對象存儲是如何保存大小文件的?
對象存儲是一個相對較新并且在持續穩步增長的市場部分。對于新手而言,對象存儲用于保存大量非結構化數據,其中每個“對象”實際上是一個沒有特定格式的文件(也稱二進制文件)。實際上,從小的對象(人類可讀取文件)到媒體(音頻和視頻)或其它行業特定格式(石油&天然氣,醫學成像等),對象存儲可以保存任何類型的數據。

與傳統存儲相比,采用對象存儲的好處良多。基于塊的系統(例如光纖通道和iSCSI)無法很好地向外擴展,并且沒有真正的了解所存儲的數據。它們是以低延遲和高粒度提供內容的“啞”塊設備。文件系統將一些結構放在數據上,將文件對象放入層級結構(文件夾/目錄)然后將元數據附加到這些對象上。然而,元數據通常只是基于存儲文件所需的信息(創建時間,時間更新,訪問規則)存儲文件。
對象存儲更進一步消除了文件夾層次結構,具有高度可搜索的可擴展元數據。在規模方面,對象存儲可以增加到多(即便不是上百)PB容量,通常對數據沒有地域限制。因為對象存儲平臺提供了優于傳統存儲的形式,越來越多的企業開始采用它。基于塊的存儲陣列無法很好地擴展,且帶有大量HDD和SSD的數據保護(例如RAID)的問題。基于文件的系統受到系統自身的可擴展性限制,無論是在對象計數、并發、并行訪問或恢復時間方面,都能檢驗出文件系統結構的一致性。對象存儲代表一種更簡單、更可擴展的解決方案,通過標準的基于網絡的協議可輕松訪問。
我們都知道,保存像圖片、音視頻這類大文件,最佳的選擇就是 對象存儲。對象存儲不僅有很好的 大文件讀寫性能,還可以 通過水平擴展實現近乎無限的容量,并且可以 兼顧服務高可用、數據高可靠 這些特性。
對象存儲之所以能做到這么「全能」,最主要的原因是,對象存儲是原生的分布式存儲系統。這里我們講的「原生分布式存儲系統」,是相對于 MySQL、Redis 這類單機存儲系統來說的。雖然這些非原生的存儲系統,也具備一定的集群能力,但你也能感受到,用它們構建大規模分布式集群的時候,其實是非常不容易的。
隨著云計算的普及,很多新生代的存儲系統,都是原生的分布式系統,它們一開始設計的目標之一就是分布式存儲集群,比如說 Elasticsearch、Ceph 和國內很多大廠推出的新一代數據庫,大多都可以做到:
- 近乎無限的存儲容量;
- 超高的讀寫性能;
- 數據高可靠:節點磁盤損毀不會丟數據;
- 實現服務高可用:節點宕機不會影響集群對外提供服務。
那這些原生分布式存儲是如何實現這些特性的呢?這里面同樣存在嚴重的「互相抄作業」的情況。這個也可以理解,除了存儲的數據結構不一樣,提供的查詢服務不一樣以外,這些分布式存儲系統,它們面臨的很多問題都是一樣的,那實現方法差不多也是可以理解。
對象存儲的查詢服務和數據結構都非常簡單,是最簡單的原生分布式存儲系統,對象存儲數據是如何保存大文件的?

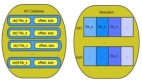
對象存儲對外提供的服務,其實就是一個 近乎無限容量的大文件 KV 存儲,所以對象存儲和分布式文件系統之間,沒有那么明確的界限。對象存儲的內部,肯定有很多的存儲節點,用于保存這些大文件,這個就是數據節點的集群。
另外,我們為了管理這些數據節點和節點中的文件,還需要一個存儲系統保存集群的節點信息、文件信息和它們的映射關系。這些為了管理集群而存儲的數據,叫做元數據 (Metadata)。
元數據對于一個存儲集群來說是非常重要的,所以保存元數據的存儲系統必須也是一個集群。但是元數據集群存儲的數據量比較少,數據的變動不是很頻繁,加之客戶端或者網關都會緩存一部分元數據,所以元數據集群對并發要求也不高。一般使用類似 ZooKeeper 或者 etcd 這類分布式存儲就可以滿足要求。
另外,存儲集群為了對外提供訪問服務,還需要一個 網關集群,對外接收外部請求,對內訪問元數據和數據節點。網關集群中的每個節點不需要保存任何數據,都是無狀態的節點。有些對象存儲沒有網關,取而代之的是客戶端,它們的功能和作用都是一樣的。

那么,對象存儲是如何來處理對象讀寫請求的呢?這里面處理讀和寫請求的流程是一樣的,我們一起來說。網關收到對象讀寫請求后,首先拿著請求中的 Key,去元數據集群查找這個 Key 在哪個數據節點上,然后再去訪問對應的數據節點讀寫數據,最后把結果返回給客戶端。
以上是一個比較粗略的大致流程,實際上這里面包含很多的細節,我們暫時沒有展開講。目的是讓你在整體上對對象存儲,以至于分布式存儲系統,有一個清晰的認知。
對象是如何拆分和保存的?
一般來說,對象存儲中保存的文件都是圖片、視頻這類大文件。在對象存儲中,每一個大文件都會被拆成多個大小相等的塊兒(Block),拆分的方法很簡單,就是把文件從頭到尾按照固定的塊兒大小,切成一塊兒一塊兒,最后一塊兒長度有可能不足一個塊兒的大小,也按一塊兒來處理。塊兒的大小一般配置為幾十 KB 到幾個 MB 左右。
把大對象文件拆分成塊兒的目的有兩個:
- 第一是為了 提升讀寫性能,這些塊兒可以分散到不同的數據節點上,這樣就可以并行讀寫。
- 第二是 把文件分成大小相等塊兒,便于維護管理。
對象被拆成塊兒之后,還是太過于碎片化了,如果直接管理這些塊兒,會導致元數據的數據量會非常大,也沒必要管理到這么細的粒度。所以一般都會再把塊兒聚合一下,放到塊兒的容器里面。
這里的「容器」就是存放一組塊兒的邏輯單元。容器這個名詞,沒有統一的叫法,比如在 ceph 中稱為 Data Placement。容器內的塊兒數大多是固定的,所以容器的大小也是固定的。
到這里,這個 容器的概念,就比較 類似 于我們之前講 MySQL 和 Redis 時提到的**「分片」的概念** 了,都是復制、遷移數據的基本單位。每個容器都會有 N 個副本,這些副本的數據都是一樣的。其中有一個主副本,其他是從副本,主副本負責數據讀寫,從副本去到主副本上去復制數據,保證主從數據一致。
對象存儲一般都不記錄類似 MySQL 的 Binlog 這樣的日志。主從復制的時候,復制的不是日志,而是整塊兒的數據。這么做有兩個原因:
- 第一個原因是基于性能的考慮。
我們知道操作日志里面,實際上就包含著數據。在更新數據的時候,先記錄操作日志,再更新存儲引擎中的數據,相當于在磁盤上串行寫了 2 次數據。對于像數據庫這種,每次更新的數據都很少的存儲系統,這個開銷是可以接受的。但是對于對象存儲來說,它每次寫入的塊兒很大,兩次磁盤 IO 的開銷就有些不太值得了。 - 第二個原因是它的存儲結構簡單,即使沒有日志,只要按照順序,整塊兒的復制數據,仍然可以保證主從副本的數據一致性。
以上我們說的 對象(也就是文件)、塊兒和容器,都是 邏輯層面的概念,數據落實到副本上,這些副本就是真正物理存在了。這些副本再被分配到 數據節點 上保存起來。這里的數據節點就是運行在服務器上的服務進程,負責在本地磁盤上保存副本的數據。

了解了對象是如何被拆分并存儲在數據節點上之后,我們再來回顧一下數據訪問的流程。當我們請求一個 Key 的時候,網關首先去元數據中查找這個 Key 的元數據。然后根據元數據中記錄的對象長度,計算出對象有多少塊兒。接下來的過程就可以分塊兒并行處理了。對于每個塊兒,還需要再去元數據中,找到它被放在哪個容器中。
我剛剛講過,容器就是分片,怎么把塊兒映射到容器中,這個方法就是我們在《MySQL 存儲海量數據的最后一招:分庫分表》 課中講到的幾種分片算法。不同的系統選擇實現的方式也不一樣,有用哈希分片的,也有用查表法把對應關系保存在元數據中的。找到容器之后,再去元數據中查找容器的 N 個副本都分布在哪些數據節點上。然后,網關直接訪問對應的數據節點讀寫數據就可以了。
對象存儲是最簡單的分布式存儲系統,主要由 數據節點集群、**元數據集群 **和 **網關集群(或者客戶端)**三部分構成。
- 數據節點集群:負責保存對象數據,
- 元數據集群:負責保存集群的元數據,
- 網關集群和客戶端:對外提供簡單的訪問 API,對內訪問元數據和數據節點讀寫數據。
為了便于維護和管理,大的對象被拆分為若干固定大小的塊兒,塊兒又被封裝到容器(也就分片)中,每個容器有一主 N 從多個副本,這些副本再被分散到集群的數據節點上保存。
對象存儲雖然簡單,但是它具備一個分布式存儲系統的全部特征。所有分布式存儲系統共通的一些特性,對象存儲也都具備,比如說數據如何分片,如何通過多副本保證數據可靠性,如何在多個副本間復制數據,確保數據一致性等等。
不僅是學會對象存儲,還要對比分析一下,對象存儲和其他分布式存儲系統,比如 MySQL 集群、HDFS、Elasticsearch 等等這些,它們之間有什么共同的地方,差異在哪兒。想通了這些問題,你對分布式存儲系統的認知,絕對會上升到一個全新的高度。然后你再去看一些之前不了解的存儲系統,就非常簡單了。
對象存儲并不是基于日志來進行主從復制的。假設我們的對象存儲是一主二從三個副本,采用半同步方式復制數據,也就是主副本和任意一個從副本更新成功后,就給客戶端返回成功響應。主副本所在節點宕機之后,這兩個從副本中,至少有一個副本上的數據是和宕機的主副本上一樣的,我們需要找到這個副本作為新的主副本,才能保證宕機不丟數據。
但是沒有了日志,如果這兩個從副本上的數據不一樣,我們如何確定哪個上面的數據是和主副本一樣新呢?一般都是基于版本號來解決,在 Leader上,KEY 每更新一次,KEY 的版本號就加 1,版本號作為 KV 的一個屬性,一并復制到從節點上,通過比較版本號就可以知道哪個節點上的數據是最新的。
如果用比較時間戳的方式來解決這個問題。這個方法理論上可行,但實際上非常難實現,因為它要求集群上的每個節點的時鐘都必須時刻保持同步,這個要求往往非常難達到。