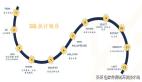
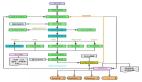
關于 SQL 執行順序的詳解
在使用 SQL 進行數據庫查詢時,理解 SQL 語句的執行順序至關重要。這不僅有助于編寫高效的查詢,還能幫助調試和優化查詢性能。本文將詳細介紹 SQL 語句的執行順序,并通過示例代碼加以說明。
SQL 執行順序概述
SQL 的執行順序并不總是按照我們編寫 SQL 語句的順序進行,而是有其特定的邏輯順序。通常情況下,SQL 查詢的執行順序如下:
- FROM
- WHERE
- GROUP BY
- HAVING
- SELECT
- DISTINCT
- ORDER BY
- LIMIT
我們將逐步解析每個步驟,并通過示例代碼進行說明。

1. FROM
FROM 子句是 SQL 查詢的起點。它指定了查詢數據的表或視圖。在這個階段,SQL 引擎會根據 FROM 子句中的表名讀取數據。
SELECT *
FROM employees;在這個示例中,SQL 引擎首先從 employees 表中讀取數據。
2. WHERE
WHERE 子句用于過濾數據,只返回滿足條件的記錄。此步驟在 SELECT 之前執行。
SELECT *
FROM employees
WHERE department = 'Sales';在這個示例中,SQL 引擎首先從 employees 表中讀取數據,然后過濾出部門為 "Sales" 的記錄。
3. GROUP BY
GROUP BY 子句用于將數據分組,以便對每組數據進行聚合操作。此步驟在 WHERE 之后執行。
SELECT department, COUNT(*)
FROM employees
WHERE department IS NOT NULL
GROUP BY department;在這個示例中,SQL 引擎會首先從 employees 表中讀取數據,然后過濾出部門不為空的記錄,最后按部門分組并統計每個部門的員工數量。
4. HAVING
HAVING 子句用于過濾分組后的數據。這一步在 GROUP BY 之后執行,用于限制返回的組。
SELECT department, COUNT(*)
FROM employees
WHERE department IS NOT NULL
GROUP BY department
HAVING COUNT(*) > 10;在這個示例中,SQL 引擎會按部門分組并統計每個部門的員工數量,然后過濾出員工數量大于 10 的部門。
5. SELECT
SELECT 子句用于指定查詢返回的列。在前面步驟完成之后,SQL 引擎會根據 SELECT 子句返回所需的列。
SELECT department, COUNT(*)
FROM employees
WHERE department IS NOT NULL
GROUP BY department
HAVING COUNT(*) > 10;在這個示例中,SELECT 子句指定返回部門名稱和每個部門的員工數量。
6. DISTINCT
DISTINCT 子句用于去除重復的記錄。此步驟在 SELECT 之后執行。
SELECT DISTINCT department
FROM employees;在這個示例中,SQL 引擎會從 employees 表中讀取數據,并返回不重復的部門名稱。
7. ORDER BY
ORDER BY 子句用于對查詢結果進行排序。此步驟在 SELECT 和 DISTINCT 之后執行。
SELECT department, COUNT(*)
FROM employees
WHERE department IS NOT NULL
GROUP BY department
HAVING COUNT(*) > 10
ORDER BY COUNT(*) DESC;在這個示例中,查詢結果按員工數量降序排序。
8. LIMIT
LIMIT 子句用于限制返回的記錄數量。此步驟在所有其他步驟之后執行。
SELECT department, COUNT(*)
FROM employees
WHERE department IS NOT NULL
GROUP BY department
HAVING COUNT(*) > 10
ORDER BY COUNT(*) DESC
LIMIT 5;在這個示例中,查詢結果返回前五個部門。
結語
理解 SQL 執行順序對于編寫高效的查詢和優化數據庫性能至關重要。通過按步驟解析 SQL 查詢的執行過程,可以更好地理解 SQL 查詢的行為并進行優化。