TCP 到底有什么性能問題?
概述
TCP 的性能問題本質是公平與效率的取舍問題。
TCP 實現可靠傳輸層的核心有三點:
(1) 確認與重傳 (已經可以滿足 “可靠性”,但是可能存在性能問題)
(2) 滑動窗口 (也就是流量控制,為了提高吞吐量,充分利用鏈路帶寬,避免發送方發的太慢)
(3) 擁塞控制 (防止網絡鏈路過載造成丟包,避免發送方發的太快)
- 滑動窗口主要關注發送方到接收方的流量控制
- 擁塞控制更多地關注整個網絡 (鏈路) 層面的流量控制
滑動窗口和擁塞控制相互制約,使發送方可以從網絡鏈路的全局角度來自動調整發送速率,從這個角度來看,TCP 對于整個網絡的意義已經超過 “傳輸層”。
擁塞控制
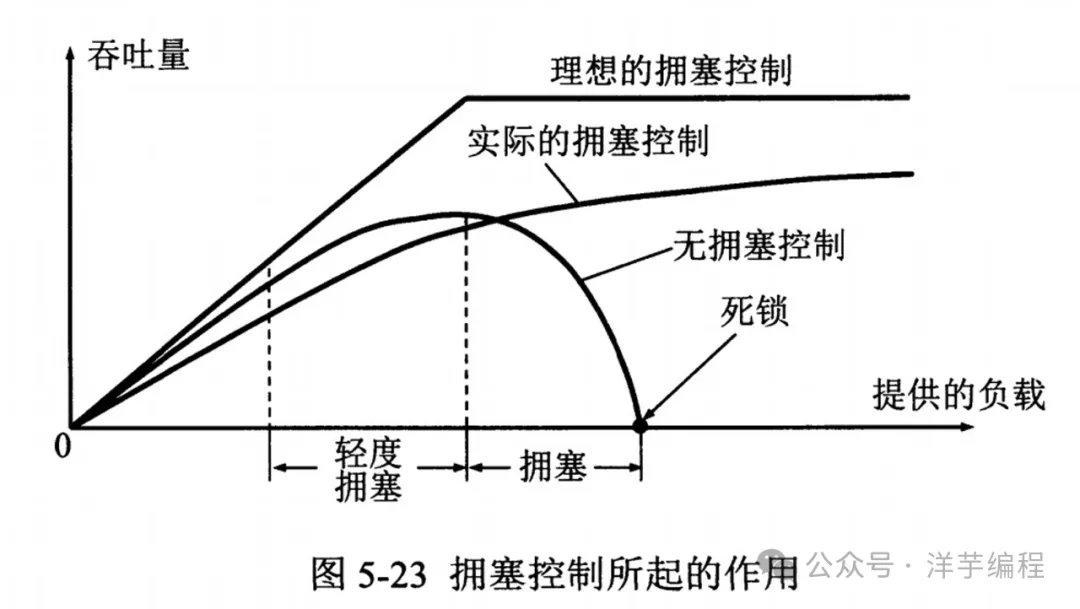
相比滑動窗口,擁塞控制的視角更為全面,會對整個網絡鏈路中的所有主機、路由器,以及降低網絡傳輸性能的有關因素進行綜合考量。
既然擁塞控制要考慮這么多因素,那就不可避免地會在某些場景下存在所謂 “性能問題”,下面來具體分析下。
1. 慢啟動
慢啟動本身不會造成性能問題,因為慢啟動時,cwnd (擁塞窗口大小值) 是指數級增長,所以 “慢啟動” 其實并不慢,這一點我們在之前的 TCP 擁塞控制實現原理 文章中已經講過了。
但是在特定場景下 (如 HTTP),慢啟動會增加數據傳輸的 往返次數。
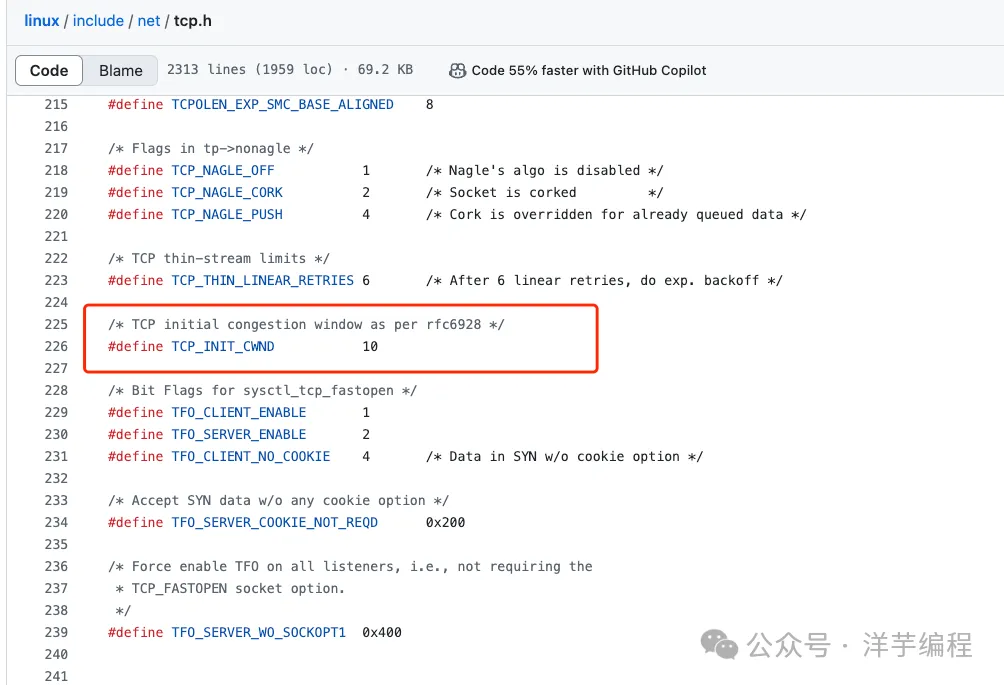
這里以 Linux 為例,內核在 3.0 之后,采用了 Google 的建議,將 cwnd 初始化為 10 個 MSS,默認的 MTU 為 1500, MSS 為 1460, 那么,第一次發送的 TCP 數據 (Segment) 總量為:
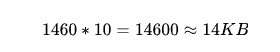
默認情況下,ssthresh 值為 65 KB,也就是從 慢啟動階段 進入到 擁塞避免階段 的閾值。
我們隨便訪問一個網站的主頁 (例如 stackoverflow.com), 這里就以其首頁 html 文本數據大小 (68.8 KB) 為例,說明一下慢啟動對于服務端發送響應數據,帶來了哪些性能影響。
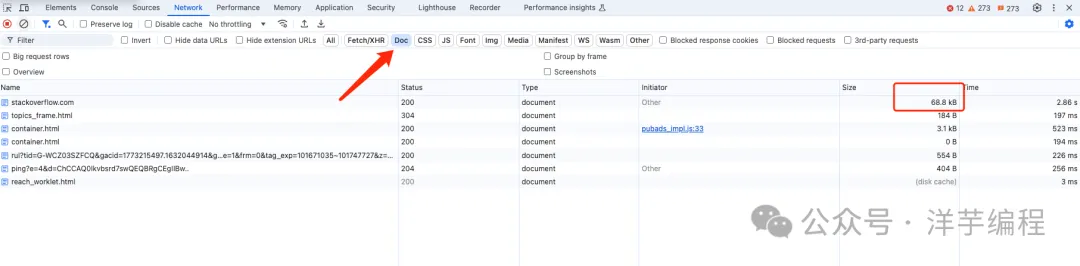
- 第 1 次發送的數據總量為: 14 KB
- 經過 1 個 RTT, cwnd 翻倍
- 第 2 次發送的數據總量為: 28 KB
- 經過 1 個 RTT, cwnd 再次翻倍
- 第 3 次發送的數據總量為: 56 KB
經過 3 次發送后,14 + 28 + 56 = 98 KB, 首頁 html 文本數據傳輸完成,一共經歷了 3 個往返次數。
當網頁資源加載完成后,一般很少再去加載其他資源/數據,但是此時,cwnd 也才剛剛接近 ssthresh 閾值大小。
假設現在我們消除掉慢啟動階段,直接火力全開,第 1 次就發送數據總量: 65 KB, 那么就只需要經歷 2 個往返次數,就可以完成數據傳輸。
2. 擁塞發生 (丟包)
在基于丟包的擁塞控制算法中 (例如 Reno、Cubic、NewReno), 認為一旦發生丟包,就是網絡鏈路發生了擁塞,所以發送方會急劇地減小發送窗口,甚至進入短暫的等待狀態(超時重傳)。
1% 的丟包率并不只是降低 1% 的傳輸性能,而是可能降低 50% 甚至更多 (取決于具體的 TCP 實現),此時就可能出現極端情況: 網絡花在重傳被丟掉的數據包的時間比發送新的數據包的時間還要多,所以這是造成 所謂 TCP 性能問題 的最大元兇。
丟包同時會加重網絡鏈路擁塞,假設 1 個 TCP 數據段轉發到第 N 個路由器,前 N-1 個路由器已經完成轉發,但是第 N 個路由器轉發時丟失了數據段,最終導致丟失的數據段浪費了前面所有路由器的帶寬。
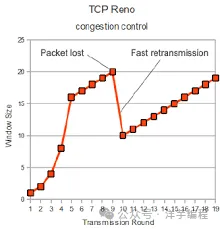
TCP Reno 算法發生丟包時,性能直接腰斬
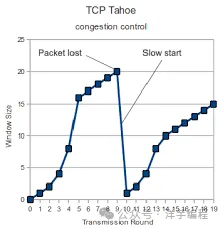
TCP Tahoe 算法發生丟包時,直接重置,進入慢啟動過程
這里以 HTTP 場景為例,丟包帶來的影響在 HTTP/2 中表現更為嚴重,因為 HTTP/2 只使用 1 個 TCP 連接進行傳輸。所以 1 次丟包會導致所有的資源下載速度變慢。而 HTTP/1.1 可能有多個獨立的 TCP 連接,1 次丟包也只會影響其中 1 個 TCP 連接,所以這種場景下 HTTP/1.1 反而會獲得更好的性能。
3.順序可靠性保證
雖然 TCP 確保所有數據包有序到達,但是這個順序語義保證可能會引發類似 HTTP 隊列頭部請求阻塞 (head of line blocking) 問題。
TCP 在傳輸時使用序列號 (Seq) 標識數據的順序,一旦某個數據丟失,后續的數據需要保存在接收方的 TCP 緩沖區中,等待丟失的數據重傳完成后,才能進行下一步處理 (傳遞到應用層)。
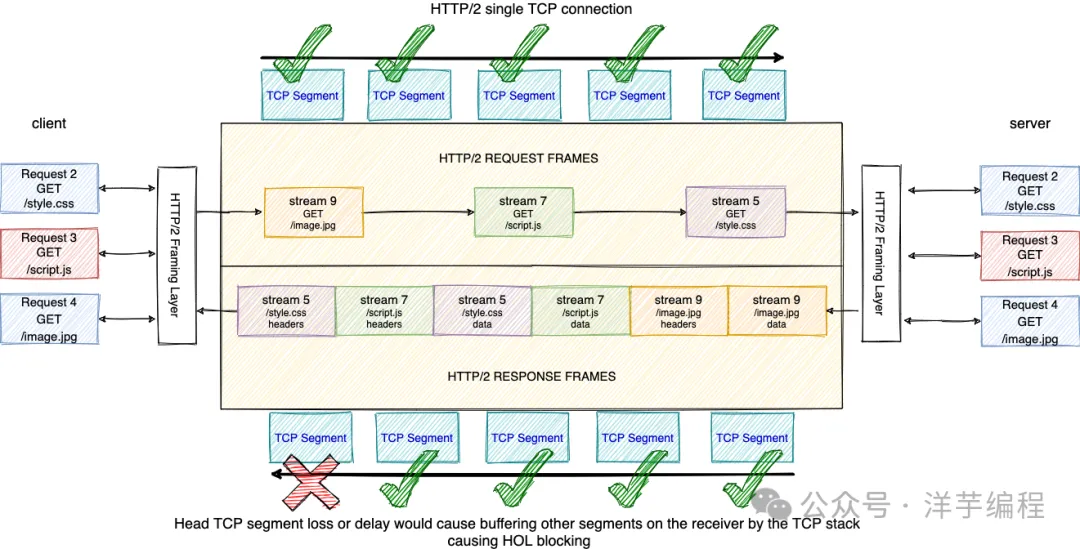
應用層無法得知 TCP 接收緩沖區的情況,所以必須等待序列 (Seq) 完整之后才可以獲取應用數據。但是實際上,已經接收到的數據包中,很可能就有應用層可以直接處理的數據,所以,這也可以稱之為 TCP 隊列頭部請求阻塞 (head of line blocking) 問題。
4.改進和優化
針對基于丟包的擁塞控制算法,最明顯的改進就是使用更為合理的擁塞控制算法,例如可以更好地適應高帶寬、高時延、且容忍一定丟包率的 BBR 算法。
如果保證 TCP 可以在 0 丟包 的前提下傳輸數據,那么自然而然可以最大化利用帶寬。
??: 思考: 如果高丟包的情況下,使用 UDP 會獲得更好的性能嗎?
三次握手
除了擁塞控制引起的 "性能問題" 外,TCP 建立連接時的三次握手機制,在某些場景下也會引起性能問題。
對于大多數 TCP 的使用場景 (長連接 + 頻繁數據傳輸),三次握手幾乎可以忽略不計。真正會造成性能影響的是 長時間 + 大量短連接 場景,針對這個問題, 可以考慮將短連接改造為長連接,或者使用 TFO 技術[1] 來進行優化。
此外,還有 2 個會引發性能問題的場景是 HTTP 和網絡切換。
1.HTTP
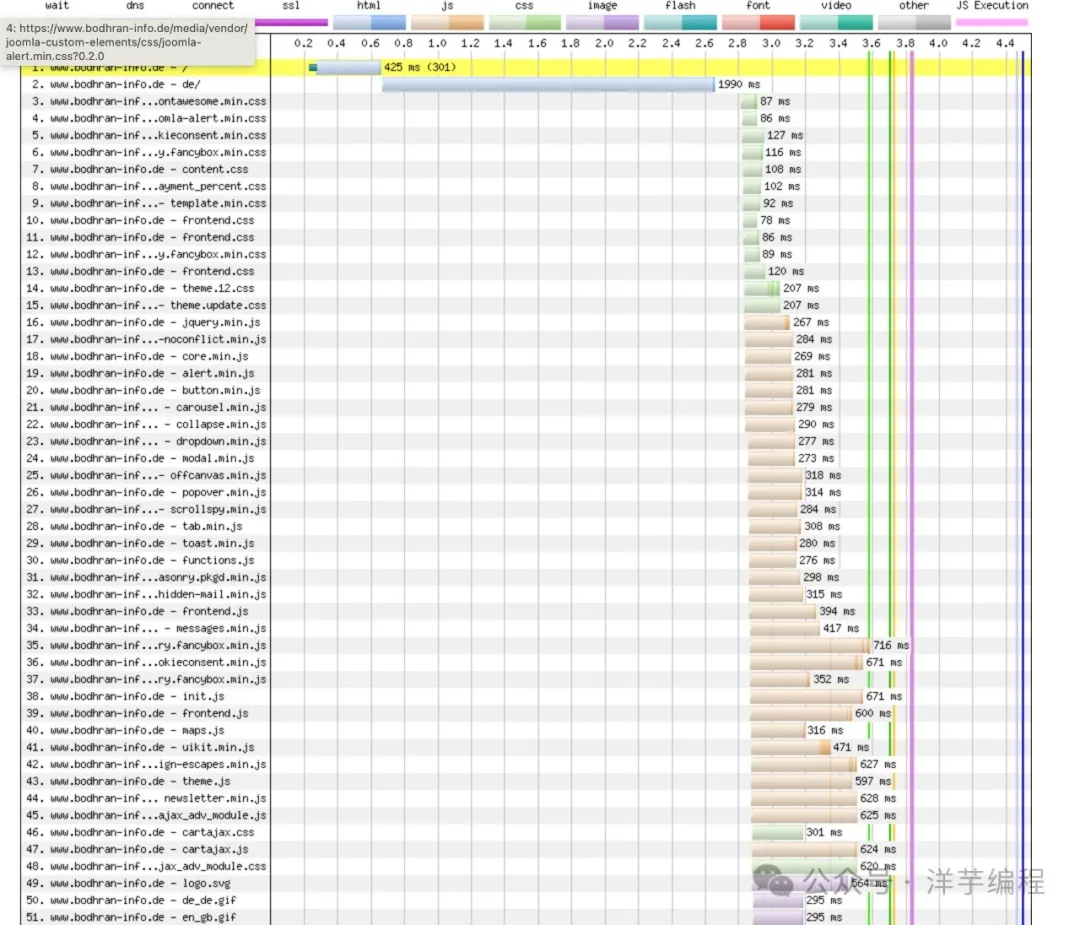
在 HTTP/1.1 版本中,訪問不同的的資源時 (CSS, Javascript, images ...) 會使用多個 TCP 連接會產生大量的延遲,如下圖所示。
使用 HTTP/1.1 訪問時的瀑布圖
解決方案也很簡單:直接升級使用 HTTP/2, 在整個通信過程中,只會有 1 個 TCP 連接。
使用 HTTP/2 訪問時的瀑布圖
除此之外,有的讀者可能會想到 “弱網絡” 這個使用場景 (例如人群密集的地鐵車廂),但是,既然都是 “弱網絡” 了,那么使用其他的傳輸協議也很難規避這個問題。
2.網絡切換
TCP 連接遷移:受限于 TCP 四元組 的限制,如果源 IP 發生變化,則需要重新建立 TCP 連接,從而導致延遲暫停 (例如當前設備從 Wifi 切換到蜂窩網絡)。
類似的場景,還有多個物理場所使用不同的出口公網 IP 地址,例如學校的圖書館和宿舍,公司的會議室和辦公區,當使用者切換物理空間時,也會發送重新建立 TCP 連接。
當然,該問題同樣可以通過使用 TFO 技術[2] 來進行優化。
確認與重傳
這塊 (可能) 會引發 TCP 性能問題的原因,主要涉及到 3 點:
- TCP 超時重傳帶來的性能影響
- TCP 快速重傳的局限性
- TCP 選擇性重傳解決了哪些問題
細節部分在 之前的文章中[3] 已經詳細講過了,本文不再贅述。
小結
現代 TCP 在理想傳輸條件下,性能只受限于光速和接收方緩沖區 (內存) 大小,也就是硬件和物理。
硬件方面,有例如 TOE, NIC 的各種助攻和加速。
所以最終 TCP 在理想情況下的硬件性能受限于:
- 鏈路中最小的帶寬
- 鏈路中最慢的硬件處理
- 鏈路中最小的接收緩沖區大小
三者結合起來,也就是通信過程中的所謂 “瓶頸鏈路”。
如果不存在硬件性能限制,也就是在足夠的帶寬、足夠的內存、足夠的處理速度的前提下,TCP 的性能理論上只受限于物理,也就是光速。
最后,再次搬上大佬語錄:
網絡編程中,開發者遇到的實際問題,大約有 90% 都和開發者對于 TCP/IP 的理解有關。不要對 TCP 和 UDP 的相對性能做任何先驗假設,即使是很小的擦不參數改變,都可能對性能產生嚴重影響。