













面試官:說說看你知道的常見限流算法有哪些?它們的優缺點分別是什么?如何基于用戶身份限流?
面試官:能不能說說看在系統架構中,限流的主要目的是什么,有哪些常見的限流算法
在系統架構中,限流的主要目的是保護系統免受過量請求的沖擊,確保系統資源能夠得到合理分配和有效利用,從而維持系統的穩定性和可靠性。具體來說,限流有助于防止以下幾種情況的發生:
- 系統過載:當請求量超過系統的處理能力時,系統可能會因為資源耗盡(如CPU、內存、數據庫連接等)而崩潰或響應變慢。
- 數據庫壓力:大量的并發請求可能導致數據庫負載過高,進而影響數據的一致性和完整性。
- 服務雪崩:在微服務架構中,一個服務的過載可能會引發連鎖反應,導致整個系統的崩潰。

限流常見的實現方式包括以下幾種:
(1) 計數器限流:
通過記錄單位時間窗口內的請求數量,當數量達到設定的閾值時,拒絕后續請求。
優點:實現簡單,易于理解。
缺點:存在臨界問題,即在時間窗口切換時的大量請求突發會影響下一個窗口對限流的判斷。
(2) 滑動窗口限流:
改進了計數器限流,通過維護一個滑動的時間窗口來記錄請求數量,從而更精細地控制請求速率。
優點:解決了臨界問題,能夠更平滑地控制請求流量。
缺點:實現相對復雜,且依舊無法很好應對突發流量給系統帶來的高負荷。
(3) 令牌桶限流:
以恒定速率向令牌桶中添加令牌,請求到來時從桶中取出令牌,若桶中無令牌則拒絕請求。
優點:能夠平滑突發流量,適應性強。
缺點:需要維護令牌桶的狀態,開銷稍大。
(4) 漏桶限流:
請求以固定速率流入漏桶,桶滿則拒絕請求,桶不滿則請求繼續處理。
優點:實現簡單,易于理解。
缺點:應對突發流量時能通過恒定速度放開請求避免系統高負荷,但是可能造成高并發請求延遲。
(5) 基于Redis的限流:
利用Redis的原子操作特性,如INCR、EXPIRE等,實現限流邏輯。
面試官:能詳細說說看計數器限流的基本原理嗎?
計數器限流(也稱為固定窗口限流算法)是一種簡單且直觀的限流方法,其基本原理是在一段時間間隔內對請求進行計數,并將計數結果與設置的最大請求數進行比較,以決定是否允許后續請求通過。以下是對計數器限流基本原理的詳細解釋:

1.時間間隔與計數器
- 時間間隔:計數器限流通常設定一個固定的時間間隔,如1分鐘、5分鐘等。在這個時間間隔內,系統會對接收到的請求進行計數。
- 計數器:系統維護一個計數器變量,用于記錄在當前時間間隔內接收到的請求數量。每當有請求到達時,計數器就會加1。
2.請求計數與比較
- 請求計數:在設定的時間間隔內,每當有請求到達系統時,計數器就會增加相應的數值。這樣,系統就可以實時地跟蹤當前時間間隔內的請求數量。
- 比較操作:系統會將計數器的當前值與預設的最大請求數進行比較。如果計數器的值小于或等于最大請求數,則允許請求通過;如果計數器的值大于最大請求數,則拒絕后續請求,直到時間間隔結束并重置計數器。
3.時間間隔結束與計數器重置
- 時間間隔結束:當設定的時間間隔結束時,系統會自動將計數器重置為0,并開始下一個時間間隔的計數。
- 計數器重置:重置計數器是為了確保在新的時間間隔內,系統能夠重新接收和處理請求。這樣,系統就可以持續地對請求進行限流控制。
以下是一個使用Python實現的簡單計數器限流示例。這個示例使用了一個全局變量來模擬計數器,以及一個時間戳來跟蹤當前時間窗口的開始時間。
import time
from threading import Lock
class CounterRateLimiter:
def __init__(self, max_requests, window_size_in_seconds):
"""
初始化計數器限流器
:param max_requests: 時間窗口內允許的最大請求數
:param window_size_in_seconds: 時間窗口的大小(秒)
"""
self.max_requests = max_requests
self.window_size_in_seconds = window_size_in_seconds
self.request_count = 0
self.window_start_time = time.time()
self.lock = Lock()
def allow_request(self):
"""
檢查是否允許請求通過
:return: 如果允許請求通過則返回True,否則返回False
"""
with self.lock:
current_time = time.time()
# 檢查是否到了新的時間窗口
if current_time - self.window_start_time >= self.window_size_in_seconds:
# 重置計數器和時間窗口
self.request_count = 0
self.window_start_time = current_time
# 檢查請求數量是否超過閾值
if self.request_count < self.max_requests:
self.request_count += 1
return True
else:
return False
# 使用示例
if __name__ == "__main__":
# 允許每分鐘最多10個請求
rate_limiter = CounterRateLimiter(max_requests=10, window_size_in_seconds=60)
# 模擬請求
for i in range(15):
if rate_limiter.allow_request():
print(f"請求 {i + 1} 被允許")
else:
print(f"請求 {i + 1} 被拒絕")
# 模擬請求間隔(例如,每秒一個請求)
time.sleep(1)計數器限流是一種常用的限流策略,具有簡單易用、直觀易懂等優點,但也存在一些明顯的問題,具體包括:
時間臨界點突發流量問題:計數器限流存在“時間臨界點”缺陷,即在時間區間的臨界點附近,如果請求數突然增加,可能會導致短時間內大量請求通過限流檢查,從而對系統造成壓力。
假設我們要求系統在1分鐘之內最多通過100個請求,系統以1分鐘作為時間區間,因此 [0s, 59s] 是一個時間區間,[1min, 1min 59s]是一個時間區間。
假設有一個惡意用戶,他在0:59時,瞬間發送了100個請求,并且1:00又瞬間發送了100個請求。我們希望的是1分鐘內平均最多只能接受200個請求,但其實這個用戶在 1秒里面,瞬間發送了200個請求。
要知道,1分鐘均勻請求100次和1分鐘內的短短幾秒里突發請求100次所帶給系統的壓力是完全不同的。用戶有可能通過算法的這個漏洞,瞬間壓垮我們的應用。
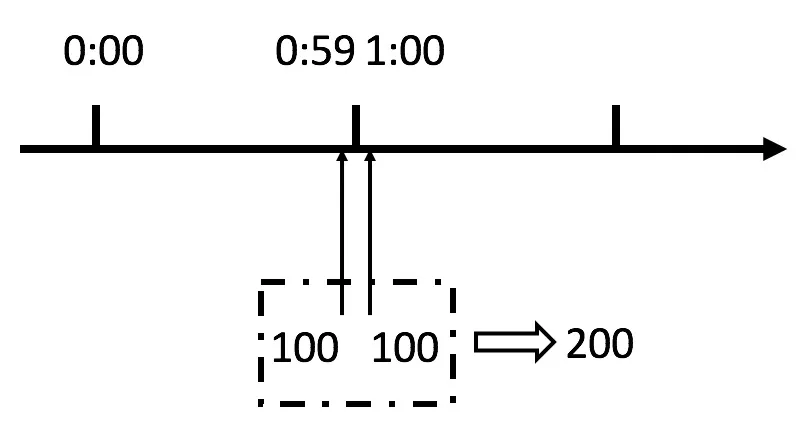
這個問題,本質其實就在于這樣固定周期清空計數器的方式精度太低,不能區分 1 分鐘內均勻請求 100 次,以及只在 1 分鐘內很小的一個時間區間里請求 100 次,這兩種情況。
面試官:那么有沒有什么更好的算法可以解決這個問題呢?
解決這個問題本質就是要解決時間區間的精度問題,而滑動窗口限流算法可以通過將一個大的時間區間進一步劃分為多個小的區間來解決窗口精度問題。
其基本原理可以歸納如下:
1.定義
滑動窗口限流算法通過將大的時間區間劃分為若干個固定大小的小區間(或稱為時間片段),并且以這個大的時間區間作為一個時間窗口,隨著時間的推移這個大的時間窗口可以在小的時間分片上移動,并動態地維護這個大窗口內的請求數量和小時間片內的請求數量,從而實現對流量的精確控制。
2.基本原理
(1) 時間窗口劃分:
將大的時間區間(如上面例子中的1分鐘)劃分為多個固定大小的小區間(例如10秒)。

(2) 窗口滑動:
在第一個一分鐘里,窗口并不會滑動。而之后,每隔一個時間片(也就是每隔10秒),窗口就會往前移動一個時間片。以此類推,隨著時間的推移,窗口會不斷向前滑動。
(3) 請求計數:
在每個小的時間片段內,都維護一個計數器來記錄該時間片內的請求數量。而大的時間窗口內的請求數量等于它里面所有小時間片段的請求數量之和。
當新的請求到達時,根據其到達時間確定其所屬的小時間片段,并在該時間片的計數器上遞增(也就是圖中黃色的時間片),與此同時大窗口內的請求數量也同時增加。
而第一個時間片中的請求數量會被大窗口內丟棄(減法扣去),同時開始加上新的時間片內的請求計數。
(4) 限流判斷:
每次請求到達的時候,都會檢查大窗口內的總請求數量是否超過了預設的閾值。
如果請求數量超過了閾值,則在窗口繼續滑動到下一個時間片之前的請求都會被拒絕,等到10s過去了,窗口滑動到下一個時間片并丟棄掉窗口內第一個時間片的請求量之后,請求才會被允許通過并繼續處理。
3.優點
(1) 靈活性:
滑動窗口限流算法可以根據業務需求動態地調整窗口內時間片的大小(可以調成10秒,也可以調成1秒)。
這使得算法能夠更好地適應不同的流量場景和業務需求。
(2) 精確性:
如果將窗口內的時間片調節的足夠小,滑動窗口限流算法就能夠更有效地應對突發流量。
還是上面那個例子,依舊要求1分鐘內最多處理100個請求,如果我將時間片調整為1秒,窗口就會每秒滑動一次。惡意用戶依舊是在第59秒并發100個請求,再在第60秒并發另外100個請求。
那么當窗口滑動到第60秒的時候,第60秒的100個請求都會被拒絕。
4.缺點
滑動窗口算法在將窗口劃分的很細的情況下,可能會帶來以下缺點:
(1) 算法復雜度增加:
想要進一步提高被控制流量的平滑性,就需要不斷增加窗口的精度,也就是縮小每個區間的大小。當窗口被劃分得非常細時,需要維護的計數器數量會顯著增加。每個子窗口都需要一個獨立的計數器來跟蹤請求數量,這會導致算法在計算和更新計數器時的復雜度增加。
窗口細化意味著需要處理更多的數據點和時間戳。這會增加算法的存儲需求和計算開銷。
(2) 限流效果依舊不穩定:
滑動窗口限流算法的另一個缺點是限流仍然不夠平滑。例如,如果在某個小窗口的開始階段就達到了限流閾值,那么在這個小窗口剩余的時間內,所有新的請求都會被拒絕,這也會影響到用戶體驗。
面試官:能不能具體實現一下滑動窗口限流算法呢?
Redis的有序集合(zset)非常適合實現這種算法,因為zset能夠存儲帶時間戳的分數,并根據分數自動排序。
下面是一個使用Redis的zset實現滑動窗口限流算法的代碼:
import redis
import time
class SlidingWindowRateLimiter:
def __init__(self, redis_client, key_prefix, max_requests, window_size_in_seconds):
self.redis = redis_client
self.key_prefix = key_prefix
self.max_requests = max_requests
self.window_size_in_seconds = window_size_in_seconds
def _get_key(self, user_id):
return f"{self.key_prefix}:{user_id}"
def _get_current_window_start_time(self):
return int(time.time()) // self.window_size_in_seconds * self.window_size_in_seconds
def _add_request(self, user_id):
key = self._get_key(user_id)
window_start_time = self._get_current_window_start_time()
score = time.time()
# 使用管道來確保原子性
with self.redis.pipeline() as pipe:
pipe.zremrangebyscore(key, 0, window_start_time - self.window_size_in_seconds)
pipe.zadd(key, {score: score})
pipe.zcard(key)
result = pipe.execute()
# 移除舊窗口的數據,并添加新請求
_, _, current_count = result
return current_count
def allow_request(self, user_id):
current_count = self._add_request(user_id)
return current_count <= self.max_requests
# 示例使用
if __name__ == "__main__":
# 連接到Redis服務器
redis_client = redis.StrictRedis(host='localhost', port=6379, db=0)
# 創建限流器實例
rate_limiter = SlidingWindowRateLimiter(
redis_client,
key_prefix="rate_limiter",
max_requests=10, # 每窗口最多10個請求
window_size_in_seconds=60 # 窗口大小為60秒
)
# 示例用戶ID
user_id = "user_123"
# 模擬請求
for i in range(15):
if rate_limiter.allow_request(user_id):
print(f"Request {i + 1} allowed.")
else:
print(f"Request {i + 1} denied.")
time.sleep(2) # 每2秒發送一個請求import redis
import time
class SlidingWindowRateLimiter:
def __init__(self, redis_client, key_prefix, max_requests, window_size_in_seconds):
self.redis = redis_client
self.key_prefix = key_prefix
self.max_requests = max_requests
self.window_size_in_seconds = window_size_in_seconds
def _get_key(self, user_id):
return f"{self.key_prefix}:{user_id}"
def _get_current_window_start_time(self):
return int(time.time()) // self.window_size_in_seconds * self.window_size_in_seconds
def _add_request(self, user_id):
key = self._get_key(user_id)
window_start_time = self._get_current_window_start_time()
score = time.time()
# 使用管道來確保原子性
with self.redis.pipeline() as pipe:
pipe.zremrangebyscore(key, 0, window_start_time - self.window_size_in_seconds)
pipe.zadd(key, {score: score})
pipe.zcard(key)
result = pipe.execute()
# 移除舊窗口的數據,并添加新請求
_, _, current_count = result
return current_count
def allow_request(self, user_id):
current_count = self._add_request(user_id)
return current_count <= self.max_requests
# 示例使用
if __name__ == "__main__":
# 連接到Redis服務器
redis_client = redis.StrictRedis(host='localhost', port=6379, db=0)
# 創建限流器實例
rate_limiter = SlidingWindowRateLimiter(
redis_client,
key_prefix="rate_limiter",
max_requests=10, # 每窗口最多10個請求
window_size_in_seconds=60 # 窗口大小為60秒
)
# 示例用戶ID
user_id = "user_123"
# 模擬請求
for i in range(15):
if rate_limiter.allow_request(user_id):
print(f"Request {i + 1} allowed.")
else:
print(f"Request {i + 1} denied.")
time.sleep(2) # 每2秒發送一個請求(1) 初始化:
__init__ 方法中初始化Redis客戶端、key前綴、最大請求數和窗口大小。
(2) 獲取Redis鍵:
_get_key 方法根據用戶ID生成Redis鍵。
(3) 獲取當前窗口開始時間:
_get_current_window_start_time 方法計算當前時間所屬窗口的開始時間(向下取整到窗口大小的倍數)。
(4) 添加請求:
- _add_request 方法使用Redis管道(pipeline)來確保原子性操作。
- 先移除舊窗口的數據(分數小于當前窗口開始時間減去窗口大小的數據)。
- 添加新請求的時間戳到zset中。
- 獲取當前窗口內的請求數量,判斷請求是否允許。
在不使用中間件的情況下我們可以使用純內存數據結構(隊列)結合時間戳來實現滑動窗口限流算法。這種方法適用于單機環境,或者當你不希望/不能使用外部存儲(如Redis)時。
以下是一個使用Python的deque實現滑動窗口限流的示例代碼:
from collections import deque
import time
class SlidingWindowRateLimiter:
def __init__(self, max_requests, window_size_in_seconds):
self.max_requests = max_requests
self.window_size_in_seconds = window_size_in_seconds
self.window = deque() # 存儲 (timestamp, request_id) 元組
def _is_within_window(self, timestamp):
window_start = time.time() - self.window_size_in_seconds
return timestamp >= window_start
def allow_request(self):
current_timestamp = time.time()
# 移除窗口外的請求
while self.window and not self._is_within_window(self.window[0][0]):
self.window.popleft()
# 添加當前請求到窗口
self.window.append((current_timestamp, id(self))) # 使用id(self)作為示例請求ID,實際中應替換為唯一請求標識
# 檢查窗口內的請求數量
if len(self.window) > self.max_requests:
return False
return True
# 示例使用
if __name__ == "__main__":
# 創建限流器實例
rate_limiter = SlidingWindowRateLimiter(max_requests=5, window_size_in_seconds=10)
# 模擬請求
for i in range(10):
if rate_limiter.allow_request():
print(f"Request {i + 1} allowed.")
else:
print(f"Request {i + 1} denied.")
time.sleep(2) # 每2秒發送一個請求(1) 初始化:
__init__ 方法中初始化最大請求數、窗口大小和用于存儲請求記錄的deque。
(2) 檢查時間戳是否在窗口內:
_is_within_window 方法用于檢查給定的時間戳是否在當前窗口內。
(3) 允許請求:
- allow_request 方法首先獲取當前時間戳,然后移除窗口外(即過期)的請求記錄。
- 接著,將當前請求(帶有時間戳和請求ID)添加到窗口中。
- 最后,檢查窗口內的請求數量是否超過最大請求數,并返回相應的結果。
面試官:就像你剛剛說的,滑動窗口限流在面對突發流量的情況下依舊不夠平滑,還有沒有什么限流算法能夠讓系統在面對突發流量的時候更均勻的接收請求呢?
可以使用漏桶算法,當請求速率大于桶的流出速率時,漏桶只會按照桶的流出速率均勻的放出請求給系統處理,而超出速率的請求會被儲蓄在桶中等待處理。
漏桶算法的原理可以簡單描述為:數據(或請求)流入漏桶,桶內的數據以固定的速率流出,控制了系統能夠處理請求的速度。如果桶滿了(即桶的容量到達上限),后續的流量(或請求)會被丟棄,防止系統超載。
具體來說,漏桶算法維持一個具有固定容量的“桶”,該桶接受以任意速率流入的請求,并以固定的速率處理(即“漏出”)這些請求。當桶滿時,任何新進入的請求都將被丟棄。這樣,無論請求到達的速率如何變化,系統處理請求的速率都保持恒定,從而實現了流量整形和限流控制。

漏桶算法的重要參數主要包括以下2個:
- 桶的容量:代表了系統能夠處理的請求的最大數量,也代表了漏桶(包緩存)可以容納的數據包的最大字節數。這個尺寸受限于有效的系統內存。
- 漏出速率:這個速率代表了系統處理數據的速率。它決定了數據從漏桶中注入網絡的速率,從而平滑了突發流量。
在實際應用中,漏桶算法的工作流程大致如下:
- 初始化:設置桶的容量和漏出速率。
- 接收請求:每當有數據(或請求)到達時,先檢查桶的狀態。
- 桶未滿:如果桶未滿,允許數據(或請求)進入桶中,然后等待漏出。
- 桶已滿:如果桶已滿,新到達的數據(或請求)會被丟棄或排隊等待。
- 數據(或請求)處理:數據(或請求)在桶中等待直到之前的請求被處理完,然后以漏出速率再被處理。
優缺點
優點:
- 穩定性好:漏桶算法能夠以固定的速率去控制流量,使得系統處理請求的速率保持恒定,從而有效防止了流量激增導致的服務不穩定。
- 保護后端服務:通過限制請求的處理速率,漏桶算法能夠保護后端服務免受大流量沖擊,避免服務崩潰。
缺點:
- 請求延遲處理:當系統在短時間內有突發的大流量時,由于漏桶的流出速率是固定的,因此無法及時處理這些突發流量,突發流量會被阻塞一段時間才得到處理,還可能導致部分請求被丟棄。
下面是一個使用Python實現的簡單漏桶算法示例實現。
import time
import threading
from collections import deque
class LeakyBucket:
def __init__(self, capacity, leak_rate):
self.capacity = capacity # 桶的容量
self.leak_rate = leak_rate # 漏出速率(每秒漏出的請求數)
self.bucket = deque() # 使用雙端隊列來模擬桶,存儲請求的時間戳
self.lock = threading.Lock() # 線程鎖,用于線程安全
def _leak(self):
"""內部方法,用于模擬漏出請求"""
current_time = time.time()
while self.bucket and (current_time - self.bucket[0]) >= 1.0 / self.leak_rate:
self.bucket.popleft() # 移除最舊的請求
def allow_request(self):
"""判斷是否可以允許一個請求進入桶中"""
with self.lock:
self._leak() # 先嘗試漏出一些請求
current_time = time.time()
if len(self.bucket) < self.capacity:
self.bucket.append(current_time) # 允許請求進入桶中
return True
else:
# 桶已滿,拒絕請求
return False
# 示例使用
if __name__ == "__main__":
bucket = LeakyBucket(capacity=10, leak_rate=5) # 創建一個漏桶,容量為10,漏出速率為5個請求/秒
# 模擬請求到達
for i in range(20):
if bucket.allow_request():
print(f"Request {i} allowed at {time.time():.2f}")
else:
print(f"Request {i} rejected at {time.time():.2f}")
# 模擬請求到達的間隔
time.sleep(0.2)
import time
import threading
from collections import deque
class LeakyBucket:
def __init__(self, capacity, leak_rate):
self.capacity = capacity # 桶的容量
self.leak_rate = leak_rate # 漏出速率(每秒漏出的請求數)
self.bucket = deque() # 使用雙端隊列來模擬桶,存儲請求的時間戳
self.lock = threading.Lock() # 線程鎖,用于線程安全
def _leak(self):
"""內部方法,用于模擬漏出請求"""
current_time = time.time()
while self.bucket and (current_time - self.bucket[0]) >= 1.0 / self.leak_rate:
self.bucket.popleft() # 移除最舊的請求
def allow_request(self):
"""判斷是否可以允許一個請求進入桶中"""
with self.lock:
self._leak() # 先嘗試漏出一些請求
current_time = time.time()
if len(self.bucket) < self.capacity:
self.bucket.append(current_time) # 允許請求進入桶中
return True
else:
# 桶已滿,拒絕請求
return False
# 示例使用
if __name__ == "__main__":
bucket = LeakyBucket(capacity=10, leak_rate=5) # 創建一個漏桶,容量為10,漏出速率為5個請求/秒
# 模擬請求到達
for i in range(20):
if bucket.allow_request():
print(f"Request {i} allowed at {time.time():.2f}")
else:
print(f"Request {i} rejected at {time.time():.2f}")
# 模擬請求到達的間隔
time.sleep(0.2)在這個示例中,LeakyBucket 類實現了漏桶算法。
- __init__ 方法初始化了桶的容量、漏出速率以及用于存儲請求時間戳的雙端隊列。
- _leak 方法是一個內部方法,用于模擬漏出請求的過程,它會檢查桶中最舊的請求是否已經超過了漏出速率所允許的時間,并移除這些請求。
- allow_request 方法用于判斷是否可以允許一個新的請求進入桶中,它首先嘗試漏出一些請求,然后檢查桶是否已滿,如果未滿則允許請求進入并返回 True,否則返回 False 表示請求被拒絕。
面試官:能否說說看與漏桶算法相似的令牌桶算法以及它們的差異呢?
令牌桶算法的基本算法是這樣的:
- 如果我們需要在一秒內限制訪問次數為 N 次,那么就每隔 1/N 的時間,往桶內放入一個令牌;
- 在處理請求之前先要從桶中獲得一個令牌,如果桶中已經沒有了令牌,那么就需要等待新的令牌或者直接拒絕服務;
- 桶中的令牌總數也要有一個限制,如果超過了限制就不能向桶中再增加新的令牌了。這樣可以限制或增加令牌的總數,一定程度上可以避免瞬時流量高峰的問題。
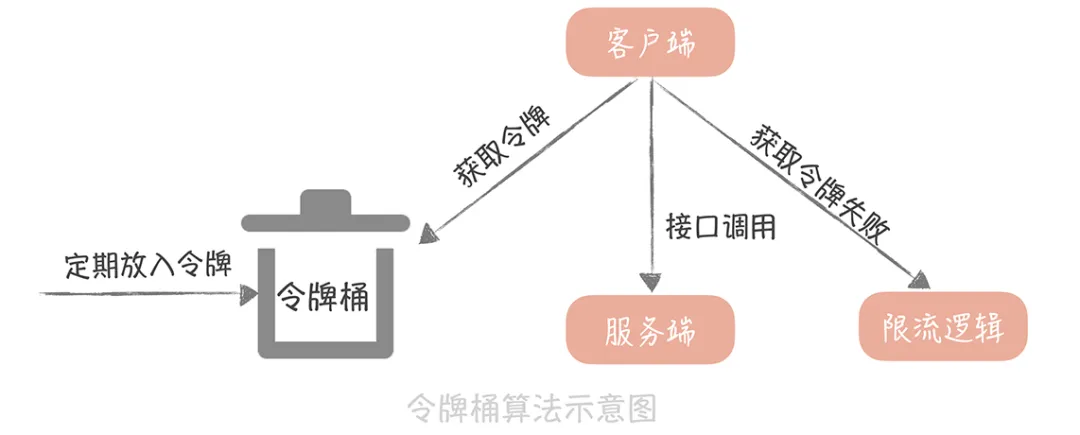
令牌桶算法與漏桶算法的差異點是,漏桶算法的目的是“精確平滑控制速率”,它會完全避免系統受到突發流量的沖擊,讓系統一直以均勻的速度處理請求。
而令牌桶的桶本身具備一定的容量,可以允許一次把桶里的令牌全都取出,因此,令牌桶算法在限制請求的平均速率的同時,還允許一定程度的突發流量。
正常來說,系統并非是受不了一點沖擊的溫室花朵,也還是具有一定的處理突發流量的能力的,令牌桶算法也符合現實業務中90%的時間流量處于均值或者低谷,而偶爾存在并發高峰的場景。
下面是一個令牌桶算法的簡單Python實現。
import time
import threading
class TokenBucket:
def __init__(self, rate, capacity):
"""
初始化令牌桶
:param rate: 令牌生成速率(每秒生成的令牌數)
:param capacity: 桶的容量(最大令牌數)
"""
self.rate = rate
self.capacity = capacity
self.tokens = capacity # 初始令牌數
self.lock = threading.Lock()
self.last_refill_timestamp = time.time() # 上次添加令牌的時間戳
def _add_tokens(self):
"""
根據時間差計算并添加令牌
"""
now = time.time()
elapsed = now - self.last_refill_timestamp
added_tokens = elapsed * self.rate
self.last_refill_timestamp = now
# 添加令牌,但不能超過桶的容量
self.tokens = min(self.capacity, self.tokens + added_tokens)
def consume(self, num_tokens):
"""
嘗試消耗指定數量的令牌
:param num_tokens: 需要消耗的令牌數
:return: 如果成功消耗則返回 True,否則返回 False
"""
with self.lock:
self._add_tokens()
if self.tokens >= num_tokens:
self.tokens -= num_tokens
return True
else:
return False
# 示例使用
if __name__ == "__main__":
# 令牌生成速率 5 個/秒,桶容量 10 個
bucket = TokenBucket(rate=5, capacity=10)
for i in range(15):
if bucket.consume(1):
print(f"Successfully consumed 1 token. Current tokens: {bucket.tokens}")
else:
print("Failed to consume token. Not enough tokens in the bucket.")
time.sleep(0.5) # 每 0.5 秒嘗試消耗一次此外還需要注意的是使用令牌桶算法就需要存儲令牌的數量以及申請獲取令牌,如果是單機上實現限流的話,可以在進程中使用一個變量來存儲;但是如果在分布式環境下,不同的機器之間無法共享進程中的變量,我們就一般會使用 Redis 來存儲這個令牌的數量。
這樣的話,每次請求的時候都需要請求一次 Redis 來獲取一個令牌,會增加幾毫秒的延遲,性能上會有一些損耗。因此,一個折中的思路是:我們可以在每次取令牌的時候,不再只獲取一個令牌,而是獲取一批令牌,這樣可以盡量減少請求 Redis 的次數。
面試官:如何實現不僅對總流量限流,也對單個用戶的在指定長度的時間段限流?
舉個例子,如果我需要對總流量限流為每分鐘1萬個請求,對單個用戶限流為每分鐘60個請求。這就意味著對于用戶A來說,如果A請求時已經觸發總流量1萬個請求的限流,那么A無法訪問;或者如果A請求時已經在1分鐘內請求超過了60次,那么A也還是無法訪問。
此時我們可以設置了兩個令牌桶:一個是全局的令牌桶,一個是以 userid 為 key,按照用戶來劃分的令牌桶。
這里用兩個令牌桶做了一個組合,就可以即做到對總流量限流,也對用戶身份限流:
在全局令牌桶還有令牌的情況下,判斷全局的令牌桶,如果全局令牌桶沒有令牌了,那么觸發限流拒絕訪問。如果全局令牌桶還有令牌,就再去檢查用戶令牌桶;
在用戶令牌桶有令牌的情況下,用戶A的請求可以通過。用戶令牌桶沒有令牌的情況下,用戶A的請求會被拒絕掉。
這樣一來,就可以保證其他用戶的請求不會受到影響。























