一文搞懂大模型在多 GPU 環境的分布式訓練!
隨著大模型時代的到來,模型參數量、訓練數據量、計算量等各方面急劇增長。大模型訓練面臨新的挑戰:
- 顯存挑戰:例如,175B的GPT-3模型需要175B*4bytes即700GB模型參數空間,而常見的GPU顯存如A100是80G顯存,這樣看來連模型加載都困難更別說訓練。
- 計算挑戰:175B的GPT-3模型計算量也很龐大了,再疊加預訓練數據量,所需的計算量與BERT時代完全不可同日而語。
分布式訓練(Distributed Training)則可以解決海量計算和內存資源要求的問題。它可將一個模型訓練任務拆分為多個子任務,并將子任務分發給多個計算設備(eg:單機多卡,多機多卡),從而解決資源瓶頸。
本文將詳細介紹分布式訓練的基本概念、集群架構、并行策略等,以及如何在集群上訓練大語言模型。

一、何為分布式訓練?
分布式訓練是指將機器學習或深度學習模型訓練任務分解成多個子任務,并在多個計算設備上并行訓練,可以更快速地完成整體計算,并最終實現對整個計算過程的加速。
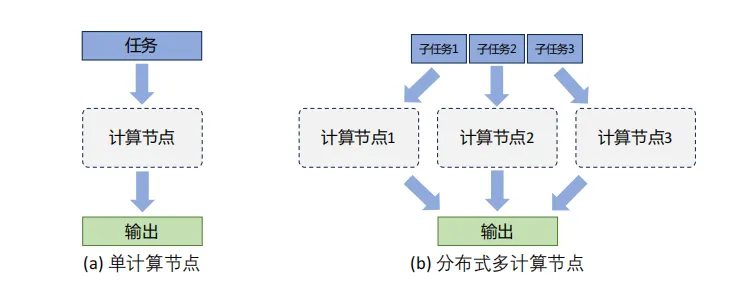
如上圖是單個計算設備和多個計算設備的不同,這里計算設備可以是CPU、GPU、TPU、NPU等。
在分布式訓練的背景下,無論是單服務器內的多計算設備還是跨服務器的多設備,系統架構均被視為「分布式系統」。這是因為,即使在同一服務器內部,多個計算設備(如GPU)之間的內存也不一定是共享的,意味著「設備間的數據交換和同步必須通過網絡或高速互聯實現」,與跨服務器的設備通信本質相同。
二、分布式訓練集群架構
分布式訓練集群屬于高性能計算集群(High Performance Computing Cluster,HPC),其目標是提供海量的計算能力。 在由高速網絡組成的高性能計算上構建分布式訓練系統。
高性能計算集群硬件組成如圖所示。
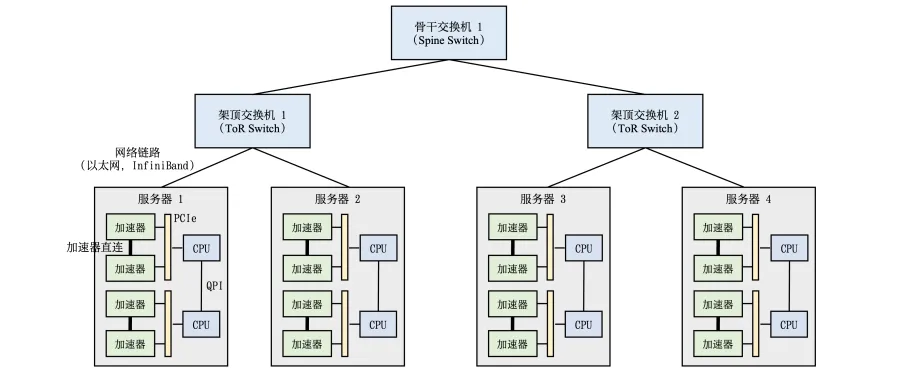
整個計算集群包含大量帶有計算加速設備的服務器,多個服務器會被安置在機柜中,服務器通過架頂交換機(Top of Rack Switch,ToR)連接網絡。在架頂交換機滿載的情況下,可以通過在架頂交換機間增加骨干交換機進一步接入新的機柜。
每個服務器中通常是由2-16個計算加速設備組成,這些計算加速設備之間的高速通信直接影響到分布式訓練的效率。傳統的PCI Express(PCIe)總線,即使是PCIe 5.0版本,也只能提供相對較低的128GB/s帶寬,這在處理大規模數據集和復雜模型時可能成為瓶頸。
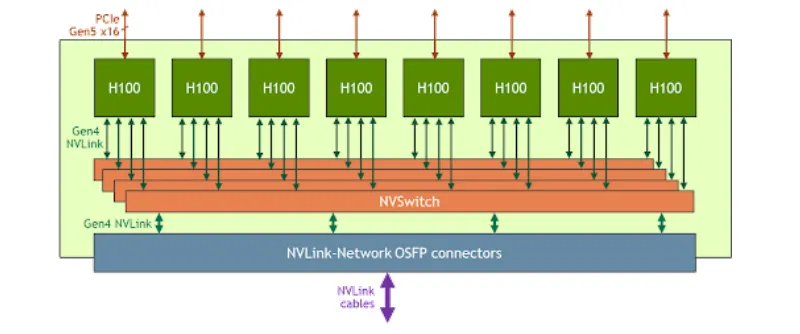
為了解決這一問題,NVIDIA推出了NVLink和NVSwitch技術。如下圖所示,每個H100 GPU都有多個NVLink端口,并連接到所有四個NVSwitch上。每個NVSwitch都是一個完全無阻塞的交換機,完全連接所有8個H100計算加速卡。NVSwitch的這種完全連接的拓撲結構,使得服務器內任何H100加速卡之間都可以達到900GB/s雙向通信速度。
針對分布式訓練服務器集群進行架構涉及的主流架構,目前主流的主要分為參數服務器(ParameterServer,簡稱PS)和去中心化架構(Decentralized Network)兩種分布式架構。
1.參數服務器架構
參數服務器架構的分布式訓練系統中有兩種服務器:
- 訓練服務器:提供大量的計算資源
- 參數服務器:提供充足的內存資源和通信資源
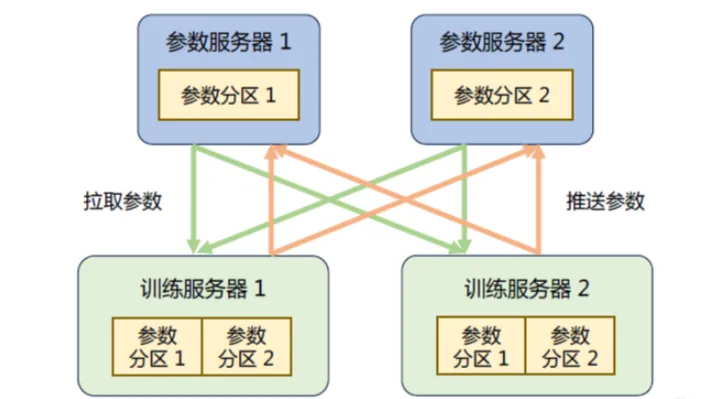
如下所示是具有參數服務器的分布式訓練集群的示意圖。在訓練過程中,每個訓練服務器都擁有完整的模型,并根據將分配到此服務器的訓練數據集切片(Dataset Shard)進行計算,將得到的梯度推送到相應的參數服務器。參數服務器會等待兩個訓練服務器都完成梯度推送,然后開始計算平均梯度,并更新參數。之后,參數服務器會通知訓練服務器拉取最新的參數,并開始下一輪訓練迭代。
2.去中心化架構
去中心化架構沒有中央服務器或控制節點,而是由節點之間進行直接通信和協調,這種架構的好處是可以減少通信瓶頸,提高系統的可擴展性。
節點之間的分布式通信一般有兩大類:
- 點對點通信(Point-to-Point Communication):在一組節點內進行通信
- 集合通信(Collective communication,CC):在兩個節點之間進行通信
去中心化架構中通常采用集合通信實現。
常見通信原語如下:
(1) Broadcast
將數據從主節點發送到集群中的其他節點。如下圖,計算設備1將大小為1xN的張量廣播到其它設備,最終每張卡輸出均為1×N矩陣。
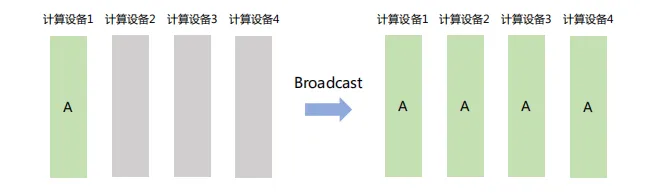
Broadcast在分布式訓練中主要用于「模型參數初始化」。
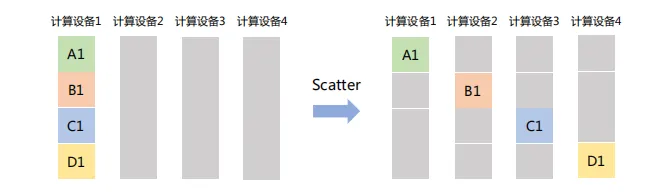
(2) Scatter
主節點將一個大的數據塊分割成若干小部分,再將每部分分發到集群中的其他節點。如下圖,計算設備1將大小為1xN的張量分成4個子張量,再分別發送給其它設備。
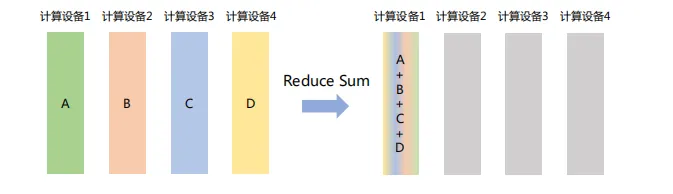
(3) Reduce
將不同節點上的計算結果進行聚合。Reduce操作可以細分為多種類型,包括SUM(求和)、MIN(求最小值)、MAX(求最大值)、PROD(乘積)、LOR(邏輯或)等,每種類型對應一種特定的聚合方式。
如下圖所示,Reduce Sum操作將所有計算設備上的數據進行求和,然后將結果返回到計算設備1。
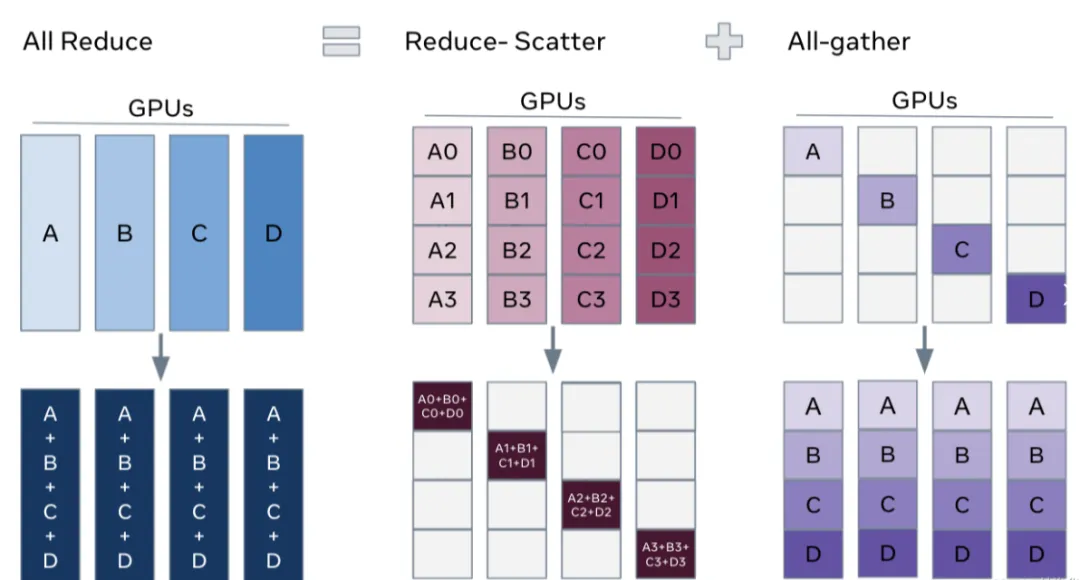
(4) All Reduce
在所有節點上執行同樣的Reduce操作,如求和、求最小值、求最大值等。可通過單節點上Reduce+Broadcast操作完成。
如下圖所示,All Reduce Sum操作將所有節點上的數據求和,然后將求和結果Broadcast到所有節點。
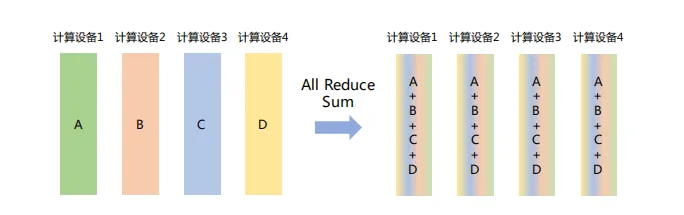
(5) Gather
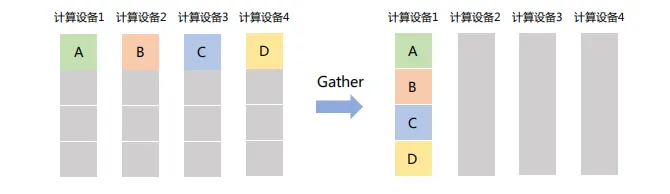
將所有節點的數據收集到單個節點,可以看作是Scatter操作的逆操作。
如下圖所示,Gather操作將所有設備的數據收集到計算設備1中。
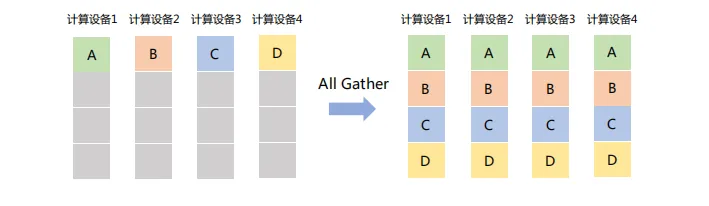
「All Gather」在所有節點上收集所有其他節點的數據,最終使每個節點都擁有一份完整的數據集合。可以視為Gather操作與Broadcast操作的結合體。如下圖所示,All Gather操作將所有計算設備上的數據收集到各個計算設備。
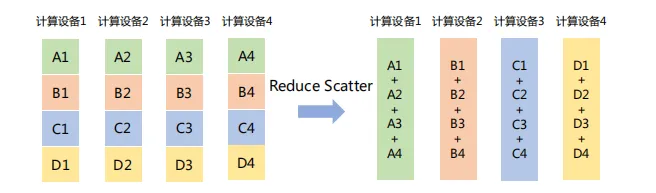
「Reduce Scatter」將每個節點的張量分割成多個塊,每個塊分發給不同的節點,再在每個節點執行Reduce操作(如求和、平均等)。如下圖所示,Reduce Scatter操作將每個計算設備中的張量分割成4塊,并發送給4個不同的計算設備,每個計算設備對接收到的塊執行Reduce Sum操作。
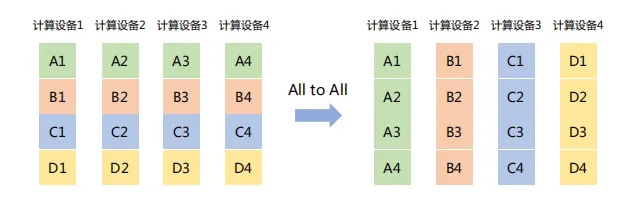
(7) All to All
將每個節點上的數據分割成多個塊,并將這些塊分別發送給不同的節點。
如下圖所示,All to All操作將每個計算設備中的張量分割成4塊,并發送給4個不同的計算設備。
三、分布式訓練并行策略
分布式訓練系統的核心目標是將原本在單一計算節點上進行的模型訓練過程,轉化為能在多個計算節點上并行執行,以加速訓練速度并支持更大規模的模型和數據集。
在單節點模型訓練中,系統結構主要由兩大部分組成:數據和模型。訓練過程由多個數據小批次(Mini-batch)完成。如圖所示,數據表示一個數據小批次。訓練系統會利用數據小批次根據損失函數和優化算法生成梯度,從而對模型參數進行修正。
針對大語言模型多層神經網絡的執行過程,模型訓練過程可以抽象為一個計算圖(Computational Graph)。這個圖由多個相互連接的算子(Operator)構成,每個算子對應神經網絡中的一個層(Neural Network Layer),如卷積層、全連接層等。參數(Weights)則是這些層在訓練過程中不斷更新的權重。
計算圖的執行過程可以分為前向傳播和反向傳播兩個階段。
前向計算(Forward Pass):
- 輸入數據:數據從輸入層開始,被送入計算圖的第一個算子。
- 算子執行:每個算子接收輸入數據,執行相應的數學運算(如矩陣乘法、激活函數等),并產生輸出。
- 數據傳遞:算子的輸出作為后續算子的輸入,沿著計算圖向前傳播。
- 輸出生成:當數據到達計算圖的末端,即輸出層,產生最終的預測結果。
反向計算(Backward Pass):
- 損失計算:在前向傳播完成后,使用損失函數比較預測輸出與實際標簽,計算損失值。
- 梯度計算:從輸出層開始,反向遍歷計算圖,根據損失值和算子的導數,計算每個算子的梯度。
- 參數更新:利用計算出的梯度,根據選擇的優化算法(如梯度下降、Adam等),更新模型參數。
- 傳播回溯:反向計算過程從輸出層向輸入層遞歸進行,直到所有參數都被更新。
根據單設備模型訓練流程,可以看出,如果進行并行加速,可以從數據和模型兩個維度考慮:
- 對數據進行切分(Partition),并將同一個模型copy到多個設備上,每個設備并行執行不同的數據分片,即「數據并行(Data Parallelism,DP)」。
- 對模型進行拆分,將模型中的算子分發到多個設備分別完成,即「模型并行(Model Parallelism,MP)」。
- 訓練超大規模語言模型時,同時對數據和模型進行并行,即「混合并行(Hybrid Parallelism,HP)」。
1.數據并行DP
數據并行是最常用的并行訓練方式,主要分為DataParallel(DP)和DistributedDataParallel(DDP)兩種。
(1) DP
DP是早使用的數據并行方案,通過torch.nn.DataParallel()來調用,代碼如下:
# 設置可見的GPU
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1,2,3"
# 將模型放到GPU 0上,必須先把模型放在GPU上,后面才可以調用DP
model.cuda()
# 構建DataParallel數據并行化
model=torch.nn.DataParallel(model)DP核心思想是將一個大的batch數據分割成多個子batch,并將子batch分配給不同的GPU進行并行計算。如下圖將訓練過程分為前向傳播和反向傳播詳細分析:
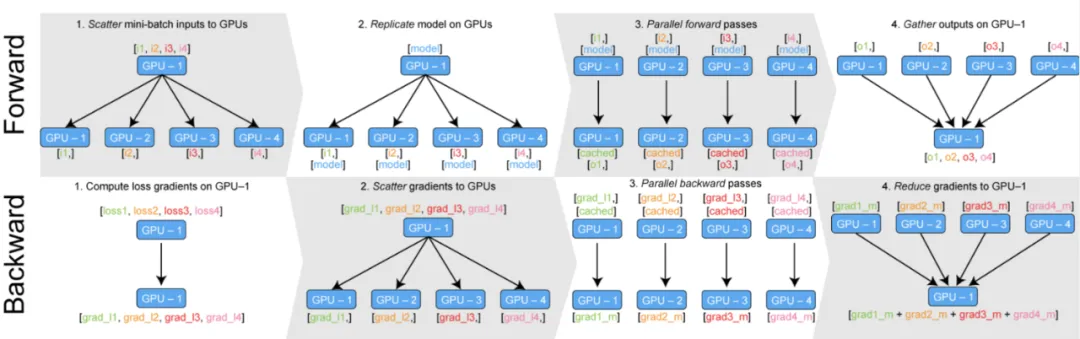
前向傳播:
- 模型和完整的mini-batch數據被放置在Master GPU(例如GPU:0)上。
- GPU:0將mini-batch數據分割成若干個子batch,并將這些子batch分發(scatter)到其它GPU上。
- GPU:0將自身的模型參數復制到其它GPU,確保每個GPU上的模型參數完全相同。
- 每個GPU在單獨的線程上對其sub-mini-batch的數據前向傳播,計算出各自的輸出結果。
- GPU:0收集所有GPU的輸出結果。
反向傳播:
- GPU:0基于收集的輸出結果和真實label計算總損失loss,并得到loss的梯度。
- GPU:0將計算出的loss梯度分發(scatter)到所有GPU上。
- 每個GPU根據收到的loss梯度反向傳播,計算出所有模型參數的梯度。
- 所有GPU計算出的參數梯度被匯總回GPU:0。
- GPU:0基于匯總的梯度更新模型參數,完成一次迭代的訓練。
有人說GPU:0好自私,把其它GPU當做工具人,核心機密不對外,只給其他GPU數據,不給label,其它GPU得到結果它再給計算loss和loss梯度,然后分發給其他GPU去計算參數梯度,之后得到這些參數的梯度后再去更新參數,等下次需要其它GPU了再分發更新好的參數。
這是一個悲傷的故事,首先「單進程多線程」就似乎已經注定的結局,Python的全局解釋鎖給這些附屬的GPU戴上了沉沉的牢拷,其他GPU想奮起反抗,但是DP里面只有一個優化器Optimizer,這個優化器Optimizer只在Master GPU上進行參數更新,當環境不再不在改變的時候,其它GPU選擇了躺平,當GPU:0忙前忙后去分發數據、匯總梯度,更新參數的時候,其它GPU就靜靜躺著。
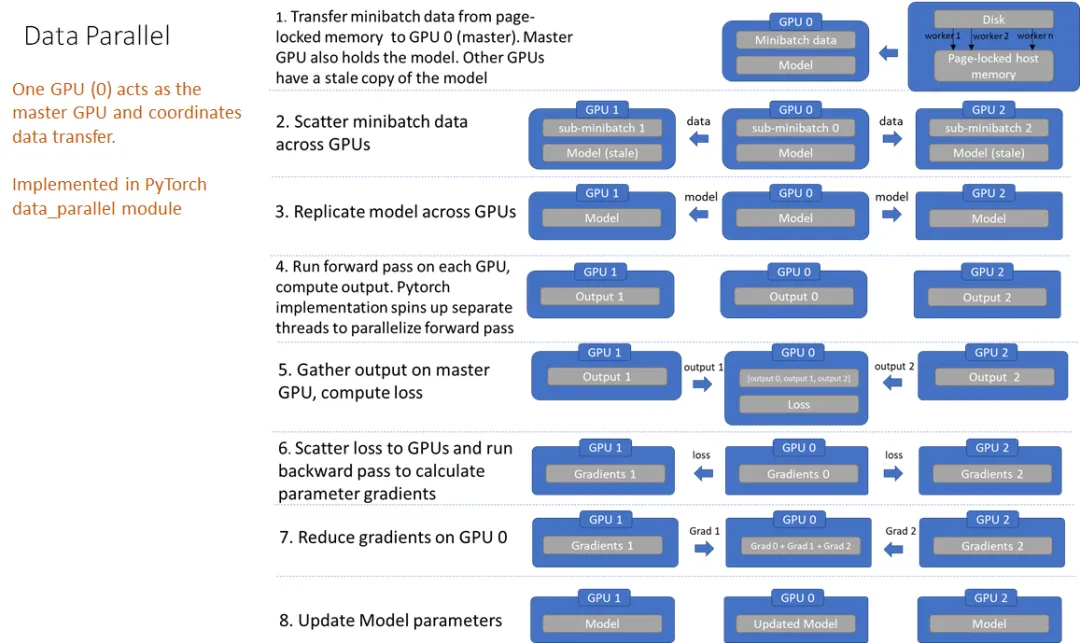
DataParallel采用的是Parameter Server并行架構,在實現多GPU或多節點并行訓練時,存在一些固有的局限性:
- 通信開銷大:每個「計算節點」在每次迭代中都需要與參數服務器進行多次通信,以獲取最新的參數更新并將計算的梯度發送回去。這種頻繁的通信會導致網絡帶寬成為瓶頸,尤其是當模型參數量大且GPU數量眾多時,通信延遲和帶寬消耗會顯著影響整體訓練速度。
- 負載不均衡:其中一個GPU被指定為Master GPU,負責匯總梯度和廣播更新等,Master GPU可能會承擔額外的通信和計算負擔,導致負載不均衡。這不僅會影響該GPU的計算效率,也可能拖慢整個訓練過程的速度。同時導致GPU利用率不足。
- 僅支持單機多卡模式,無法實現多機多卡訓練。
(2) DistributedDataParallel(DDP)
DDP采用多進程架構,賦予了每個GPU更多的自由,支持多機多卡分布式訓練。每個進程都擁有自己的優化器Optimizer,可獨立優化所有步驟。每個進程中在自己的GPU上計算loss,反向計算梯度。
在DDP中,不存在所謂的Master GPU,所有GPU節點地位平等,共同參與訓練過程的每一個環節。每個GPU都會計算loss和梯度,然后通過高效的通信協議(如AllReduce)與其它GPU同步梯度,確保模型參數的一致性。
實現代碼如下:
# 初始化分布式環境
-----------------------------------------------------------------------------
# 1) 指定通信后端為nccl(NVIDIA Collective Communications Library),
# 這是針對GPU集群優化的高性能通信庫
torch.distributed.init_process_group(backend='nccl')
# 2)從命令行接收local_rank參數,該參數表示當前GPU在本地機器上的編號,用于后續的設備設置
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1, type=int)
args = parser.parse_args()
# 3) 設置cuda
# 根據local_rank設置當前進程使用的GPU設備,創建對應的device對象
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
-----------------------------------------------------------------------------
# 模型設置
# 將模型封裝進DistributedDataParallel,
# 指定模型運行在local_rank對應的GPU上,同時將模型移動到相應的設備
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
model.to(device)
-----------------------------------------------------------------------------
# Dataset設置
Test_data = FunDataset(args.input)
# 創建DistributedSampler,用于在分布式環境中對數據集進行采樣,確保每個進程處理不同的數據子集
test_sample = torch.utils.data.distributed.DistributedSampler(Test_data)
# 使用DataLoader加載數據,指定sampler為DistributedSampler,確保數據的分布式加載和處理
test_data_dataset = DataLoader(dataset=Test_data, batch_size=args.batch_size, shuffle=False,
collate_fn=Test_data.collate__fn,
drop_last=False,sampler=test_sample) # , pin_memory=True)
-------------------------------------------------------------------------------
# 運行的時候需要設置
for epoch in range(num_epochs):
# 在每個epoch開始時,更新DistributedSampler的epoch,確保數據的隨機重排
trainloader.sampler.set_epoch(epoch)
# 遍歷數據集,前向傳播計算預測值,計算損失,執行反向傳播和參數更新
for data, label in trainloader:
prediction = model(data)
loss = loss_fn(prediction, label)
loss.backward()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.step()DDP解決了DP模式下存在的效率瓶頸和資源分配不均等問題,每個GPU節點都具備獨立的數據加載能力,無需等待主GPU的數據分發。并且,可執行模型訓練的每一環節,包括前向傳播、損失計算和反向傳播,實現了真正的并行計算。
引入了DistributedSampler,用于在分布式環境中均勻分割數據集,確保每個GPU處理的數據互不重疊,避免了數據冗余和計算浪費。
采用了高效的Ring All-Reduce算法作為通信后端,用于梯度的聚合和參數的同步。在每個訓練迭代結束時,每個GPU計算出自己的梯度后,通過環形網絡結構與其他GPU進行梯度交換,最終每個GPU都能獲取到所有GPU的梯度信息。
針對DP來說,Dataloder的batch_size是針對所有卡訓練batch_size的和,例如10卡,每張卡batch_size是20,那么就要指定batch_size為200。針對DDP來說,batch_size就是每張卡所訓練使用的batch_size為20。
2.模型并行MP
模型并行(Model Parallelism)通常用于解決單節點內存不足的問題。以GPT-3為例,該模型擁有1750億參數,如果每個參數都使用32位浮點數表示,那么模型需要占用700GB(即175G× 4 Bytes)內存。即使使用16位浮點數表示,每個模型副本也需要350GB的內存。單個加速卡(如NVIDIA H100)的顯存容量(80GB)顯然不足以容納整個模型。
模型并行從計算圖的切分角度,可以分為以下兩種:
- 按模型的「layer層切分」到不同設備,即「層間并行或算子間并行」(Inter-operator Parallelism),也稱之為「流水線并行」(Pipeline Parallelism,PP)。
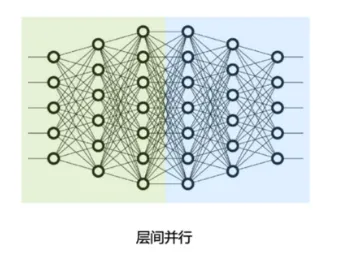
- 將計算圖層內的「參數切分」到不同設備,即「層內并行或算子內并行」(Intra-operator Parallelism),也稱之為「張量并行」(Tensor Parallelism,TP)。
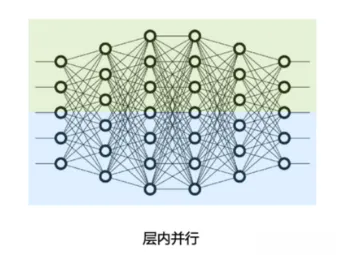
(1) 張量并行
張量并行(Tensor Parallelism,TP)旨在通過將模型參數和中間張量在多個設備(如GPU)之間進行切分,以克服單個設備內存限制的問題。
張量并行要解決的兩個核心問題:如何合理地將參數切分到不同設備,以及如何確保切分后的計算結果在數學上保持一致。
大語言模型都是以Transformer結構為基礎,Transformer結構主要由以下三種算子構成:
- 嵌入式表示(Embedding)
- 矩陣乘法(MatMul)
- 交叉熵損失(Cross Entropy Loss)
這三種類型的算子均需要設計對應的張量并行策略,才可以將參數切分到不同設備。
① 嵌入式表示(Embedding)
對于Embedding算子,總詞表數很大,將導致單計算設備顯存無法容納Embedding層參數。
例如,詞表數為64000,嵌入表示維度為5120,使用32位浮點數表示,整層參數需要的顯存大約為6400x5120x4/1024/1024=1250MB,加上反向傳播時的梯度存儲,總計近2.5GB,這對于顯存有限的設備而言是一個嚴峻挑戰。
為了解決這一問題,可以采用張量并行策略,將Embedding層的參數按詞維度切分,每個計算設備只存儲部分詞向量,然后通過匯總各個設備上的部分詞向量,從而得到完整的詞向量。
如下圖所示是單節點Embedding和兩節點張量并行的示意圖。
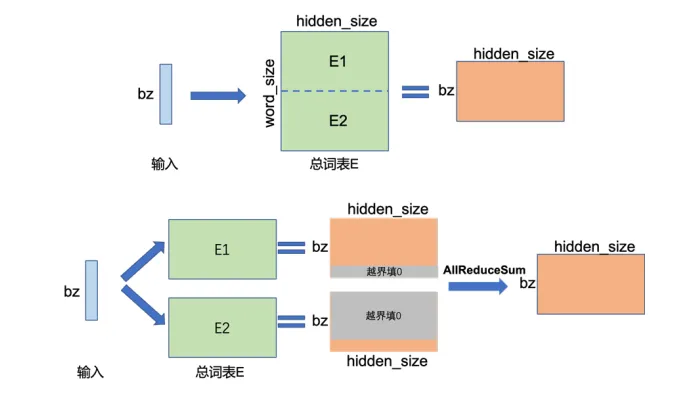
在單節點上,執行Embedding操作,bz是批次大小(batch size),Embedding的參數大小為[word_size, hidden_size],計算得到[bz,hidden_size]張量。
在兩節點上,可以將Embedding層參數按詞維度切分為兩半,每臺設備存儲一半的詞向量,即參數大小為[word_size/2, hidden_size],分別存儲在兩個設備上。在前向傳播過程中,每個設備根據輸入的詞匯ID查詢自身的詞向量。如果無法查到,則該詞的表示為0。各設備計算得到的詞向量結果形狀為[bz, hidden_size],由于詞匯可能被分割在不同設備上,需要通過跨設備的All Reduce Sum操作,將所有設備上的詞向量結果進行匯總求和,以得到完整的詞向量表示。可以看出,這里的輸出結果和單節點執行的結果一致。
② 矩陣乘法(MatMul)
矩陣乘的張量模型并行充分利用矩陣分塊乘法的原理。
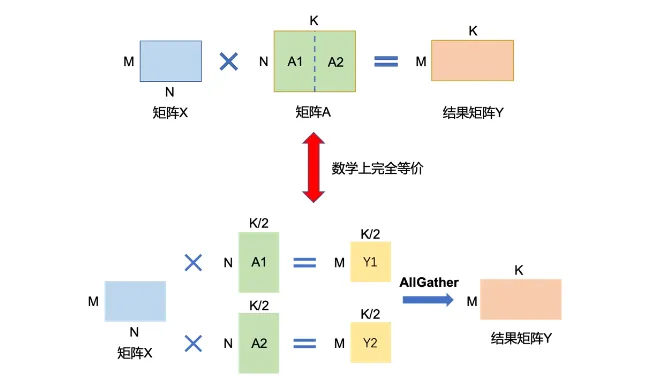
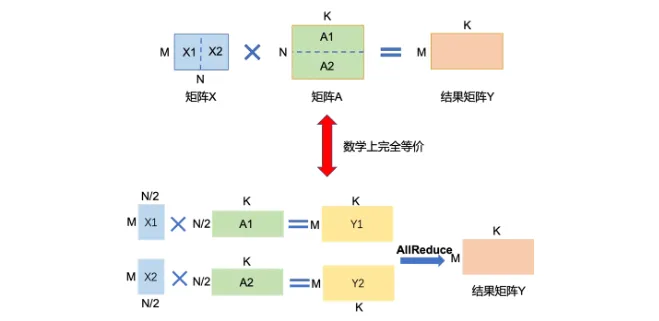
例如,要實現矩陣乘法Y=X*A。其中,X是維度為MxN的輸入矩陣,A是維度為NxK的參數矩陣,Y是輸出,維度為MxK。
當參數矩陣A的尺寸過大,以至于單個卡無法容納時,可以將參數矩陣A切分到多張卡上,并通過集合通信匯集結果,保證最終結果在數學計算上等價于單卡計算結果。
這里A切分方式包括按列切塊和按行切塊兩種。
「按列切塊」。如下圖所示,將參數矩陣A按列方向切分為A1和A2。將子矩陣A1和A2分配到兩張卡上。在計算過程中,每張卡將執行獨立的矩陣乘法,即卡1計算Y1=X*A1,卡2計算Y2=X*A2。計算完成后,通過All Gather操作,每張卡將獲取另一張卡上的計算結果。在收集到所有計算結果后,每張卡將拼接它們收到的片段,形成完整的Y矩陣。最終,無論在哪張卡上查看,Y都將是一個完整的MxK矩陣,與單卡計算的結果完全等價。
「按行切塊」。如下圖所示,將參數矩陣A按列方向切分為A1和A2。為了與按行切塊的A矩陣相乘,輸入矩陣X(尺寸為MxN)也需要按列方向切分為X1和X2。將子矩陣A1和A2分別分配到兩張卡上。同時,將X1和X2也分別分配到對應的卡上。每張卡將執行獨立的矩陣乘法,即卡1計算Y1=X1*A1,卡2計算Y2=X2*A2。計算完成后,通過All Reduce Sum操作,每張卡將匯總另一張卡上的計算結果。在收集到所有計算結果后,每張卡將整合它們收到的片段,形成完整的Y矩陣的行。同理,參數矩陣A按行切塊的張量模型并行策略,通過巧妙地切分矩陣和利用多卡的計算能力,有效地解決了單卡顯存限制的問題,同時確保了計算結果的數學等價性。
③ 交叉熵Loss計算(CrossEntropyLoss)
分類網絡中,最后一層通常使用softmax函數結合交叉熵損失(CrossEntropyLoss)來評估模型的預測結果與真實標簽之間的差距。然而,當類別數量非常大時,單個GPU卡可能無法存儲和計算logit矩陣,導致顯存溢出。為了解決這一問題,可以采用張量并行策略,將logit矩陣和標簽按類別數維度切分,通過中間結果的通信,計算出全局的交叉熵損失。具體的計算步驟如下:
首先計算softmax值。其中,p表示張量并行的設備號。
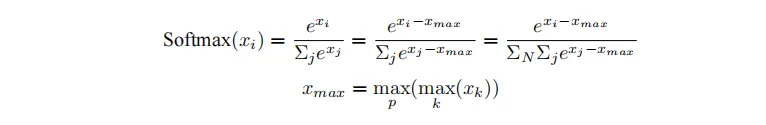
得到Softmax結果之后,同時對標簽Target按類別切分,每個設備得到部分損失,最后再進行一次通信,得到所有類別的損失。
具體的計算步驟如下圖所示。

(2) 流水線并行
所謂流水線并行,就是由于模型太大,無法將整個模型放置到單張GPU卡中,因此,將模型的不同層放置到不同的計算設備,降低單個計算設備的顯存消耗,從而實現超大規模模型訓練。
流水線并行PP(Pipeline Parallelism),是一種最常用的并行方式,將模型的各個層分段處理,并將每個段分布在不同的計算設備上,使得前后階段能夠流水式、分批進行工作。
如下圖所示是一個包含四層的深度學習模型,被切分為三個部分,并分別部署在三個不同的計算設備(Device 0、Device 1 和 Device 2)上。
其中,第一層(Layer 1)放置在Device 0上。第二層(Layer 2)和第三層(Layer 3)放置在Device 1上。第四層(Layer 4)放置在Device 2上。
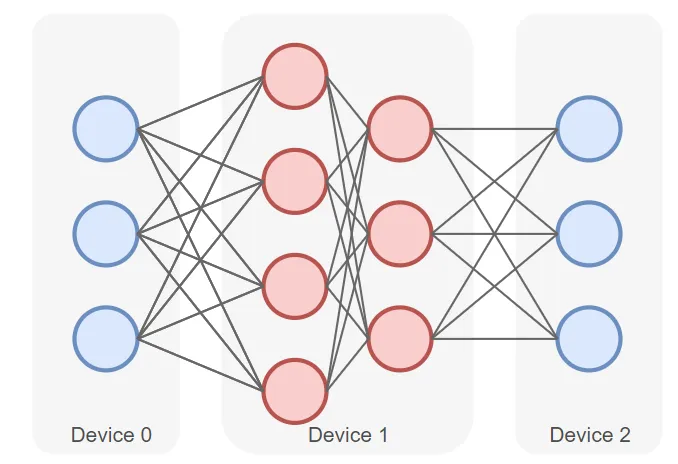
前向計算過程中,輸入數據首先在 Device 0 上通過Layer 1的計算得到中間結果,并將中間結果傳輸到Device 1,再繼續在Device 1上計算得到Layer 2 和 Layer 3的輸出,并將模型Layer 3的輸出結果傳輸到Device 2。在 Device 2 上,數據經過Layer 4 的計算,得到最終的前向計算結果。反向傳播過程類似。
最后,各個設備上的網絡層會使用反向傳播過程計算得到的梯度更新參數。由于各個設備間傳輸的僅是相鄰設備間的輸出張量,而不是梯度信息,因此通信量較小。
通過將模型切分為多個部分并分布到不同的計算設備上,流水線并行策略有效地擴展了可用于訓練的GPU顯存容量。這意味著原本無法在單一GPU上裝載的大模型,現在可以通過類似流水線的方式,利用更多GPU的顯存來承載訓練中的模型參數、梯度、優化器狀態以及激活值等數據,從而實現超大規模模型的高效訓練。
① 樸素流水線并行
當模型規模超過單個GPU的處理能力時,樸素層并行(Naive Layer Parallelism)是一種直觀的并行策略,將模型的不同層分配到不同的GPU上,實現模型的并行化訓練。如下所示是一個4層序列模型:
output=L4(L3(L2(L1(input)))))將其劃分到兩個GPU上:
- GPU1負責計算前兩層:intermediate=L2(L1(input))
- GPU2負責計算后兩層:output=L4(L3(intermediate))
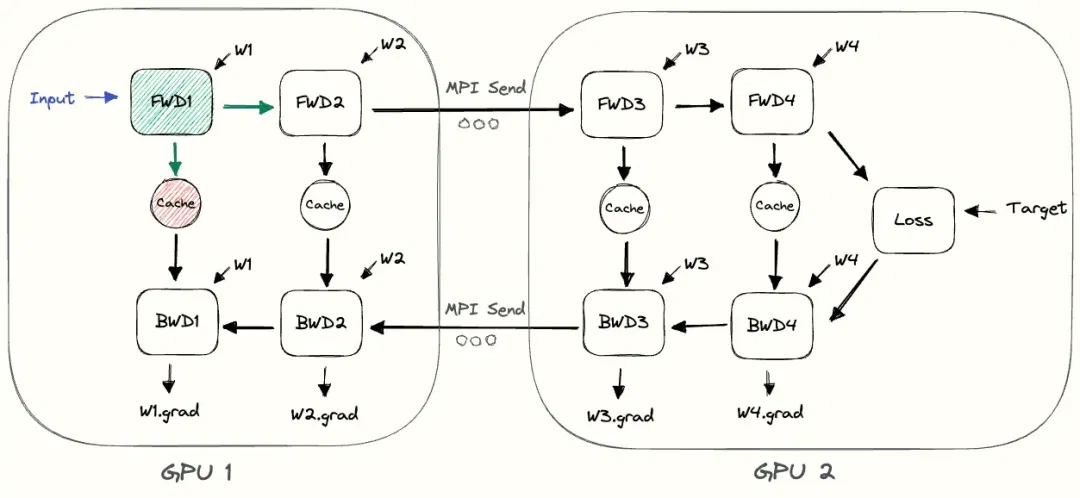
整個樸素層并行前向傳播和后向傳播的過程如上圖所示。GPU1執行Layer 1和Layer 2的前向傳播,并緩存激活(activations),再將Layer 2的輸出(intermediate)發送給GPU2。GPU2接收來自GPU1的中間結果,執行Layer 3和Layer 4的前向傳播,然后計算損失后,開始反向傳播,計算Layer 4和Layer 3的梯度,并將Layer 3的梯度返回給GPU1。GPU1接收梯度,繼續完成Layer 2和Layer 1的反向傳播。
② 樸素層并行的缺點:
- 低GPU利用率:同一時刻,只有其中一個GPU在執行計算,其余GPU處于空閑狀態(又稱氣泡bubble),這導致了計算資源的浪費。
- 計算和通信沒有重疊:在數據傳輸期間,無論是前向傳播的中間結果還是反向傳播的梯度,GPU都處于等待狀態,這進一步降低了計算效率。
- 高顯存占用:GPU1需要保存整個mini-batch的所有激活,直到反向傳播完成。如果mini-batch很大,這將顯著增加顯存的需求,可能超出單個GPU的顯存容量。
③ GPipe流水線并行
GPipe通過引入微批次(Micro-batch)的概念,顯著提高了模型并行訓練的效率。將一個大的mini-batch進一步細分為多個更小的、相等大小的微批次(microbatches),并在流水線并行的框架下獨立地對每個microbatch執行前向傳播和反向傳播。然后將每個mircobatch的梯度相加,就能得到整個batch的梯度。由于每個層僅在一個GPU上,對mircobatch的梯度求和僅需要在本地進行即可,不需要通信。
假設我們有4個GPU,并將模型按層劃分為4個部分,每個部分部署在一個GPU上。樸素層并行的過程如下所示:
由此可以看出,在每一時刻,僅有一個1個GPU工作,并且每個timesep花費的時間也比較長,因為GPU需要跑完整個minibatch的前向傳播。
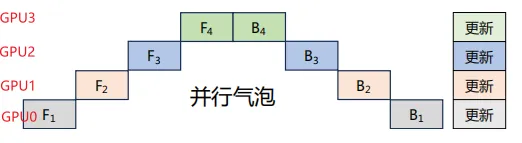
GPipe將minibatch劃分為4個microbatch,然后依次送入GPU0。GPU0前向傳播后,再將結果送入GPU1,以此類推。整個過程如下所示。GPU0的前向計算被拆解為F11、F12、F13、F14,在GPU0中計算完成F11后,會在GPU1中開始計算F21,同時GPU0并行計算F12。
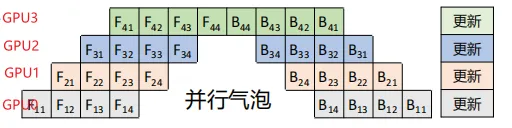
相比于樸素層并行方法,GPipe流水線方法可以有效降低并行氣泡大小。但是GPipe只有當一個Mini-batch(4個Microbatch)中所有的前向傳播計算完成后,才能開始執行反向傳播計算。因此還是會產生很多并行氣泡,從而降低了系統的并行效率。每個GPU需要緩存4份中間激活值。
④ PipeDream流水線并行
PipeDream流水線并行采用1F1B策略,即一個前向通道和一個后向通道,采用任務調度機制,使得下游設備能夠在等待上游計算的同時執行其他可并行的任務,從而提高設備的利用率。
1F1B策略分為非交錯式和交錯式兩種方式調度方式。如下圖所示。
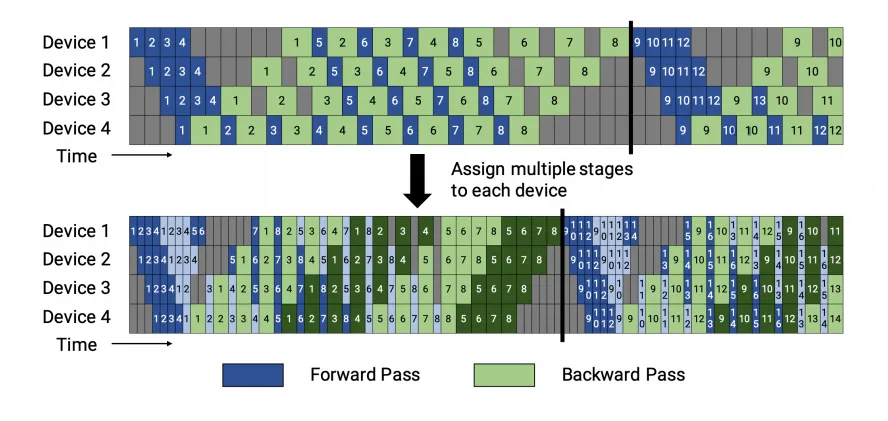
1F1B非交錯式調度分為三個階段:
- 熱身階段:在這個階段,計算設備執行不同數量的前向計算,為后續階段做準備。
- 前向-后向階段:設備按照順序執行一次前向計算,緊接著進行一次后向計算。這一階段循環執行,直到所有microbatch被處理完畢。
- 后向階段:在完成所有前向計算后,設備執行剩余的后向計算,直至所有計算任務完成。
1F1B交錯式調度要求microbatch的數量是流水線階段的整數倍。 每個設備不再僅負責連續多個層的計算,而是可以處理多個層的子集,這些子集被稱為模型塊。例如:
- 在傳統模式下,設備1可能負責層1-4,設備2負責層5-8。
- 在交錯式模式下,設備1可以處理層1、2、9、10,設備2處理層3、4、11、12,以此類推。 這樣,每個設備在流水線中被分配到多個階段,可以并行執行不同階段的計算任務,從而更好地利用流水線并行的優勢。
3.混合并行HP
在進行上百億/千億級以上參數規模的超大模型預訓練時,通常會組合上述(數據并行、張量并行、流水線并行)多種并行技術一起使用。常見的分布式并行技術組合方案如下。
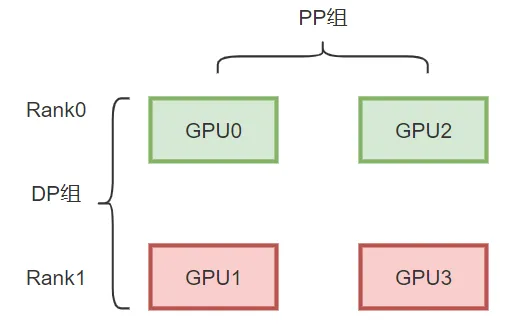
(1) DP+PP
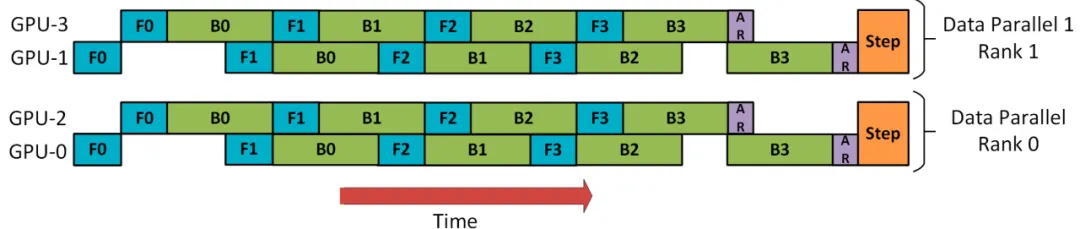
DP rank 0看不到GPU2, DP rank 1看不到GPU3,對于DP,只有GPU 0和1提供數據,就好像只有2個GPU一樣。GPU0使用PP將其部分負載卸載到GPU2,同樣的GPU1使用PP將其部分負載卸載到GPU3。
由于每個維度至少需要2個GPU,因此這里至少需要4個GPU。
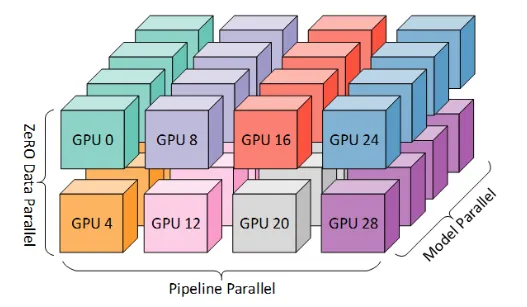
(2) 3D并行(DP+PP+TP)
3D并行是由數據并行(DP)、張量并行(TP)和流水線并行(PP)組成。由于每個維度至少需要2個 GPU,因此這里至少需要8個GPU。
四、分布式訓練并行策略選擇
1.單節點并行化策略
當單個GPU可以裝入整個模型時:
- DDP (Distributed DataParallel)
- ZeRO
當單個GPU無法裝入整個模型時:
- Pipeline Parallel (PP)
- Tensor Parallel (TP)
- ZeRO
當單個GPU無法裝入模型的最大層時:
- 使用Tensor Parallel(TP),因為僅靠PipelineParallel(PP)不足以容納大型層。
- ZeRO
2.多節點并行化策略
具有快速的節點間連接時:
- ZeRO
- 組合使用PP、TP和DP
節點間連接速度較慢且GPU內存不足時:
- 組合使用PP、TP、DP和ZeRO