GPU 內存,為何如此重要?
Hello folks,我是 Luga,今天我們繼續來聊一下人工智能生態相關技術 - 用于加速構建 AI 核心算力的 GPU 硬件技術。
隨著人工智能、渲染、仿真技術以及支持高動態范圍(HDR)的 4K 顯示器逐漸進入主流市場,GPU(圖形處理單元)的內存需求也在迅速增長。這一需求的增加源自多個方面,包括更復雜和龐大的模型與數據集、多任務工作流程、多個顯示器上顯示的高分辨率內容以及團隊協作等因素。
在現代專業工作環境中,GPU 內存的重要性比以往任何時候都更為突出。尤其是工程、設計、影視制作和科學計算等領域的工作流程,對大容量 GPU內存的依賴不斷增加……

什么是 CPU 內存 ?
GPU 內存是 GPU 上的專用內存,主要用于存儲臨時數據緩沖區。這些緩沖區在 GPU 執行復雜數學運算、圖形渲染和視覺數據處理時起著關鍵作用。通常而言,執行特定指令前,GPU 通常需要在內存中存儲大量數據,包括幾何信息、紋理數據和計算參數。高效的數據存儲與管理是 GPU 快速處理任務的核心。
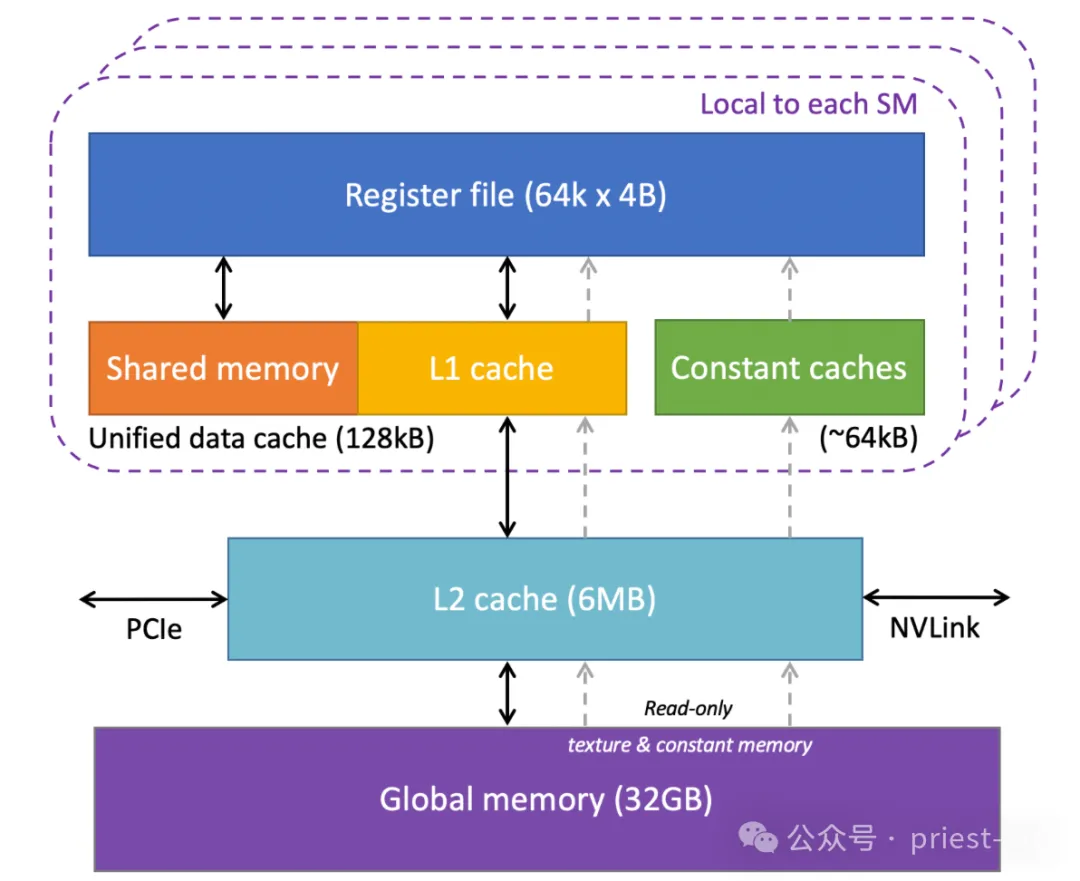
NVIDIA Tesla V100 GPU 內存結構
在實際應用場景中,系統通常需要將大量小型數據包從 CPU 或全局內存傳輸到 GPU 內存進行處理。如果 GPU 內存資源不足,數據傳輸頻率和處理速度會受到影響,導致性能瓶頸和延遲。這種情況尤其常見于高分辨率圖像處理、3D 建模和復雜的實時渲染任務。
值得注意的是,GPU 內存是獨立于系統 RAM 的專用內存空間,專為圖形和計算任務優化。它在快速存儲和訪問數據中扮演著重要角色,尤其是在高性能計算和實時應用中,對整體計算效率和響應速度有直接影響。
有時,在處理人工智能(AI)和機器學習(ML)模型等需要大量數據的復雜工作負載時, GPU 內存的使用要求常被低估。AI/ML 模型通常需要處理龐大數據集和復雜算法,此時內存資源的有效利用至關重要。GPU 內存的使用效率和帶寬常是影響系統性能的關鍵瓶頸之一。
對于這些高強度計算任務,GPU 不僅需要大容量內存來存儲數據,還需要足夠的內存帶寬以確保數據在處理器與內存間的高速傳輸。因此,內存容量和帶寬在處理 AI、深度學習模型及其他繁重工作負載時至關重要。隨著技術的發展,工作負載對 GPU 內存的需求持續增長,這強調了在設計和使用 GPU 時充分考慮內存資源分配和管理的重要性。
常見的 GPU 內存解析
在云計算體系中,“內存”作為硬件系統的基石,為各類應用提供了存儲和處理數據的空間。從龐大的數據中心到微小的嵌入式系統,內存的性能直接影響著整個系統的響應速度和處理能力。無論是大數據分析中海量數據的快速處理,人工智能模型的實時訓練和推理,還是物聯網設備對實時性的嚴苛要求,高效的內存利用都是提升系統性能的關鍵。
通常而言,在 GPU 內存體系中,不同類型的內存具有各自的特性和適用場景。合理地選擇和利用這些內存類型,對于提升應用程序的性能至關重要。
在深入研究 GPU 中的各種內存類型之前,首先需要明確內存的基本分類。通常,在討論內存時,我們會將其分為兩種主要類型:物理內存和邏輯內存。這一區分在理解 GPU 內存架構以及如何優化其使用時至關重要。
1. 物理內存
通常指的是實際存在于硬件中的內存,包括顯卡上的 VRAM(視頻隨機存取存儲器)以及其他存儲組件。這種內存是真實存在的硬件資源,決定了 GPU 能夠直接存儲和訪問數據的容量。物理內存的大小直接影響了 GPU 在處理大量數據時的能力,尤其是在運行復雜的圖形任務、訓練深度學習模型或者執行大規模計算時,物理內存的容量越大, GPU 能夠處理的數據集就越大,從而減少內存溢出和性能瓶頸的發生。
2. 邏輯內存
邏輯內存則是從編程和軟件層面上定義的內存。它并不與物理內存一一對應,而是通過抽象層次為開發者提供了一種管理內存資源的方式。在 GPU 編程中,邏輯內存的概念包括不同類型的存儲區域,例如寄存器、共享內存、全局內存和本地內存等。每種邏輯內存有著不同的訪問速度、容量和適用場景,開發者在編寫代碼時需要根據具體任務和需求,合理選擇和管理這些邏輯內存,以最大化性能。
這種對內存的劃分幫助我們在理解 GPU 工作機制時,明確硬件資源和軟件管理之間的區別。物理內存提供了硬件層面的基礎,而邏輯內存則通過編程模型來合理管理和調度這些資源。優化應用程序的性能往往需要充分理解這兩者之間的關系,確保物理內存得到高效利用,同時最大限度地發揮邏輯內存的優勢,避免資源浪費和性能瓶頸。
接下來,我們先來看一下 GPU 的邏輯內存架構圖,具體可參考如下所示:
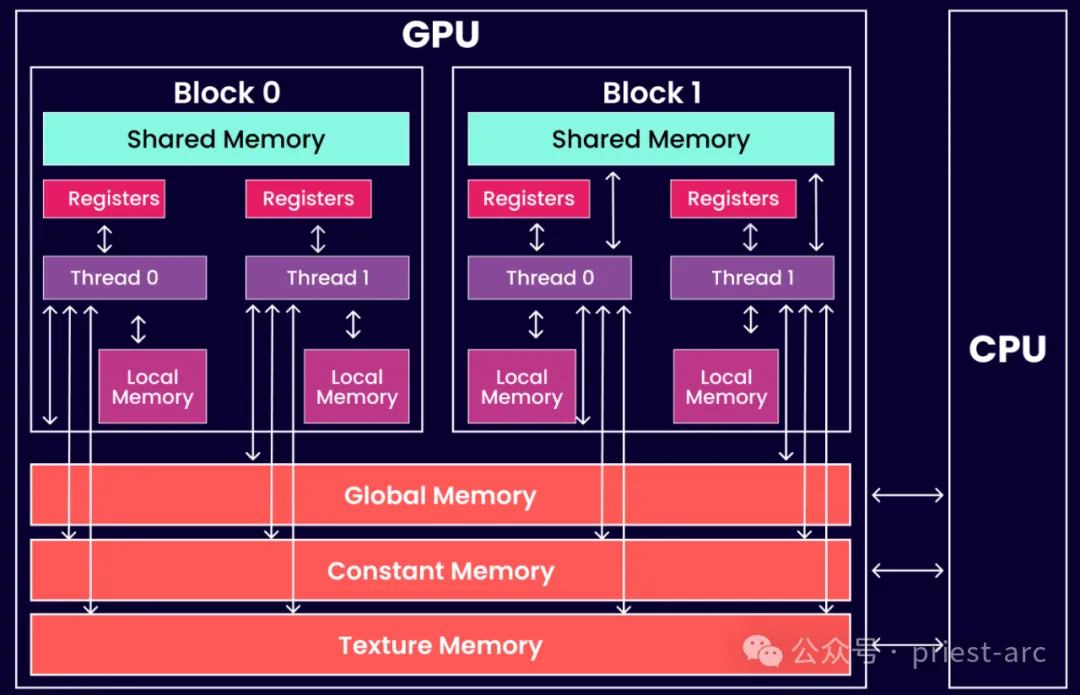
(1) 共享 GPU 內存
當 GPU 的 VRAM(視頻內存)不足時,系統會調用另一種內存類型來補充。這種內存類型通常是指共享內存(Shared Memory),在 CUDA 編程模型中發揮著重要作用。多個線程可以在同一 GPU 塊中共享這些 CUDA 內存空間,從而在處理資源密集型任務時提高效率。
共享內存的特點是其生命周期與創建它的塊(Block)相同,也就是說,一旦該塊結束執行,分配給共享內存的數據也會被釋放。
共享內存的主要優勢在于:提供了一種比全局內存更快的訪問方式,允許同一線程塊中的多個線程同時訪問和共享數據,而不必每次都通過較慢的全局內存傳輸。這種機制在處理大量數據時,能夠極大地減少內存訪問延遲,從而提升整體計算效率。因此,在并行計算和資源密集型任務(如科學計算、圖像處理和機器學習)中,共享內存的合理利用可以顯著加快計算速度。
然而,GPU 的共享內存是有限的資源,且通常分配給每個線程塊的共享內存量是固定的。這意味著,開發者在編寫 CUDA 程序時,必須仔細規劃內存的分配和使用,以避免超出共享內存的容量限制。如果任務需要的內存超過了共享內存的容量,GPU 就不得不依賴速度較慢的全局內存,可能導致性能下降。
(2) 注冊 GPU 內存
在大多數情況下,訪問寄存器的指令不消耗時鐘周期。然而,讀后寫依賴關系和銀行沖突可能導致延遲。具體而言,寫后依賴項的讀后延遲大約為 24 個時鐘周期。對于配備 32 個內核的較新 CUDA 設備來說,可能需要多達 768 個線程才能完全隱藏這種延遲。
除了讀寫延遲之外,寄存器壓力也會嚴重影響應用程序性能。當任務所需的寄存器不足時,就會發生寄存器壓力。這種情況下,數據將“溢出”到本地內存中進行存儲,從而導致性能下降。
有效管理寄存器使用對于優化 CUDA 應用程序的性能至關重要。通過仔細分配線程和優化內存訪問模式,可以減輕這些潛在的性能瓶頸。
(3) 本地 GPU 內存
本地 GPU 內存是由操作系統內核分配的靜態內存,在 CUDA 編程中,此類內存被視為線程的本地內存。每個線程只能訪問其自身分配的本地內存。這種內存訪問速度較慢,因為它通過寄存器或共享內存進行操作,效率不如直接使用寄存器。
在實際應用中,本地內存的使用會導致性能下降,尤其是在需要頻繁數據訪問的情況下。因此,在 CUDA 編程中,優化內存使用、盡量減少對本地內存的依賴,對于提升程序執行效率至關重要。
當然,我們也可以將上述內存劃分為其他形式,比如,紋理內存(Texture Memory)、常量內存(Constant Memory)以及其他內存等。
而對于 GPU 的物理內存架構圖,可參考如下:
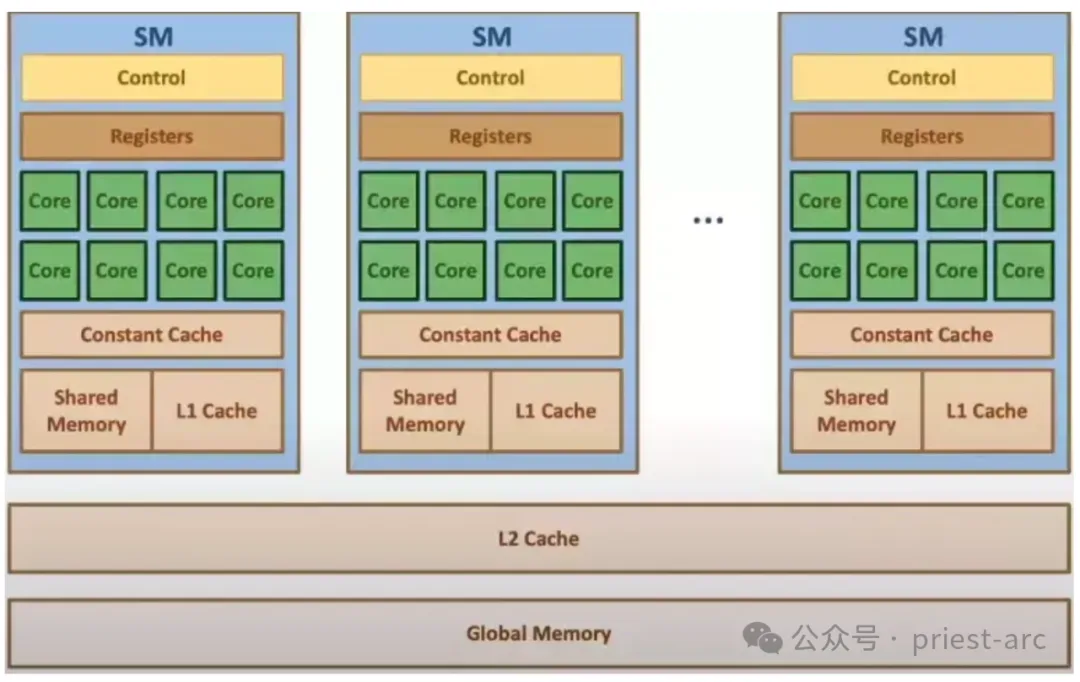
上述架構圖所述與塊和線程的關系非常相似,但在這里我們討論的是流式多處理器(SM)和流式處理器(SP)。每個 SM 都擁有自己獨立的共享內存、緩存、常量內存和寄存器資源,這些資源僅供該 SM 內部的線程使用。然而,所有 SM 之間共享相同的全局內存資源,所有線程都可以訪問該內存。
GPU 內存常用場景解析
在 GPU 中,內存帶寬是決定其在處理內核和內存之間數據傳輸速度的關鍵因素。內存帶寬可以通過兩種主要方式來衡量:一是內存與計算內核之間的數據傳輸速度,二是連接這兩者之間的總線數量和帶寬。
內存帶寬對 GPU 的性能有著深遠的影響,直接影響到各種任務的處理效率。例如,在進行計算密集型任務時,如大規模的機器學習(ML)項目、醫療影像分析或高端游戲,內存帶寬的寬度會顯著影響計算的生產力和任務的執行速度。內存帶寬越大,GPU 能夠更高效地傳輸和處理數據,從而提高整體計算性能和響應速度。
對于復雜的任務,如神經網絡的訓練和推斷,一個擁有更寬內存帶寬的 GPU 可以避免數據傳輸成為性能瓶頸。大規模的 ML 項目通常需要處理大量的權重和激活值,這些數據需要在計算內核和內存之間迅速傳輸。更高的內存帶寬意味著 GPU 能夠在并行處理時更有效地訪問和利用數據,提升計算的吞吐量和效率。
此外,不同類型的應用對內存帶寬的需求也有所不同。例如,圖像和視頻處理相關的機器學習項目(如圖像識別、對象檢測等)通常需要較高的內存帶寬,因為這些任務涉及大量的視覺數據處理和高頻率的數據傳輸。足夠的內存帶寬可以確保 GPU 能夠高效地處理和存儲大量的視覺數據,避免由于帶寬不足而造成的數據傳輸延遲。
相比之下,涉及聲音處理或自然語言處理(NLP)的任務通常對內存帶寬的需求較低。這些工作負載通常涉及的數據量較小,因此可以在較低帶寬的 GPU 上有效處理,而不會造成明顯的性能瓶頸。盡管如此,足夠的內存帶寬仍然能夠優化這些應用的處理效率和響應速度。
因此,毫無疑問地講,內存帶寬在 GPU 的性能表現中起著至關重要的作用。其寬度直接影響到數據傳輸的速度和計算的效率,尤其在處理高數據量和高計算需求的任務時尤為重要。選擇適合的 GPU時,了解內存帶寬的要求可以幫助確保計算資源的有效利用,并優化應用程序的整體性能。
Reference :
- [1] https://www.engineering.com/why-gpu-memory-matters-more-than-you-think/
- [2] https://www.microway.com/hpc-tech-tips/gpu-memory-types-performance-comparison/