













譯者 | 陳峻
審校 | 重樓
作為開發人員,我們經常會陷入兩難的局面:我們既希望在應用中使用閃亮的新工具或代碼庫,又忌憚在部署到生產環境之后可能出現的未知問題。畢竟,沒有人希望自己的手機老是在半夜叮咚作響,更不用說來自為了保持應用能夠以多少個9高可用性運行的壓力了。這往往塑造了開發人員在應用構建和編程時具有創新精神,卻在運營場景中過于保守的狀況。

其中,一種最為典型的現象便是—“過度配置(overprovisioning)”,即:在云計算環境中,為應用的部署配備了過多的算力(通常是CPU和RAM),以確保應用擁有足夠的資源,來啟動或應對運行過程中出現的峰值。顯然,既然是過度,我們就需要設法降低此類過度配置的需求,從而節省大量且寶貴的云服務資源的支出。下面,我將和您一起探討在Java應用的環境中如何避免過度的配置。
應用負載從來都不穩定
正如大多數開發和DevOps人員切實感受的那樣,在一天或一周之內,應用的流量負載隨著時間的推移,從來就是不均勻的。在閑時,應用無需為不多的用戶請求提供服務或處理數據,而在大量用戶頻繁對應用產生高利用率時,應用實例會在如下情況下,無法被及時推送給應用,進而出現不穩定的峰值:
- 響應延遲時間過長,無法滿足服務級別協議(SLA)。
- 內存的過度使用,導致Java虛擬機(JVM)中的垃圾回收器(Garbage Collector,GC)出現抖動。
- 缺少CPU線程、網絡或文件句柄等資源,導致傳入的請求被拒絕,更不會被予以處理。
其中,后兩個問題會導致應用出現毫無響應的狀態,因此在測試過程中,開發人員很容易注意到應用的負載上限,以及時擴展所需要的CPU內核和內存數量。而為了避免再次出現峰值,他們通常會趨向于過度添加CPU和內存的數量,以求安全穩定地滿足用戶需求。例如,開發團隊往往會配置比已發現的峰值高出5%到50%的額外云計算余量。
但是,過度的預配置也會增加應用在運行過程中的大量成本。畢竟對于正在運行的云虛擬機而言,固有的CPU(核心或虛擬CPU)和內存,通常并不會自我彈性調整。這就意味著無論應用是否會完全使用到已配置的容量與算力,您都需要為此付費。
為此,我們需要使用合適的策略,來管控過度的預配,以節省不必要的云計算支出。下面,我將向您介紹“垂直擴展(Vertical Scaling)”和“水平擴展(Horizontal Scaling)”這兩種擴展模型,以及每種模型的具體策略。而且此類策略和技術既可以適用于跑在云端的應用,也能夠適合本地運行的環境。
垂直擴展
垂直擴展旨在讓應用通過簡單的策略擴展,以處理更多的負載請求。不過它不如后面講到的水平擴展那么靈活。垂直擴展意味著向物理或虛擬服務器上的應用,添加更多的CPU內核和更多的內存(如果應用屬于I/O密集型,則需要添加更多、更快的SSD存儲)。當然,此類擴展往往需要停止并重啟應用。而有時候這對于應用來說是不可接受的。
水平擴展
多年來,彈性計算(Elastic Compute)一直被奉為可擴展應用開發的“圣杯”。而水平擴展是彈性計算的基礎。水平擴展意味著通過添加更多的服務器(各自具有一套完備的CPU和內存)來增加應用的承載能力,而不是向現有服務器添加更多的CPU內核和內存。
不過,與垂直擴展相比,水平擴展更為復雜,需要更多的規劃和更多的外部(對應用而言)設置。而且,由于必須引入路由層,這就意味著會產生更多的處理和網絡開銷,因此其效率不如垂直擴展。
在針對Java應用的水平擴展部署中,我們可以通過自動檢測負載,和啟停應用節點實例的方式,按需增減資源,進而避免過度的配置。而且,就算在較短的時間內,出現了被過度預置的資源,其數量也會很少(主要取決于您的配置方式)。
更好的負載測試和估計
性能測試通常被認為是一種最困難的測試類型。它需要開發團隊對整個應用及其所有連接的服務,具有深入的了解。他們往往需要通過全面思考和反復調整,才能正確地生成模擬生產環境的負載、以及應用數據。顯然,為了與生產環境的特征保持同步,測試環境的性能設置是一項勞動密集型工作。
就Java應用而言,開發人員經常會在確定應用峰值性能要求時,通過執行三項操作,來實現更加貼近真實情況的配置調整:
1. 測量服務器和JVM的CPU和內存的利用率
通常,開發人員需要查看服務器(或虛擬機)的CPU與內存的利用率,以確定二者為處理峰值負載所需的數字。其中,在JVM中,他們可以使用工具去監控如下兩項指標,以設置正確的級別:
- JVM GC監控:它有助于檢測那些由于內存太少所導致的、在JVM進入GC場景時CPU的使用率過高的情況。同時,它也有助于檢測被分配了過多內存的位置。這些位置因引發GC的暫停時間過長,從而導致延遲時間明顯長于預期。對此,減少不需要的內存可以節省此方面的開銷。
- JVM線程監控:它有助于檢測何時出現由于CPU不足而導致的響應時間過長或無響應的情況。同時,它也有助于檢測那些過多的空閑線程,并能通過減少分配的內核數量,以節省開銷。
2. 新的JVM版本比舊版本提供更好的性能
在從JDK 11到17,再到21的測試中,我們發現每個JVM版本的CPU使用率都有所提升。與之相對的應用代碼則可能需要稍作調整,特別是當您的應用原先基于早于Java 11的版本時。
同時,不同的GC算法也能提升云端VM的效率,雖然這在很大程度上取決于應用的內存利用率。例如,那些執行大數據處理與轉換的應用,會具有與RESTful應用不同的GC配置文件。
3. 了解JVM的工作原理
下圖顯示了一個典型Java應用,從JVM的啟動到它是如何隨時間推移而執行的過程。在啟動時,由于需要啟動JVM、加載各種類,所以其CPU的使用率較高。之后,該應用框架(如,Spring Boot)相繼進入啟動、初始化并達到“準備處理請求”的狀態。
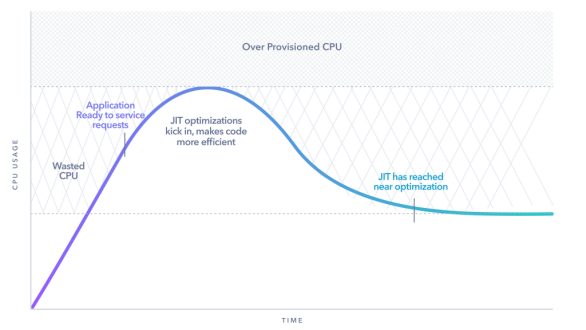
請注意圖中峰值上方一行的區域。該區域顯示了有多少顆CPU被過度預配置給了該應用的VM部署,以應對突發性高負載。隨著JVM的實時(just-in-time,JIT)編譯器優化代碼的生效,該應用的性能會逐漸提高。也就是說,它能夠使用更少的CPU來處理相同數量的負載。最終,在JIT編譯器的優化效果下,JVM達到了較低的CPU利用率基準。那么,為應用保留下來的富余資源,就浪費了您為其分配的CPU。顯然,這些資金本來是有機會可以被節省的。
鑒于使用高性能JVM可以讓您減少(或完全消除)過度配置的可能性,我們有必要通過了解此曲線及其對應用的影響,來減少分配給應用VM實例的資源。也就是說,一旦知曉了長尾峰值的所在位置,我們就可以降低其頂線(即“過度配置”),以便分配更少的CPU內核,并節省云計算的租用成本。
減小應用的體積
我們的應用架構隨著從單體模式轉為微服務(甚至更小的云服務功能),應用的體積規模也變得越來越小。雖然這些不同的架構各有利弊,但在云服務成本優化的背景下,使用水平擴展來達到彈性計算的縮減無疑是最好的實現方式。
應用體積的縮減,也能夠減少需要分配給應用每個實例的CPU和內存的數量。而且,這種增量擴展方式不但實現了更高效的資源使用,也反過來達到了對云計算成本更精細化的控制效果。可以說,部署的單元越小,在縱向擴展時所支付的費用就越少。當然,這里主要討論的是自動化的擴展方式。
使用自動化擴展
說到自動化擴展,它是一種根據應用負載的增加或減少,自動化地增減應用實例節點的能力。通過云服務成本的優化,我們可以根據所構建的應用群集環境的不同,采用不同的自動化擴展選項。目前,最流行的自動化擴展平臺當屬Kubernetes。當然,它也給標準的固定分布式集群(fixed-distributed-cluster)部署帶來了不小的復雜性。
比Kubernetes更為簡單的替代方案是容器即服務(CaaS),例如AWS的Fargate、Google的Cloud Run、以及Microsoft的Azure 容器。這些部署服務提供了一些更加簡單的應用部署方法,并通過將Docker容器中的應用提供給服務,來自動處理向上和向下擴縮容。CaaS解決方案的缺點在于,它們的成本會高于標準的VM,并且可能會比托管式的Kubernetes部署的成本還要高。
結論
總的說來,減少過度配置可以幫助我們節省應用在云服務中的成本開銷。無論您使用上述哪種策略來減少過度配置,了解Java應用的CPU和內存配置文件,無疑將有助于您掌握應用在啟動和運行時的性能狀況。目前,有一種Azul Platform Prime不但可以為大中型Java應用部署提供更為高效的高性能JVM,而且具有如下特點:
- 由于具有先進的C4 GC、底層優化和先進的Falcon JIT編譯器,它比其他JVM能夠更好地處理峰值負載。
- 使用ReadyNow以避免JIT加速(即由JIT帶來的高CPU使用率)。
- 其處理峰值方式不但可以處理更高的峰值負載,而且能夠提供更低的延遲。
如果您對本文討論的話題感興趣的話,請參閱IDC的白皮書--《優化Java應用性能以改善業務成果和云成本效率》,以了解更多信息。
譯者介紹
陳峻(Julian Chen),51CTO社區編輯,具有十多年的IT項目實施經驗,善于對內外部資源與風險實施管控,專注傳播網絡與信息安全知識與經驗。
原文標題:How to Avoid Overprovisioning Java Resources,作者:Pratik Patel















