MinerU一款全能、開源的文檔與網(wǎng)頁數(shù)據(jù)提取工具

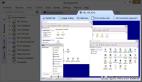
MinerU 是一款由上海人工智能實驗室OpenDataLab團隊發(fā)布的全能、開源的文檔與網(wǎng)頁數(shù)據(jù)提取工具。它能夠?qū)瑘D片、表格、公式等元素的多模態(tài)PDF文檔轉(zhuǎn)化為清晰、易于分析的Markdown格式,同時也支持從包含廣告等干擾信息的網(wǎng)頁中快速解析、抽取正式內(nèi)容,并將其批量轉(zhuǎn)化為Markdown格式。

一、主要特點
多功能性:MinerU 包含兩個主要部分:Magic-PDF和Magic-Doc,分別負責PDF文檔提取和網(wǎng)頁與電子書提取。
多模態(tài)處理:Magic-PDF能夠處理PDF中的圖像、表格、公式等多種內(nèi)容類型,并保留原文檔的結(jié)構(gòu)和格式。
高質(zhì)量解析:MinerU使用了先進的模型,如LayoutLMv3、YOLOv8、UniMERNet和PaddleOCR,以確保數(shù)據(jù)提取的高準確度。
廣泛的應用場景:適用于學術(shù)、財務、法律等多個領(lǐng)域,并支持多達176種語言的準確識別。
跨平臺支持:能夠在Windows、Linux和Mac平臺上運行,并支持CPU和GPU環(huán)境。

二、使用場景
MinerU 適用于需要從復雜格式的文檔中提取數(shù)據(jù)的場景,尤其適合于AI研究和大模型訓練中處理大量非結(jié)構(gòu)化數(shù)據(jù)的需求。
三、技術(shù)細節(jié)

PDF文檔提取:MinerU的PDF提取過程包括PDF文檔分類預處理、模型解析和管線處理等環(huán)節(jié)。它能夠識別和處理文本型、圖層型和掃描版的PDF文檔,并通過一系列深度學習模型進行版面分析、OCR和公式識別。
網(wǎng)頁與電子書提取:Magic-Doc能夠從多種類型的網(wǎng)頁和電子書中提取信息,支持包括epub、mobi在內(nèi)的多種格式,并能夠處理文章、論壇、音樂、視頻等內(nèi)容類型。

四、快速安裝與使用
CPU Demo
# 1. 安裝依賴
conda create -n MinerU pythnotallow=3.10
conda activate MinerU
pip install -U magic-pdf[full] --extra-index-url https://wheels.myhloli.com -i https://pypi.tuna.tsinghua.edu.cn/simple
# 2. 下載模型權(quán)重文件
# 根據(jù)官方文檔(https://github.com/opendatalab/MinerU/blob/master/docs/how_to_download_models_en.md)指示操作
# 3. 配置Magic-PDF
cp magic-pdf.template.json ~/magic-pdf.json
# 編輯 ~/magic-pdf.json,設(shè)置正確的模型文件路徑
# 4. 開始使用
magic-pdf --help
magic-pdf -p {some_pdf} -o {some_output_dir} -m autoDocker 快速部署
# 檢查您的設(shè)備是否支持Docker上的CUDA加速。
docker run --rm --gpus=all nvidia/cuda:12.1.0-base-ubuntu22.04 nvidia-smi
# 運行 docker 部署
wget https://github.com/opendatalab/MinerU/raw/master/Dockerfile
docker build -t mineru:latest .
docker run --rm -it --gpus=all mineru:latest /bin/bash
magic-pdf --help更多使用方式,請查閱如下提供地址
總結(jié)
體驗鏈接: https://opendatalab.com/OpenSourceTools/Extractor/PDF
開源倉庫:https://github.com/opendatalab/MinerU/
MinerU開源模型(PDF-Extract-Kit): https://modelscope.cn/models/OpenDataLab/PDF-Extract-Kit