MySQL 是什么?架構(gòu)是怎么樣的?
你是一個(gè)程序員,你做了一個(gè)網(wǎng)站應(yīng)用,站點(diǎn)里的用戶數(shù)據(jù),需要存到某個(gè)地方,方便隨時(shí)讀寫。
很容易想到可以將數(shù)據(jù)存到文件里。
但如果數(shù)據(jù)量很大,想從大量文件數(shù)據(jù)中查找某部分?jǐn)?shù)據(jù),并更新,是一件很痛苦的事情。
那么問題就來了,有辦法可以解決這個(gè)問題嗎?
好辦,沒有什么是加一層中間層不能解決的,如果有,那就再加一層。
這次我們要加的中間層是 MySQL。
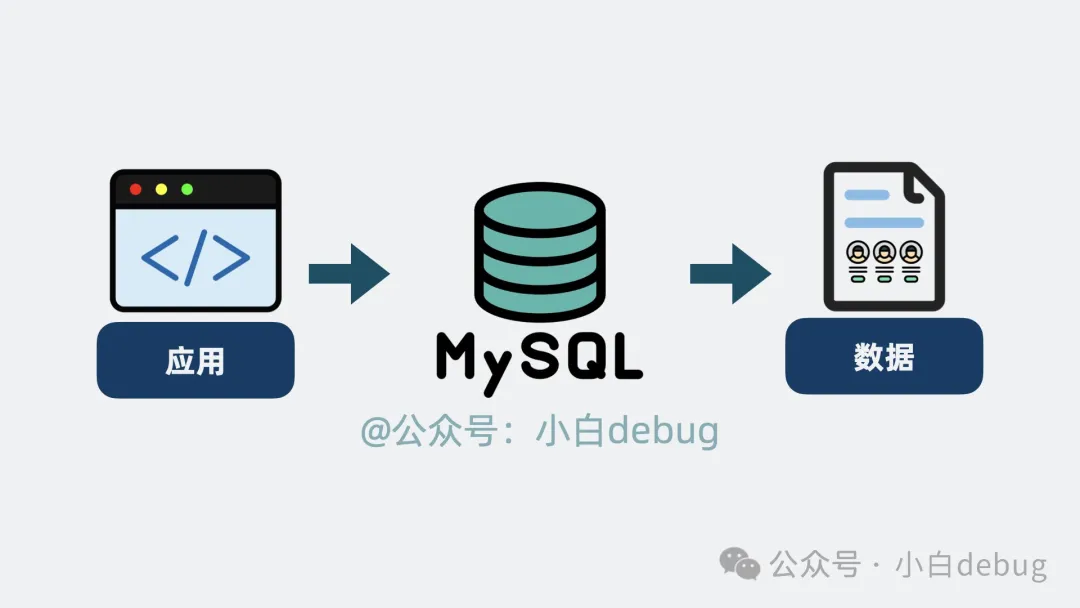
mysql是數(shù)據(jù)和應(yīng)用的中間層
什么是 MySQL
Mysql數(shù)據(jù)庫,是一款存放和管理數(shù)據(jù)的軟件, 它介于應(yīng)用和數(shù)據(jù)之間,通過一些設(shè)計(jì),將大量數(shù)據(jù),變成一張張像 excel 的數(shù)據(jù)表。為應(yīng)用提供創(chuàng)建(Create), 讀取(Read), 更新(Update), 刪除(Delete)等核心操作。
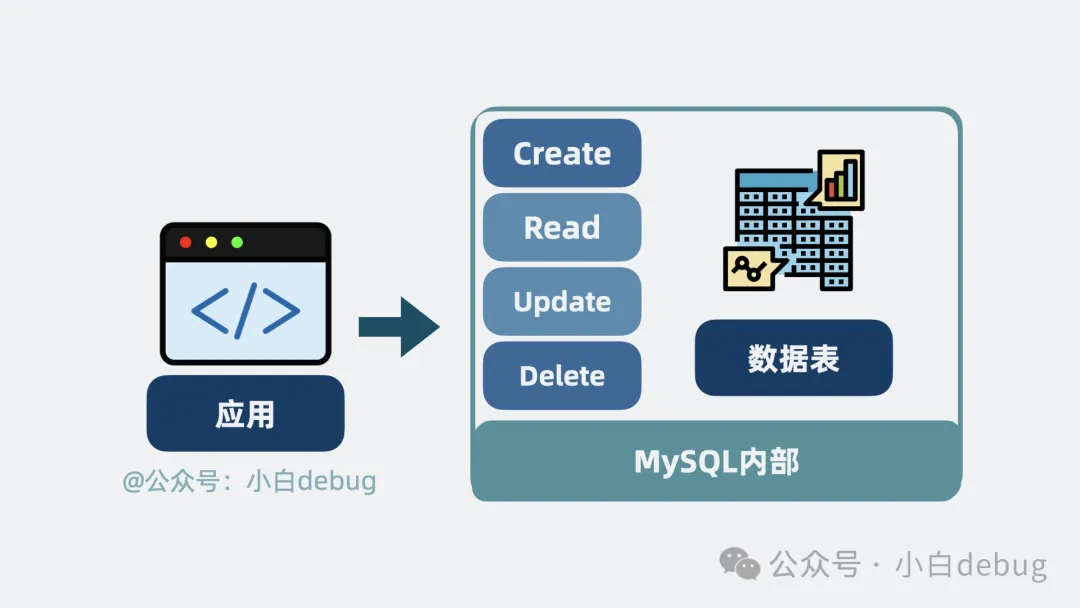
MySQL是什么
我們來看下它是怎么實(shí)現(xiàn)的。
數(shù)據(jù)頁
MySQL 將數(shù)據(jù)組織成 excel 表的樣子。
excel 文件在磁盤上是個(gè)xls 文件,MySQL 的數(shù)據(jù)表也類似,在磁盤上則是個(gè)ibd 后綴的文件。

ibd文件是什么
數(shù)據(jù)表越大,磁盤上的 ibd 文件也就越大。
直接讀寫一個(gè)大文件里的全部數(shù)據(jù)會很慢,所以 MySQL 將數(shù)據(jù)拆成一個(gè)個(gè)數(shù)據(jù)頁,每頁大小 16KB。這樣我們讀寫部分表數(shù)據(jù)的時(shí)候,就只需要讀取磁盤里的幾個(gè)數(shù)據(jù)頁就好。
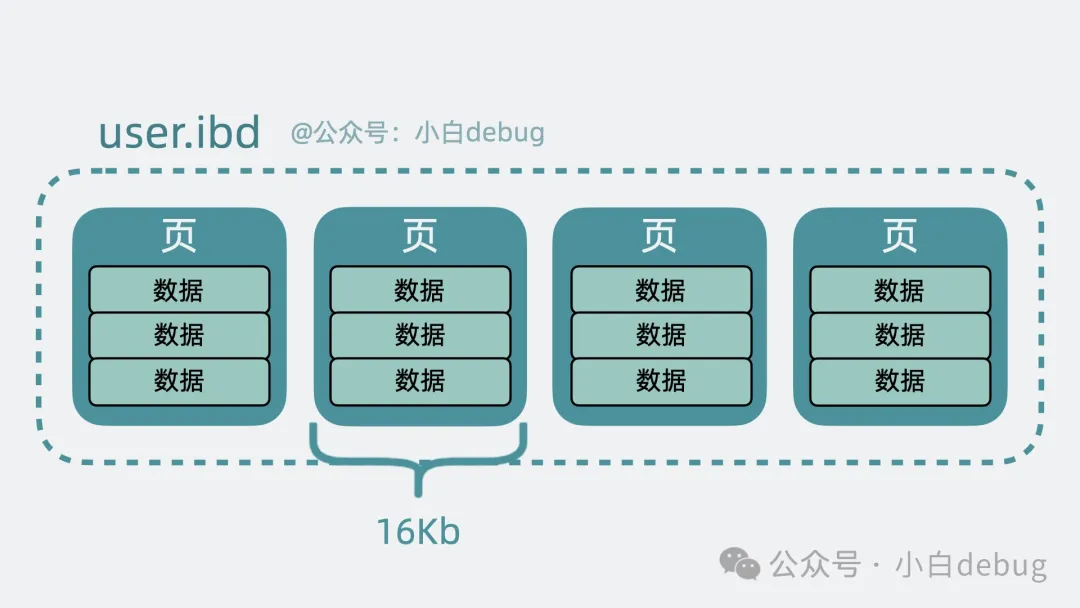
MySQL將文件分成多個(gè)數(shù)據(jù)頁
索引
但數(shù)據(jù)頁那么多,查某條數(shù)據(jù)時(shí),怎么知道要讀哪些數(shù)據(jù)頁?
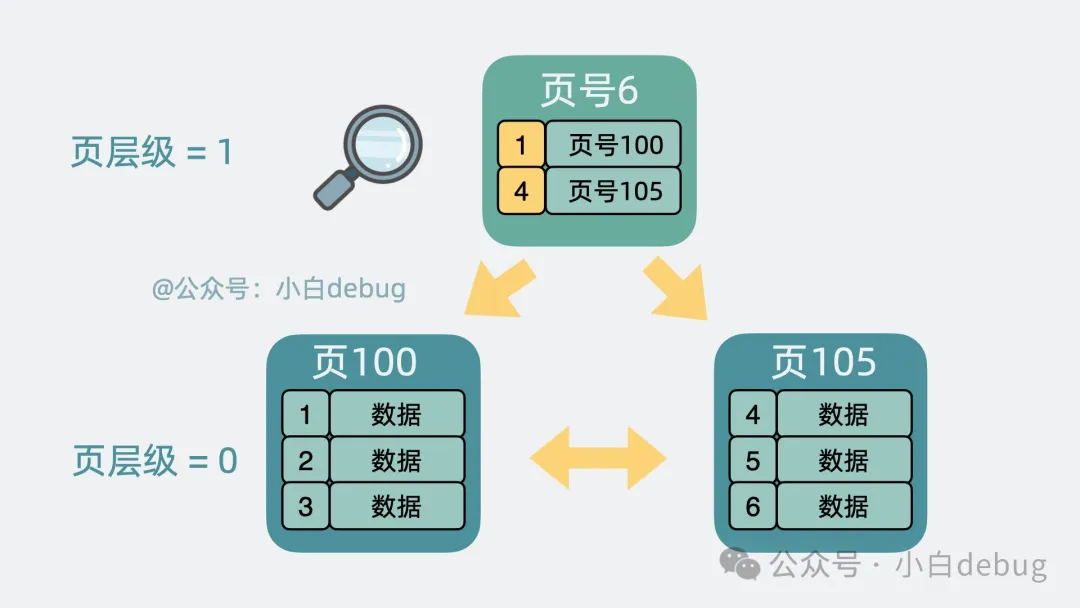
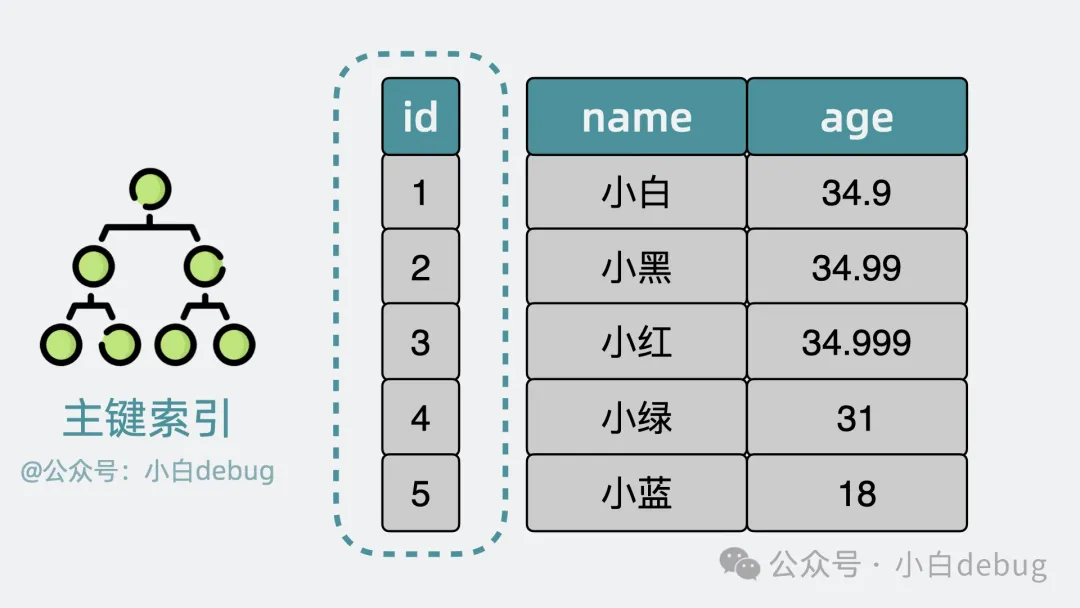
好辦,可以為每個(gè)數(shù)據(jù)頁加入頁號,再為每行數(shù)據(jù)加個(gè)序號,這個(gè)序號其實(shí)就是所謂的主鍵。
按主鍵大小排序,將每個(gè)數(shù)據(jù)頁里最小的主鍵序號和所在頁的頁號提出來,放入到一個(gè)新生成的數(shù)據(jù)頁中,并且給數(shù)據(jù)頁加入層級的概念。
這樣我們就可以通過上層的數(shù)據(jù)頁快速縮小查找范圍,加速查找數(shù)據(jù)頁的過程。
現(xiàn)在頁跟頁之間看起來就像是一棵倒過來的樹,這棵可以加速查找數(shù)據(jù)頁的樹,就是我們常說的B+樹索引。
B+樹索引
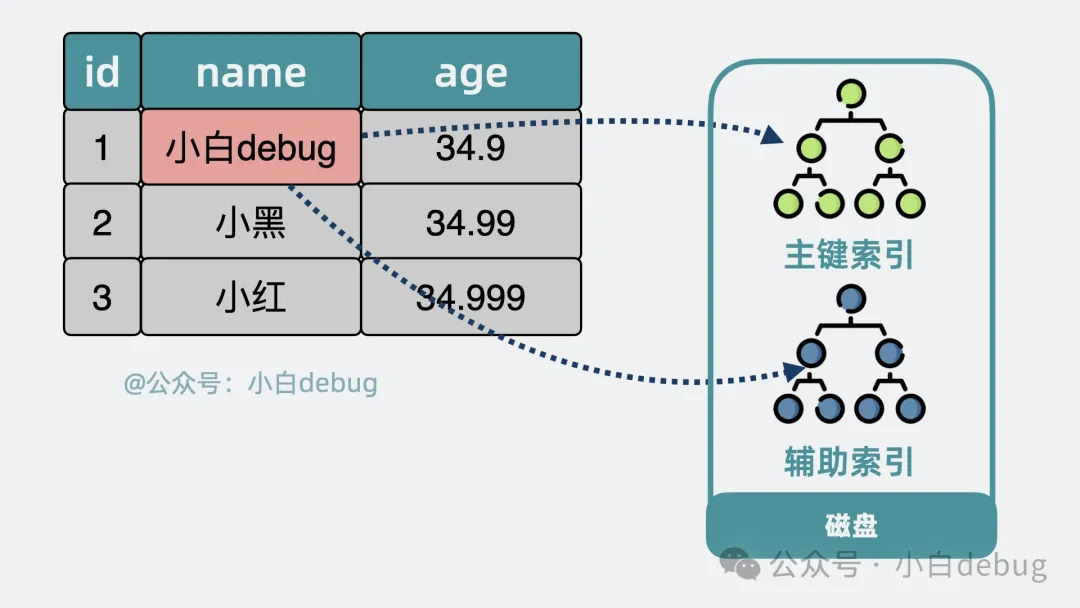
上面提到的是針對主鍵的索引,也就是主鍵索引。
主鍵索引
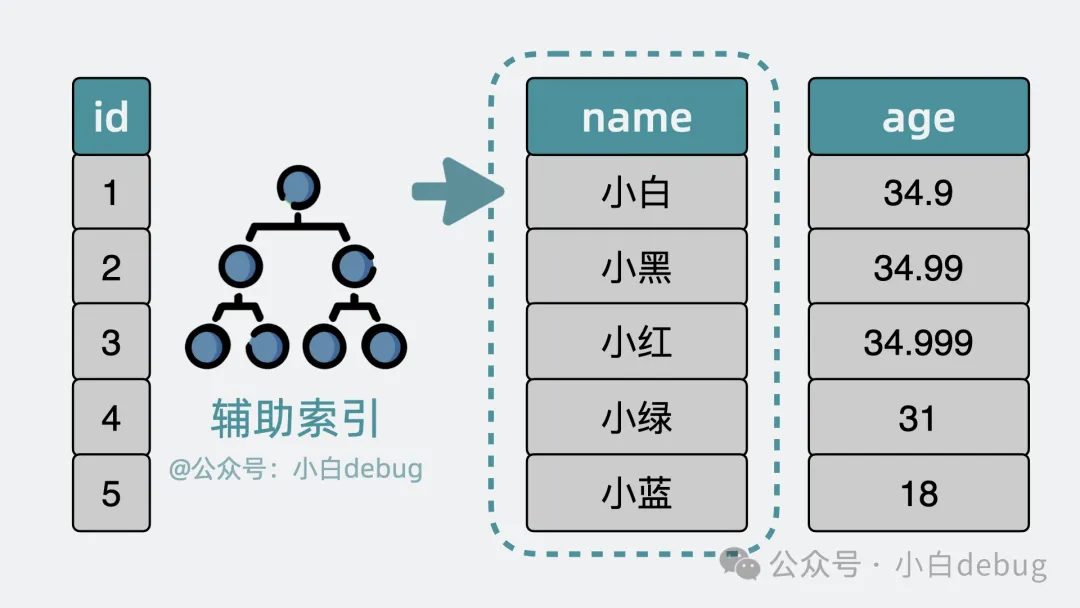
按同樣的思路,也可以為其他數(shù)據(jù)表的列去建立索引,比如用戶表的名稱字段,這樣我們就能快速查找到名字為 xx 的用戶有哪些,這就是所謂的輔助索引。
輔助索引
Buffer Pool
但就算有了索引,數(shù)據(jù)也還是在磁盤上。每次都讀磁盤太慢了。有辦法提升下性能嗎?
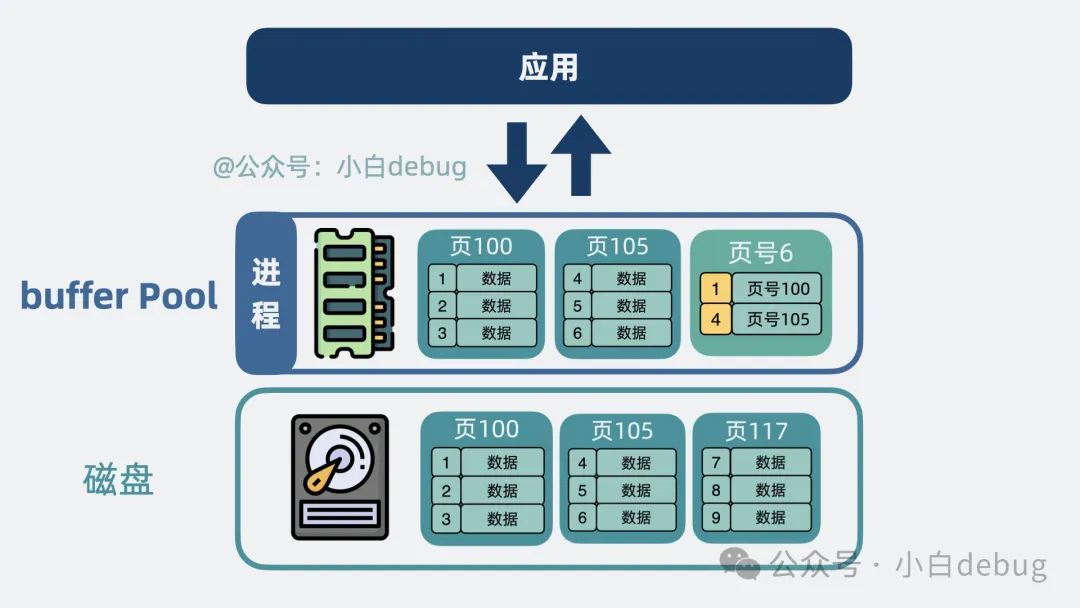
有!在磁盤數(shù)據(jù)和應(yīng)用之間,加一層進(jìn)程內(nèi)緩存,緩存里裝的就是前面提到的 16KB 數(shù)據(jù)和索引頁, 它就是所謂的 Buffer Pool。
buffer pool是什么
讀數(shù)據(jù)的時(shí)候優(yōu)先讀 Buffer Pool,有數(shù)據(jù)就返回,沒數(shù)據(jù)才去磁盤里讀取,減少了讀磁盤的次數(shù),大大提升了性能。
但問題就來了,我們知道,文件讀取,默認(rèn)會先將文件數(shù)據(jù)加載到操作系統(tǒng)的文件緩存中,同樣都是緩存,為什么還要整 Buffer Pool 這死出?
這是因?yàn)檫M(jìn)程自己維護(hù)的 Buffer Pool ,可以定制更多緩存策略,還能實(shí)現(xiàn)加鎖等各種數(shù)據(jù)表高級特性。
也正是因?yàn)橐呀?jīng)有了 Buffer Pool,所以也就沒必要使用操作系統(tǒng)的文件緩存了,所以 Buffer Pool 通過"直接 I/O" 模式, 繞過操作系統(tǒng)的緩存機(jī)制,直接從磁盤讀寫數(shù)據(jù)。
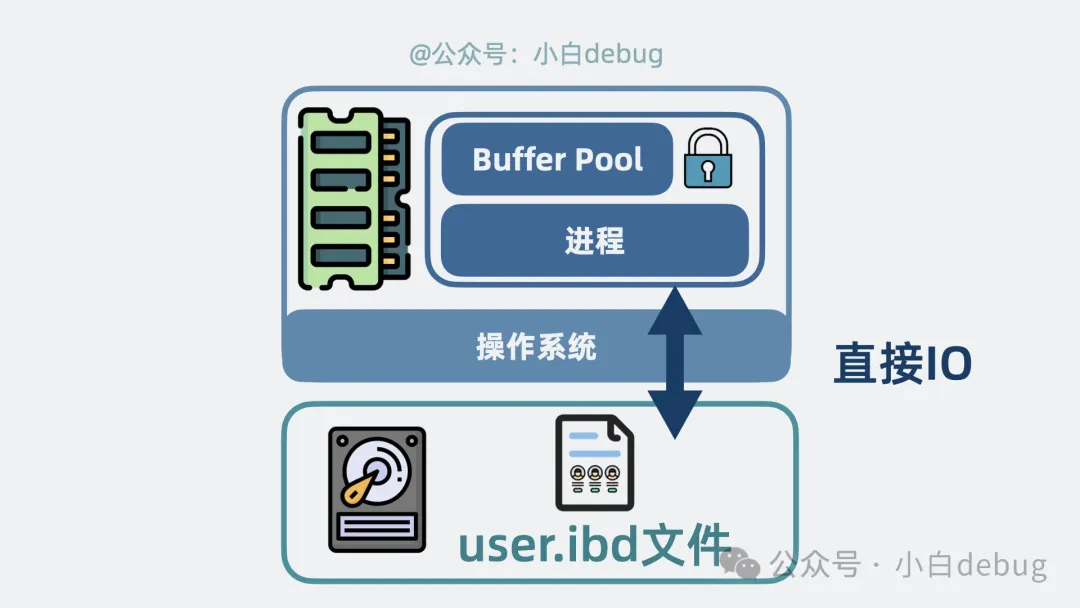
buffer pool直接IO
自適應(yīng) hash 索引
就算有了 buffer pool,要查到某個(gè)數(shù)據(jù)頁,也依然要查找 B+樹,查詢復(fù)雜度 O(lgn)。能更快嗎?
能!可以使用查詢復(fù)雜度為 **O(1)**的 hash 表進(jìn)行優(yōu)化。
記錄每個(gè)數(shù)據(jù)頁的查詢頻率,對于熱點(diǎn)數(shù)據(jù)頁,我們以查詢的值為 key,數(shù)據(jù)頁地址為 value,構(gòu)建 hash 表。
比如name為 'xiaobai' 的數(shù)據(jù)頁,被頻繁查詢,那 key 就是 xiaobai,value 就是包含 xiaobai 記錄的數(shù)據(jù)頁的地址。
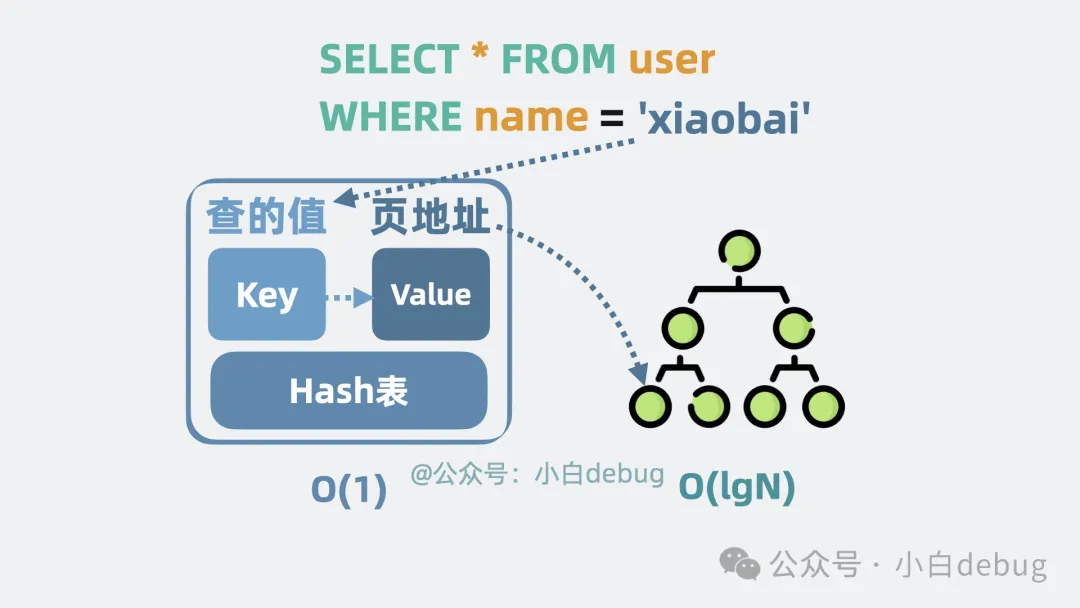
哈希的key和value
這個(gè) hash 表,就是所謂的自適應(yīng)哈希索引,Adaptive Hash Index。
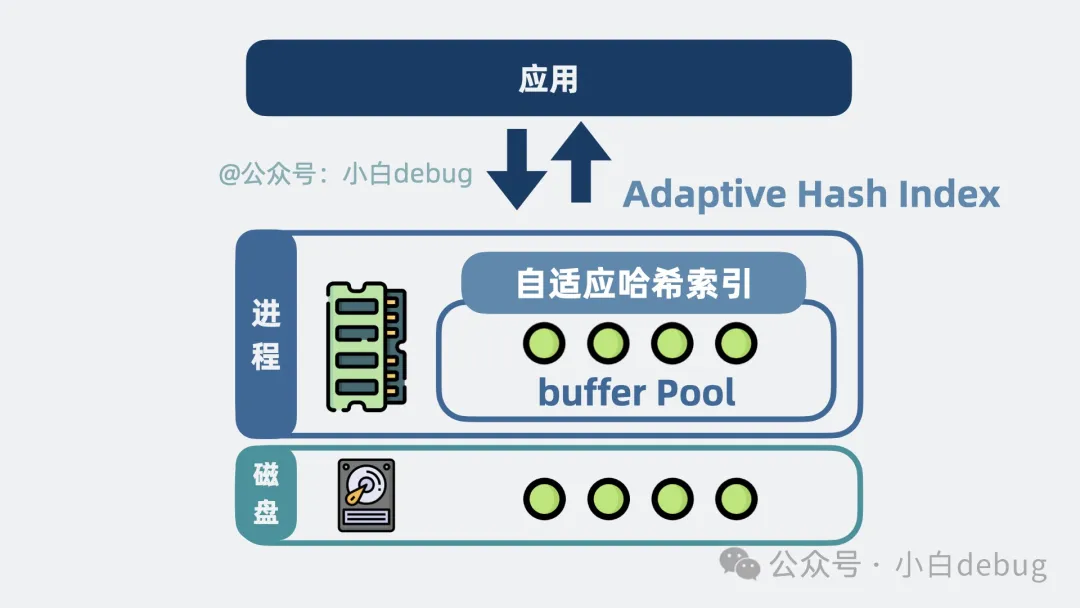
自適應(yīng)哈希
Change Buffer
有了自適應(yīng) hash 索引的加持,讀性能提高了。那寫性能也能優(yōu)化嗎?
能!
大部分?jǐn)?shù)據(jù)表,除了主鍵索引外,我們還會加一些輔助索引。比如對用戶名加個(gè)輔助索引。
那對于這類數(shù)據(jù)表的寫操作,更新完主鍵索引的數(shù)據(jù)頁之后,還需要更新輔助索引頁。這樣讀取輔助索引頁的磁盤 IO 必然少不了。
更新主鍵和輔助索引
怎么辦呢?我們可以先將要寫入的數(shù)據(jù)收集到一塊內(nèi)存里,等哪天磁盤里的索引頁正好被讀入 Buffer pool 的時(shí)候,再將寫入數(shù)據(jù)應(yīng)用到索引頁中。
通過這個(gè)方式減少大量的磁盤 IO,提升性能。
而這個(gè)將寫操作收集起來的地方,就是所謂的 Change Buffer,它其實(shí)是 Buffer pool 的一部分。

Change Buffer的更新流程
Undo Log
在數(shù)據(jù)庫中,有一個(gè)叫事務(wù)的概念。不了解沒關(guān)系,說白了,就是可以讓多行數(shù)據(jù),要么同時(shí)更新成功,要么同時(shí)更新失敗。也就是所謂的原子性。

事務(wù)是什么
為了實(shí)現(xiàn)這一點(diǎn),我們就需要知道寫數(shù)據(jù)時(shí)每行數(shù)據(jù)原來長啥樣,方便對更新后的數(shù)據(jù)行,進(jìn)行回滾,因此就有了 Undo Log。
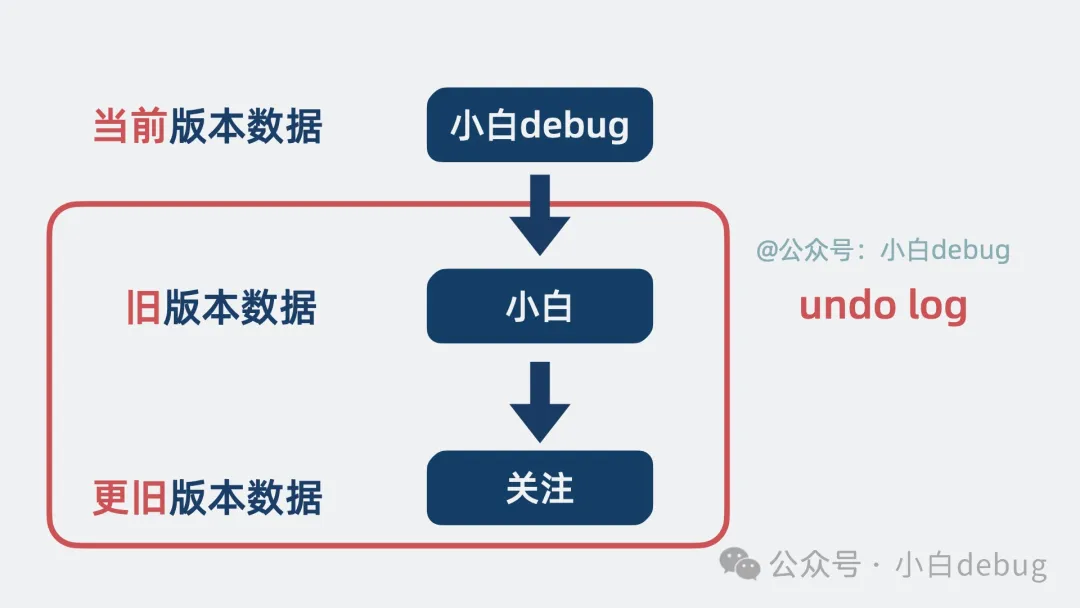
undo log回滾
更新 buffer pool 數(shù)據(jù)頁的時(shí)候:
- 會用舊數(shù)據(jù)生成 undo log 記錄,存儲在 Buffer Pool 中的特殊 undo log 內(nèi)存頁中。
- 并隨著 buffer pool 的刷盤機(jī)制,不定時(shí)寫入到磁盤的 undo log 文件中。
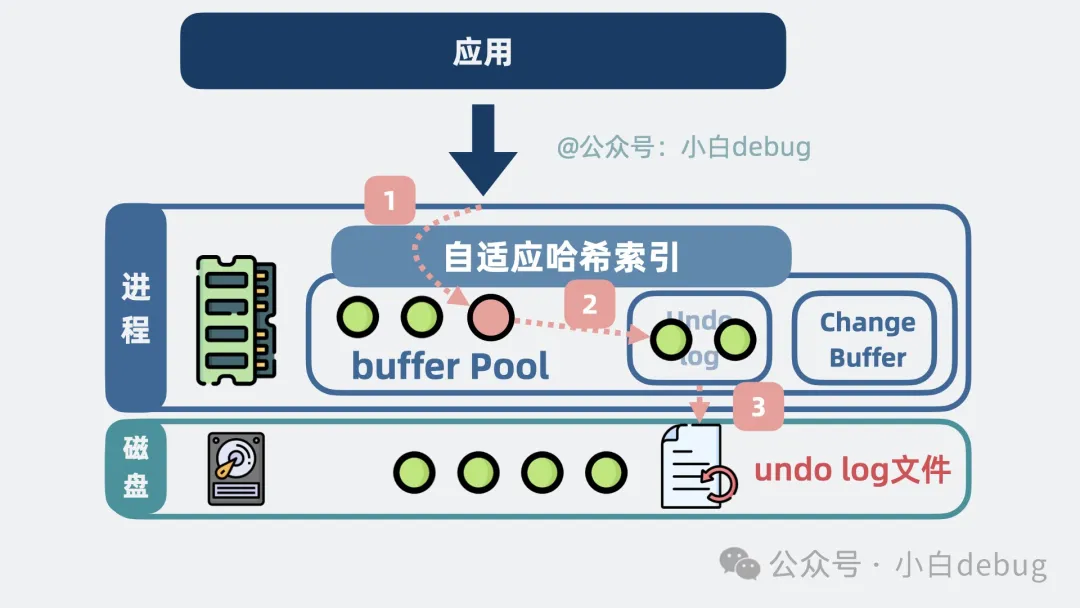
undo log的寫入流程
Redo Log
上面提到的都是 buffer pool 相關(guān)的內(nèi)容,它們本質(zhì)上都是內(nèi)存。
如果內(nèi)存數(shù)據(jù)只寫了一半到磁盤中,數(shù)據(jù)庫進(jìn)程就崩了,那一個(gè)事務(wù)里的多行數(shù)據(jù)就沒能做到"同時(shí)更新成功"。
怎么辦呢?
好辦,我們將事務(wù)中更新數(shù)據(jù)行的操作都寫入到 redo log buffer 內(nèi)存中,然后在事務(wù)提交的時(shí)候進(jìn)行 redo log 刷磁盤,將數(shù)據(jù)固化到 redo log 文件中。
數(shù)據(jù)庫進(jìn)程崩潰重啟后,就能通過 redo log file 找到歷史操作記錄,重做數(shù)據(jù)。保證了事務(wù)里的多行數(shù)據(jù)變更,要么都成功,要么都失敗。

redo log的寫入流程
這時(shí)候問題就來了,我有這功夫更新 redo log file 文件,直接將 buffer pool 的數(shù)據(jù)寫入到磁盤不香嗎?
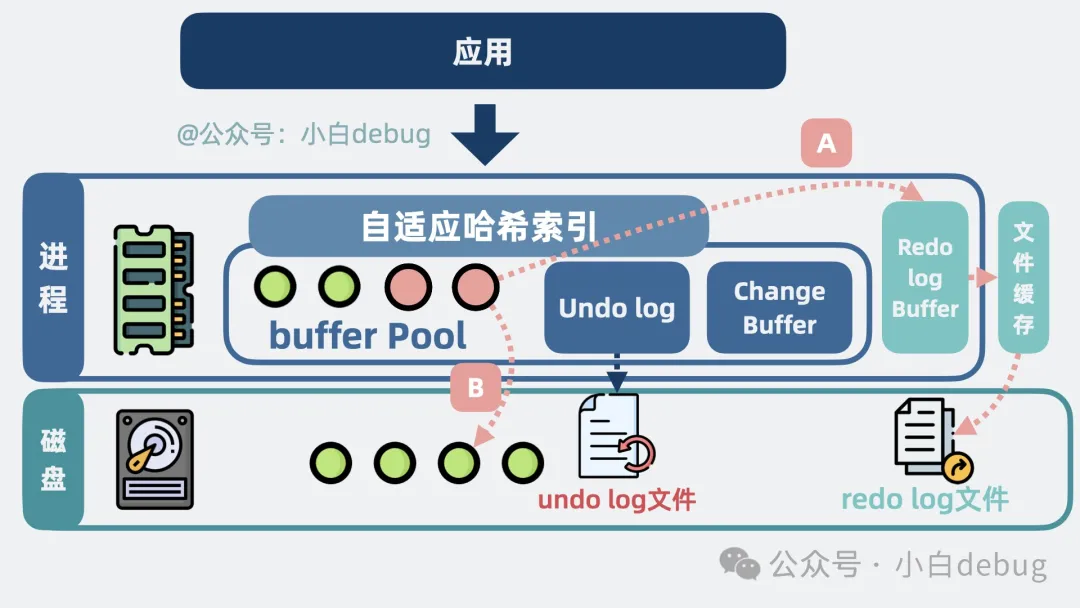
為什么不直接寫磁盤數(shù)據(jù)頁
不太一樣,redo log file 是順序?qū)懭氲模琤uffer pool 的內(nèi)存數(shù)據(jù)是隨機(jī)分散在磁盤各處的,順序?qū)懘疟P性能是隨機(jī)寫的幾十倍,所以很多存儲系統(tǒng)在寫數(shù)據(jù)時(shí)都會搞個(gè)日志來記錄操作,方便服務(wù)重啟后進(jìn)行數(shù)據(jù)對賬,確保數(shù)據(jù)的一致性和完整性,這類操作就是所謂的 Write-Ahead Logging (WAL) 。
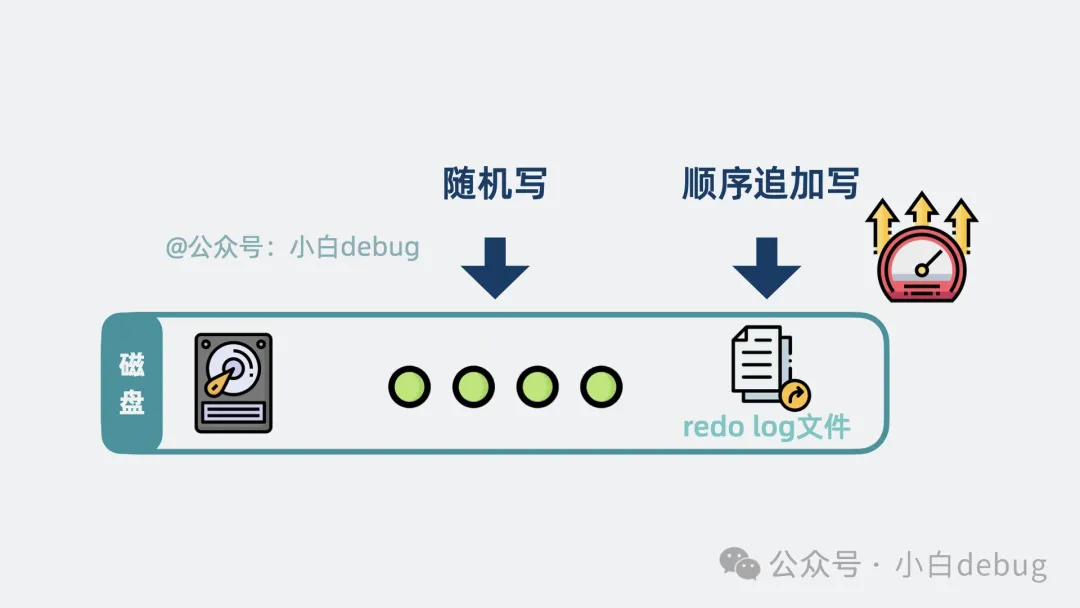
順序?qū)懕入S機(jī)寫快很多
但問題又來了,redo log buffer 也是內(nèi)存,buffer pool 也是內(nèi)存,如果 redo log buffer 里的數(shù)據(jù)還沒來得及寫入到 redo log,數(shù)據(jù)庫進(jìn)程就崩了,那 redo log buffer 里的數(shù)據(jù)不也丟了嗎?
是的,所以 redo log 的作用并不是保證所有數(shù)據(jù)不丟失,而是確保已提交事務(wù)的變更不會丟失。但因?yàn)?redo log 刷盤頻率很高,所以丟失數(shù)據(jù)的概率很低。
redo log 本質(zhì)上是寫入性能和數(shù)據(jù)完整性折中的產(chǎn)物,做架構(gòu)就是這樣,做到最后總是需要通過犧牲某些東西去換取另一樣?xùn)|西,果然,程序員才是真正的煉金術(shù)師。
Innodb 是什么
我們將上面提到的內(nèi)容,分為內(nèi)存和磁盤兩部分,一部分是內(nèi)存里的自適應(yīng)哈希,buffer pool,以及 redo log buffer。另一部分是磁盤里存放行數(shù)據(jù)和索引的.ibd 文件, 以及 undo log, redo log 等文件。它們共同構(gòu)成了 innodb 存儲引擎。并對外提供一系列函數(shù)接口。
比如操作數(shù)據(jù)行的 write_row(), update_row(),以及操作數(shù)據(jù)表的 create(), drop()等等接口。
我們平時(shí)寫的 SQL 語句,最終都會轉(zhuǎn)換成 InnoDB 提供的這些接口函數(shù)調(diào)用。
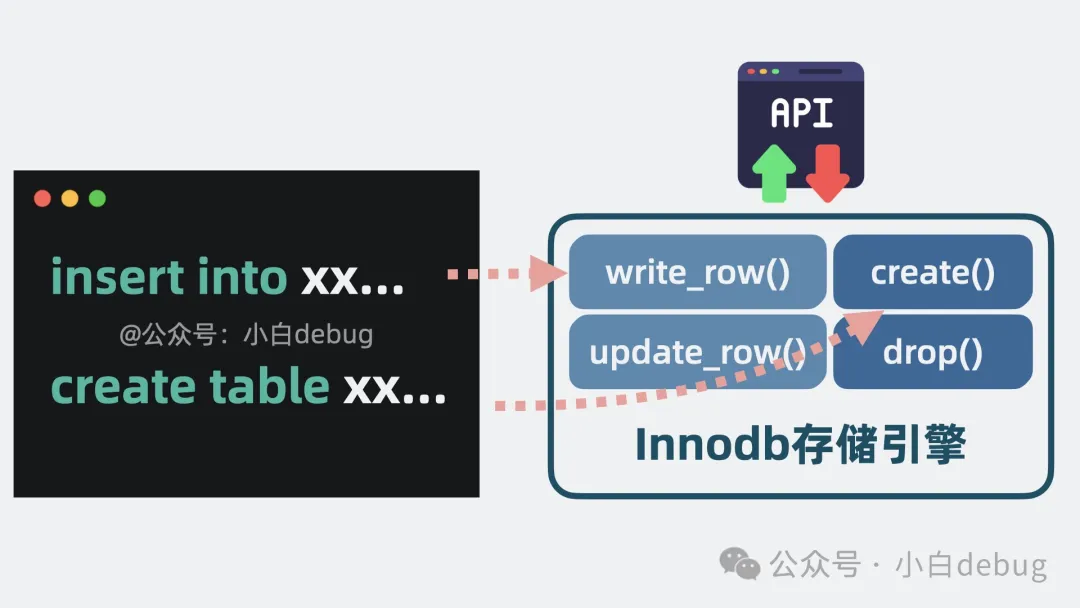
innodb提供的函數(shù)接口
比如:
- INSERT 語句會調(diào)用 write_row() 接口來插入數(shù)據(jù)行。
- UPDATE 語句會調(diào)用 update_row() 接口來更新數(shù)據(jù)行。
- CREATE TABLE 語句會調(diào)用 create() 接口來創(chuàng)建新表。
- DROP TABLE 語句會調(diào)用 drop() 接口來刪除表。
但問題就來了,我們平時(shí)讀寫 mysql 用的 sql 語句,是怎么轉(zhuǎn)成存儲引擎的函數(shù)接口的呢?
那就需要介紹 Server 層了。
Server 層是什么
Server 層,本質(zhì)上是 sql 語句 和 innodb 存儲引擎之間的中間層。
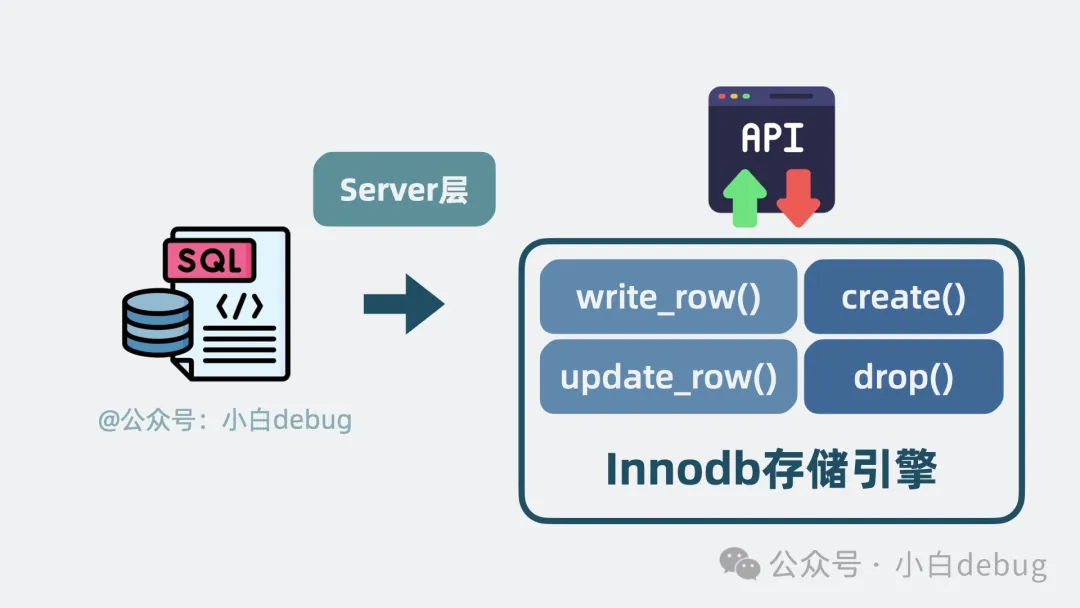
server層
在 Server 層內(nèi)提供一個(gè)連接管理模塊,用于管理來自應(yīng)用的網(wǎng)絡(luò)連接。
并提供一個(gè)分析器,用于判斷 SQL 語句有沒有語法錯(cuò)誤,比如 select,是不是少打了一個(gè)l。
再提供一個(gè)優(yōu)化器,用于根據(jù)一定的規(guī)則選擇該用什么索引,生成執(zhí)行計(jì)劃。
之后,提供一個(gè)執(zhí)行器,根據(jù)執(zhí)行計(jì)劃去調(diào)用Innodb 存儲引擎的接口函數(shù)。
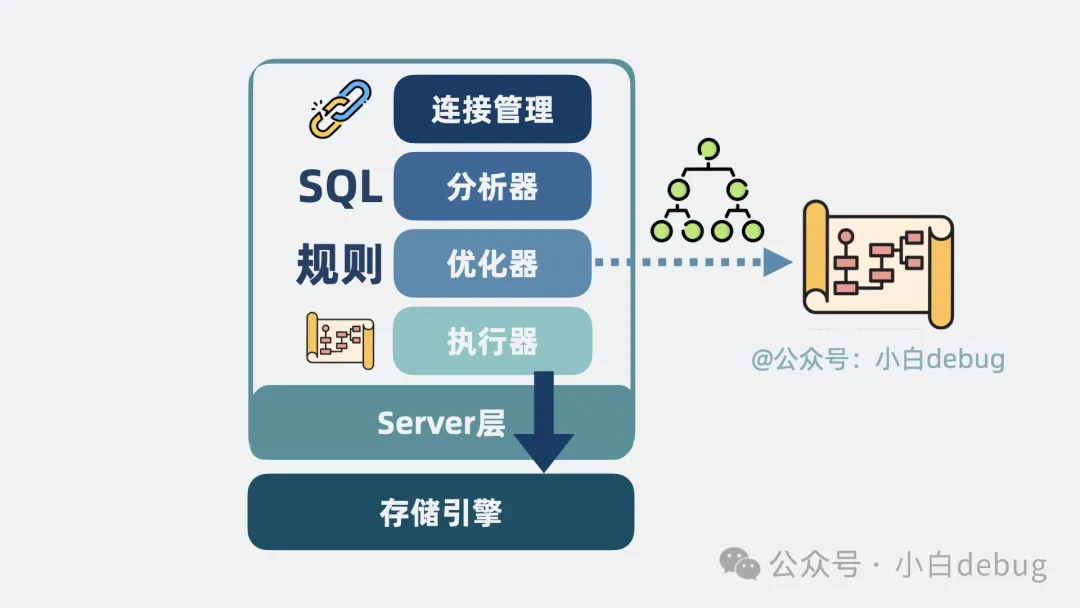
server層做了哪些事情
server 層和存儲引擎層共同構(gòu)成了一個(gè)完整的數(shù)據(jù)庫,它就是我們常說的 MySQL 數(shù)據(jù)庫。
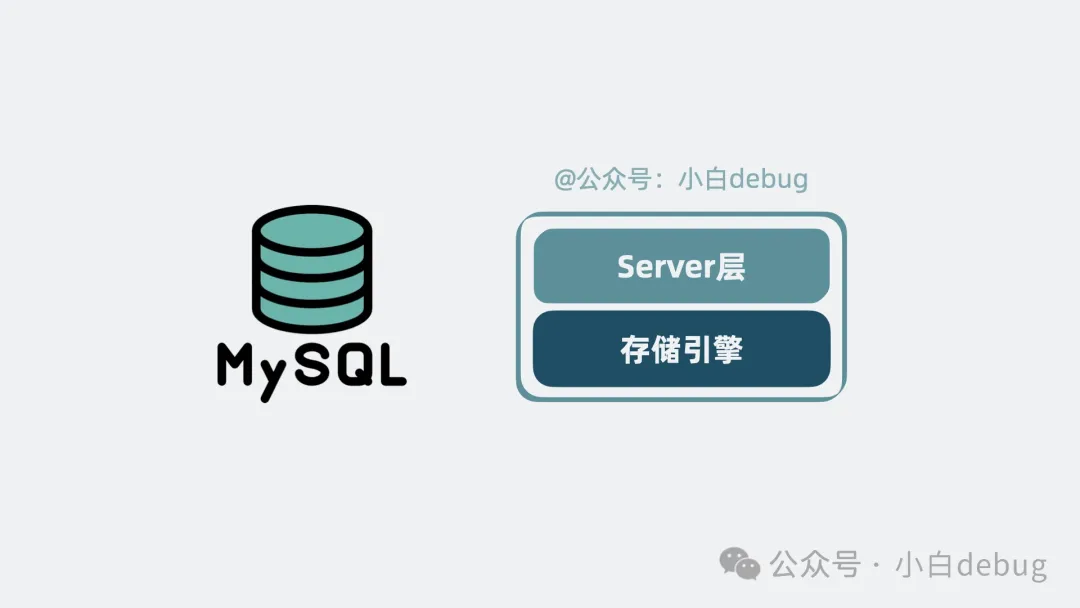
MySQL是什么
并且,server 層和存儲引擎層是通過接口函數(shù)進(jìn)行解耦的,換句話說就是,只要實(shí)現(xiàn)了上面這些接口函數(shù),就能作為存儲引擎與 Server 層對接。
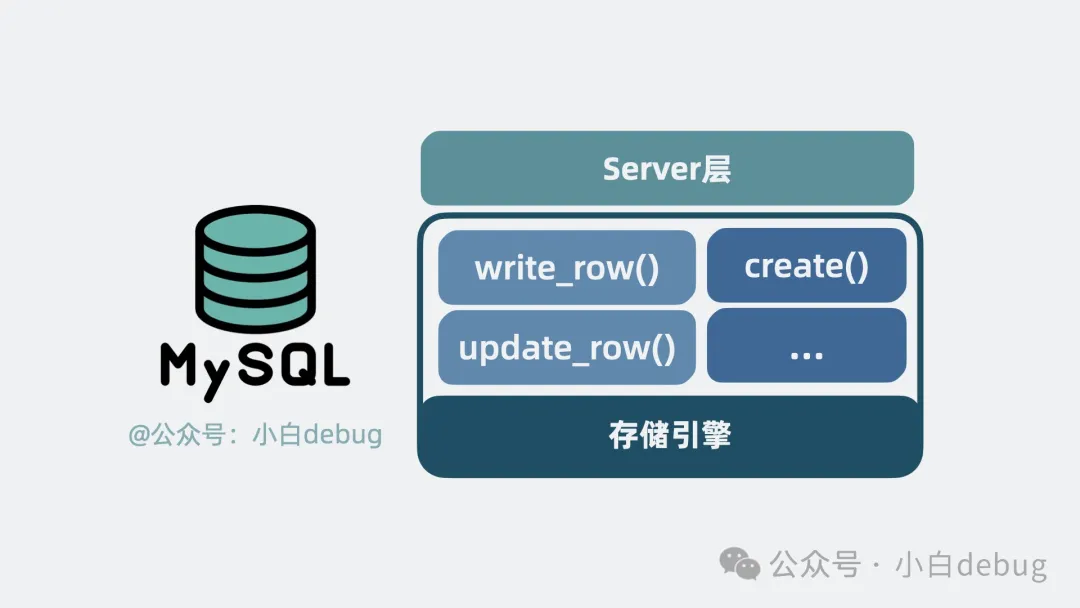
引擎解耦
比如,MySQL 早期用的是 myisam 存儲引擎,后來才支持的 innodb。

常用存儲引擎有哪些
binlog 是什么
你聽說過刪庫跑路吧,為了防止數(shù)據(jù)庫表被刪除帶來的影響, server 層會將歷史上所有變更操作記錄到磁盤上的日志文件中,這個(gè)日志文件就是所謂的 binlog。一旦誤刪表,就可以利用 binlog 來恢復(fù)數(shù)據(jù)。
那么問題就來了,innodb 有一個(gè) redo log 也做類似的事情,為什么還要多此一舉?評論區(qū)告訴我答案。
這是因?yàn)?redo log 是環(huán)狀寫入的,后面寫的內(nèi)容最終會覆蓋前面的內(nèi)容,也就是不會記錄所有歷史寫操作,而 binlog 卻會記錄所有歷史變更。并且 binlog 位于 server 層,這樣不管底層的存儲引擎是什么,都能復(fù)用這部分能力。
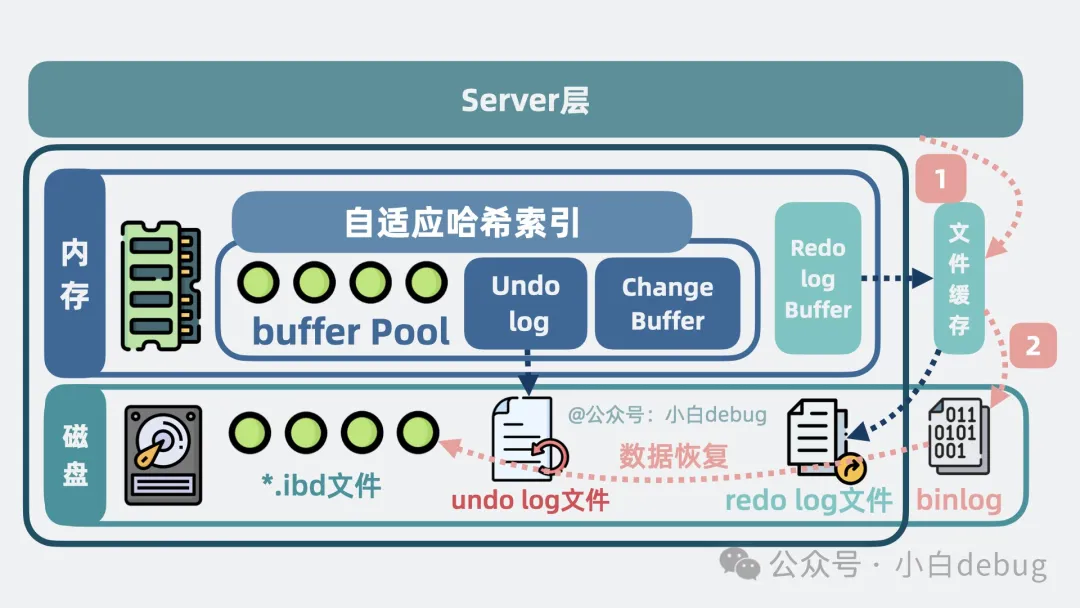
binlog寫入流程
MySQL 主從架構(gòu)
由于 binlog 記錄了一個(gè) MySQL 的所有變更操作,因此我們還可以利用 binlog 數(shù)據(jù),"復(fù)制"一個(gè)新的 MySQL 出來。原來的 master 叫主數(shù)據(jù)庫,復(fù)制出來的則是從數(shù)據(jù)庫,主數(shù)據(jù)庫負(fù)責(zé)承接寫流量,從數(shù)據(jù)庫負(fù)責(zé)讀流量,這樣就可以讓 MySQL 承接更高的讀寫流量。它就是經(jīng)典的 MySQL 主從同步架構(gòu)。
數(shù)據(jù)庫查詢更新流程
接下來我們用實(shí)際例子將上面提到的內(nèi)容串起來。首先不管是查詢還是更新操作,客戶端都會先跟 mysql 建立網(wǎng)絡(luò)連接,并將 sql 發(fā)送到 server 層,經(jīng)過分析器解析 sql 語法、優(yōu)化器選擇索引生成執(zhí)行計(jì)劃,最終給到執(zhí)行器調(diào)用 InnoDB 的函數(shù)接口。
- 對于讀操作。InnoDB存儲引擎會先檢查 Buffer Pool 中是否存在所需的 B+樹數(shù)據(jù)頁,如果存在則直接返回?cái)?shù)據(jù)。如果 Buffer Pool 中沒有所需的數(shù)據(jù)頁,則會從磁盤中讀取相應(yīng)的數(shù)據(jù)頁加載到 Buffer Pool 中,再返回?cái)?shù)據(jù)。同時(shí),如果查詢的數(shù)據(jù)是熱點(diǎn)數(shù)據(jù),還會將數(shù)據(jù)頁加入到自適應(yīng)哈希索引豪華套餐中,加速后續(xù)的查詢。
- 對于寫操作,則會先將數(shù)據(jù)寫入 Buffer Pool,并生成相應(yīng)的 Undo Log 記錄,以便在事務(wù)回滾時(shí)能夠恢復(fù)數(shù)據(jù)的原始狀態(tài)。接下來,會將寫操作記錄到 Redo Log Buffer 中,這些 redo log 會周期性地寫入到磁盤中的 Redo Log 文件中,就算數(shù)據(jù)庫崩了,已提交的事務(wù)也不會丟失。對于輔助索引的更新操作,InnoDB 會將這些更新暫時(shí)存儲在 Change Buffer 中,等到相關(guān)的索引頁被讀取到 Buffer Pool 時(shí)再進(jìn)行實(shí)際的更新操作,從而減少磁盤 I/O,提高寫入性能。同時(shí),所有的變更都會記錄到 server 層的 binlog 中,以便進(jìn)行數(shù)據(jù)恢復(fù)。
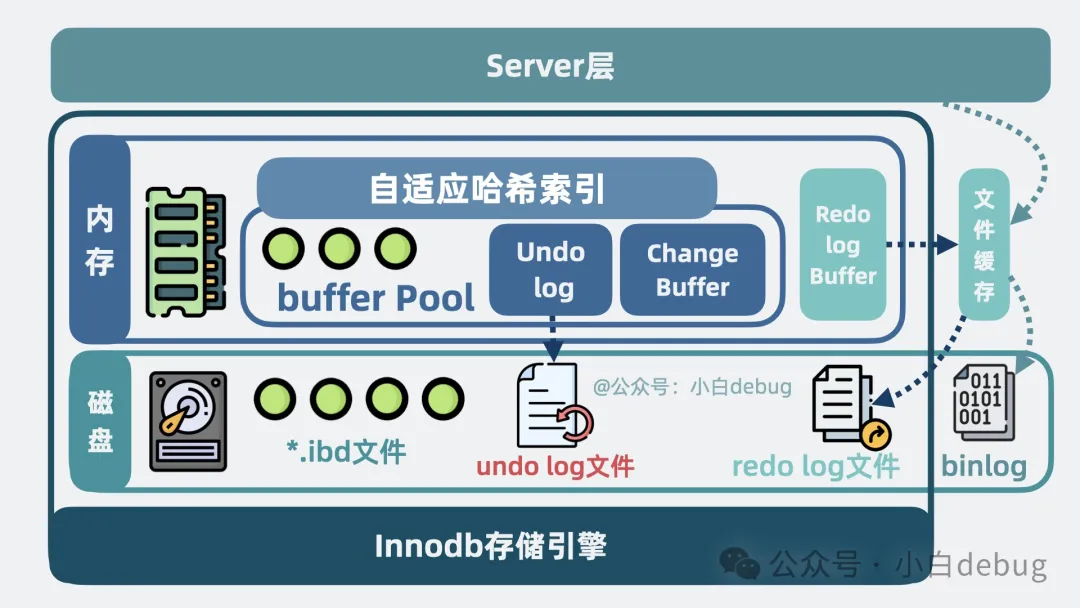
mysql架構(gòu)總覽圖
現(xiàn)在大家通了嗎?
總結(jié)
- MySQL 分為 server 層和存儲引擎層。存儲引擎層可更換,既可以是 myisam,也可以是 innodb。當(dāng)前用 innodb 更多。
- innodb 分為內(nèi)存和磁盤兩部分,一部分是內(nèi)存里的自適應(yīng) hash,buffer bool,以及 redo log buffer。另一部分是磁盤里存放行數(shù)據(jù)和索引的.ibd 文件, 以及 undo log, redo log 等文件。
- mysql server 層會通過 binlog 記錄數(shù)據(jù)庫變更操作,binlog 可以用于數(shù)據(jù)恢復(fù),也可以用于主從同步等場景。