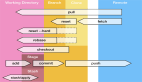
快速分析日志的小抄
日志解析命令是強大的工具,可用于執行各種任務,例如在日志中查找模式、分析網絡流量、提取特定字段等。這些任務對于故障排除、監控和維護系統日志至關重要。
 圖片
圖片
01 在文本文件中搜索特定模式
處理大型日志時,通常需要搜索特定模式或關鍵字來幫助識別系統中的問題或行為。最常用的工具是 grep。
- 示例:
grep "ERROR" /var/log/syslog該命令在 syslog 中搜索包含 "ERROR" 的行。
還可以使用正則表達式進行更復雜的模式匹配:
grep -E "ERROR|WARN" /var/log/syslog該命令查找包含 "ERROR" 或 "WARN" 的行。
02 分析網絡數據包
分析網絡流量生成的日志(如數據包捕獲),可以使用 tcpdump 或 Wireshark 之類的工具。通常會將這些工具與日志解析結合起來分析網絡行為。
- 使用 tcpdump 的示例:
tcpdump -r network_traffic.pcap | grep "192.168.1.10"這里,tcpdump 讀取數據包捕獲文件,grep 搜索與 IP 192.168.1.10
對于更詳細的分析,你可以結合時間戳、源和目標 IP 以及協議字段。
03 從分隔日志中解析字段
日志通常包含結構化數據,如 CSV 或制表符分隔的字段。你可以使用 awk 或 cut 來提取這些日志中的特定字段。
- 使用 awk 的示例:
awk -F, '{print $2, $5}' access.log此命令從逗號分隔的日志文件中提取第 2 和第 5 個字段。
- 使用 cut,你可以指定分隔符和字段:
cut -d ',' -f 2,5 access.log這兩個命令對于處理大型日志非常高效。
04 替換文件中的字符串
有時你需要更新日志或標準化日志格式,通過替換特定的字符串來實現。sed 命令非常適合這類操作。
- 示例:
sed 's/DEBUG/INFO/g' application.log此命令將 application.log 中所有的 "DEBUG" 替換為 "INFO"。
你也可以使用正則表達式結合 sed 來替換更復雜的模式。
05 排序文件
當你需要對日志條目進行排序時,sort 可以根據時間戳、IP 地址或其他標準對日志進行排序。
- 示例:
sort -k 3,3n access.log該命令基于第 3 個字段的數字順序對日志條目進行排序,假設它包含時間戳或像 IP 地址這樣的數值。
- 逆序排序:
sort -r access.log這有助于優先查看最新的條目。
06 逐行比較文件顯示差異
要比較日志文件之間的變化,可以使用 diff 命令。這對于比較不同時間段或服務器環境的日志非常有用。
- 示例:
diff old_log.log new_log.log此命令逐行顯示兩個日志文件之間的差異。
你還可以添加選項忽略某些變化,例如忽略空格差異:
diff -w old_log.log new_log.log07 額外技巧:通過管道組合命令
Unix/Linux 系統的強大之處在于可以使用管道 (|) 將多個命令組合起來。例如:
- 示例:
grep "ERROR" /var/log/syslog | awk '{print $1, $3}' | sort | uniq -c | sort -nr這個命令:
- 在 syslog 中搜索 "ERROR",
- 提取第一列和第三列(可能是時間戳和錯誤類型),
- 對提取的數據進行排序,
- 統計唯一的出現次數(uniq -c),
- 最后按照出現次數逆序排序(sort -nr),顯示最頻繁的錯誤。