面試官:Kafka是如何實現百萬級高吞吐量的?
我們還是用一張圖先概括所有的要點:
 圖片
圖片
批量發送與壓縮
Kafka發送消息時,首先將消息進行批量打包,然后壓縮后通過網絡傳輸,Producer可以通過GZIP或Snappy格式對消息集合進行壓縮。這樣可以減少網絡傳輸的開銷,同時也可以利用壓縮算法來降低磁盤存儲的空間占用。
優秀的網絡模型
Kafka使用了基于Java NIO的網絡框架,其實也是個 reactor的模型。他的設計中,Accepter 作為一個 main reactor,里面包含了 child reactor 即 processor,然后發送和接收都是通過隊列的方式異步進行[1]。
 圖片
圖片
磁盤順序寫
與隨機訪問相比,磁盤上的順序寫操作要快得多。Kafka將每個分區的日志作為一系列連續的文件段進行管理,并且總是追加到當前活動的日志文件末尾。
頁緩存技術(MMAP內存映射)
即便是順序寫入硬盤,硬盤的訪問速度還是不可能追上內存。所以 Kafka 的數據并不是實時的寫入硬盤 ,它充分利用了現代操作系統頁緩存來利用內存提高 I/O 效率。kafka在寫數據的時候,會先將數據寫入到頁緩存,滿足一定條件后刷寫到磁盤上,可以保證更高的讀寫性能。
操作系統本身有一層緩存,叫做page cache,是在內存里的緩存,我們也可以稱之為os cache,意思就是操作系統自己管理的緩存。你在寫入磁盤文件的時候,可以直接寫入這個os cache里,也就是僅僅寫入內存中,接下來由操作系統自己決定什么時候把os cache里的數據真的刷入磁盤文件中[2]。

MMAP將磁盤文件映射到內存,用戶通過修改內存就能修改磁盤文件。通過MMAP,進程像讀寫硬盤一樣讀寫內存(當然是虛擬機內存)。使用這種方式可以獲取很大的 I/O 提升,省去了用戶空間到內核空間復制的開銷。
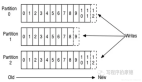
分區并發
Kafka的分區機制可以實現高并發的數據消費。Kafka中的topic中的內容可以分在多個分區(partition)存儲,每個partition又分為多個段segment,所以每次操作都是針對一小部分做操作,很輕便,并且增加并行操作的能力,每個分區都是獨立的、有序的消息隊列。
消費者組內的不同成員可以并行地消費不同的分區,從而實現了水平擴展性和更高的并發度。這種設計使得Kafka能夠很好地支持大規模的消息處理場景。
Sendfile零拷貝
當客戶端請求讀取數據時,Kafka可以利用操作系統級別的零拷貝特性直接將數據從磁盤傳輸給網絡接口,而不需要經過應用程序緩沖區,這樣就減少了不必要的數據復制過程。Kafka 使用到了 mmap 和 sendfile 的方式來實現零拷貝。分別對應 Java 的 MappedByteBuffer 和 FileChannel.transferTo。如下圖[4]:
 圖片
圖片
結語
Kafka是一個非常優秀的消息系統,它提供了高吞吐量、低延遲和高可靠性等特性。通過使用批量發送與壓縮、優秀的網絡模型、磁盤順序寫、頁緩存、分區并發、sendfile零拷貝等技術,Kafka可實現百萬級高吞吐量。
參考:
[1] https://juejin.cn/post/7276814487054532645
[2] https://blog.csdn.net/CSDN2497242041/article/details/120458401
[3] https://www.jianshu.com/p/53b8ec516a0b
[4] https://mp.weixin.qq.com/s/MLQzOv2lFV_NL1tm5rAZ-w
[5] https://mp.weixin.qq.com/s/iJJvgmwob9Ci6zqYGwpKtw
[6] https://developer.aliyun.com/article/939817