='Price', ax=inset_ax, size='Distance from Train', sizes=(40, 200), hue='Distance from Ocean', alpha=0.7, marker='D', legend=False)
# Capturing the part of the original regression line that falls within the bounds
sns.regplot(
x='Size of House',
y='Price',
data=df, # Using the entire dataset for the trend line
scatter=False,
color='red',
ax=inset_ax,
lowess=True,
truncate=True # Truncating the line within the limits of the inset axes
)
# Adjusting the limits of the inset axes
inset_ax.set_xlim(2000, 3500)
inset_ax.set_ylim(600000, 1000000)
# Display the plot
plt.show()插圖 4 展示了散點圖,其中 X 軸和 Y 軸分別代表房屋面積和售價。
菱形點代表已售出的房屋,顏色表示與海邊的距離,大小對應著與火車站的距離。 這個用例展示了如何通過嵌入地塊的重要部分來提高地塊的有效性。
 圖 4. 帶有插圖的房屋銷售數據
圖 4. 帶有插圖的房屋銷售數據
用例 5
為公眾號數據STUDO制作一張吸引眼球的海報
在本例中,我們將使用詞云圖。這種圖表包含不同大小的詞語,詞語的大小取決于它在原文中出現的頻率。圖 5 顯示了詞云圖,下面的代碼片段顯示了生成該圖的 Python 代碼。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# Sample from the reviews of a book
reviews = """
????寶藏級???? 原創公眾號『數據STUDIO』內容超級硬核。公眾號以Python為核心語言,垂直于數據科學領域,包括可戳?? Python|MySQL|數據分析|數據可視化|機器學習與數據挖掘|爬蟲 等,從入門到進階!
"""
font_path="/System/Library/fonts/PingFang.ttc" #解決中文亂碼
wordcloud = WordCloud(width=800, height=400, background_color='white', font_path=font_path).generate(reviews)
plt.figure(figsize=(12, 7), dpi=150)
plt.imshow(wordcloud, interpolatinotallow='bilinear')
plt.axis('off')
plt.show()
plt.figure(figsize=(12, 7))
plt.imshow(wordcloud, interpolatinotallow='bilinear')
plt.axis('off')
plt.show() 圖 5. 根據公眾號簡介創建的詞云
圖 5. 根據公眾號簡介創建的詞云
用例 6
以清晰而有說服力的方式介紹一種新零食產品的優勢。
我們的數據科學家的任務是展示市場營銷部門進行的一次民意調查的結果。在這次民意調查中,客戶被要求對一種高蛋白棒的新舊配方的性價比、營養價值、外觀和口味進行評分。
據科學家使用雷達圖來顯示投票結果。雷達圖將不同的屬性(口味、外觀等)放在不同的坐標軸上,然后連接屬于同一實體(本例中為蛋白棒)的屬性值,形成一個多邊形區域。不同的區域使用不同的顏色,便于查看者掌握產品之間的差異。
雷達圖(Radar Chart),又可稱為戴布拉圖、蜘蛛網圖(Spider Chart),每個分類都擁有自己的數值坐標軸,這些坐標軸由中心向外輻射, 并用折線將同一系列的值連接,用以顯示獨立的數據系列之間,以及某個特定的系列與其他系列的整體之間的關系。
圖 6 顯示了生成的圖形,下面的代碼片段顯示了生成圖形的 Python 代碼。下面代碼的第 7-9 行有一個有趣的地方。enpoint被設置為False,第一個值被添加到 old_values 和 new_values 數組的末尾,以關閉循環。
import matplotlib.pyplot as plt
import numpy as np
categories = ['Taste', 'Nutritional value', 'Appearance', 'Money Value']
old_values = [3, 4, 4, 3]
new_values = [5, 5, 4, 5]
N = len(categories)
angles = np.linspace(0, 2 * np.pi, N, endpoint=False).tolist()
old_values = np.append(old_values, old_values[0])
new_values = np.append(new_values, new_values[0])
angles = np.append(angles, angles[0])
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(polar=True))
ax.fill(angles, old_values, color='blue', alpha=0.4)
ax.fill(angles, product_values, color='lime', alpha=0.4)
ax.set_yticklabels([])
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories)
plt.title('Benchmarking: Standard vs New Product', size=20)
plt.legend(['Old Product', 'New Product'], loc='lower right', bbox_to_anchor=(1.1, 1.1))
plt.show()如下圖所示,人們認為新的蛋白質棒在三個關鍵方面優于舊產品:營養價值、口味和性價比。
在這個案例中,展示了如何利用顏色和形狀在雷達圖上區分兩種產品。
 圖 6. 展示兩種產品屬性差異的雷達圖
圖 6. 展示兩種產品屬性差異的雷達圖
用例 7
在同一幅圖上,顯示不同類型圖書在這些類型的圖書節前后的銷售情況。
在這個案例中,我們需用同一圖繪制不同類別的時間數據。Python的ridge plot適合這種情況。橋形圖以不同類別分布的垂直堆疊圖呈現,便于比較它們的異同。圖7顯示了不同圖書類型的銷售差異以相應圖書節為中心。將分布圖放在同一圖上,使用不同顏色,可創建一個視覺效果良好的圖表,有效比較。
相應代碼如下:
(a) ridge plot使用joyplot Python軟件包創建(b) 第6-13行模擬了各種圖書流派的分布情況,書籍類型后面的數字是相應分布的中心和標準偏差。(c) 在第20行,我們將數據放入一個DataFrame中,因為joyplot希望輸入一個DataFrame。(d) 在第30行、第33-36行,我們指定了軸[-1]上x軸的參數,即底圖的參數。
import matplotlib.pyplot as plt
import pandas as pd
from joypy import joyplot
import numpy as np
import scipy.stats as stats
book_festivals = {
'Mystery': [1,1],
'Adventure fiction':[6,2],
'Fantasy': [11,3],
'Self-help':[10,2],
'Sci-Fi': [7,2],
'Historical fiction': [12,1]
}
genre_data = {}
for genre, params in book_festivals.items():
mu,sigma=params
data = np.random.normal(mu, sigma, 300)
genre_data[genre] = data
genre_data_dict = {genre: data.tolist() for genre, data in genre_data.items()}
data=pd.DataFrame(genre_data_dict)
# Now we can plot it using joyplot
fig, axes = joyplot(
data,
figsize=(30, 18),
colormap=plt.cm.plasma,
alpha=1.0
)
colors = plt.cm.plasma(np.linspace(0, 1, len(data.columns)))
# Set x-axis labels and limits
axes[-1].set_xlim(1, 12)
month_order = ['January', 'February', 'March', 'April', 'May', 'June',
'July', 'August', 'September', 'October', 'November', 'December']
axes[-1].set_xticks(range(1, 13))
axes[-1].set_xticklabels(month_order)
axes[-1].tick_params(axis='x', labelsize='30')
axes[-1].set_xticklabels(month_order)
for ax in axes:
ax.set_yticks([])
legend_handles = [plt.Line2D([0], [0], color=color, lw=6, label=genre) for genre, \
color in zip(book_festivals.keys(), colors)]
ax.legend(handles=legend_handles, title='Book Genres', loc='upper right', fnotallow='26')
plt.show() 圖 7. 圖書類型的脊狀分布圖
圖 7. 圖書類型的脊狀分布圖
用例 8
給定信用卡公司提供的有關年齡和購買金額的數據,在圖中突出顯示購買金額最高的組別。
二維直方圖似乎適合這類數據,與標準直方圖不同,標準直方圖按一維分類,而二維直方圖同時按兩個維度分類。以下是代碼片段和圖8顯示的生成的二維直方圖。
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
ages = np.random.randint(18, 61, 20) # Random ages between 18 and 60 for 20 customers
purchase_amounts = np.random.randint(200, 1001, 20) # Random purchase amounts between 200 and 1000 for 20 customers
plt.figure(figsize=(10, 6))
plt.hist2d(ages, purchase_amounts, bins=[5, 5], range=[[18, 60], [200, 1000]], cmap='plasma')
plt.colorbar(label='Number of Customers')
plt.xlabel('Age')
plt.ylabel('Purchase Amount ($)')
plt.title('2D Histogram of Customer Age and Purchase Amount')下面的二維柱狀圖顯示,消費金額最高的是 35-45 歲的人群。總之,二維柱狀圖有效且直觀地顯示了購買金額最高的群體。
 圖 8:顯示年齡與購買金額的二維柱狀圖
圖 8:顯示年齡與購買金額的二維柱狀圖
用例 9
在一幅圖中,顯示 1990-2010 年生物、天文、物理和數學系的學生人數。
在這種情況下,我們可以使用堆疊面積圖。這種類型的圖表用于顯示不同類別的時間數據,可以使用堆疊區域圖來展示不同類別的時間數據,用戶可以看到:
(a) 每個類別隨時間的變化;(b) 它們的相對規模;(c) 它們隨時間的總規模。每個類別用不同的顏色標識。
代碼如下,圖 9 顯示了不同院系學生人數的堆疊面積圖。
堆疊面積圖與面積圖類似,都是在折線圖的基礎上,將折線與自變量坐標軸之間區域填充起來的統計圖表,主要用于表示數值隨時間的變化趨勢。 而堆疊面積圖的特點在于,有多個數據系列,它們一層層的堆疊起來,每個數據系列的起始點是上一個數據系列的結束點。
import matplotlib.pyplot as plt
import numpy as np
years = np.arange(1990, 2011)
biology_students = np.linspace(100, 1000, len(years))
astronomy_students = np.linspace(50, 150, len(years))
math_students = np.linspace(80, 500, len(years))
physics_students = np.linspace(70, 480, len(years))
plt.figure(figsize=(10, 6))
plt.stackplot(years, biology_students, astronomy_students, math_students,\
physics_students, labels=['Biology', 'Astronomy', 'Math', 'Physics'],\
colors=['#76b947', '#fcb001', '#00a2e8', '#ff7f27'])
plt.legend(loc='upper left')
plt.title('University Department Student Numbers (1990-2010)')
plt.xlabel('Year')
plt.ylabel('Number of Students')
plt.tight_layout()
plt.show() 圖 9. 不同院系學生人數的堆疊面積圖
圖 9. 不同院系學生人數的堆疊面積圖
用例 10
顯示一家公司 2010 年至 2020 年的營銷成本與收入對比。
與上一個用例一樣,我們也可以在這個用例中使用堆疊面積圖。然而,堆疊面積圖并不是萬能的,也不是繪制隨時間變化的分類差異的一站式解決方案。對于當前用例,比較營銷成本與收入的更有效方法是r收入柱狀圖,并將營銷成本作為趨勢線。代碼如下所示。將營銷成本作為趨勢線繪制在收入條形圖前,可以更有效地傳達營銷成本增加的信息。
import matplotlib.pyplot as plt
import numpy as np
years = np.arange(2010, 2021)
revenue = np.linspace(10, 60, len(years))
marketing_costs = revenue * 0.4
plt.figure(figsize=(8, 6))
plt.bar(years, revenue, color='lightblue', label='Revenue')
plt.plot(years, marketing_costs, color='red', marker='o', \
linestyle='-', linewidth=2, markersize=6, label='Marketing Costs')
plt.xlabel('Year')
plt.ylabel('Revenue (Millions)')
plt.title('Bar and Line Combination Plot')
plt.legend()
plt.tight_layout()
plt.show()
plt.figure(figsize=(8, 6))
plt.stackplot(years, marketing_costs, revenue, labels=['Marketing Costs', 'Revenue'], colors=['lightcoral', 'palegreen'])
plt.xlabel('Year')
plt.ylabel('Total Amount (Millions)')
plt.title('Area Plot')
plt.legend()
plt.tight_layout()
plt.show() 圖 10. 以營銷成本為趨勢線的收入柱狀圖
圖 10. 以營銷成本為趨勢線的收入柱狀圖
 圖 11. 收入和營銷成本的堆疊區域圖
圖 11. 收入和營銷成本的堆疊區域圖
結論
在這篇文章中,我們討論了各種用例和相應的 Python 圖,強調了 Python 語言在可視化方面的豐富性。從 Sankey 圖的流程到蜘蛛圖的輪廓再到山脊圖的多峰,展示了 Python 將原始數據轉化為引人注目的數據故事的能力。討論的圖只是 Python 廣泛工具箱中的一個縮影。