5 個 Pandas 超級好用的隱藏技巧
作者:云朵君
在本文中,分享五個鮮為人知的 Pandas 技巧。這些技巧初時對我來說非常新穎,需要經過大量研究才能掌握。
對于數據科學來說,Python 中最重要的庫是什么?有些人可能認為是 scikit-learn,它提供了許多內置函數用于機器學習任務。部分人可能會選擇 NumPy 進行數值運算。
但我還是支持 Pandas。為什么?如果你不使用它的功能,你的操作可能會寸步難行。Pandas 非常龐大,需要學習的東西很多。
在本文中,分享五個鮮為人知的 Pandas 技巧。這些技巧初時對我來說非常新穎,需要經過大量研究才能掌握。
1. pipe() 方法鏈
.pipe() 方法鏈可以使代碼更簡潔、更高效。使用.pipe(),可以在一行中應用多個操作。
下面,我們將篩選市場價值高于 1,000,000 歐元的球員數據,并按排序market_value_in_eur,找出世界上最昂貴的球員。
# 這個 transfermarkt 數據集來自 Kaggle(https://www.kaggle.com/datasets/davidcariboo/player-scores)
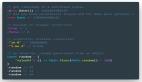
def filter_high_value_players ( df ):
return df[df[ 'market_value_in_eur' ] > 1000000 ]
def sort_by_market_value ( df ):
return df.sort_values( 'market_value_in_eur' , accending= False )
# 使用 .pipe() 進行方法鏈
filtered_sorted_df = df.pipe(filter_high_value_players).pipe(sort_by_market_value)2. query()簡化過濾
該query()方法使得過濾數據幀更加容易。無需使用長條件,query()使代碼更具可讀性。
在這里,我們嘗試尋找身價 5000 萬歐元且身高超過 185 歲的足球運動員。
high_value_players_2022 = df2.query("market_value_in_eur > 50000000 和 height_in_cm == 185")
high_value_players_2022.head(5)3. eval()加速計算
該eval()函數可以為算術運算提速,特別是對于列式計算非常有用。
# 使用 eval() 計算百萬市值
df[ 'market_value_in_millions' ] = df.eval ( 'market_value_in_eur / 1_000_000' )
# 刪除 na df.dropna (
subset=[ 'market_value_in_millions' ], inplace= True )
# 從最高到最低升序
df.sort_values( "market_value_in_millions" , accending = False )[[ "name" , "market_value_in_millions" ]]4. astype()優化數據類型
將列轉換為Categorical數據類型可以節省內存并加快操作,并且如果在為機器學習算法處理數據時,這是該方法將是你最佳選擇。
# 將 'player_club_domestic_competition_id' 轉換為分類
df [ 'player_club_domestic_competition_id' ] = df [ 'player_club_domestic_competition_id' ].astype( 'category' )5. assign()臨時添加列
對于于臨時更改數據列,可以使用assign()方法添加新列而不修改原始數據。
在這里可以看到球員的價值是否高于平均水平。
# 使用assign()添加一列,表示市場價值是否高于平均水平
df_with_new_col = df.assign(above_average = df[ 'market_value_in_millions' ] > df[ 'market_value_in_millions' ].mean())
df_with_new_col.head() 圖片
圖片
責任編輯:武曉燕
來源:
數據STUDIO