SoCC 論文解讀:字節跳動如何在大規模集群中進行統一資源調度

本文解讀了字節跳動基礎架構編排調度團隊發表在國際云計算頂級會議 SoCC 2023 上的論文“G?del: Unified Large-Scale Resource Managment and Scheduling at Bytedance”。

論文鏈接: dl.acm.org/doi/proceedings/10.1145/3620678
論文介紹了字節跳動內部基于 Kubernetes 提出的一套支持在線任務和離線任務混部的高吞吐任務調度系統,旨在有效解決大規模數據中心中不同類型任務的資源分配問題,提高數據中心的資源利用率、彈性和調度吞吐率。
目前,該調度系統支持管理著數萬節點的超大規模集群,提供包括微服務、batch、流式任務、AI 在內的多種類型任務的資源并池能力。自 2022 年開始在字節跳動內部各數據中心批量部署,G?del 調度器已經被驗證可以在高峰期提供 >60%的 CPU 利用率和 >95%的 GPU 利用率,峰值調度吞吐率接近 5,000 pods/sec。
引言
在過去的幾年里,隨著字節跳動各業務線的高速發展,公司內部的業務種類也越來越豐富,包括微服務、推廣搜(推薦/廣告/搜索)、大數據、機器學習、存儲等業務規模迅速擴大,其所需的計算資源體量也在飛速膨脹。
早期字節跳動的在線業務和離線業務有獨立的資源池,業務之間采用分池管理。為了應對重要節日和重大活動時在線業務請求的爆炸性增長,基礎設施團隊往往需要提前做預案,將部分離線業務的資源拆借到在線業務的資源池中。雖然這種方法可以應對一時之需,但不同資源池之間的資源拆借流程長,操作復雜,效率很低。同時,獨立的資源池導致在離線業務之間混部成本很高,資源利用率提升的天花板也非常有限。
為了應對這一問題,論文中提出了在離線統一調度器 G?del,旨在使用同一套調度器來統一調度和管理在離線業務,實現資源并池,從而在提升資源利用率和資源彈性的同時,優化業務成本和體驗,降低運維壓力。G?del 調度器基于 Kubernetes 平臺,可以無縫替換 Kubernetes 的原生調度器,在性能和功能上優于 Kubernetes 原生調度器和社區中其他調度器。
開發動機
字節跳動運營著數十個超大規模的多集群數據中心,每天有數以千萬計容器化的任務被創建和刪除,晚高峰時單個集群的平均任務吞吐 >1000 pods/sec。這些任務的業務優先級、運行模式和資源需求各不相同,如何高效、合理地調度這些任務,在保證高優任務 SLA 和不同任務資源需求的同時維持較高的資源利用率和彈性是一項很有挑戰的工作。

通過調研,目前社區常用的集群調度器都不能很好地滿足字節跳動的要求:
- Kubernetes 原生調度器雖然很適合微服務調度,也提供多種靈活的調度語義,但是它對離線業務的支持不盡如人意,同時因為 Kubernetes 原生調度器調度吞吐率低(< 200 pods/sec),支持的集群規模也有限(通常 <= 5000 nodes),它也無法滿足字節跳動內部龐大的在線業務調度需求。
- CNCF 社區的 Volcano 是一款主要針對離線業務的調度器,可以滿足離線業務(e.g. batch, offline training 等)的調度需求(e.g. Gang scheduling)。但是其調度吞吐率也比較低,而且不能同時支持在線業務。
- YARN 是另一款比較流行的集群資源管理工具,在過去很長一段時間一直是離線業務調度的首選。它不僅對 batch、offline training 等離線業務所需的調度語義有很好的支持,而且調度吞吐率也很高,可以支持很大規模的集群。但其主要弊端是對微服務等在線業務的支持不好,不能同時滿足在線和離線業務的調度需求。

因此,字節跳動希望能夠開發一款結合 Kubernetes 和 YARN 優點的調度器來打通資源池、統一管理所有類型的業務。基于上述討論,該調度器被期望具有下述特點:
- Unified Resource Pool
集群中的所有計算資源對在線和離線的各種任務均可見、可分配。降低資源碎片率,和集群的運維成本。
- Improved Resource Utilization
在集群和節點維度混部不同類型、不同優先級的任務,提高集群資源的利用率。
- High Resource Elasticiy
在集群和節點維度,計算資源可以在不同優先級的業務之間靈活且迅速地流轉。在提高資源利用率的同時,任何時候都保證高優業務的資源優先分配權和 SLA。
- High Scheduling Throughput
相比于 Kubernetes 原生調度器和社區的 Volcano 調度器,不論是在線還是離線業務都要大幅提高調度吞吐率。滿足 > 1000 pods/sec 的業務需求。
- Topology-aware Scheduling
在做調度決策時而不是 kubelet admit 時就識別到候選節點的資源微拓撲,并根據業務需求選擇合適的節點進行調度。
G?del 介紹
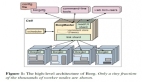
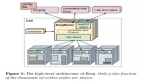
G?del Scheduler 是一個應用于 Kubernetes 集群環境、能統一調度在線和離線業務的分布式調度器,能在滿足在離線業務功能和性能需求的前提下,提供良好的擴展性和調度質量。
如下圖所示,G?del Scheduler 和 Kubernetes 原生調度器的結構類似,由三個組件組成:Dispatcher、Scheduler 和 Binder。不一樣的是,為了支持更大規模的集群和提供更高的調度吞吐,它的 Scheduler 組件可以是多實例的,采用樂觀并發調度, Dispatcher 和 Binder 則是單實例運行。

核心組件
Dispatcher 是整個調度流程的入口,主要負責任務排隊、任務分發、節點分區等工作。它主要由幾個部分構成:Sorting Policy Manager、Dispatching Policy Manager、Node Shuffler、Scheduler Maintainer。

- Sort Policy Manager:主要負責對任務進行排隊,現在實現了 FIFO、DRF、FairShare 等排隊策略,未來會添加更多排隊策略,如:priority value based 等。
- Dispatching Policy Manager:主要負責分發任務到不同的 Scheduler 實例,通過插件化配置支持不同的分發策略。現階段的默認策略是基于 LoadBalance。
- Node Shuffler:主要負責基于 Scheduler 實例個數,對集群節點進行 Partition 分片。每個節點只能在一個 Partition 里面。每個 Scheduler 實例對應一個 Partition,一個 Scheduler 實例工作的時候會優先選擇自己 Partition 內的節點,沒有找到符合要求的節點時才會去找其他 Partition 的節點。如果集群狀態發生變化,例如增加或者刪除節點,又或者 Scheduler 個數改變,node shuffle 會基于實際情況重新劃分節點。
- Scheduler Maintainer:主要負責對每個 Scheduler 實例狀態進行維護,包括 Scheduler 實例健康狀況、負載情況、Partition 節點數等。
Scheduler 從Dispatcher 接收任務請求,負責為任務做出具體的調度和搶占決策,但是不真正執行。和 Kubernetes 原生調度器一樣,G?del 的 Scheduler 也是通過一系列不同環節上的 plugins 來決定一個調度決策,例如通過下面兩個 plugins 來尋找符合要求的節點。
- Filtering plugins:基于任務的資源請求,過濾掉不符合要求的節點;
- Scoring plugins:對上面篩選出來的節點進行打分,選出最合適的節點。
和 Kubernetes 原生調度器不同的是,G?del 的 Scheduler 允許多實例分布式運行。對于超大規模的集群和對高吞吐有要求的場景,我們可以配置多個 scheduler 實例來滿足需求。此時每個 scheduler 實例獨立、并行地進行調度,選擇節點時,優先從該實例所屬的 partition 中選擇,這樣性能更好,但只能保證局部最優;本地 partition 沒有合適的節點時,會從其他實例的 partition 中選擇節點,但這可能會引起 conflict,即多個 scheduler 實例同時選中同一個節點,scheduler 實例數量越多,發生 conflict 的幾率越大。因此,要合理設置實例的數量,不是越多越好。
另外,為了同時支持在線和離線任務,G?del Scheduler 采用了兩層調度語義,即支持代表 Pod Group 或 ReplicaSet 等業務部署的 Scheduling Unit 和 Pod 的 Running Unit 的兩級調度。具體用法將在后面介紹。
Binder 主要負責樂觀沖突檢查,執行具體的搶占操作,進行任務綁定前的準備工作,比如動態創建存儲卷等,以及最終執行綁定操作。總的來說,它和 Kubernetes 的 Binder 工作流程類似,但在 G?del 中,Binder 要處理更多由于多 Scheduler 實例導致的沖突。一旦發現沖突,立即打回,重新調度。對于搶占操作,Binder 檢查是否存在多個 Schduler 實例嘗試搶占同一個實例(i.e. Victim Pod)。如果存在這樣的問題,Binder 只處理第一個搶占并拒絕其余 Schduler 實例發出的搶占訴求。對于 Gang/Co-scheduling 而言,Binder 必須為 Pod Group 中的所有 Pod 處理沖突(如果存在的話)。要么所有 Pod 的沖突都得到解決,分別綁定每個 Pod;要么拒絕整個Pod Group 的調度。
CNR 代表 Custom Node Resource,是字節跳動為補充節點實時信息創建的一個 CRD。它雖然本身不是 G?del Scheduler 的一部分,但可以增強 G?del 的調度語義。該 CRD 不僅定義了一個節點的資源量和狀態,還定義了資源的微拓撲,比如 dual-socket 節點上每個 socket 上的 CPU/Memory 消耗量和資源剩余量。使得調度器在調度有微拓撲親和需求的任務時,可以根據 CNR 描述的節點狀態篩選合適的節點。
相比于只使用 topology-manager 的原生 Kubernetes,使用 CNR 可以避免將 Pod 調度到不滿足 topology 限制的節點上時 kubelet 碰到的 scheduling failure。如果一個 Pod 成功地在節點上創建,CNR 將會被隸屬于 Katalyst 的 node agent 更新。
相關閱讀:《Katalyst:字節跳動云原生成本優化實踐》
兩層調度
字節跳動在設計 G?del 之初,一個主要的目標就是能夠同時滿足在線和離線業務的調度需求。為了實現這一目標,G?del 引入了兩層調度語義,即 Scheduling Unit 和 Running Unit。
前者對應一個部署的 job,由一個或多個 Running Unit 組成。例如,當用戶通過 Kubernetes Deployment 部署一個 job 時,這個 job 映射為一個 Scheduling Unit,每個運行 task 的 Pod 對應一個 Running Unit。和原生 Kubernetes 直接面向 Pod 的調度不同,G?del 的兩級調度框架會始終以 Scheduling Unit 的整體狀態為準入原則。當一個 Scheduling Unit 被認為可調度時,其包含的 Running Unit(i.e. Pod)才會被依次調度。
判斷一個 Scheduling Unit 是否可調度的規則是有 >= Min_Member 個 Running Unit 滿足調度條件,即調度器能夠為一個 job 中足夠多的 Pod 找到符合資源要求的節點時,該 job 被認為是可以被調度的。此時,每個 Pod 才會被調度器依次調度到指定的節點上。否則,所有的 Pod 均不會被調度,整個 job 部署被拒絕。
可以看出,Scheduling Unit 的 Min_Member 是一個非常重要的參數。設置不同的 Min_Member 可以應對不同場景的需求。Min_Member 的取值范圍是[1, Number of Running Units]。
比如,當面向微服務的業務時,Min_Member 設置為 1。每個 Scheduling Unit 中只要有一個 Running Unit/Pod 的資源申請能夠被滿足,即可進行調度。此時,G?del 調度器的運行和原生 Kubernetes 調度器基本一致。
當面向諸如 Batch、offline training 等需要 Gang 語義的離線業務時,Min_Member 的值等于 Running Unit/Pod 的個數(有些業務也可以根據實際需求調整為 1 到 Number of Running Units 之間的某個值),即所有 Pod 都能滿足資源請求時才開始調度。Min_Member 的值會根據業務類型和業務部署 template 中的參數被自動設置。
性能優化
因為字節跳動自身業務的需求,對調度吞吐的要求很高。G?del 的設計目標之一就是提供高吞吐。為此,G?del 調度器把最耗時的篩選節點部分放在可并發運行的多實例 Scheduler 中。一方面因為多實例會碰到 conflict 的原因,Schduler 的實例數量不是越多越好;另一方面僅僅多實例帶來的性能提高不足以應對字節單一集群上晚高峰 1000 - 2000 pods/s 的吞吐要求。為了進一步提高調度效率,G?del 在以下幾個方面做了進一步優化。
- 緩存候選節點
在篩選節點的過程中,Filter 和 Prioritize 是最耗時的兩個部分。前者根據資源請求篩選可用的節點,后者給候選節點打分尋找最適宜的節點。如果這兩個部分的運行速度能夠提高,則整個調度周期會被大幅壓縮。
字節跳動開發團隊觀察到,雖然計算資源被來自不同業務部門的不同應用所使用,但是來自某一個業務用戶的某個應用的所有或者大部分 Pods 通常有著相同的資源訴求。
例:某個社交 APP 申請創建 20,000 個 HTTP Server,每個 Server 需要 4 CPU core 和 8GB 內存。某個 Big Data 團隊需要運行一個擁有 10,000 個子任務的數據分析程序,每個子任務需要 1 CPU core 和 4GB 內存。
這些大量創建的任務中多數 Pod 擁有相同的資源申請、相同的網段和設備親和等需求。那么 Filter Plugin 篩選出來的候選節點符合第一個 Pod 的需求,也大概率滿足該任務其他 Pod 的需求。
因此,G?del 調度器會在調度第一個 Pod 后緩存候選節點,并在下一輪調度中優先從緩存中搜索可用的節點。除非集群狀態發生變化(增加或刪除節點)或者碰到不同資源訴求的 Pod,不需要每一輪都重新掃描集群中的節點。在調度的過程中沒有資源可分配的節點會被移除緩存,并根據集群狀態調整排序。這一優化可以明顯優化節點篩選的過程,當調度同一個業務用戶的一組 Pod 時,理想情況下可以把時間復雜度從 O(n) 降低到 O(1)。
- 降低掃描節點的比例
雖然上述優化可以降低候選節點的構建過程,但是如果集群狀態或者資源申請發生變化,還是要重新掃描集群所有節點。
為了進一步降低時間開銷,G?del 調整了候選列表的掃描比例,用局部最優解作為全局最優解的近似替代。因為調度過程中需要為所有 Running Units/Pods 找到足夠的候選節點,G?del 至少會掃描 # of Running Units 個數的節點,根據歷史數據的分析,G?del 默認掃描 # of Running Units + 50 個節點來尋找候選節點。如果沒有找到合適的,會再掃描相同的個數。該方法結合候選節點緩存,會大大降低調度器為Pod尋找合適節點的時間開銷。
- 優化數據結構和算法
除了上述兩個優化外,G?del 調度器還不斷對數據結構和算法進行優化:
為了可以低成本地維護候選節點列表,避免頻繁重建節點列表產生的開銷。G?del 重構了原生 Kubernetes 調度器的 NodeList 維護機制,通過離散化節點列表的方式解決了超大規模生產集群出現的性能問題,并以更低的開銷獲得了更好的節點離散效果;
為了提高整體資源利用率,字節跳動將高優的在線任務和低優的離線任務混合部署。由于業務的潮汐特點,晚高峰時伴隨著大量在線業務的返場,往往需要高頻地搶占低優的離線業務。搶占過程涉及到大量的搜索計算,頻繁搶占嚴重地影響了調度器的整體工作效率。為了解決這一問題,G?del 調度器引入了基于 Pod 和 Nodes 的多維剪枝策略,使得搶占吞吐能夠快速回升、搶占時延大幅降低。
實驗結果
論文評估了 G?del 調度器在調度吞吐、集群規模等方面的性能。
首先,對于微服務業務,字節跳動將 G?del(單實例)與 Kubernetes 原生調度器進行了對比。在集群規模上,原生 Kubernetes 默認最大只能支持 5,000 節點的集群,最大調度吞吐小于200 Pods/s。在使用字節開源的高性能 key-value store - KubeBrain 后,原生 Kubernetes 可以支持更大規模的集群,調度吞吐也明顯提高。但 Kubernetes + KubeBrain 組合后的性能仍然遠小于 G?del。G?del 在 5,000 節點規模的集群上可以達到 2,600 Pods/s 的性能,即使在 20,000 節點時仍然有約 2,000 Pods/s,是原生 Kubernetes 調度器性能的 10 倍以上。
為了取得更高的調度吞吐,G?del 可以開啟多實例。下面右圖中描述的是 10,000 節點的集群中依次開啟 1-6個 調度器實例,開始階段吞吐逐漸增加,峰值可以達到約 4,600 Pods/s。但當實例數超過 5 個后,性能有所下降,原因是實例越多,實例間的沖突越多,影響了調度效率。所以,并不是調度實例越多越好。

對于有 Gang 語義需求的離線任務,論文將 G?del 和開源社區常用的 YARN 和 K8s-volcano 進行對比。可以明顯看出,G?del 的性能不但遠遠高于 K8s-volcano,也接近兩倍于 YARN。G?del 支持同時調度在線和離線任務,論文通過改變系統中提交的在離線任務的比例來模擬不同業務混部時的場景。可以看出,不論在離線業務的比例如何,G?del的性能都比較穩定,吞吐維持在 2,000 Pods/s 左右。

為了論證為什么 G?del 會有如此大的性能提高,論文著重分析了兩個主要的優化“緩存候選節點”和“降低掃描比例”產生的貢獻。如下圖所示,依次使用完整版 G?del、只開啟節點緩存優化的 G?del 和只開啟降低掃描比例的 G?del 來重復前面的實驗,實驗結果證明,這兩個主要的優化項分別貢獻了約 60% 和 30% 的性能提升。

除了用 benchmark 來評估 G?del 的極限性能,論文還展示了字節跳動在生產環境中使用 G?del 調度器帶來的實際體驗,表現出 G?del 在資源并池、彈性和流轉方面具備良好的能力。
下面左圖描述的是某集群在某段時間內在線任務和離線任務的資源分配情況。開始階段,在線任務消耗的資源不多,大量計算資源被分配給優先級較低的離線任務。當在線任務由于某個特殊事件(突發事件、熱搜等)導致資源需求激增后,G?del 立刻把資源分配給在線任務,離線任務的資源分配量迅速減少。當高峰過后,在線任務開始降低資源請求,調度器再次把資源轉向離線任務。通過在離線并池和動態資源流轉,字節跳動可以一直維持較高的資源利用率。晚高峰時間,集群的平均資源率達到 60%以上,白天波谷階段也可以維持在 40% 左右。

總結及未來展望
論文介紹了字節跳動編排調度團隊設計和開發的統一在離線資源池的調度系統 G?del。該調度系統支持在超大規模集群中同時調度在線和離線任務,支持資源并池、彈性和流轉,并擁有很高的調度吞吐。G?del 自 2022 年在字節跳動自有數據中心批量上線以來,滿足了內場絕大部分業務的混部需求,實現了晚高峰 60% 以上的平均資源利用率和約 5,000 Pods/s 的調度吞吐。
未來,編排調度團隊會繼續推進 G?del 調度器的擴展和優化工作,進一步豐富調度語義,提高系統響應能力,降低多實例情況下的沖突概率,并且會在優化初次調度的同時,構建和加強系統重調度的能力,設計和開發 G?del Rescheduler。通過 G?del Scheduler 和 Rescheduler 的協同工作,實現全周期內集群資源的合理分配。