緩存使用中常見的坑及解決方案
作者:lyl
使用緩存并非沒有代價,如果不當使用或配置,很容易遇到各種問題。本文將探討在緩存使用過程中可能遇到的一些常見“坑”以及相應的解決方案。
在軟件開發中,緩存是提高系統性能和響應速度的關鍵技術之一。然而,使用緩存并非沒有代價,如果不當使用或配置,很容易遇到各種問題。本文將探討在緩存使用過程中可能遇到的一些常見“坑”以及相應的解決方案。

1. 緩存擊穿
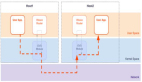
問題描述: 緩存擊穿是指查詢一個不存在的數據,由于緩存中也沒有,導致每次都去數據庫中查詢,而數據庫也沒有該數據,這樣每次都進行了無用的數據庫查詢,增加了數據庫壓力。
解決方案:
- 空值緩存:當數據庫查詢不到數據時,仍然將鍵與空值(如null)放入緩存,并設置一個較短的過期時間。這樣,后續的相同查詢可以直接從緩存中獲取空值,避免了對數據庫的頻繁無效查詢。
- 布隆過濾器:使用布隆過濾器等數據結構預先判斷數據是否存在,從而避免對不存在的數據進行查詢。
2. 緩存雪崩
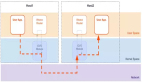
問題描述: 緩存雪崩是指當大量緩存同時過期,或者緩存服務宕機時,所有請求都會直接打到數據庫上,導致數據庫壓力過大甚至宕機。
解決方案:
- 緩存過期時間隨機化:避免大量緩存同時過期,可以將緩存的過期時間設置為一個范圍內的隨機值。
- 使用高可用緩存集群:如Redis Cluster或Sentinel,確保緩存服務的高可用性。
- 降級和熔斷:在檢測到數據庫壓力過大時,通過降級策略返回默認數據或錯誤信息,并通過熔斷機制防止進一步的壓力傳遞。
3. 緩存預熱
問題描述: 緩存預熱是指在系統啟動時或緩存清空后,大量請求同時到達,由于緩存中無數據,導致大量請求直接訪問數據庫,造成數據庫壓力驟增。
解決方案:
- 預加載緩存:在系統啟動時或定期地,預先將熱點數據加載到緩存中。
- 懶加載與異步更新:在緩存未命中時,不僅從數據庫中加載數據,還觸發異步任務更新其他相關緩存項。
4. 緩存與數據庫一致性
問題描述: 當數據庫中的數據發生變化時,如何確保緩存中的數據與之保持一致是一個挑戰。
解決方案:
- 先更新數據庫,再刪除緩存:在更新數據時,首先更新數據庫,然后刪除相關緩存。后續的查詢會重新加載緩存。
- 使用消息隊列:通過消息隊列通知緩存服務數據已變更,由緩存服務負責更新或刪除相關緩存。
- 延遲雙刪策略:在更新數據庫后,不是立刻刪除緩存,而是延遲幾百毫秒再刪除。這是為了解決數據庫主從同步延遲可能導致的問題。
5. 緩存溢出與內存管理
問題描述: 不合理的緩存配置或無限制的緩存增長可能導致內存溢出或資源浪費。
解決方案:
- 設置合理的緩存大小和過期策略:根據應用需求和資源限制,合理配置緩存的最大容量和各項的過期時間。
- 使用LRU、LFU等淘汰策略:當緩存達到上限時,自動淘汰最不常用或最近最少使用的數據。
結論
緩存是提高系統性能的關鍵技術,但不當的使用和管理也可能引入新的問題。通過了解并應對上述常見的“坑”,開發者可以更加高效地利用緩存,提升系統的穩定性和響應速度。在實際應用中,需要根據具體的業務場景和資源限制來定制合適的緩存策略。
責任編輯:趙寧寧
來源:
后端Q