簡(jiǎn)單易懂的LLM三角原則,讓你輕松開發(fā)大模型應(yīng)用
先前我們聊到了《從零開始構(gòu)建大模型(LLM)應(yīng)用》,不少朋友偷偷問我:“什么是LLM的三角原則?”今天就給大家仔細(xì)講講構(gòu)建LLM應(yīng)用的三角原則。這套原則其實(shí)不復(fù)雜,由“3+1”(一范式三原則)個(gè)基礎(chǔ)組成,適合任何團(tuán)隊(duì)來實(shí)踐。
說到以LLM為核心的應(yīng)用,有不少人以為是高大上的模型占主導(dǎo),但其實(shí)情況是這樣的:10%是那些復(fù)雜的模型,而有足足90%是實(shí)驗(yàn)性的、以數(shù)據(jù)為驅(qū)動(dòng)的工程作業(yè)。
當(dāng)我們把LLM應(yīng)用到實(shí)際產(chǎn)品中時(shí),需要的不僅是代碼功底,更多的是工程上的精磨細(xì)打。如果用戶不能直接和LLM打交道,那我們就必須搭建完善的構(gòu)造prompt ,確保涵蓋所有必要的細(xì)節(jié),否則用戶的反饋可能就沒法收集完整,將會(huì)影響到后續(xù)的迭代升級(jí)!
1、LLM三角原則概念
提到LLM三角原則,你可能會(huì)覺得這是個(gè)很復(fù)雜的概念,但實(shí)際上,它就是我們構(gòu)建高效LLM本地應(yīng)用的一套基本指南。這套原則為開發(fā)者們提供了清晰的框架和方向,一步一步地打造出既健壯又可靠的LLM應(yīng)用。有了這個(gè)原則作為指南,開發(fā)的過程將會(huì)變得更有條不紊,有效率。
1.1關(guān)鍵點(diǎn)
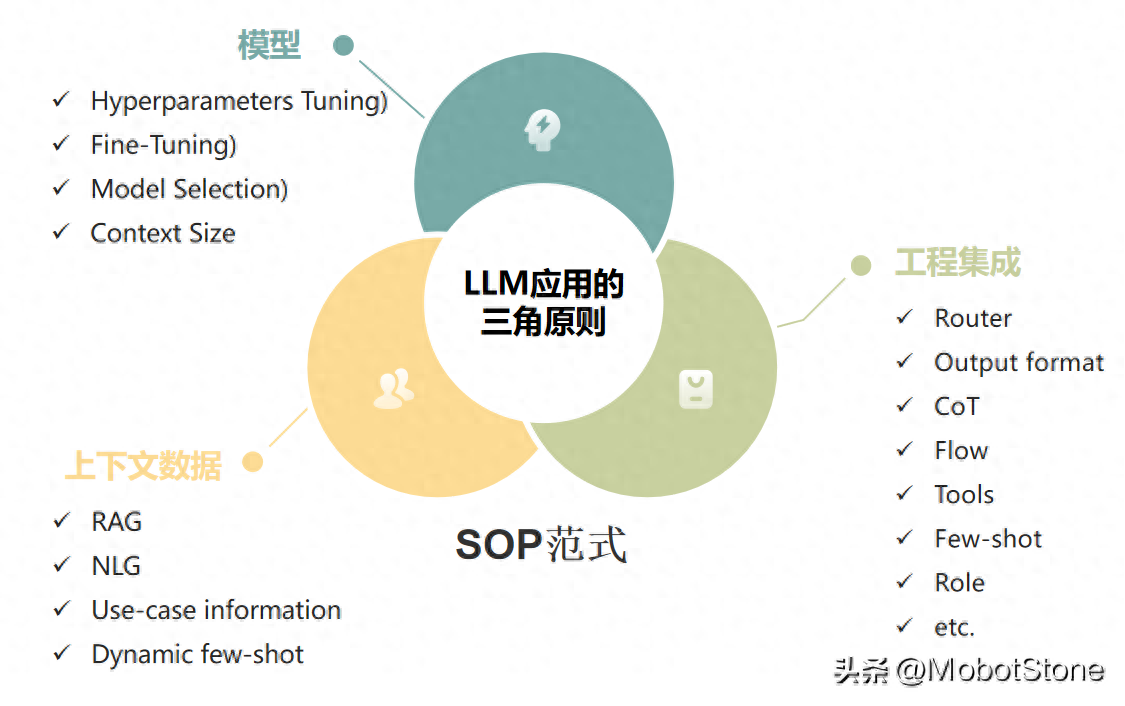
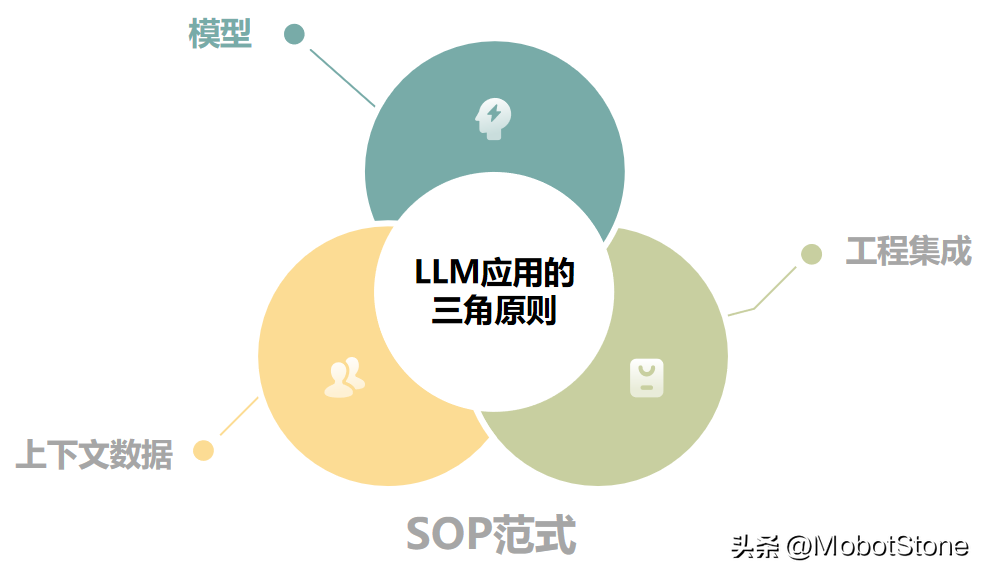
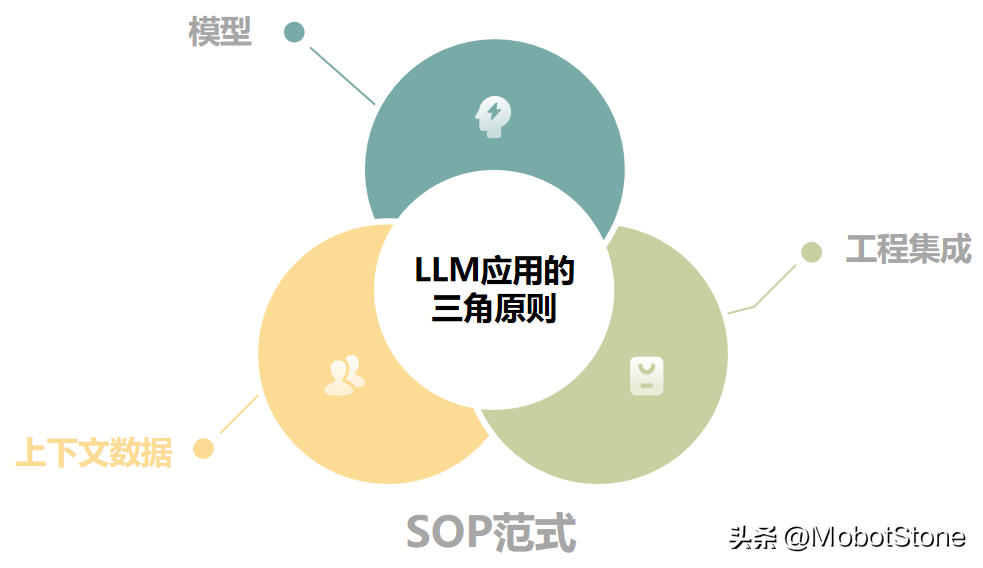
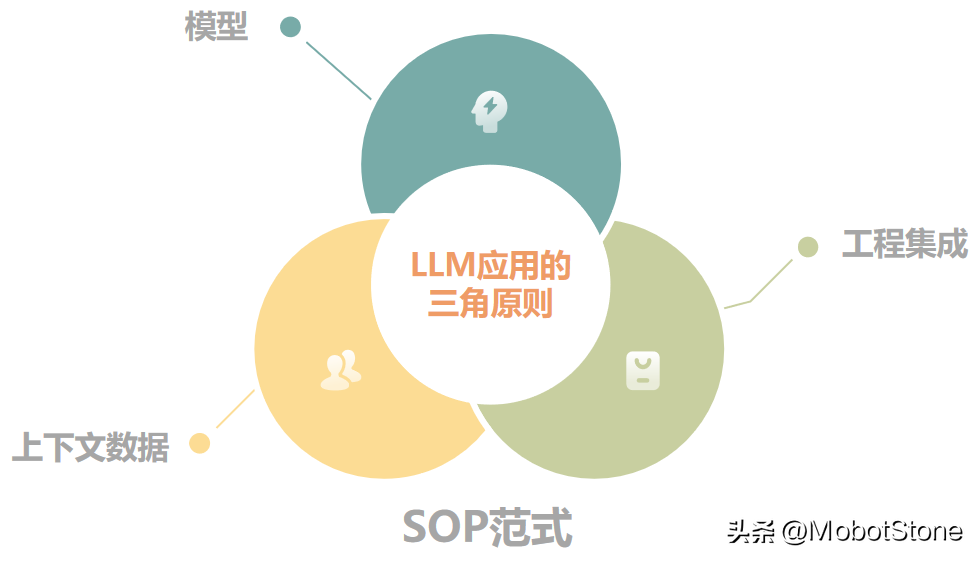
在我們打造LLM本地應(yīng)用的過程中,LLM三角原則介紹了一個(gè)范式三大實(shí)用原則。
我們來看看范式:標(biāo)準(zhǔn)操作程序(SOP)。這個(gè)原則幫助我們把握好三個(gè)重要原則:模型、工程集成和上下文數(shù)據(jù)。
簡(jiǎn)單地說,把這三部分通過SOP進(jìn)行精細(xì)調(diào)整,就是打造一個(gè)高效強(qiáng)大LLM本地應(yīng)用的秘訣。這就像是確保我們的應(yīng)用在正確的軌道上高速前進(jìn),既穩(wěn)定又快速。
2. 標(biāo)準(zhǔn)操作程序(SOP)
**標(biāo)準(zhǔn)操作程序(SOP)**是一個(gè)常見的概念。其實(shí)就是一本操作手冊(cè),里面詳細(xì)記錄了每一步怎么做,確保每個(gè)員工做同一個(gè)工作時(shí),效果都差不多,質(zhì)量都很高。就像是給沒有經(jīng)驗(yàn)的員工一個(gè)詳細(xì)的指導(dǎo)書,讓他們也能像正常工作。
在我們構(gòu)建LLM應(yīng)用時(shí),我們也用了這個(gè)原則。把模型想象成一個(gè)剛?cè)胄械男率郑ㄟ^SOP這樣的標(biāo)準(zhǔn)操作指南來“教”它怎么像專家那樣完成任務(wù)。這樣一來,我們的應(yīng)用不僅運(yùn)行得更流暢,出來的成果也能保證是高質(zhì)量的。

“沒有SOP,再厲害的LLM也難以保持一貫的高質(zhì)量。”
在弄清楚SOP指導(dǎo)范式的時(shí)候,我們需要思考哪些技術(shù)工具可以幫助我們最有效地實(shí)行三大原則。
2.1 認(rèn)知建模
要制定SOP,我們得先觀察那些干得最好的員工——也就是我們的業(yè)務(wù)專家。我們需要模仿他們的思考和工作方式,確保能夠達(dá)到他們同樣的成果,并且要把他們的每一步操作都記錄下來。
當(dāng)我們編輯和正式化這些記錄后,就會(huì)形成一套詳盡的操作指南。這套指南能幫助經(jīng)驗(yàn)不夠或技術(shù)不足的員工也能夠順利完成工作。
我們自己在工作時(shí),如果任務(wù)太復(fù)雜,就會(huì)感到頭腦負(fù)擔(dān)重。所以我們通常會(huì)把復(fù)雜的任務(wù)簡(jiǎn)化或者分解成小步驟,可以幫助我們更輕松地完成任務(wù)。遵循這樣簡(jiǎn)單明了的分步指導(dǎo),比起那些長(zhǎng)長(zhǎng)的、復(fù)雜的操作流程要容易得多。
在這個(gè)過程中,我們還會(huì)注意到一些專家在不經(jīng)意間采取的小小習(xí)慣,這些習(xí)慣可能看起來微不足道,但實(shí)際上對(duì)最終結(jié)果有很大的影響。
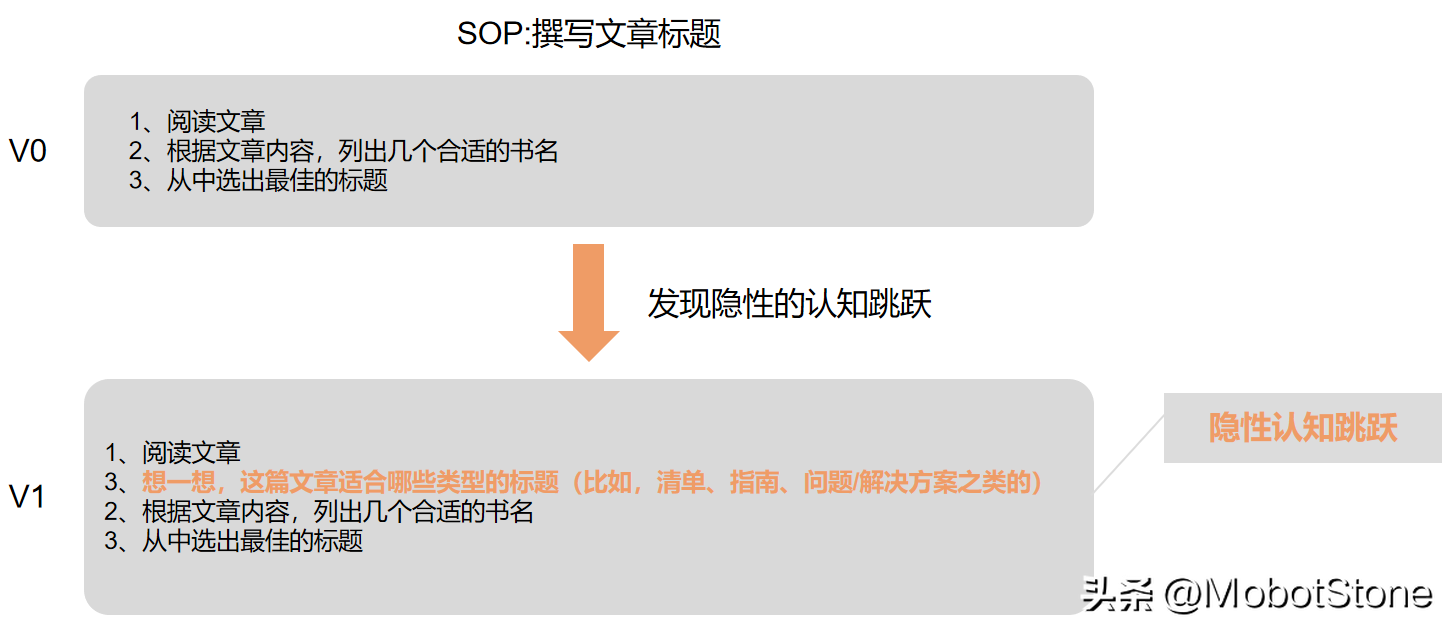
比如說,我們想要模擬一個(gè)數(shù)據(jù)分析(通常是使用SQL或者表格)的工作方式。我們可以先從訪談開始,問他們一些具體的問題,了解他們的日常工作流程:
- 當(dāng)需要你分析一個(gè)業(yè)務(wù)問題時(shí),你通常會(huì)怎么做?
- 你是如何確保你的解決方案完全符合需求的?
- 接下來,我們會(huì)把我們理解的過程反饋給受訪者看看,比如說:“所以你是這樣分析的嗎?”
- 然后詢問:“這個(gè)流程可以覆蓋你的工作過程嗎?”這樣可以讓他們糾正我們可能理解錯(cuò)誤的地方。
- 諸如此類的問題。

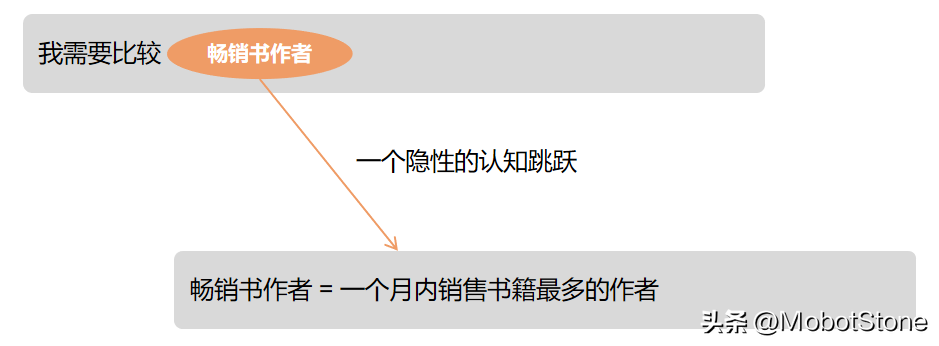
隱性認(rèn)知過程有很多種,它們的形式和表現(xiàn)各不相同。比如說,“業(yè)務(wù)特定定義”就是一個(gè)典型例子。拿“暢銷書”這個(gè)詞來說,對(duì)于我們的業(yè)務(wù)專家來講,這是一個(gè)非常重要的術(shù)語,他們對(duì)這個(gè)詞有著明確的理解和定義。但如果你問一般人,他們可能就不那么清楚這個(gè)詞具體是什么意思了。
到最后,我們就能擁有一套完整的SOP流程,這讓我們可以模仿我們最優(yōu)秀分析師的工作方法。當(dāng)我們?cè)噲D繪制這些復(fù)雜的流程時(shí),將它們用圖表形式展示出來會(huì)非常有幫助。特別是當(dāng)這些流程包括許多小步驟、條件選擇和不同分支時(shí),圖表的方式可以讓我們更清晰地看到每一個(gè)環(huán)節(jié),理解和執(zhí)行起來也會(huì)更加直觀。這樣的方法能幫助我們更好地掌握流程,確保像那些優(yōu)秀的分析師一樣執(zhí)行每一步操作。
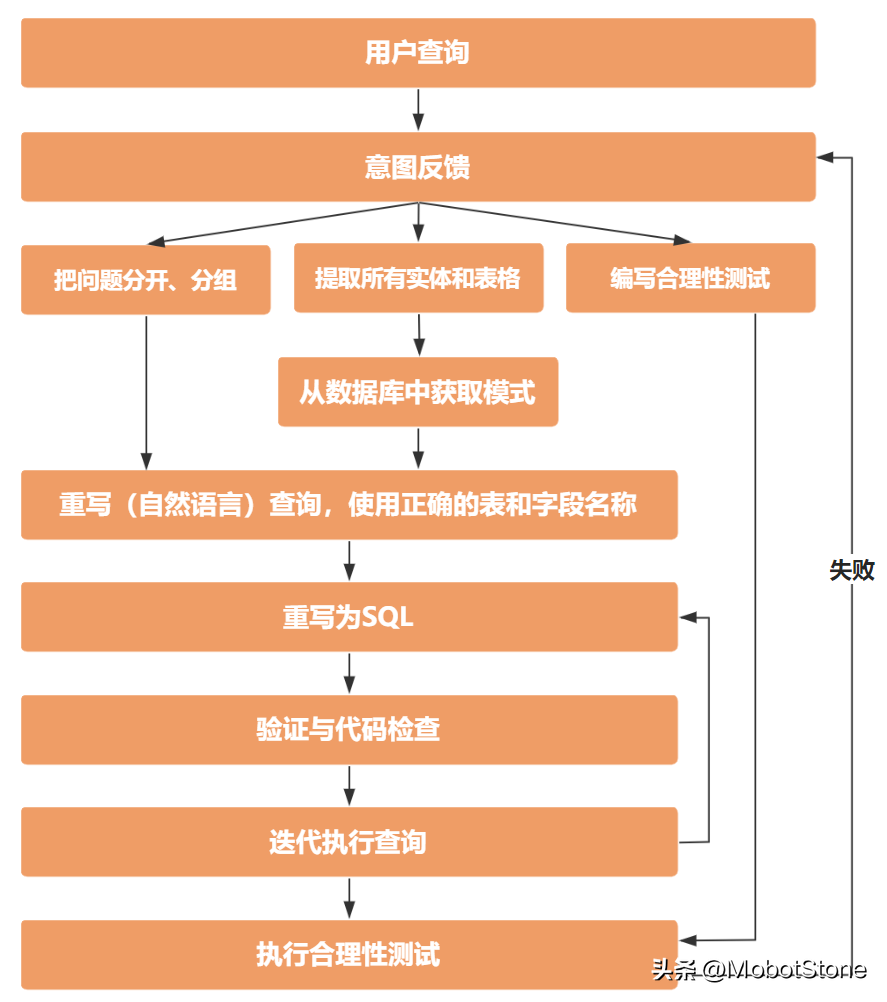
我們的最終解決方案應(yīng)該嚴(yán)格按照SOP中定義的步驟來模仿執(zhí)行。在設(shè)計(jì)初期,不必過多關(guān)注實(shí)現(xiàn)的具體細(xì)節(jié)——這部分我們可以在后續(xù)階段,針對(duì)解決方案的具體步驟或環(huán)節(jié)中逐步實(shí)施。
與其他原則不同,認(rèn)知建模(即編寫SOP)是一個(gè)獨(dú)立的過程。我強(qiáng)烈推薦,在動(dòng)手編寫代碼之前,先對(duì)整個(gè)流程進(jìn)行模擬。當(dāng)然,在實(shí)際實(shí)施過程中,隨著對(duì)問題的理解不斷深入,你可能需要根據(jù)新的認(rèn)識(shí)對(duì)模型進(jìn)行調(diào)整。
既然我們已經(jīng)了解到創(chuàng)建一個(gè)SOP的重要性,這個(gè)SOP將指導(dǎo)我們更好地理解產(chǎn)品的問題及定位,并探討如何有效利用各種工程技術(shù)來實(shí)施這一過程。這種方法確保我們的方案既符合需求又具有執(zhí)行效率。
3. 工程集成
工程集成是實(shí)施SOP并最大化模型效用的關(guān)鍵。在考慮工程集成原則時(shí),我們需要思考:使用的“工具”里有哪些技術(shù)可以幫助我們執(zhí)行和完善SOP?這些技術(shù)又如何確保模型能有效執(zhí)行并滿足我們的需求?

在我們的工程技術(shù)中,有些技術(shù)僅在提示層面實(shí)施,而更多技術(shù)則需要在軟件層面才能有效運(yùn)作,還有一些技術(shù)是結(jié)合了這兩個(gè)層面。
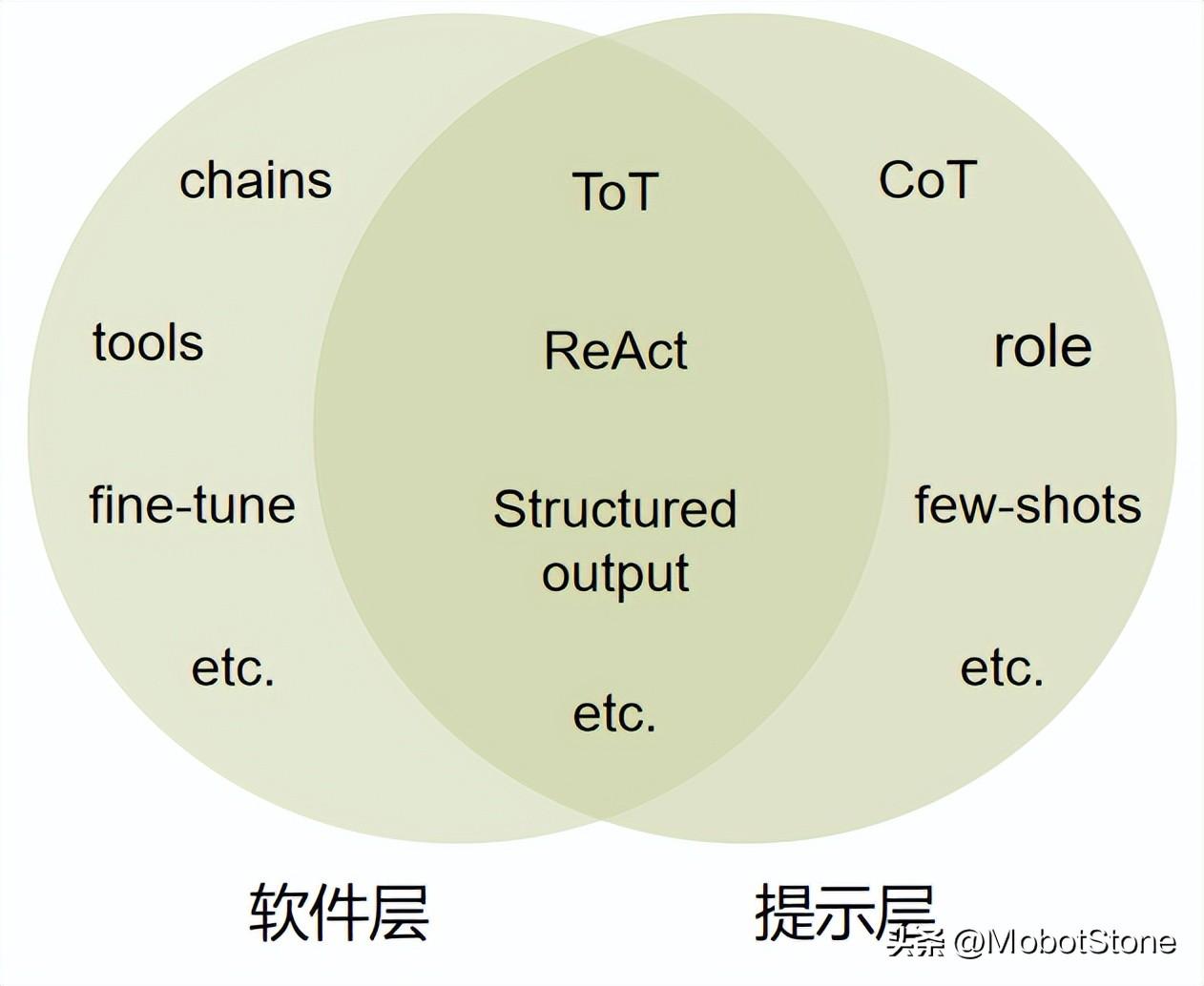
雖然每天我們都能遇到很多小調(diào)整,但在這里主要介紹兩種重要的技術(shù):工作流/鏈路和Agents。這兩種技術(shù)對(duì)于我們的系統(tǒng)來說至關(guān)重要,它們幫助我們更高效地管理和執(zhí)行復(fù)雜的任務(wù)。
3.1. LLM應(yīng)用架構(gòu)設(shè)計(jì)(工作流或鏈路)
LLM應(yīng)用架構(gòu)設(shè)計(jì)其實(shí)是在描述我們的LLM應(yīng)用要完成任務(wù)的各個(gè)流程。
在我們的設(shè)計(jì)中,每一個(gè)步驟都是不可或缺的,各自獨(dú)立地完成特定任務(wù)。有些步驟可能只需要靠一些固定的代碼來執(zhí)行;而對(duì)于其他步驟,我們可能會(huì)用到LLM(Agents)。
為了更好地構(gòu)建這個(gè)架構(gòu),我們需要重新審視之前制定的標(biāo)準(zhǔn)操作程序(SOP),并思考以下幾個(gè)問題:
- 哪些SOP步驟應(yīng)該合并到同一個(gè)流程中?哪些步驟需要分開處理?
- 哪些步驟應(yīng)該獨(dú)立執(zhí)行(雖然它們可能依賴前一個(gè)步驟的信息)?
- 哪些步驟可以通過固定步驟來實(shí)現(xiàn)?
- 等等。
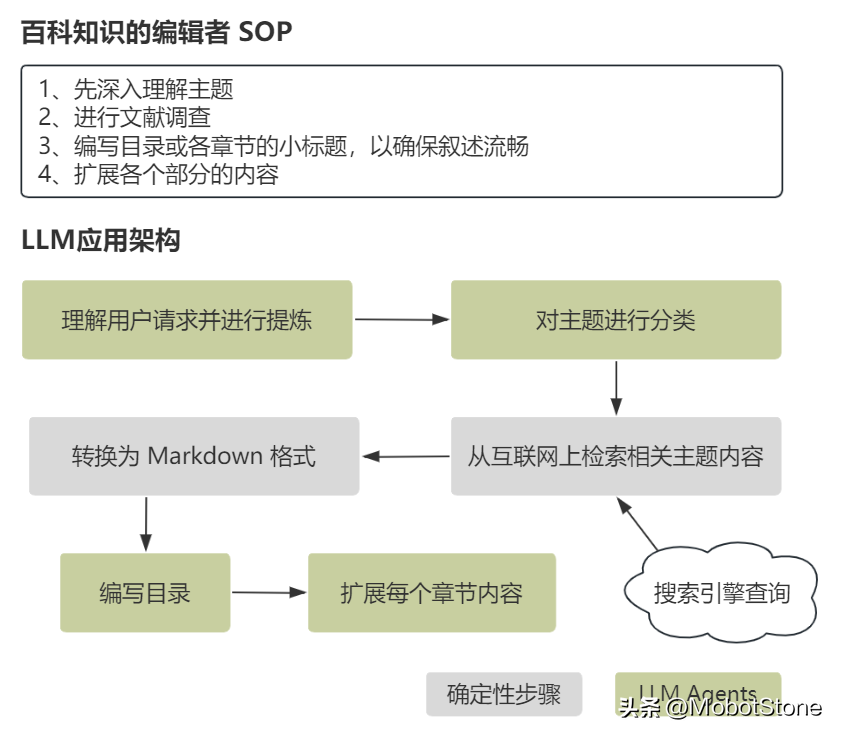
在我們繼續(xù)深入架構(gòu)或流程圖的具體步驟之前,我們應(yīng)該明確一些關(guān)鍵屬性:
- 輸入和輸出:每一步需要什么輸入?我們?cè)谛袆?dòng)前需要準(zhǔn)備什么?(這同樣適用于Agents的輸出格式)。
- 質(zhì)量保證 —— 什么樣的響應(yīng)才算是“足夠好”?有沒有需要人工介入的情況?我們可以設(shè)置哪些檢查來確保質(zhì)量?
- 自主級(jí)別 —— 我們希望對(duì)結(jié)果的質(zhì)量控制到什么程度?這個(gè)階段能處理哪些問題的范圍?換句話說,我們對(duì)模型在這個(gè)階段獨(dú)立工作的能力有多大的信任?
- 觸發(fā)器 —— 下一步我們要做什么?什么決定了下一步的行動(dòng)?
- 非功能性要求 —— 我們需要的響應(yīng)時(shí)間是多少?是否需要特別的業(yè)務(wù)監(jiān)控?
- 故障轉(zhuǎn)移控制 —— 可能會(huì)出現(xiàn)哪些類型的故障(包括系統(tǒng)性和代理性)?我們準(zhǔn)備了哪些應(yīng)對(duì)措施?
- 狀態(tài)管理 —— 我們需要特殊的狀態(tài)管理機(jī)制嗎?我們?nèi)绾螜z索或保存狀態(tài)(確定索引鍵)?是否需要持久化存儲(chǔ)?這種狀態(tài)有哪些不同的應(yīng)用(例如,用于緩存、記錄日志等)?
3.2. 代理(Agents)是什么?
在LLM本地架構(gòu)中,LLM Agents是一個(gè)獨(dú)立的組件,它的工作就是調(diào)用一個(gè)LLM。
每個(gè)Agents都是LLM的一個(gè)實(shí)例,其中的prompt 包含了相應(yīng)的上下文。但是,并不是所有的Agents都一樣——有些Agents會(huì)使用“工具”,而有些則不會(huì);有些可能在流程中只被使用一次,而其他的可以被遞歸調(diào)用或多次調(diào)用,它們會(huì)攜帶前一個(gè)輸入和輸出。這種設(shè)計(jì)讓每個(gè)Agents都能根據(jù)需要靈活地執(zhí)行任務(wù),從而有效地支持整個(gè)LLM應(yīng)用的運(yùn)行。
3.2.1. Agents 與工具集
一些LLM Agents可以利用“工具”——這些工具是預(yù)先定義好的功能,可以用來執(zhí)行數(shù)學(xué)計(jì)算或網(wǎng)絡(luò)搜索等操作。當(dāng)Agents需要使用某個(gè)工具時(shí),它會(huì)明確指出所需的工具及其輸入?yún)?shù),隨后應(yīng)用程序依照這些指令執(zhí)行任務(wù),并將結(jié)果反饋給Agents。
為了幫助大家更好地理解這個(gè)概念,我通過一個(gè)簡(jiǎn)單的例子來看看如何實(shí)現(xiàn)工具調(diào)用。這個(gè)示例可以在沒有專門訓(xùn)練用于調(diào)用工具的模型中工作:
你扮演的是一個(gè)助手,可以使用以下工具:
- calculate(expression: str) -> str - 用于計(jì)算數(shù)學(xué)表達(dá)式
- search(query: str) -> str - 用于在庫(kù)存中搜索項(xiàng)目
接到一個(gè)輸入后,你需要以YAML格式回應(yīng),其中包括以下鍵:`func`(字符串類型) 和 `arguments`(映射類型) 或 `message`(字符串類型)。
給定輸入我們需要區(qū)分兩種代理:一種是帶有工具的代理(即自主Agent),另一種是其輸出可以直接導(dǎo)致執(zhí)行動(dòng)作的代理。
“自主Agent是具備獨(dú)立完成任務(wù)方法的代理。”
自主Agent擁有決定是否采取行動(dòng)及其具體行動(dòng)的權(quán)力。相比之下,非自主代理只是簡(jiǎn)單地“處理”我們的請(qǐng)求(例如,進(jìn)行分類),處理完成后,由我們的確定性代碼來執(zhí)行具體動(dòng)作,模型本身對(duì)這一過程沒有控制權(quán)。
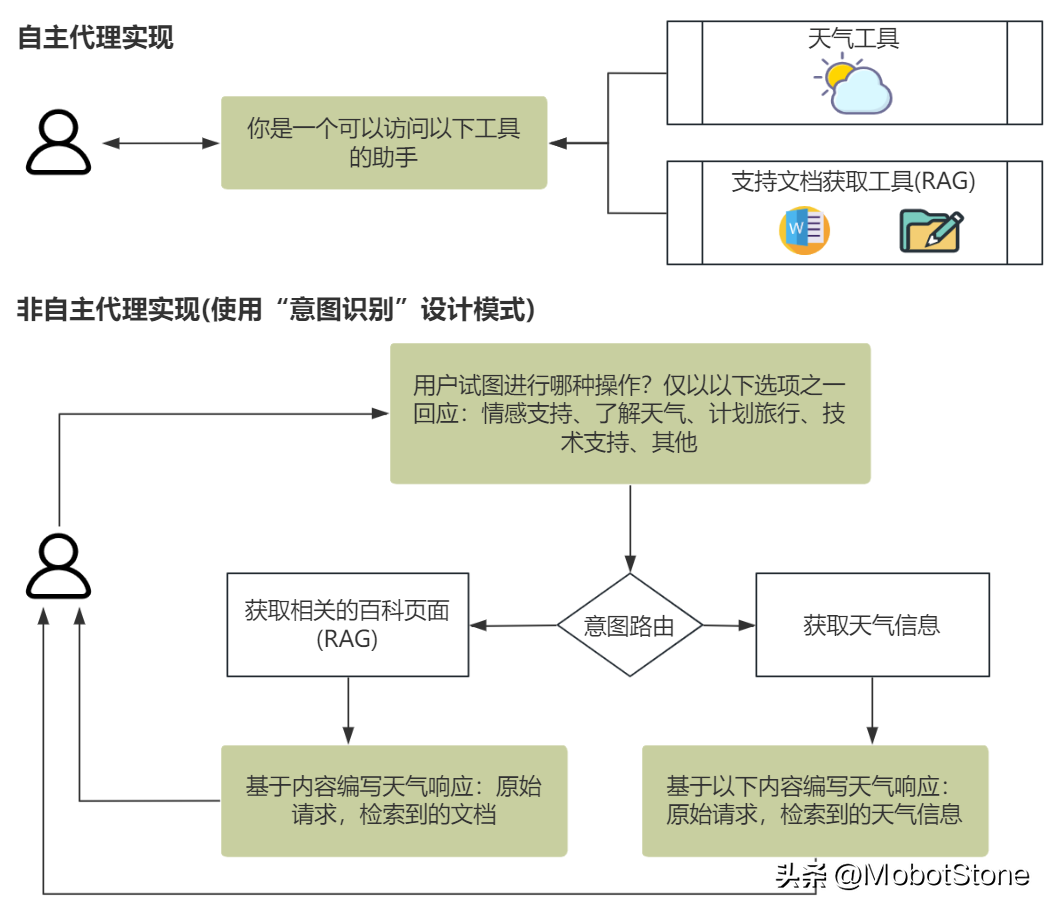
隨著我們?cè)黾覣gent在規(guī)劃和執(zhí)行任務(wù)中的自主性,我們確實(shí)增強(qiáng)了決策能力。這看似一個(gè)非常好的解決方案,可以讓Agent顯得更“智能”。但是,這樣做的一個(gè)潛在風(fēng)險(xiǎn)是可能會(huì)降低我們對(duì)最終輸出質(zhì)量的控制。
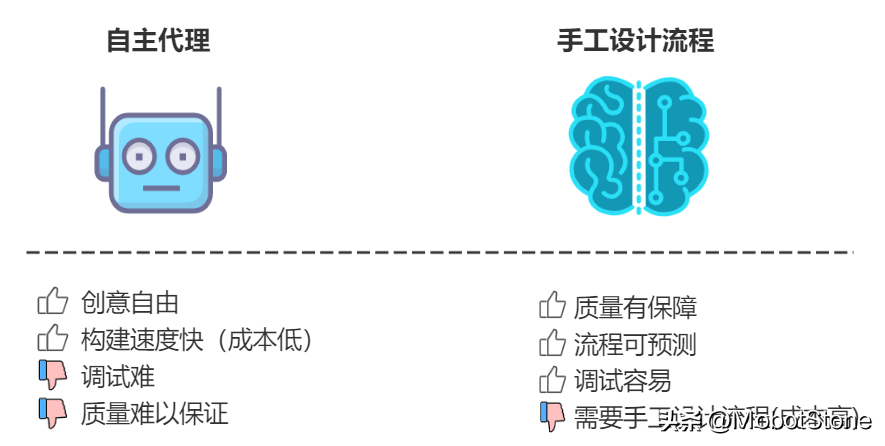
不要過分依賴全自主代理。雖然這類Agent的設(shè)計(jì)看起來簡(jiǎn)單且很有吸引力,但如果在所有情況下或作為初步概念驗(yàn)證使用,可能會(huì)在實(shí)際應(yīng)用中產(chǎn)生誤導(dǎo)。自主Agent難以調(diào)試且其響應(yīng)質(zhì)量不穩(wěn)定,因此通常不適合在生產(chǎn)環(huán)境中使用。
以經(jīng)驗(yàn)來看,在沒有詳細(xì)指導(dǎo)的情況下,Agent在規(guī)劃復(fù)雜過程時(shí)往往表現(xiàn)不佳,可能會(huì)忽略一些關(guān)鍵步驟。例如,在我們的“百科編輯者”示例中,Agent可能會(huì)直接開始寫作,而忽視了必要的準(zhǔn)備工作。這說明Agent的性能很大程度上依賴于它們訓(xùn)練的數(shù)據(jù)——簡(jiǎn)單來說,Agent只能做得和它們訓(xùn)練的數(shù)據(jù)一樣好。
與其讓一個(gè)或一組Agent自由地完成所有環(huán)節(jié)的任務(wù),不如在流程或標(biāo)準(zhǔn)操作程序(SOP)中的特定區(qū)域限定它們的任務(wù),特別是那些需要?jiǎng)?chuàng)造力和靈活性的環(huán)節(jié)。這種做法可以提高成果的質(zhì)量,因?yàn)樗壤昧肆鞒痰囊?guī)范性,又保留了創(chuàng)新的空間。
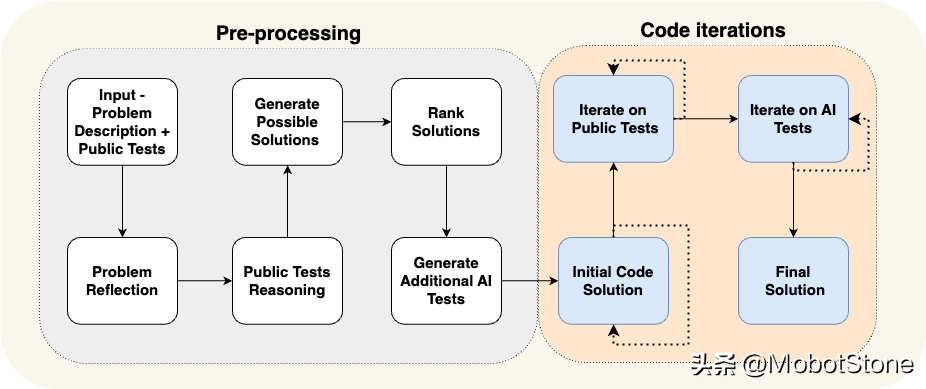
以AlphaCodium(一個(gè)代碼生成任務(wù)增強(qiáng)流程很火的開源項(xiàng)目)為例:通過將固定的流程與不同功能的Agent相結(jié)合(包括一個(gè)專門負(fù)責(zé)重復(fù)編寫和測(cè)試代碼的新型代理),他們成功地將GPT-4在CodeContests上的準(zhǔn)確率(pass@5)從19%提高到了44%。這個(gè)例子很好地說明結(jié)合流程控制和Agent創(chuàng)造力的重要性,以及這種結(jié)合如何有效提升任務(wù)執(zhí)行的效果。
在我們利用工程集成來實(shí)施標(biāo)準(zhǔn)操作程序(SOP)和優(yōu)化LLM本地應(yīng)用的同時(shí),我們也不能忽視LLM三角原則中的另一個(gè)核心要素:模型本身。
4. 模型
我們選用的模型是項(xiàng)目成功的關(guān)鍵因素。例如,像GPT-4或Claude Opus這樣的大模型雖然能夠提供更優(yōu)質(zhì)的結(jié)果,但在大規(guī)模應(yīng)用時(shí)成本也相當(dāng)高。相比之下,較小的模型雖然可能不那么“強(qiáng)大”,但有助于我們控制預(yù)算,而且在某些特定領(lǐng)域能達(dá)到我們想要的效果。因此,在考慮選擇模型時(shí),我們必須清楚自己的約束條件和目標(biāo),才能確定哪種類型的模型最適合幫助我們達(dá)成這些目標(biāo)。
并非所有的LLM都是相同的。要使模型與任務(wù)相匹配。
事實(shí)是,我們并不總是需要最大的模型;這取決于具體任務(wù)。為了找到合適的匹配,我們必須進(jìn)行實(shí)驗(yàn)過程,并嘗試我們解決方案的多種變體。
考慮到我們的“無經(jīng)驗(yàn)工人”類比——一個(gè)擁有眾多學(xué)術(shù)資質(zhì)的非常“聰明”的工人可能會(huì)輕松完成一些任務(wù),但他們可能對(duì)某些工作來說過于高資,雇用一個(gè)“更便宜”的候選人會(huì)更加具有成本效益。
在選擇模型時(shí),我們需要根據(jù)可以接受的各種權(quán)衡來定義和評(píng)估不同的解決方案:
- 任務(wù)復(fù)雜度 — 對(duì)于簡(jiǎn)單的任務(wù),如生成摘要,一個(gè)小型模型就足夠了,但處理更復(fù)雜的推理任務(wù)通常需要較大的模型。
- 推理基礎(chǔ)設(shè)施 — 我們選擇在云端還是在端側(cè)上運(yùn)行模型?模型的大小可能會(huì)限制設(shè)備配置的性能,但在云服務(wù)中這通常不是問題。
- 定價(jià) — 我們能接受的最高價(jià)格是多少?結(jié)合業(yè)務(wù)影響和預(yù)期的使用頻率,這個(gè)投入是否劃算?
- 延遲 — 模型越大,其處理速度可能越慢。
- 標(biāo)注數(shù)據(jù) — 我們是否擁有足夠的標(biāo)注數(shù)據(jù)來豐富模型,尤其是那些模型未曾學(xué)習(xí)過的信息?
在許多情況下,在我們積累足夠的“專業(yè)知識(shí)”之前,為了獲得經(jīng)驗(yàn)豐富的效果而支付額外成本是非常需要的——這對(duì)于LLMs也是適用的。這可以在初期階段幫助我們實(shí)現(xiàn)更好的性能和效果。
如果手頭沒有標(biāo)注數(shù)據(jù),一個(gè)好的策略是先使用一個(gè)更強(qiáng)大(也就是更大)的模型開始工作,通過這個(gè)模型來收集數(shù)據(jù),但這個(gè)需要注意合規(guī)風(fēng)險(xiǎn)。然后,利用收集到的這些數(shù)據(jù),我們可以通過少樣本學(xué)習(xí)或者對(duì)模型進(jìn)行微調(diào),從而進(jìn)一步提升模型的性能。
4.1. 模型微調(diào)
在對(duì)模型進(jìn)行微調(diào)之前,您必須考慮以下幾個(gè)方面:
- 隱私:如果您的數(shù)據(jù)中包含敏感或個(gè)人信息,必須對(duì)這些信息進(jìn)行匿名化處理,以避免可能的法律責(zé)任。
- 法律、合規(guī)性和數(shù)據(jù)權(quán)利:訓(xùn)練模型時(shí)可能涉及法律問題。例如,OpenAI的使用條款禁止未經(jīng)許可使用其生成的內(nèi)容來訓(xùn)練模型。另外,根據(jù)歐盟的GDPR法規(guī),用戶有權(quán)要求企業(yè)刪除其個(gè)人數(shù)據(jù),這可能會(huì)引起關(guān)于模型是否需要重新訓(xùn)練的法律問題。
- 更新延遲:與直接在上下文中嵌入新信息相比,重新訓(xùn)練模型通常需要更多時(shí)間,因此更新的頻率可能較低。
- 開發(fā)和操作:建立一個(gè)可重復(fù)、可擴(kuò)展并可監(jiān)控的微調(diào)流程是至關(guān)重要的,同時(shí)需要持續(xù)評(píng)估性能。這一過程復(fù)雜且需要持續(xù)的維護(hù)。
- 成本:由于訓(xùn)練過程的復(fù)雜性以及高密集的資源需求(如GPU),重新訓(xùn)練模型通常代價(jià)高昂。
LLMs作為“上下文學(xué)習(xí)者”的功能,以及新模型支持更寬廣上下文窗口的能力,已經(jīng)大大簡(jiǎn)化了我們的應(yīng)用實(shí)現(xiàn)。這意味著即使不進(jìn)行模型微調(diào),我們也能獲得很好的效果。因此,考慮到微調(diào)的復(fù)雜性,我們建議只在必要時(shí)才采用,或者盡可能避免使用微調(diào)。
另一方面,對(duì)于特定任務(wù)(例如生成結(jié)構(gòu)化的JSON輸出)或特定領(lǐng)域的應(yīng)用進(jìn)行微調(diào),可能會(huì)更有效。一個(gè)專為特定任務(wù)設(shè)計(jì)的小模型在處理這些任務(wù)時(shí)既高效又成本低,比大型LLMs要經(jīng)濟(jì)得多。因此,在決定是否升級(jí)到更大規(guī)模的LLM訓(xùn)練之前,評(píng)估所有相關(guān)因素是非常必要的。
請(qǐng)注意,即使是最先進(jìn)的模型,也需要依賴相關(guān)而且結(jié)構(gòu)合理的上下文數(shù)據(jù),才能充分發(fā)揮其潛力。
5. 上下文數(shù)據(jù)
LLMs 是上下文學(xué)習(xí)的高手。只要我們提供相關(guān)任務(wù)的具體信息,LLM Agent就能夠在不經(jīng)過特殊訓(xùn)練或微調(diào)的情況下幫助我們完成這些任務(wù)。這讓我們可以很輕松地向它們“傳授”新的知識(shí)或技能。
當(dāng)涉及到上下文數(shù)據(jù)的處理時(shí),我們應(yīng)該要向如何組織和建模手頭上的數(shù)據(jù),并考慮如何在我們的prompt 中有效地整合這些數(shù)據(jù)。這樣一來,LLM就能更好地理解和執(zhí)行任務(wù),從而提高效率和效果。
要構(gòu)建有效的上下文,我們需要在發(fā)送給LLM的提示(prompt)中包含相關(guān)的信息。通常,我們可以采用兩種類型的上下文:
- 嵌入上下文:這種上下文直接嵌入到prompt的文本中,作為信息的一部分提供。
你是<name>的得力助手,<name>在<company>擔(dān)任<role>。- 附件上下文:這種上下文通過在prompt的開頭或結(jié)尾附加信息片段來提供。
在保持友好語氣的同時(shí)總結(jié)所提供的電子郵件。
---
<email_0>
<email_1>我們通常使用“prompt模板”來實(shí)現(xiàn)這些上下文,比如使用jinja2、mustache或簡(jiǎn)單的原生格式化字符串。通過這種方式,我們可以優(yōu)雅地構(gòu)建提示內(nèi)容,同時(shí)保持其核心本質(zhì)清晰:
# 帶有附件上下文的嵌入上下文
prompt = f"""
你是{name}的得力助手,{name}在{company}擔(dān)任{role}。
幫助我用{tone}語氣回復(fù)附加的電子郵件。
始終以以下簽名結(jié)尾:
{signature}
---
{email}
"""5.1. 少樣本學(xué)習(xí)
少樣本學(xué)習(xí)是一個(gè)不需要大量調(diào)整模型就能教會(huì)LLMs新技能的方法。我們只需在prompt中加入一些準(zhǔn)備好的示例,模型就能學(xué)會(huì)我們需要的格式、風(fēng)格或怎樣完成任務(wù)。
比如,如果我們想讓LLM幫忙回復(fù)電子郵件,我們可以在prompt中加入幾個(gè)認(rèn)為寫的好的回復(fù)示例。這樣,模型就能學(xué)到我們希望的回復(fù)結(jié)構(gòu)和語氣。
通過提供多種不同的示例,模型可以更好地理解各種復(fù)雜的情況和細(xì)微的差異。因此,確保你的示例全面,能覆蓋所有可能的情況是非常重要的。
隨著應(yīng)用程序的進(jìn)步,你可以采取“動(dòng)態(tài)少樣本學(xué)習(xí)”的策略,根據(jù)每個(gè)特定的輸入選擇最相關(guān)的示例。這種方式雖然更復(fù)雜,但能讓模型針對(duì)不同的情況得到最好的指導(dǎo),從而在處理多種任務(wù)時(shí)提高性能,同時(shí)避免了成本高的大規(guī)模調(diào)整。
5.2. RAG
檢索增強(qiáng)生成(Retrieval Augmented Generation,簡(jiǎn)稱RAG)是一種特別的技術(shù),它會(huì)在LLM生成回答之前先查找相關(guān)的文檔,以此來提供更多的上下文信息。可以想象成,在LLM回答問題之前,它會(huì)先快速查閱相關(guān)的資料,這樣做可以幫助它給出更準(zhǔn)確和更新的信息。
例如,在聊天機(jī)器人的應(yīng)用中,RAG能夠自動(dòng)查找并提取相關(guān)的幫助臺(tái)維基頁(yè)面,這些信息將直接用來支持LLM的回答。
這種方法讓LLM能夠依據(jù)最新獲取的信息來生成回答,這不僅確保了信息的及時(shí)更新,還減少了生成不準(zhǔn)確或虛假信息的風(fēng)險(xiǎn)。對(duì)于那些需要最新數(shù)據(jù)或?qū)iT知識(shí)的任務(wù),使用RAG特別有效,而且這樣做不需要重新訓(xùn)練整個(gè)模型,既節(jié)約了時(shí)間也節(jié)省了資源。
例如,假設(shè)我們正在為產(chǎn)品開發(fā)一個(gè)在線支持聊天功能。在這種情況下,我們可以利用RAG技術(shù)從知識(shí)庫(kù)中檢索出相關(guān)的文檔,然后把這些信息提供給LLM Agent。接著,讓它根據(jù)提供的問題和文檔內(nèi)容撰寫出合適的答案。
在部署RAG技術(shù)時(shí),我們需要特別關(guān)注以下幾個(gè)關(guān)鍵點(diǎn):
- 檢索機(jī)制:通常的做法是通過搜索相似的內(nèi)容來找到相關(guān)文檔,有時(shí)候采用更簡(jiǎn)單的搜索方法(例如,基于關(guān)鍵詞的BM-25搜索)可能更有效或成本更低。
- 索引數(shù)據(jù)結(jié)構(gòu):如果我們直接索引整篇文檔而不做預(yù)處理,可能會(huì)影響搜索結(jié)果的質(zhì)量。因此,我們可能需要先進(jìn)行一些數(shù)據(jù)準(zhǔn)備,例如根據(jù)文檔內(nèi)容制作一份問答對(duì)列表。
- 元數(shù)據(jù):保留與查詢相關(guān)的元數(shù)據(jù)可以幫助我們更有效地篩選和引用信息(比如,只關(guān)注與用戶查詢直接相關(guān)的知識(shí)頁(yè)面)。這一額外的數(shù)據(jù)層可以使檢索過程更簡(jiǎn)單。
5.3. 提供相關(guān)上下文
在提供信息給Agent時(shí),關(guān)鍵是要把握一個(gè)度。提供很多信息似乎看起來非常有用,但是如果信息太多、太雜,反而可能會(huì)讓模型感到不堪重負(fù),難以區(qū)分哪些信息是真正相關(guān)的。過多的無關(guān)信息可能會(huì)讓模型學(xué)到錯(cuò)誤的東西,造成混淆甚至錯(cuò)誤的判斷。
例如,當(dāng)Gemini 1.5發(fā)布時(shí),它能處理高達(dá)10M標(biāo)記的數(shù)據(jù),一些專家開始質(zhì)疑這樣龐大的數(shù)據(jù)處理能力是否真的有效。盡管這種能力對(duì)某些特定場(chǎng)景(比如處理PDF文件的對(duì)話)很有幫助,但在需要對(duì)多種文檔進(jìn)行綜合推理的情況下,它的效果還是非常有限。
因此,我們?cè)谔峁┬畔r(shí),應(yīng)該盡量保證信息的相關(guān)性。這樣做不僅能減少模型處理無關(guān)數(shù)據(jù)時(shí)的計(jì)算負(fù)擔(dān),還能提高任務(wù)的執(zhí)行質(zhì)量和效率,同時(shí)也能降低成本。選擇什么樣的信息提供給模型,直接影響到模型的表現(xiàn)和效果。
要提高我們提供給LLM的上下文信息的相關(guān)性,有很多有效的方法,這些方法主要涉及如何更好地存儲(chǔ)和管理數(shù)據(jù)。特別是在使用檢索增強(qiáng)生成(RAG)技術(shù)的應(yīng)用中,加入一個(gè)準(zhǔn)備數(shù)據(jù)的步驟會(huì)非常有幫助。例如,我們可以先從文檔中提取出問題和答案,然后只向LLM代理提供這些答案。這樣,Agent接收到的上下文就會(huì)更加簡(jiǎn)潔明了。同時(shí),使用一些算法對(duì)檢索到的文檔進(jìn)行重新排序,也能優(yōu)化最終的輸出結(jié)果。
“數(shù)據(jù)是LLM應(yīng)用的核心驅(qū)動(dòng)力。好的上下文數(shù)據(jù)能最大限度地發(fā)揮出它的潛力。”
6、總結(jié)
LLM三角原則提供了一個(gè)基礎(chǔ)框架,幫助我們?cè)陂_發(fā)產(chǎn)品時(shí)發(fā)揮LLMs的功能。這個(gè)框架基于三個(gè)主要的元素:模型、工程集成、上下文數(shù)據(jù),以及一套詳細(xì)的操作步驟(SOP)。
6.1關(guān)鍵要點(diǎn)
- 從明確的操作步驟開始:先模擬專家如何思考和操作,然后根據(jù)這些信息為你的LLM應(yīng)用制定一份詳細(xì)的操作指南。這個(gè)指南將成為你實(shí)施其他步驟的基礎(chǔ)。
- 選擇合適的模型:在選擇模型時(shí)要考慮到性能和成本之間的平衡。你可以先從一個(gè)大模型開始,如果需要,以后再改用一個(gè)經(jīng)過微調(diào)的小模型。
- 利用工程技術(shù):建立一個(gè)LLM本地架構(gòu),并巧妙地利用代理來提升性能,同時(shí)確保能控制整個(gè)過程。試驗(yàn)不同的提示技術(shù),找到最適合你需求的方法。
- 提供相關(guān)上下文:合理利用上下文信息來增強(qiáng)學(xué)習(xí),比如使用檢索增強(qiáng)生成(RAG),但要注意避免給模型提供太多無關(guān)的信息。
- 不斷迭代和實(shí)驗(yàn):通常,找到最好的解決方案需要不斷的測(cè)試和調(diào)整。推薦閱讀《從零開始構(gòu)建大模型(LLM)應(yīng)用》來獲得更多關(guān)于LLM開發(fā)過程的詳細(xì)指導(dǎo)。
通過這些方法,組織不僅能超越基本的概念驗(yàn)證階段,還能開發(fā)出強(qiáng)大、準(zhǔn)備好上線的LLM應(yīng)用,最大限度地發(fā)揮這項(xiàng)技術(shù)的潛力。
6.2干貨推薦
在項(xiàng)目中,構(gòu)建大模型應(yīng)用時(shí),以下幾款工具是非常實(shí)用且常用的:
框架 | 使用場(chǎng)景 | 優(yōu)點(diǎn) | 缺點(diǎn) |
LangChain | 1、適合需要快速開發(fā)和部署大型模型應(yīng)用的場(chǎng)景。 2、適合有編程基礎(chǔ)和對(duì)大模型有了解的開發(fā)者。 | 1、易用性:LangChain簡(jiǎn)直是為程序員量身打造的工具集,簡(jiǎn)化了開發(fā)工作量。 2、模塊化設(shè)計(jì):各種模塊(如Retrievers、Memory、Chain、Agent、Tools)可以隨意組合,開發(fā)效率杠杠的。 3、快速迭代:幾乎每天都有新版本,成熟度不斷提升。 4、社區(qū)支持:在GitHub上人氣很高,社區(qū)非常活躍,獲取幫助很方便。 | 1、學(xué)習(xí)成本:雖然設(shè)計(jì)簡(jiǎn)單,但還是需要點(diǎn)代碼能力和對(duì)大模型的理解。 2、部分模塊成熟度不一:有些第三方功能還不太成熟,不建議直接用。 |
LlamaIndex | 1、適合需要結(jié)合大型語言模型和私有數(shù)據(jù)或特定領(lǐng)域數(shù)據(jù)的應(yīng)用場(chǎng)景。 2、適合有技術(shù)背景的開發(fā)者使用。 | 1、數(shù)據(jù)連接能力:LlamaIndex的數(shù)據(jù)連接器簡(jiǎn)直無敵,能讀多種外部數(shù)據(jù)源。 2、索引構(gòu)建:支持多種索引方式,用戶可以根據(jù)需求自由構(gòu)建索引。 3、查詢接口:提供大模型對(duì)話接口,讓大模型理解和回應(yīng)外部數(shù)據(jù)查詢。 4、擴(kuò)展性和靈活性:用戶可以自定義索引和查詢邏輯,滿足不同需求。 | 1、技術(shù)門檻:構(gòu)建和管理索引需要一定技術(shù)背景,對(duì)初學(xué)者有些難度。 2、資源消耗:索引和查詢會(huì)消耗較多計(jì)算資源,特別是處理大量數(shù)據(jù)時(shí)。 |
RAGFlow | 1、適合處理復(fù)雜格式非結(jié)構(gòu)化數(shù)據(jù)并構(gòu)建知識(shí)類應(yīng)用的企業(yè)和個(gè)人。 2、適合對(duì)文檔理解和問答質(zhì)量要求高的場(chǎng)景。 | 1、深度文檔理解能力:RAGFlow從復(fù)雜格式的非結(jié)構(gòu)化數(shù)據(jù)中提取真知灼見,支持無限上下文場(chǎng)景。 2、可控可解釋的文本切片:多種文本模板,結(jié)果可控可解釋,降低幻覺風(fēng)險(xiǎn)。 3、兼容異構(gòu)數(shù)據(jù)源:支持Word、PPT、Excel、PDF等多種文件類型,方便集成。 4、自動(dòng)化RAG工作流:全面優(yōu)化的RAG工作流,支持各種規(guī)模的生態(tài)系統(tǒng)。 | 目前具體缺點(diǎn)信息較少,可能包括某些特定功能的限制或性能瓶頸。 |
DB-GPT | 1、適合圍繞數(shù)據(jù)庫(kù)構(gòu)建大模型應(yīng)用的企業(yè)和個(gè)人。 2、適合對(duì)模型管理、數(shù)據(jù)處理和問答體驗(yàn)要求高的場(chǎng)景。 | 1、多模型管理:DB-GPT支持多種開源和API代理的大語言模型,管理功能強(qiáng)大。 2、Text2SQL效果優(yōu)化:優(yōu)化了Text2SQL任務(wù),提高應(yīng)用智能化水平。 3、RAG框架:基于RAG能力構(gòu)建知識(shí)類應(yīng)用。 4、數(shù)據(jù)驅(qū)動(dòng)的Multi-Agents框架:支持自定義插件執(zhí)行任務(wù),智能體協(xié)作高效。 5、數(shù)據(jù)隱私和安全:注重?cái)?shù)據(jù)隱私,通過私有化大模型、代理脫敏等技術(shù)保障數(shù)據(jù)安全。 | 相比其他框架,DB-GPT更側(cè)重?cái)?shù)據(jù)應(yīng)用和模型管理,對(duì)某些特定場(chǎng)景支持不如其他框架全面。 |