LLM仍然不能規劃,刷屏的OpenAI o1遠未達到飽和
規劃行動方案以實現所需狀態的能力一直被認為是智能體的核心能力。隨著大型語言模型(LLM)的出現,人們對 LLM 是否具有這種規劃能力產生了極大的興趣。
最近,OpenAI 發布了 o1 模型,一舉創造了很多歷史記錄。o1 模型擁有真正的通用推理能力。在一系列高難基準測試中展現出了超強實力,相比 GPT-4o 有巨大提升,讓大模型的上限從「沒法看」直接上升到優秀水平,不專門訓練直接數學奧賽金牌,甚至能在博士級別的科學問答環節上超越人類專家。
那么,o1 模型是否具備上述規劃能力?
2022 年,來自亞利桑那州立大學(ASU)的研究團隊開發了評估 LLM 規劃能力的基準 ——PlanBench。現在,亞利桑那州立大學研究團隊全面審視了當前 LLM 在 PlanBench 上的表現,包括 o1 模型。值得注意的是,雖然 o1 在基準測試上性能超過了競爭對手,但它還遠未達到飽和狀態。

- 論文標題:LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench
- 論文地址:https://arxiv.org/pdf/2409.13373
SOTA 性能的 LLM 仍然不會規劃
對于 vanilla LLM(通過 RLHF 微調的 Transformer 模型)來說,PlanBench 基準仍然充滿挑戰,即使在最簡單的測試集上,模型表現也不佳。
下表為當前和前一代 LLM 的結果,測試領域包括 Blocksworld 和 Mystery Blocksworld(混淆版本),其中前者是在 600 個 3 到 5 個 block Blocksworld 問題靜態測試集上運行的結果,后者是在 600 個語義相同但語法混淆的實例(稱之為 Mystery Blocksworld)上的運行結果。
在這些模型中,LLaMA 3.1 405B 在常規 Blocksworld 測試中表現最佳,準確率達到 62.6%。然而模型在 Mystery Blocksworld 的表現卻遠遠落后——沒有一個 LLM 在測試集上達到 5%,并且在一個領域上的性能并不能清楚地預測另一個領域的性能。
這種結果揭示了 LLM 本質上仍是近似檢索系統。

更進一步的,作者測試了自然語言提示和 PDDL,發現 vanilla 語言模型在前者上的表現更好。
作者還發現,與之前的說法相反,one-shot 提示并不是對 zero-shot 的嚴格改進。這在對 LLaMA 系列模型的測試中最為明顯。
值得注意的是,基準測試的原始迭代沒有考慮效率,因為 vanilla LLM 生成某些輸出所花費的時間僅取決于該輸出的長度,而與實例的語義內容或難度無關。不過作者也對各個模型的提示成本進行了比較,如表格 4 所示。

從近似檢索到近似推理:評估 o1
標準自回歸 LLM 通過近似檢索生成輸出,但這些模型面臨一個問題,即在 System 1 任務中表現出色,但在對規劃任務至關重要的類似 System 2 的近似推理能力上表現不佳。
回顧之前的研究,從 LLM 中獲取可靠規劃能力的最佳方法是將它們與生成測試框架中的外部驗證器配對,即所謂的 LLM-Modulo 系統。o1 嘗試以不同的方式為底層 LLM 補充類似 System 2 的能力。
據了解,o1 是將底層 LLM(很可能是經過修改的 GPT-4o)結合到 RL 訓練的系統中,該系統可指導私有 CoT 推理軌跡的創建、管理和最終選擇。但是目前確切的細節很少,因此只能推測其確切機制。
作者猜測 o1 和 LLM 之間有兩個主要區別:一個額外的強化學習預訓練階段和一個新的自適應擴展推理程序。無論如何,從現有細節可以看出,該模型在本質上與以前的 LLM 根本不同。
在原始測試集上評估 LRM:作者在靜態 PlanBench 測試集上測試了 o1-preview 和 o1-mini,結果如表 2 所示。其中,600 個 Blocksworld 實例范圍從 3 到 5 個 block 不等,需要 2 到 16 個 step 的規劃才能解決。
結果顯示,o1 正確回答了 97.8% 的這些實例,但在 Mystery Blocksworld 上,o1 沒有保持這種性能,但也遠遠超過了以前的模型,正確回答了 52.8% 的實例。

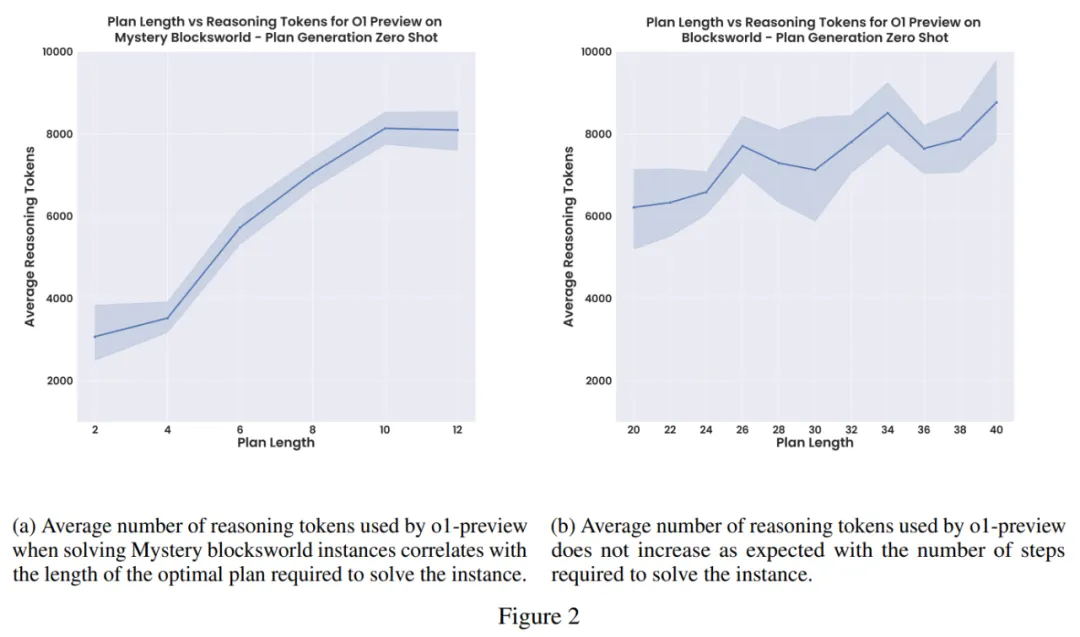
標準 LLM CoT 提示方法很脆弱,無法隨著問題規模的擴大而穩健地擴展。作者在一組較大的 Blocksworld 問題上測試了這些模型(見圖 3)。此集合中的問題長度從 6 到 20 個 block 不等,需要 20 到 40 step 的最佳規劃。
作者發現模型性能從之前報告的 97.8% 迅速下降。事實上,在這組實例中,o1-preview 僅實現了 23.63% 的準確率。可以看出雖然這些模型總體上令人印象深刻,但這表明它們的性能仍然遠不夠穩健。

在不可解決實例上的性能:接著作者修改了測試集中的一些實例,結果如表 3 所示。在 Blocksworld 上,只有 27% 的實例被 o1 正確且明確地識別為無法解決。在所有案例中,有 19% 的模型返回一個點或「empty plan」標記,沒有任何解釋或指示無法解決。在其余 54% 的案例中,模型生成了一個完整的規劃。
在隨機 Mystery Blocksworld 上,這些數字更糟:16% 的案例被正確識別為無法解決,5% 返回了一個「empty plan」,其余 79% 的案例得到了完整規劃的回答。

準確率 / 成本權衡與保證
研究團隊發現:o1-preview 似乎在每個問題使用的推理 token 數量方面受到限制。如果 o1 的正式版本消除了這一限制,可能會提高整體準確性,但也可能導致更不可預測(甚至高得離譜)的推理成本。o1-mini 雖然更便宜,但通常性能較差。