Lua 進程內存優化方案總結
作者 | benderzhao
一、方案
常見的內存優化方法有很多,針對不同的場景有不同的解決方案,下面按照由簡到繁的順序一一道來。

字段裁剪
顯而易見,把沒用的字段干掉,就可以省內存。根據前文的內存計算公式,哪怕只存了一個bool值,占用也是16字節。因此,首先考慮是去掉一些完全沒用的字段,其次是去掉一些默認值的字段。
比如游戲里常見的物品,有id、數量、各種屬性等。如果出于方便或者可讀性,亦或者C++良好的編碼習慣,為每個字段都設置一個初始值,那么物品結構就大概長這樣:
local item = {
id = 123123,
count = 1,
property1 = 0,
property2 = 0,
property3 = "",
property4 = false,
}這種寫法property1到property4的默認值占用了大量的內存,單個item從2個Key-Value變為了6個,內存也膨脹了3倍。
比較節省內存的做法是無默認值,在使用時or下即可:
local property1 = item.property1 or 0當然,如果使用的地方特別多,比如有上萬處地方直接使用了item.property1,這種改動還是太大。這個后面會講到還有別的方法。
結構調整
如果不熟悉Lua的實現,雀食會設計出一些常見于C++,但不友好于Lua內存的結構。
還是用物品舉例,假設一個玩家有1000個物品,每個物品有一些屬性。比較符合直覺的數據結構是這樣:
local items = {
[10001] = {count = 1, property1 = 1},
[10002] = {count = 2, property2 = 4},
[10003] = {count = 4, property4 = 10},
...
[11000] = {count = 3, property1 = 2},
}使用一個Table來存儲所有的物品,每個Key是物品id,Value是具體的屬性。
這種結構淺顯易懂,但是有個問題,總共有1000+個Table,而Table不同于C++的struct,它是有很大的內存開銷的,這種數據結構占用的內存會出乎意料的大,在這里光Table的占用就會有幾十KB。
考慮換成另一種結構:
local items = {
count = {
[10001] = 1,
...
[11000] = 3,
},
property1 = {
[10001] = 1
...
[11000] = 2,
}
...
}這里把相同的字段放在一起,比如所有的count是一個Table,Key是物品id,Value是數量。這種結構與前面的對比,Key-Value的數量是沒差別的,但是只有個位數的Table,對比前面的1000+,有幾個數量級的差距。
當然,改動還是比較大的,但是如果對于這個結構的訪問都收斂到物品模塊內,對外只提供接口,那就還可以接受。
對于其他結構也是一樣,主旨就是減少Table的使用。
提取公共表
前面字段裁剪提到,如果有一些默認字段不好剔除,比如有上萬次使用的地方,挨個去加判斷肯定不現實,因此可以考慮提取元表來優化。
還是用物品舉例,假設有1000個物品,每個物品有3個屬性,絕大部分情況下都是默認值0。
local items = {
[10001] = {count = 1, property1 = 0, property2 = 0, property3 = 0},
[10002] = {count = 2, property1 = 0, property2 = 0, property3 = 0},
[10003] = {count = 4, property1 = 0, property2 = 0, property3 = 0},
...
[11000] = {count = 3, property1 = 1, property2 = 0, property3 = 0},
}因為每個物品結構的字段都是一樣,且大部分都是相同的值為0,因此我們提取一個元表base:
local base = {
property1 = 0, property2 = 0, property3 = 0
}然后將原始數據里與base內容一樣的字段剔除掉,變為:
local items = {
[10001] = {count = 1},
[10002] = {count = 2},
[10003] = {count = 4},
...
[11000] = {count = 3, property1 = 1,
}再為每個物品設置元表,get不到的字段就去base里找。set則只在自己的Table里設置。所有物品共用一張元表。
顯而易見,通過共用base的默認值,很多重復的Key-Value被優化掉了,也就節省了內存。
這種方法適合于結構一致,且有大量相同值的情況。
內存壓縮
假如結構不一致,或者字段的值都各不相同,又該如何優化呢?例如我們已經把沒用的字段剔除了,現在物品結構長這樣:
local items = {
[10001] = {count = 1},
[10002] = {count = 2},
[10003] = {count = 4},
...
[11000] = {count = 3, property1 = 1,
}考慮前面的指導思想,就是減少Table的使用,因此我們可以考慮把Table序列化為字符串,例如變成:
local items = {
[10001] = "count=1",
[10002] = "count=2",
[10003] = "count=4",
...
[11000] = "count=3,property1=1",
}這樣就少了一大堆的二級的Table。當然,這種序列化格式還是比較占內存,這里只是舉個例子方便理解。實際可以序列化為緊湊的二進制形式。
改為字符串后,要是想訪問里面的count,怎么辦?還是設置元表,在使用的時候還原回Table即可。
而既然都序列化為二進制字符串了,那干脆再調用下lz4壓縮下,犧牲一點點CPU換來更高的優化效果。比如變為:
local items = {
[10001] = "\01\FF",
[10002] = "\01\FE",
[10003] = "\01\1F",
...
[11000] = "\01\3F\24",
}到此為止了嗎?不,還可以進一步優化,考慮每個結構其實都是長差不多的,比如都有count字段存放整數,那與其挨個結構壓縮,不如聚合N個結構一起壓縮,那樣的壓縮比更好。
假設N取10,將原來的id除10聚合,先變為臨時結構:
local items = {
[1000] = {
[10001] = {count = 1},
[10002] = {count = 2},
...
[10009] = {count = 4},
},
[1001] = {...}
...
[1100] = {...}
}這樣10個一組,再分別對每一組序列化后壓縮,變為:
local items = {
[1000] = "\01\FF\12\22",
[1001] = "\01\FE\12\22",
...
[1100] = "\01\3F\24\12\22",
}這樣可節省的內存將會更多。訪問的方式也是一樣,當訪問到某id時,除10找到對應的組,解壓縮反序列化即可。
這種優化方式對于一些冷數據的,尤為有效,因為大部分情況下都不會訪問它們。
下沉C++
在前面的優化方法都嘗試之后,還想繼續優化內存,怎么辦?考慮一個問題,似乎C++很少因為定義幾個字段幾個Struct就內存炸了的情況,究其原因,有以下幾點:
- C++的Struct或者Class無額外消耗,一個空Class幾乎不消耗內存。而Lua的Table本質是一個很復雜的HashTable與Vector結構,即使是個空Table也消耗了一大坨內存。
- C++的字段是緊密排列,一個int就是固定的4字節,無額外消耗。而Lua因為是弱類型的解釋語言,除了本身的數據存儲,還需要類型描述以及GC等信息,單個字段的消耗是16字節+,相比C++膨脹了數倍,雖然實際上Lua已經實現的很精巧了。
那么,我們也仿照C++實現一套內存布局,是不是就可以了?
比如某個Table結構有a、b、c三個字段,都為int范圍的整數,那我們在C++中開辟一塊12字節的內存來存放就行了,干掉Lua中的Table,把對a、b、c的讀寫操作都映射到C++里的這塊內存上。
如何映射呢?當然也是用元表了。也許你會說元表不也會占用空間?是會占用,所以我們要把所有類型相同的結構共用一份元表,比如有1000個Item,只有一份元表。
理論上來說,這種方式就可以達到接近C++的內存使用,從而優化Lua的內存占用,順便還減輕了GC的壓力,因為Lua中已經沒有復雜的Table結構了。
將大象裝進冰箱的思路有了,下面就講下具體的幾步。
結構定義
首先第一步,是要先描述結構的定義,可以采用自定義的格式,比如還是物品的例子,干脆直接用Lua描述它的格式:
local Item = {
[id] = {size = 4},
[count] = {size = 4},
[property1] = {size = 4},
...
}Item有3個字段,每個字段4字節。或者也可以使用json、protobuf等格式,比如protobuf:
message Item {
int32 id = 1;
int32 count = 2;
int32 property1 = 3;
...
}考慮到生態,使用protobuf來描述最好。各種工具齊全,且大部分人都了解這個語法,無需再重新學習。
內存布局
有了protobuf的定義后,接下來就是在內存里把這些字段排列開來,也許你突然想到,既然都用了protobuf,那直接用它的反射庫不就好了?
(1) protobuf反射庫
protobuf的反射庫做的事情與我們要做的差不多,解析proto文件,生成一套描述信息Reflection,然后就可以根據Reflection初始化一塊內存Message,并動態的讀寫其中的字段。
比如典型的接口:
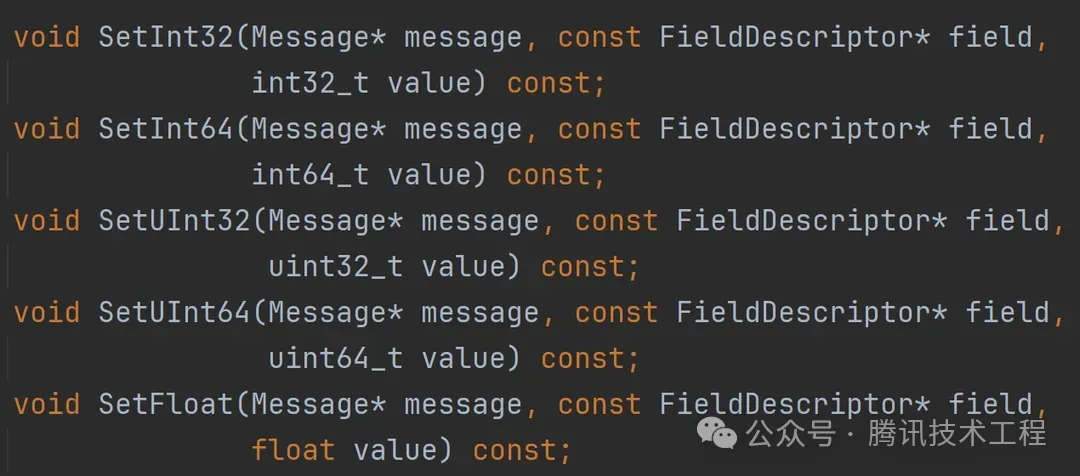
最終的實現,也是將內存地址強轉成類型指針,直接copy進內存,與我們的思路可以說一模一樣。
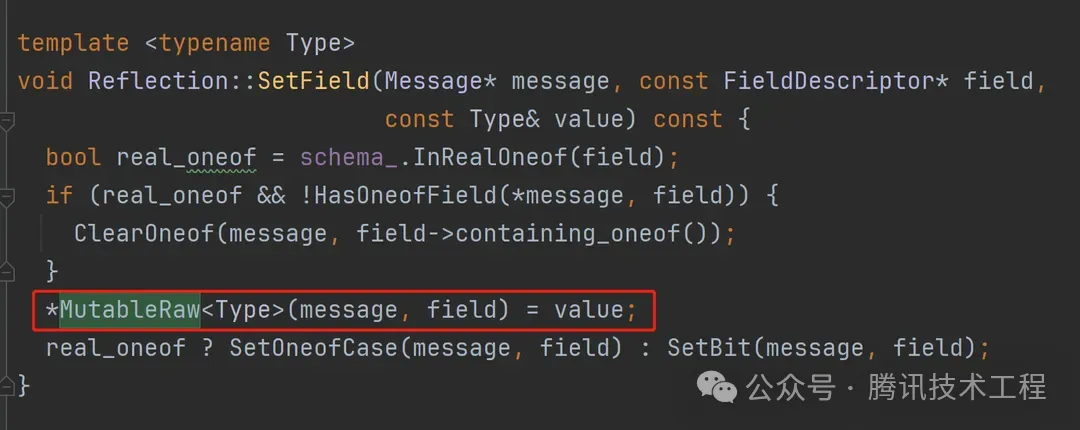
那看起來底層實現直接用protobuf就好了?然而,protobuf的反射庫除了太重,還有個最大的問題,是沒法支持熱更新。
(2) 反射需求
Lua天生就支持熱更新,因此,在將Lua內存下沉到C++時,也必須考慮這個問題。考慮之前的物品的Lua結構:
local Item = {
id = 123123,
count = 1,
property1 = 0
}對應的protobuf定義:
message Item {
int32 id = 1;
int32 count = 2;
int32 property1 = 3;
}最開始id寫在了分配的C++的內存的偏移0,count寫在了偏移4,以此類推。
當我們業務需要,假設需要增加一個字段time,出于可讀性考慮,我們加在了中間位置。Lua結構變為:
message Item {
int32 id = 1;
int32 count = 2;
int32 property1 = 3;
}對應的新的protobuf定義:
message Item {
int32 id = 1;
int32 count = 2;
int32 time = 3;
int32 property1 = 4;
}這時候,再使用新的protobuf的偏移,去讀寫我們之前分配好的內存,會明顯錯位了,比如現在property1的偏移是12,但是在舊的內存布局里,偏移是8。
怎么辦?也許你已經想到了,首先protobuf的定義不能亂來,應該兼容舊版本,比如新增字段后,新的定義應該為:
message Item {
int32 id = 1;
int32 count = 2;
int32 time = 4; // 插在中間可以,tag必須兼容
int32 property1 = 3;
}其次,在內存中永久維護一份message對應的layout,當加載新的protobuf定義后,根據tag修補layout的結構。
在這個例子中,舊的layout是(id, 0), (count, 4), (property1, 8),后面的數字是字段開始的偏移。
加載新定義之后,新的tag只會往后補充,layout變為(id, 0), (count, 4), (property1, 8), (time, 12)。
這樣,使用新的layout訪問舊內存布局,是兼容沒問題的。
也許你會問,要是刪除字段怎么辦?豈不是會留有一個空洞?比如某天property1廢棄了,那layout變為了(id, 0), (count, 4), (廢棄, 8), (time, 12),有幾種辦法:新增的同類型字段可復用這個tag;等待重啟;當看不見。
另外又因為熱更并不頻繁,所以這部分兼容的代碼,可以做在Lua里,實現更簡單,也不會造成性能的困擾。
(3) 小結
所以考慮熱更新需求和代碼復雜度,我們并不直接使用protobuf的反射庫,改為自己實現一套類似的內存布局管理。
同時protobuf的內存生命周期管理也不是我們期望的,這個下面會講到。
內存管理
熟悉Lua的人都知道,Lua把所有的短字符串都放到一個HashMap存起來,這樣內存里只會存一份字符串的拷貝。比如:
local a = "test"
local b = "test"a與b都指向了同樣的字符串地址,節省了內存,而且這樣判斷a與b是否相等時,可以直接使用指針比較,而無需調用strcmp,也提高了性能。
而什么時候從hashmap刪掉呢?自然是沒有使用了,Lua通過GC來刪掉。比如:
local a = "test"
a = nil其他需要GC的類型比如Table、UserData也是同理。
那既然我們把Lua內存下沉到C++,Lua復雜的結構如何保證既不會內存泄露,又不會野指針呢?要知道,Lua的Table是可以隨便相互各種引用的。
是不是也要復刻這套GC呢?其實大可不必,我們使用最簡單的引用計數即可。
(1) 引用計數
引用計數眾所周知,引用+1,取消引用-1,為0表示沒人引用了,就釋放掉。比如std::shared_ptr就是干這個的。
但是引用計數有個問題是循環引用,比如:
local a = {}
local b = {}
a.b = b
b.a = a這樣a與b相互引用,就沒機會減到0了。Lua為了避免這個問題,采用三色標記法來一波一波的回收。
那為什么Lua內存下沉到C++中,反倒可以使用引用計數,沒有循環引用的問題呢?
原因很簡單,我們使用了protobuf來描述結構。直接不讓這么定義就行了,比如這種是不允許的:
message A {
B b = 1;
}
message B {
A a = 1;
}實際上也幾乎不會有必須這樣寫的業務需求。大部分是分層的定義:
message A {
Base b = 1;
}
message B {
Base a = 1;
}
message Base {
...
}當去掉了循環的邊,所有的結構都變成了一顆樹,只要使用引用計數管理即可,簡單又高效。
又因為Lua都是單線程的,所以使用一個單線程版本的shared_ptr即可,性能更佳。
(2) 復雜結構
當然,我們的結構不可能總全是int,必須要支持嵌套、repeated、map的定義,比如:
message Player {
string name = 1;
int32 score = 2;
bool is_vip = 3;
float experience = 4;
repeated Item items = 5;
Pet pet = 6;
map<string, Friend> friends = 7;
}在前面我們知道各個字段是按照偏移來存放在內存里的,那這里的name、items、pet、friends成員應該如何存?畢竟幾乎都是編譯期未知的大小。
那么很簡單,只存放指針即可,固定8字節。指針索引到具體的實例上去,對應的就是String、Array、Map。
(3) 字符串池子
如前所述,我們也仿照Lua,把所有C++里的字符串用一個hashmap管理起來。
雖然實際上不需要在C++中用到字符串的比對,因為訪問a.b時,Lua層已經把b映射到某個偏移了,C++也就無需在用b再做字符串比較查找字段。
這種設計的主要目的還是減少內存的占用,畢竟程序中還是存在大量的相同字符串的。
另外String雖然也使用了引用計數管理,但是在釋放時,需要從池子中刪掉,并且池子是不能增加計數的,不然永遠到不了0,這里要用到weakptr了。
(4) Array實現
Array對應的就是Lua中的數組,比如:
local array = {"a", "b", "c"}也是protobuf里的repeated,對應的定義:
repeated string array = 1;雖然repeated看起來和普通的message區別很大,但是在C++里實現是差不多的。
message是在訪問a.b時,把b映射到某個偏移讀寫。
repeated則是在訪問a[1]時,把1也映射到某個偏移,邏輯更簡單了,乘以單個的元素大小即可。
不過這里需要注意的是,在設置元素時,要確保是符合protobuf的定義的,畢竟Lua是可以隨便寫,如果上面的例子:
array[1] = 2把整數設置到了字符串數組中,C++層要能夠檢測并拋出異常出來。
(5) Map實現
Map在Lua里雖然也是Table,但是是用來存放未知的KV的,典型的比如一個好友的集合:
local friends = {
["123123"] = {name = "張三"},
["123124"] = {name = "李四"},
}對應到protobuf的定義:
map<string, Friend> friends = 1;這個Map就不能靠偏移來實現了,是放KV的也就只能用HashMap結構。
而既然要節省內存,那自然要用最精確的字段來存儲了,比如:
map<int32, int32> map1 = 1;
map<int64, int32> map2 = 2;
map<int32, int64> map1 = 3;
map<int64, int64> map1 = 4;這有4種尺寸的KV排列組合,如果我們想簡單實現,定義個union,比如:
union Data {
int32_t i32;
int32_t i64;
...
};然后用一個C++的std::unordered_map<Data, Data>來存放所有類型的KV。這種方式固然簡單,但是內存明顯并沒有做到最優。
怎么辦呢?似乎也沒什么好方法,羅列下所有的可能性,然后定一個指針union,像這樣:
union Map {
std::unordered_map<int32_t, int32_t> * i32_32;
std::unordered_map<int32_t, int64_t> * i32_64;
...
};然后根據protobuf的定義,初始化對應的類型,并按照那個類型來讀寫。
看起來很蠢,但是卻是最簡單有效的做法。也許你會說,有字節對齊,i32_32與i32_64占用的實際內存會不會其實是一樣的?
是有這個可能,但是我們沒法假定std::unordered_map內部實現的結構定義,而且哪怕是一樣的,除了代碼多一點,CPU和內存均無損失。
而代碼方面,可以借助template以及C++17的if constexpr,最大程度的減少冗余。
(6) 測試結果
廢了好大勁,終于正確無誤的把Lua內存下沉到C++中,現在是檢驗優化成果的時候了。
分成了普通結構、Array、Map三種場景。
(7) 普通結構
就是最普通簡單的結構體,定義如下:
message SimpleStruct {
int32 a = 1;
int32 b = 2;
int32 c = 3;
...
int32 y = 25;
int32 z = 26;
}初始化了5000份數據,實測下沉C++后,內存為Lua的1/3左右。
(8) Array
也采用了最簡單的數組類型,定義如下:
repeated int32 labels = 6;插入1000w條數據后,C++內存為Lua的1/4左右。
(9) Map
最后是Map類型,定義為:
map<int32, int32> params = 9;插入1000w條數據后,C++的內存居然和Lua差不多,甚至還稍大些。這就尷尬了。
(10) Map優化
分析代碼,Map下沉之后,內存不減反增。而我們只是封裝了一層std::unordered_map,所以問題必然出現在它與Lua的實現的不同上面。
根據資料,std::unordered_map采用的是拉鏈法,除了KV本身的存儲外,還有桶、鏈表等消耗,那是會多耗費些內存。
再觀察Lua的實現,它其實用的是Coalesced hashing,這種實現雖然Set稍顯麻煩,但是Get卻很簡單,同時因為是一整塊內存,內存利用率更高。
既然std::unordered_map比不過它,那么我們自己實現一個類似的coalesced_map即可,同樣的算法,不過做了些變種,比如支持Delete。
將coalesced_map與std::unordered_map比較下性能,Set會稍慢點,Get是一致的,符合預期。實際上程序中也是讀多寫少,Lua這種策略沒錯。
(11) 優化后測試
最后,重新跑一遍測試,C++內存為Lua的1/2左右。不得不說,Lua實現真的很精巧。
總體來說,下沉方案效果還可以,但是還有繼續扣內存的空間。
(12) 總結
Lua確實是嵌入式腳本語言一哥,開發效率高,運行效率也不差。
不過如果一不注意,就容易陷入CPU與內存的陷阱中,大量使用時還是要多加注意。