Redis遇到Hash沖突怎么辦?
一、什么是 Hash 沖突
Hash 沖突,也稱為 Hash 碰撞,是指不同的關鍵字通過 Hash 函數計算得到了相同的 Hash 地址。
Hash 沖突在 Hash 表中是不可避免的,因為 Hash 表的地址空間有限,而可能的關鍵字數量是無限的。
為了解決 Hash 沖突,有幾種常見的方法:
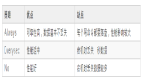
- 鏈地址法(Chaining):這是最常用的方法之一,每個 Hash 表的桶(bucket)都維護一個鏈表,所有散列到同一個位置的元素都存儲在這個鏈表中。當發(fā)生沖突時,新元素被添加到該鏈表的末尾。這種方法的優(yōu)點是操作簡單,插入、查找和刪除的時間復雜度為 O(1),但當鏈表長度較長時,查找效率會降低,并且需要額外的內存空間來存儲鏈表結構。
- 開放尋址法(Open Addressing):這種方法也稱為閉散列,當發(fā)生 Hash 沖突時,會順序地查找下一個可用的數組位置,直到找到一個空閑位置為止。開放尋址法有幾種變體,包括線性探測、二次探測和偽隨機探測。線性探測法是最簡單的形式,它按順序檢查下一個空閑位置。二次探測法在發(fā)生沖突時,在表的左右進行跳躍式探測。偽隨機探測法則使用偽隨機數序列來確定下一個探查位置。
- 再 Hash 法(Rehashing):這種方法同時構造多個不同的 Hash 函數,當發(fā)生沖突時,使用第二個 Hash 函數計算地址,直到找到一個不發(fā)生沖突的位置。這種方法不易產生聚集,但增加了計算時間。
- 建立公共溢出區(qū):將 Hash 表分為基本表和溢出表,將發(fā)生沖突的元素都存放在溢出表中。這種方法可以減少沖突,但需要額外的存儲空間。
不同的編程語言在面臨這個問題時也都采取了不同策略,例如:
- Python 采用開放尋址。字典 dict 使用偽隨機數進行探測。
- Java 采用鏈式地址。自 JDK1.8 以來,當 HashMap 內數組長度達到 64 且鏈表長度達到 8 時,鏈表會轉換為紅黑樹以提升查找性能。
- Go 采用鏈式地址。Go 規(guī)定每個桶最多存儲 8 個鍵值對,超出容量則連接一個溢出桶;當溢出桶過多時,會執(zhí)行一次特殊的等量擴容操作,以確保性能。
小伙伴們需要先熟悉這些解決方案,因為 Redis 中的解決方案無外乎就是這四種方案中的某幾種。
二、Redis 中的 Hash
Redis 中的 Hash 數據結構在底層使用了兩種不同的數據結構來存儲鍵值對:
- 壓縮列表(ziplist):當 Hash 表中的元素數量較少,并且每個元素的值都小于特定閾值(例如,值的長度小于 64 字節(jié))時,Redis 會使用壓縮列表來存儲 Hash 表。壓縮列表是一種內存高效的數據結構,它將所有的元素存儲在一塊連續(xù)的內存空間中,這樣可以減少內存碎片和內存分配次數。但是,當元素數量增加或者單個元素的大小超過閾值時,壓縮列表的性能會下降,因為它需要頻繁地進行內存重新分配和數據復制。
- Hash 表(hash table):當 Hash 表中的元素數量較多,或者元素的大小超過壓縮列表的閾值時,Redis 會使用一個普通的 Hash 表來存儲數據。這個 Hash 表由數組和鏈表組成,每個數組的索引位置上可以存儲多個元素,這些元素通過鏈表連接起來。當 Hash 表中的元素數量增加到一定程度時,Redis 會進行 rehash 操作,即創(chuàng)建一個新的更大的 Hash 表,并將舊表中的所有元素重新映射到新表中。
Redis 會根據 Hash 表的大小和元素的數量自動在這兩種數據結構之間進行切換,以保證性能和內存效率。這種動態(tài)的數據結構選擇機制使得 Redis 的 Hash 數據結構既靈活又高效。
從上面的介紹中小伙伴們其實能看到,Redis 在處理 Hash 沖突的時候,用到了兩種不同的方案:
- 鏈地址法
- rehash
三、Redis 如何解決 Hash 沖突
根據前面的介紹,小伙伴們已經明白了 Redis 在處理 Hash 沖突的時候,用到了兩種不同的方案:鏈地址法和 rehash。
第一種鏈地址法大家應該是比較熟悉的,我們 Java 里邊早期的 HashMap 就是這樣的,具體數據結構如下圖:

不過鏈地址法有一個弊端,就是如果出現大量的 key 沖突導致鏈表過長,此種情況下會導致數據的檢索效率變慢,這不符合 Redis 高性能的人設,那怎么辦呢?
為了保持高效,Redis 會對 Hash 表做 rehash 操作,也就通過增加 Hash 桶來減少沖突。為了 rehash 更高效,Redis 還默認使用了兩個全局 Hash 表,一個用于當前使用,稱為主 Hash 表,一個用于擴容,稱為備用 Hash 表。
具體來說,在 Hash 表擴容時,Redis 首先會創(chuàng)建一個新的 Hash 表,該 Hash 表的大小是原有 Hash 表的兩倍,然后將原有 Hash 表中的鍵值對逐一遷移到新的 Hash 表中。
在遷移過程中,Redis 會為每個被遷移的鍵值對計算出其在新 Hash 表中的位置,并將其插入到相應的位置上。在遷移完成后,Redis 會將新 Hash 表作為當前 Hash 表,用于存儲新的鍵值對,同時釋放舊 Hash 表的內存。
由于遷移過程是逐步進行的,因此在遷移過程中,既可以對新 Hash 表進行寫入操作,也可以對舊 Hash 表進行讀取操作,從而保證了 Redis 服務的正常運行。
四、小結
Redis 通過鏈地址法解決 Hash 沖突,并通過漸進式 rehash 保持 Hash 表的性能。
鏈地址法實現簡單且在負載因子較低時性能較好,但在負載因子較高時性能會下降。漸進式 rehash 通過分批次遷移數據,避免了 rehash 過程中的服務阻塞,從而保持了系統(tǒng)的高性能和高可用性。
通過以上機制,Redis 在處理 Hash 沖突時能夠有效地平衡性能和復雜度,確保在各種使用場景下都能提供高效的數據存儲和檢索服務。