譯者 | 陳峻
審校 | 重樓
不知你是否知曉,構建和運行機器學習(Machine Learning,ML)模型通常是一個雖有益但耗時且復雜的過程。其中包括:數據準備、特征生成、模型擬合、以及驗證和部署等階段。更重要的是,隨著數據趨勢的變化,這些模型需要保持更新。否則,它們很快會變得過時,進而做出低質量的預測。
而端到端的ML管道則是通過自動化工作流程,來提高可擴展性和效率的必要條件。通過此類管道,開發者可以更加輕松、一致地開發、測試和部署新的模型。下面,我將向你介紹什么是機器學習管道,以及如何根據開發者的需求,創建出ML管道。
什么是機器學習管道?
從定義上說,機器學習管道是對ML工作流程的多個階段進行系統自動化的過程。雖然其管道中的每個階段相對于其他階段而言,都是一個獨立運作的單元,但是它們能夠通過協同,獲得累積的結果。也就是說,機器學習管道采用模塊化的方法,通過對原始數據的提取和預處理,在模型的訓練和部署等多個連續階段,實現高質量的結果預測。
作為自動化通道,ML管道無需人工進行數據收集和處理、模型訓練、質量驗證、以及最終部署,而能夠自動執行各種重復性的過程。據此,管道可以提高模型的管理和維護效率,降低錯誤率,進而最終提高各種模型的準確性和可靠性。
同時,可被用于單個或多個模型ML管道,通過為數據科學家和人工智能(AI)工程師提供可擴展且持久的解決方案,來開發、產生和更新AI系統,幫助他們有效地管理ML流程的復雜性。
此外,合理的管道執行會使得ML工作流的實施更加靈活。你可以自行定義所需的功能、模型參數和監控指標,以生成和更新管道中最關鍵的組件:模型。當然,此處的“管道”一詞并不代表著單向流動。ML管道可以通過循環來支持迭代。而且,ML管道不同于數據管道。數據管道的目標是在轉換系統的同時,在系統之間移動數據。而ML管道專注于簡化和加速復雜的ML流程,以提高效率。
創建機器管道的分步指南
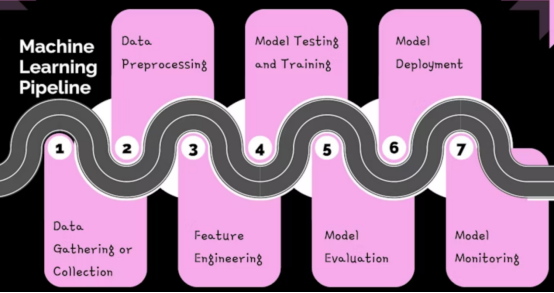
無論面對何種應用場景,大多數ML管道的典型階段是相似的,基本上會遵循如上圖所示的工作流程。其中的每個階段都建立在前一個階段的基礎上。也就是說,在獲得最終結果之前,前一階段的輸出將成為后一階段的輸入。下面,我們來具體討論典型ML管道中的各個階段:
1. 數據的收集
作為第一階段,ML管道會將從應用程序編程接口(API)、調查和問卷、在線數據庫、機構記錄、以及政府機構文件等來源,收集和記錄原始數據。數據是源自第一手研究,還是現有資源,則取決于ML使用案例的具體情況。
在此階段,你可以使用諸如:Request、Beautiful Soup、Scrapy 和 Selenium等任一款強大的Python數據收集庫。同時,由于這些數據是原始的、非結構化的且混亂的,因此它們并不適合直接開展ML分析,需要進入下一階段。
2. 數據預處理
在此階段,數據將被清理,并以可用的格式進行組織,以實現高效的分析,以及針對模型的訓練和測試。如果此階段被跳過,收集到的數據則將不適合模型。也就是說,模型將無法使用數據集來產生任何有意義的結果。
在ML中,典型的數據預處理步驟包括:整理缺失數據、處理重復數據、減少干擾數據、以及特征工程(下一階段會討論到)。數據預處理的實用Python庫包括:Pandas、NumPy、Scikit-Learn和Scipy等。數據預處理的最終目標是為特征工程準備數據。
3. 特征工程
特征工程是創建新特征的過程,同時也可以識別出那些對于提高模型預測能力具有重要意義的、相關預先存在的特征。此階段也是數據預處理的一部分,畢竟該階段需要將數據轉換為適合特定類型算法、且能夠有效訓練ML模型的形式。
特征工程的全過程通常會涉及以下技術:
- 特征提取:這是從原始數據中識別和轉換最重要特征的過程,它調用算法專注于數據集中的重要內容。例如,如果你想通過構建一個模型,來預測哪個學生會獲得獎學金,那么哪些數據集會對此有用呢?在通常情況下,學習成績、財務狀況背景、個人特質等特征都將是相關的。典型的特征提取技術包括:降維和主成分分析(PCA)。這兩者都可以使用Python的 Scikit-Learn庫來實現。當然,具體選擇哪種技術,則取決于數據類型和你的目標。
- 特征縮放、歸一化、標準化:這是對數據集中的特征進行歸一化(即:將特征調整到通用維度)的過程,可確保學習算法更容易地找到它們之間有意義的關系。當數據集中的所有特征具有相似的維度時,它會消除由于數據量級而導致的偏差。請注意,并非所有的ML算法都需要特征縮放。那些能夠處理多特征(如:決策樹和隨機森林)的、基于樹的算法,就不需要特征擴展。
- 特征編碼:這是將相關分類特征轉換為數字特征,以確保算法發揮最佳性能的過程。例如,如果獎學金預測數據集的 “財務狀況背景” 列中的觀察結果是可以被分類的,那么特征編碼會將它們轉換為 0 和 1 的數值。特征編碼的典型示例包括:One-hot或dummy編碼、標簽編碼和序號編碼等。對于此過程,你可以使用Python的Scikit-Learn庫。
值得注意的是,特征工程是管道中最重要的階段之一,畢竟它可以幫助ML模型學習到數據的模式,并提升其性能。當然,特征工程是一個復雜的過程,它需要通過實驗,來確定與訓練模型相關的特征,具體情況則取決于你使用的特定案例。
4. 模型訓練和測試
根據你的需求(如:分類、聚類、回歸)和性能指標選擇了合適的ML算法后,就可以開始訓練生成的模型了。數據集通常會被分為兩類,分別用于訓練和測試。其中的訓練數據集將幫助模型了解特征和目標變量(或稱標簽)中的任何潛在模式和關系。該訓練過程將教會模型以盡可能高的準確性,獲取輸入,并預測輸出。注意:此處的特征是向模型提供信息的輸入,而目標變量(標簽)則是模型嘗試預測的輸出。
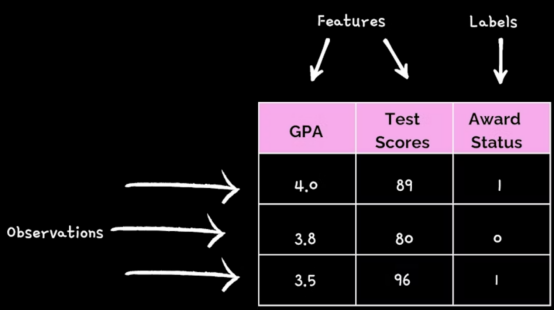
當模型達到目標預測的精度時,訓練即可結束。如果模型的性能低于預期,你可以通過重新訓練模型的方式更改算法,或是添加更準確的數據,甚至可以設計新的功能來處理性能不佳的情況。
5. 模型評估或分析
訓練結束后,我們可以使用準確率、精度、召回率和 F1 分數等性能指標,來評估模型的性能。其中:
● 準確性:表示正確分類的實例,占所有實例的比例。
● 精度:表示那些被分類為“真”的模型,占比所有實際確為“真”的數量。
● 召回率:衡量模型設法識別出的實際為“真”的實例數量。
● F1 分數:將精確率和召回率采取平衡(加權調和平均)的數值。隨著精度的提高,召回率會下降,反之亦然。當你在精確率和召回率之間找到了最佳平衡時,便獲得了最有價值的指標。
總的說來,此階段的目標是確保模型在處理新的、未曾見過的數據時的表現。
6. 模型部署
ML管道的這個階段意味著,你已成功開發并評估了符合預測準確性水平的模型。至此,我們可以將模型部署到生產環境,以確保它可以在實際環境中運行了。例如,獎學金預測模型可以在學校現有的學生檔案記錄系統中被部署實施,以便投產使用。
在此,你可以使用一款由Google發布的開源工具--TensorFlow Extended(TFX) 。它可以使得Python中的模型在部署過程更加高效。同時,該工具提供了許多框架、庫和組件,可用于模型的訓練、服務、部署和監控。
7. 模型的監控
這是ML管道的最后階段。隨著時間的推移,數據會逐漸過期,模型的預測精度也會隨之降低。這種準確度的下降常被稱為模型漂移。這就是為什么我們需要持續監控在生產環境中模型的性能,并在必要時對其進行再訓練,以確保其仍然準確可靠的原因。
通常,有如下兩種類型的模型漂移:
- 數據漂移:當特征的統計屬性發生了變化,但特征和目標變量之間的關系仍保持不變時,就會發生此類漂移。這意味著生產環境中的特征與訓練階段的特征出現了差異。讓我們仍以獎學金預測模型為例,如果該模型在2020年之前已投產,而學校后續引入了新的錄取標準,并改變了他們評估課外活動的方式,那么就會影響到該模型的預測能力。其根本原因在于模型沒有通過更新,以反映上述變化,自然也就表現不佳。
- 概念漂移:當特征和目標變量之間的關系隨著時間的推移而發生變化時,就會出現此類漂移。例如,在使用獎學金預測模型時,如果最初的模型是根據GPA和考試成績來預測獎學金的可能性,但是學校現在關注的是社區服務或領導潛力等社會價值,那么模型的準確性就會下降。這正是因為特征與目標變量(即:獎學金)之間的關系發生了變化。因此,我們需要用新的標準對模型進行重新訓練。
當然,模型監控也可以跟蹤準確度的變化、各種偏差、公平性、以及操作指標。TensforFlow庫里的TensorBoard便是一個很好的模型監控工具。同時,ML的可觀察性平臺(如:obvious AI和Valohai)在該階段也非常實用。
創建機器學習管道的好處
創建機器學習管道的主要優勢包括:
- 更高的生產力:機器學習管道減少了對于持續人工干預和手動方法的依賴。通過減少重復性流程和優先考慮自動化,數據科學家可以有更多的時間,來完成真正需要人工干預的工作,例如:決策的制定、數據的標注(即:正確地標記數據)、以及在訓練期間模型的微調。
- 高質量的預測:構造良好的機器學習管道可以減少誤判,讓模型返回更接近真實情況的預測。
- 可擴展性:高效的ML管道不但可以處理大量復雜的數據,而且可以確保模型能夠被繼續有效地執行。由于企業的數據量會隨著業務不斷增長,因此這一點顯得非常重要。
- 易于故障排查:由于管道中的每個階段都是相互獨立的,因此更易于在特定的階段跟蹤問題,并隨后開展調試。
綜上所述,機器學習管道是數據科學家的強大工具。它們能夠在將原始數據轉化為有價值的見解的過程中,提供一致且有效的流程保證。
譯者介紹
陳峻(Julian Chen),51CTO社區編輯,具有十多年的IT項目實施經驗,善于對內外部資源與風險實施管控,專注傳播網絡與信息安全知識與經驗。
原文標題:Set Up Your First Machine Learning Pipeline With This Beginner’s Guide,作者:Praise James