《Python機器學習》作者科普長文:從頭構建類GPT文本分類器,代碼開源
近日,機器學習研究員、暢銷書《Python 機器學習》作者 Sebastian Raschka 又分享了一篇長文,主題為《從頭開始構建一個 GPT 風格的 LLM 分類器》。
文章展示了如何將預訓練的大型語言模型(LLM)轉化為強大的文本分類器。機器之心對文章內容進行了不改變原意的編譯、整理:
為什么要關注分類呢?首先,針對分類任務,對預訓練模型進行微調是一個簡單有效的 LLM 知識入門方式。其次,文本分類有許多商業(yè)應用場景,比如:垃圾郵件檢測、情感分析、客戶反饋分類、主題分類等等。
閱讀完本文,你將找到以下 7 個問題的答案:
1. 需要訓練所有層嗎?
2. 為什么微調最后一個 token,而不是第一個 token?
3. BERT 與 GPT 在性能上有何比較?
4. 應該禁用因果掩碼嗎?
5. 擴大模型規(guī)模會有什么影響?
6. LoRA 可以帶來什么改進?
7. Padding 還是不 Padding?
完整代碼可以從 GitHub 找到:https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/ch06.ipynb
Different categories of finetuning
微調的不同種類
指令微調和分類微調是最常見的語言模型微調方法。指令微調是用特定任務訓練模型,提高它理解和執(zhí)行自然語言提示中所描述任務的能力,如下圖 1 所示。

圖 1:指令微調的兩種場景。上方:模型的任務是判斷文本是否為垃圾郵件;下方:模型的任務是將英文句子翻譯成德語。
在分類微調中,模型被訓練用于識別特定的類別標簽,比如「垃圾郵件」和「非垃圾郵件」。分類任務還包括從圖像中識別不同的植物、給新聞按體育、政治或科技等主題分類,從醫(yī)學影像中區(qū)分良性和惡性腫瘤等等。
不過經(jīng)過分類微調的模型只能判斷類別,不能對輸入的文本作出其他判斷。

圖 2:一個使用 LLM 進行垃圾郵件分類的示例。針對垃圾郵件分類微調的模型在輸入時不需要額外的指令,然而,與指令微調模型相比,它的回答只能是「垃圾郵件」和「非垃圾郵件」。
指令微調的模型通常能夠執(zhí)行更廣泛的任務。我們可以將分類微調的模型視為是高度專業(yè)化的模型,一般來說,開發(fā)一個專用模型比開發(fā)一個在各種任務上表現(xiàn)良好的通用模型更容易。
使用預訓練權重初始化模型
下圖中展示了將通用預訓練 LLM 轉變?yōu)閷iT用于分類任務的 LLM 需要做的修改:
 圖 3:在此跳過步驟 1-5,直接進入步驟 6(將在下一節(jié)開始)。
圖 3:在此跳過步驟 1-5,直接進入步驟 6(將在下一節(jié)開始)。
在做修改之前,讓我們先簡單了解一下正在使用的預訓練 LLM。為簡便起見,假設我們設置了如下代碼來加載該模型:
model = GPTModel (BASE_CONFIG)
load_weights_into_gpt (model, params)
model.eval ()在將模型權重加載到 GPT 后,使用下列文本生成的函數(shù)庫,確保模型生成連貫的文本:
from chapter04 import generate_text_simple
from chapter05 import text_to_token_ids, token_ids_to_text
text_1 = "Every effort moves you"
token_ids = generate_text_simple (
model=model,
idx=text_to_token_ids (text_1, tokenizer),
max_new_tokens=15,
context_size=BASE_CONFIG ["context_length"]
)
print (token_ids_to_text (token_ids, tokenizer))根據(jù)以下輸出,我們可以看到模型生成了連貫的文本,這表明模型權重已正確加載:
Every effort moves you forward.
The first step is to understand the importance of your work讓我們先看看模型是否可以通過指令微調完成垃圾郵件的分類:
text_2 = (
"Is the following text'spam'? Answer with 'yes' or 'no':"
"'You are a winner you have been specially"
"selected to receive $1000 cash or a $2000 award.'"
)
token_ids = generate_text_simple (
model=model,
idx=text_to_token_ids (text_2, tokenizer),
max_new_tokens=23,
context_size=BASE_CONFIG ["context_length"]
)
print (token_ids_to_text (token_ids, tokenizer))模型的輸出如下所示:
Is the following text'spam'? Answer with 'yes' or 'no': 'You are a winner you have been specially selected to receive $1000 cash or a $2000 award.'
The following text'spam'? Answer with 'yes' or 'no': 'You are a winner可以明顯看出模型在準確遵循指令方面遇到了一些挑戰(zhàn)。這是可以預見的,因為它僅經(jīng)過了預訓練,缺乏指令微調。
加入分類頭
我們將原始輸出層(這層的功能是將模型內部生成的隱藏表示轉換為一個包含 50,257 個 tokens 的詞表)替換為一個較小的輸出層,該層映射到兩個類別:0(非垃圾郵件)和 1(垃圾郵件),如下圖 4 所示。

圖 4:此圖展示了如何通過改變架構將 GPT 模型適配為垃圾郵件分類。最初,模型的線性輸出層將 768 個隱藏單元映射到一個包含 50,257 個 tokens 的詞匯表。為了進行垃圾郵件檢測,這一層被替換為一個新的輸出層,該層將相同的 768 個隱藏單元映射到兩個類別,分別表示「垃圾郵件」和「非垃圾郵件」。
輸出層節(jié)點
從技術上講,因為這是一個二元分類任務,可以只用一個輸出節(jié)點。然而,這將需要修改損失函數(shù)。因此,我們選擇一種更通用的方法,匹配輸出節(jié)點與分類的數(shù)量。例如,對于一個分三類的問題,如將新聞文章分類為「科技」、「體育」或「政治」,使用三個輸出節(jié)點,依此類推。
在嘗試進行圖 4 中所示的修改之前,先通過 print (model) 輸出模型架構:
GPTModel (
(tok_emb): Embedding (50257, 768)
(pos_emb): Embedding (1024, 768)
(drop_emb): Dropout (p=0.0, inplace=False)
(trf_blocks): Sequential (
...
(11): TransformerBlock (
(att): MultiHeadAttention (
(W_query): Linear (in_features=768, out_features=768, bias=True)
(W_key): Linear (in_features=768, out_features=768, bias=True)
(W_value): Linear (in_features=768, out_features=768, bias=True)
(out_proj): Linear (in_features=768, out_features=768, bias=True)
(dropout): Dropout (p=0.0, inplace=False)
)
(ff): FeedForward (
(layers): Sequential (
(0): Linear (in_features=768, out_features=3072, bias=True)
(1): GELU ()
(2): Linear (in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm ()
(norm2): LayerNorm ()
(drop_resid): Dropout (p=0.0, inplace=False)
)
)
(final_norm): LayerNorm ()
(out_head): Linear (in_features=768, out_features=50257, bias=False)
)如上所示,GPTModel 由嵌入層和 12 個相同的 transformer 塊組成,為簡潔起見,僅顯示最后一個塊,然后是最終的 LayerNorm 和輸出層 out_head。
接下來,我們將 out_head 替換為一個新的輸出層,如圖 4 所示,我們將對這一層進行微調。
選擇微調特定層與微調所有層
我們不必對模型每一層進行微調,因為神經(jīng)網(wǎng)絡的較低層捕捉到的基本的語言結構和語義是通用的,可以在許多不同的任務和數(shù)據(jù)集中發(fā)揮作用。
因此,我們僅微調最后幾層(靠近輸出的層)就夠了,這些層更具體于細微的語言模式和任務特征。這種方法在計算上也將更加高效。
為了準備進行分類微調,首先我們凍結模型,即將所有層設置為不可訓練:
for param in model.parameters ():
param.requires_grad = False然后,如圖 4 所示,我們修改輸出層 model.out_head :
torch.manual_seed (123)
num_classes = 2
model.out_head = torch.nn.Linear (
in_features=BASE_CONFIG ["emb_dim"],
out_features=num_classes
)注意,在上述代碼中,我們使用了 BASE_CONFIG ["emb_dim"],它的值在 “gpt2-small(124M)” 模型中為 768。這樣做的目的是為了讓后續(xù)的代碼更加通用,相同的代碼也能處理其他型號的 GPT-2 模型。
新的 model.out_head 輸出層的 requires_grad 屬性默認設置為 True,這意味著這是模型中唯一會在訓練期間更新的層。
從技術上講,只訓練剛剛添加的輸出層就足夠了。然而,我在實驗中發(fā)現(xiàn),微調額外的層,可以顯著提高微調模型的預測性能。
此外,我們將最后一個 transformer 塊以及連接該塊與輸出層的 LayerNorm 模塊設置為可訓練,如圖 5 所示。

圖 5:用我的步驟開發(fā)的 GPT 模型包含 12 個重復的 transformer 塊。除了輸出層,我們將最后的 LayerNorm 和最后一個 transformer 塊設置為可訓練,而其余 11 個 transformer 塊和嵌入層保持為不可訓練。
為了做到這點,我們將它們各自的 requires_grad 設置為 True:
for param in model.trf_blocks [-1].parameters ():
param.requires_grad = True
for param in model.final_norm.parameters ():
param.requires_grad = True盡管我們添加了一個新的輸出層,并將某些層設置為不可訓練,我們仍然可以使用這個模型。例如,我們可以像之前那樣輸入一段示例文本:
inputs = tokenizer.encode ("Do you have time")
inputs = torch.tensor (inputs).unsqueeze (0)
print ("Inputs:", inputs)
print ("Inputs dimensions:", inputs.shape)如輸出所示,上述代碼將輸入編碼為一個包含 4 個輸入 tokens 的張量:
Inputs: tensor ([[5211, 345, 423, 640]])
Inputs dimensions: torch.Size ([1, 4])然后,我們將編碼后的 token IDs 輸入模型:
with torch.no_grad ():
outputs = model (inputs)
print ("Outputs:\n", outputs)
print ("Outputs dimensions:", outputs.shape)輸出張量如下所示:
Outputs:
tensor ([[[-1.5854, 0.9904],
[-3.7235, 7.4548],
[-2.2661, 6.6049],
[-3.5983, 3.9902]]])
Outputs dimensions: torch.Size ([1, 4, 2])模型將輸出一個 [1, 4, 50257] 的輸出張量,其中 50,257 代表詞匯表的大小。輸出行數(shù)對應于輸入標記的數(shù)量(在本例中是 4)。每個輸出的嵌入維度(列數(shù))現(xiàn)在減少到 2,而不是 50,257,因為我們替換了模型的輸出層。
由于我們的主要目標是微調出更擅長對垃圾郵件進行分類的模型。為了實現(xiàn)這一點,我們不需要對所有行進行微調,可以專注于一個單一的輸出 token。具體來說,我們將專注于最后一行,對應的最后一個輸出 token,如圖 6 所示。

圖 6: 本圖展示了 GPT 模型處理一個包含 4 個 token 的輸入示例,并生成相應輸出的詳細過程。模型的輸出層經(jīng)過調整,輸出張量僅包含 2 列,為了完成分類微調,我們專注于輸出的最后一行,對應的最后一個 token。
可以使用以下代碼從輸出張量中提取最后一個輸出 token:
print ("Last output token:", outputs [:, -1, :])Print 出來結果如下:
Last output token: tensor([[-3.5983, 3.9902]])那么,我們?yōu)槭裁匆x擇最后一個 token,而不是其他位置上的 token 呢?
注意力機制建立了每個輸入 token 與其他 token 之間的關系,為了讓「注意力」集中,需要用到因果注意力掩碼。它的原理是限制每個 token 只關注自己和前面的 token,如下圖 7 所示:

圖 7:因果注意力機制,矩陣顯示了每個輸入 token 之間的注意力得分。空白單元格表示被掩碼屏蔽的位置,防止 token 關注后來的 token。最后一個 token「time」是唯一需要為所有之前的 token 計算注意力得分的 token。
如圖所示,序列中的最后一個 token 積累了最多的信息,因此,在微調過程中,我們重點關注這個最后的 token。
如何將最后一個 token 轉換為分類標簽預測,并計算模型的初始預測準確率。接下來,我們將在后續(xù)部分微調模型以完成垃圾郵件分類任務。
評估模型性能
由于這部分內容已經(jīng)很長,我就不詳細討論模型評估的細節(jié)了。不過,我想至少分享一張圖,展示訓練過程中,模型訓練集和驗證集的分類準確率,以展示模型確實學得很好。
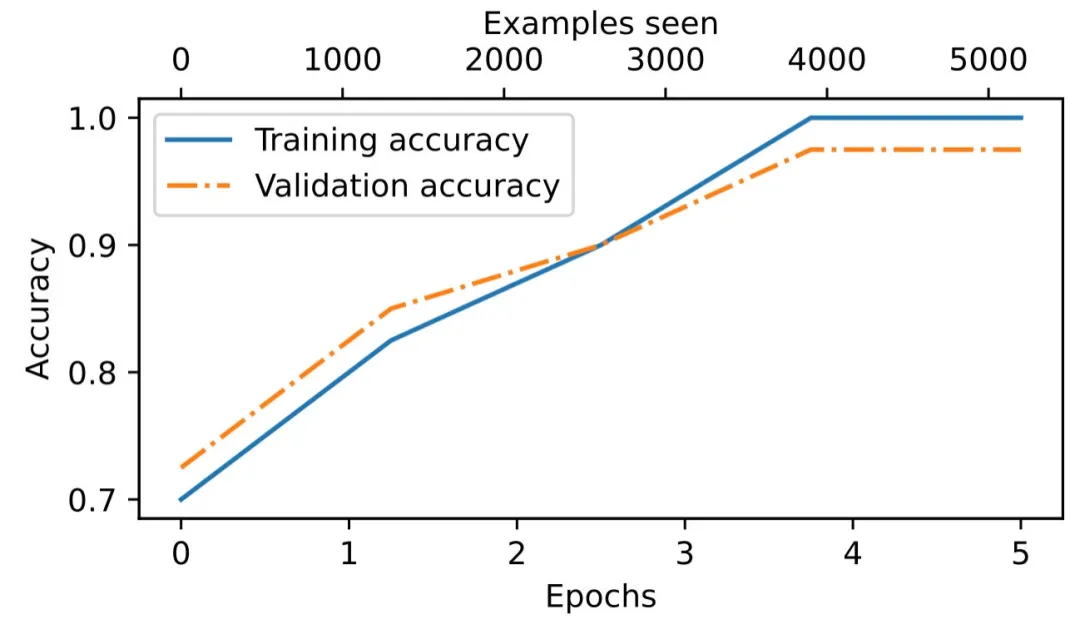
圖 8:訓練準確率(實線)和驗證準確率(虛線)在早期的訓練周期中大幅上升,然后趨于平穩(wěn),達到了幾乎完美的準確率 1.0,對應 100%。兩條線在整個訓練過程中相距較近,表明模型對訓練數(shù)據(jù)并沒有過度擬合。
模型的驗證準確率約為 97%。測試準確率約為 96%。此外,我們可以看到模型略微有一點點過擬合,因為訓練集的準確率稍高。
從補充實驗得出的洞見
到這里,你可能對某些設計選擇有很多疑問,所以我進行了一些補充實驗并把結果分享了出來。重新運行這些實驗的代碼已經(jīng)放在了以下 GitHub 項目中。
GitHub 地址:https://github.com/rasbt/LLMs-from-scratch/tree/main/ch06/02_bonus_additional-experiments
需要訓練所有層嗎?
出于效率原因,我們僅訓練輸出層和最后一個 transformer 塊。如前所述,對于分類微調,無需更新 LLM 中的所有層。我們更新的權重越少,訓練速度就越快,因為我們不需要在反向傳播期間計算權重的梯度。
但是,你可能想知道如果不更新所有層,我們會留下多少預測性能。因此,在下表中,我對所有層、僅最后一個 transformer 塊(包括最后一層)、僅最后一層進行了微調。

表 1:訓練所有層 vs 僅訓練最后一個 Transformer 塊(包括最后一層)vs 僅訓練最后一層
如上表 1 所示,訓練所有層的性能稍好一些:96.67% vs 95.00%。不過,這使運行時間增加了約 2.5 倍。
為什么要微調最后一個 token,而不是第一個 token?
如果你熟悉 BERT(Devlin et al. 2018)等編碼器式語言模型,你可能知道這些模型有一個指定的分類 token 作為其第一個 token,如下圖所示:
 圖來自 BERT 原始論文:https://arxiv.org/abs/1810.04805
圖來自 BERT 原始論文:https://arxiv.org/abs/1810.04805
與 BERT 相比,GPT 是一種具有因果注意力掩碼的解碼器式模型(如圖 7 所示)。這意味著第一個 token 沒有輸入中任何其他 token 的上下文信息。只有最后一個 token 具有有關所有其他 token 的信息。
因此,如果我們想使用像 GPT 這樣的模型進行分類微調,我們應該關注最后一個 token 標記以捕獲所有其他輸入 token 的上下文信息。
如下表所示,我們可以看到使用第一個 token 來微調 GPT 模型進行分類會導致性能更差。

表 2:微調 GPT 模型中的最后一個 token 與第一個 token。
BERT 與 GPT 的性能比較如何?
說到 BERT,你可能想知道它在分類任務上與類 GPT 模型的性能比較如何?簡單來說,在垃圾郵件分類任務上,更小的 GPT-2(124M)與更大 BERT(340M)的性能類似,具體如下表 3 所示。

表 3:GPT-2 與 BERT 的結果比較。
可以看到,BERT 模型的表現(xiàn)比 GPT-2 稍微好一點(測試準確率高 1%),但 BERT 的參數(shù)規(guī)模幾乎是 GPT-2 的 3 倍。此外,數(shù)據(jù)集可能太小且太簡單了,因此我又在 IMDB Movie Review 數(shù)據(jù)集上嘗試比較了情感分類表現(xiàn)(即預測觀看者是否喜歡一部電影)。

表 4:GPT-2 與 BERT 在影評分類任務上的比較。
可以看到,在這個更大的數(shù)據(jù)集上(包含 25k 訓練和 25k 測試集記錄),GPT-2 與 BERT 兩個模型的預測性能同樣類似。
總的來說,在分類任務上,BERT 和其他編碼器風格的模型被認為優(yōu)于解碼器風格的模型。但是,實驗結果也表明,編碼器風格的 BERT 和解碼器風格的 GPT 模型之間沒有太大的差異。
此外,如果你對更多基準比較以及如何進一步提升解碼器風格模型的分類性能感興趣,可以參閱以下兩篇最近的論文:
- Label Supervised LLaMA Finetuning:https://arxiv.org/abs/2310.01208
- LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders:https://arxiv.org/abs/2404.05961
其中第一篇論文討論了:在分類微調期間移除因果掩碼可以提升解碼器風格模型的分類性能。
我們應該禁用因果掩碼嗎?
當我們在下一個詞(next-word)預測任務上訓練類 GPT 模型時,GPT 架構的核心特征是因果注意力掩碼,這與 BERT 模型或原始 transformer 架構不同。
但實際上,我們可以在分類微調階段移除因果掩碼, 從而允許我們微調第一個而不是最后一個 token。這是因為未來的 tokens 將不再被掩碼,并且第一個 token 可以看到所有其他的 tokens.

有 / 無因果掩碼的注意力權重矩陣。
幸運的是,在類 GPT 大語言模型中禁用因果注意力掩碼只需要改變 2 行代碼。
class MultiheadAttention (nn.Module):
def __init__(self, d_in, d_out, context_length, dropout, num_heads):
super ().__init__()
# ...
def forward (self, x):
b, num_tokens, d_in = x.shape
keys = self.W_key (x) # Shape: (b, num_tokens, d_out)
queries = self.W_query (x)
values = self.W_value (x)
# ...
attn_scores = queries @ keys.transpose (2, 3)
# Comment out the causal attention mask part
# mask_bool = self.mask.bool ()[:num_tokens, :num_tokens]
# attn_scores.masked_fill_(mask_bool, -torch.inf)
attn_weights = torch.softmax (
attn_scores /keys.shape [-1]**0.5, dim=-1
)
context_vec = (attn_weights @ values).transpose (1, 2)
context_vec = context_vec.contiguous ().view (
b, num_tokens, self.d_out
)
context_vec = self.out_proj (context_vec)
return context_vec下表 5 展示了改變代碼后對垃圾郵件分類任務帶來的影響。

表 5:有無使用因果注意力掩碼來微調 GPT-2 分類器的結果。
可以看到,在微調階段禁用因果掩碼可以帶來略微的提升。
增加模型大小會帶來哪些影響?
目前為止,我們只看到了最小的 GPT-2(124M)模型的性能,那么與規(guī)模更大的 GPT-2 變體相比如何呢?比如 GPT-2 medium(355M)、GPT-2 large(774M)和 GPT-2 XL(1558M)。結果如下表 6 所示。

表 6:不同參數(shù)規(guī)模的 GPT-2 變體的分類微調結果。
可以看到,隨著模型參數(shù)增加,預測準確率顯著提升。不過 GPT-2 medium 是個例外,它在其他數(shù)據(jù)集上的性能同樣很差。我懷疑該模型可能沒有經(jīng)過很好的預訓練。
此外,最大的 GPT-2 XL 獲得了比最小的 GPT-2 small(124M)好得多的分類準確率,但微調時間也長了 7 倍。
LoRA 預計能帶來哪些改進?
回到本文第一個問題:我們需要訓練所有層嗎?結果發(fā)現(xiàn),當僅僅微調最后一個 transformer 塊而不是整個模型時, 我們可以(或幾乎可以)匹配分配性能。所以僅僅微調最后一個塊的優(yōu)勢在于訓練速度更快,畢竟不是所有的權重參數(shù)都要更新。
接下來的問題是與低秩適應(LoRA)的比較結果如何,LoRA 是一種參數(shù)高效的微調技術。

表 7:覆蓋所有層的完整微調 vs 利用 LoRA 的參數(shù)高效微調。
可以看到,完整微調(所有層)和 LoRA 在數(shù)據(jù)集上獲得了相似的測試集性能。
在小模型上,LoRA 會稍微慢一點,添加 LoRA 層帶來的額外開銷可能會超過獲得的收益。但當訓練更大的 15 億參數(shù)模型時,LoRA 的訓練速度會快 1.53 倍。
填充(Padding)還是不填充?
如果我們想要在訓練或推理階段分批次地處理數(shù)據(jù)(包括一次處理多個輸入序列),則需要插入 padding token,以確保訓練樣本的長度相等。

圖中描述了給定批次中的輸入文本如何在 padding 過程中保持長度相等。
在常規(guī)文本生成任務中,由于 padding tokens 通常要添加到右側,因而 padding 不影響模型的響應結果。并且由于前面討論過的因果掩碼,這些 padding tokens 也不影響其他 token。
但是,我們對最后一個 token 進行了微調。同時由于 padding tokens 在最后一個 token 的左側,因此可能影響結果。
如果我們使用的批大小為 1,實際上不需要 pad 輸入。當然,這樣做從計算的角度來看更加高效(一次只處理一個輸入樣本)。并且批大小為 1 可以用作一個變通方法,來測試使用 padding 是否影響結果。

表 8:有無 padding 時,GPT-2(124M)的訓練準確率、驗證準確率和測試準確率變化。
可以看到,避免 padding tokens 的確可以為模型帶來效果的顯著提升。這里使用了梯度累計來模擬批大小 8,以匹配默認實驗的批大小,并進行公平比較。
作者介紹

個人主頁:https://sebastianraschka.com/
Sebastian Raschka 是一名機器學習和人工智能研究員,曾在威斯康星大學麥迪遜分校擔任統(tǒng)計學助理教授,專門研究深度學習和機器學習。他致力于關于 AI 和深度學習相關的內容更簡單易懂。
Sebastian 還熱衷于開源軟件,十多年來,他一直是一個充滿熱情的開源貢獻者。他提出的方法現(xiàn)已成功在 Kaggle 等機器學習競賽中得到應用。
除了編寫代碼,Sebastian 還喜歡寫作,他撰寫了暢銷書《Python Machine Learning》(《Python 機器學習》)和《Machine Learning with PyTorch and ScikitLearn》。
這篇博客的內容是他的新書《Build a Large Language Model (From Scratch)》的第六章。
更多研究細節(jié),可參考原博客。