為什么用雪花ID替代自增ID?
今天咱們來看一道數據庫中比較經典的面試問題:為什么要使用雪花 ID 替代數據庫自增 ID?同時這道題也出現在了浩鯨科技的 Java 面試中,下面我們一起來看吧。
1.什么是雪花 ID?
雪花 ID(Snowflake ID)是一個用于分布式系統中生成唯一 ID 的算法,由 Twitter 公司提出。它的設計目標是在分布式環境下高效地生成全局唯一的 ID,具有一定的有序性。
雪花 ID 的結構如下所示:

這四部分代表的含義
- 符號位:最高位是符號位,始終為 0,1 表示負數,0 表示正數,ID 都是正整數,所以固定為 0。
- 時間戳部分:由 41 位組成,精確到毫秒級。可以使用該 41 位表示的時間戳來表示的時間可以使用 69 年。
- 節點 ID 部分:由 10 位組成,用于表示機器節點的唯一標識符。在同一毫秒內,不同的節點生成的 ID 會有所不同。
- 序列號部分:由 12 位組成,用于標識同一毫秒內生成的不同 ID 序列。在同一毫秒內,可以生成 4096 個不同的 ID。
2.Java 版雪花算法實現
接下來,我們來實現一個 Java 版的雪花算法:
public class SnowflakeIdGenerator {
// 定義雪花 ID 的各部分位數
private static final long TIMESTAMP_BITS = 41L;
private static final long NODE_ID_BITS = 10L;
private static final long SEQUENCE_BITS = 12L;
// 定義起始時間戳(可根據實際情況調整)
private static final long EPOCH = 1609459200000L;
// 定義最大取值范圍
private static final long MAX_NODE_ID = (1L << NODE_ID_BITS) - 1;
private static final long MAX_SEQUENCE = (1L << SEQUENCE_BITS) - 1;
// 定義偏移量
private static final long TIMESTAMP_SHIFT = NODE_ID_BITS + SEQUENCE_BITS;
private static final long NODE_ID_SHIFT = SEQUENCE_BITS;
private final long nodeId;
private long lastTimestamp = -1L;
private long sequence = 0L;
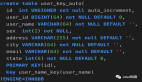
public SnowflakeIdGenerator(long nodeId) {
if (nodeId < 0 || nodeId > MAX_NODE_ID) {
throw new IllegalArgumentException("Invalid node ID");
}
this.nodeId = nodeId;
}
public synchronized long generateId() {
long currentTimestamp = timestamp();
if (currentTimestamp < lastTimestamp) {
throw new IllegalStateException("Clock moved backwards");
}
if (currentTimestamp == lastTimestamp) {
sequence = (sequence + 1) & MAX_SEQUENCE;
if (sequence == 0) {
currentTimestamp = untilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = currentTimestamp;
return ((currentTimestamp - EPOCH) << TIMESTAMP_SHIFT) |
(nodeId << NODE_ID_SHIFT) |
sequence;
}
private long timestamp() {
return System.currentTimeMillis();
}
private long untilNextMillis(long lastTimestamp) {
long currentTimestamp = timestamp();
while (currentTimestamp <= lastTimestamp) {
currentTimestamp = timestamp();
}
return currentTimestamp;
}
}調用代碼如下:
public class Main {
public static void main(String[] args) {
// 創建一個雪花 ID 生成器實例,傳入節點 ID
SnowflakeIdGenerator idGenerator = new SnowflakeIdGenerator(1);
// 生成 ID
long id = idGenerator.generateId();
System.out.println(id);
}
}其中,nodeId 表示當前節點的唯一標識,可以根據實際情況進行設置。generateId 方法用于生成雪花 ID,采用同步方式確保線程安全。具體的生成邏輯遵循雪花 ID 的位運算規則,結合當前時間戳、節點 ID 和序列號生成唯一的 ID。
“
需要注意的是,示例中的時間戳獲取方法使用了 System.currentTimeMillis(),根據實際需要可以替換為其他更精確的時間戳獲取方式。同時,需要確保節點 ID 的唯一性,避免不同節點生成的 ID 重復。
”
3.雪花算法問題
雖然雪花算法是一種被廣泛采用的分布式唯一 ID 生成算法,但它也存在以下幾個問題:
- 時間回撥問題:雪花算法生成的 ID 依賴于系統的時間戳,要求系統的時鐘必須是單調遞增的。如果系統的時鐘發生回撥,可能導致生成的 ID 重復。時間回撥是指系統的時鐘在某個時間點之后突然往回走(人為設置),即出現了時間上的逆流情況。
- 時鐘回撥帶來的可用性和性能問題:由于時間依賴性,當系統時鐘發生回撥時,雪花算法需要進行額外的處理,如等待系統時鐘追上上一次生成 ID 的時間戳或拋出異常。這種處理會對算法的可用性和性能產生一定影響。
- 節點 ID 依賴問題:雪花算法需要為每個節點分配唯一的節點 ID 來保證生成的 ID 的全局唯一性。節點 ID 的分配需要有一定的管理和調度,特別是在動態擴容或縮容時,節點 ID 的管理可能較為復雜。
4.如何解決時間回撥問題?
百度 UidGenerator 框架中解決了時間回撥的問題,并且解決方案比較經典,所以咱們這里就來給大家分享一下百度 UidGenerator 是怎么解決時間回撥問題的?
“
UidGenerator 介紹:UidGenerator 是百度開源的一個分布式唯一 ID 生成器,它是基于 Snowflake 算法的改進版本。與傳統的 Snowflake 算法相比,UidGenerator 在高并發場景下具有更好的性能和可用性。它的實現源碼在:https://github.com/baidu/uid-generator
”
UidGenerator 是這樣解決時間回撥問題的:UidGenerator 的每個實例中,都維護一個本地時鐘緩存,用于記錄當前時間戳。這個本地時鐘會定期與系統時鐘進行同步,如果檢測到系統時鐘往前走了(出現了時鐘回撥),則將本地時鐘調整為系統時鐘。
5.為什么要使用雪花 ID 替代數據庫自增 ID?
數據庫自增 ID 只適用于單機環境,但如果是分布式環境,是將數據庫進行分庫、分表或數據庫分片等操作時,那么數據庫自增 ID 就有問題了。
例如,數據庫分片之后,會在同一張業務表的分片數據庫中產生相同 ID(數據庫自增 ID 是由每個數據庫單獨記錄和增加的),這樣就會導致,同一個業務表的竟然有相同的 ID,而且相同 ID 背后存儲的數據又完全不同,這樣業務查詢的時候就出問題了。
所以為了解決這個問題,就必須使用分布式中能保證唯一性的雪花 ID 來替代數據庫的自增 ID。
6.擴展:使用 UUID 替代雪花 ID 行不行?
如果單從唯一性來考慮的話,那么 UUID 和雪花 ID 的效果是一致的,二者都能保證分布式系統下的數據唯一性,但是即使這樣,也不建議使用 UUID 替代雪花 ID,因為這樣做的問題有以下兩個:
- 可讀性問題:UUID 內容很長,但沒有業務含義,就是一堆看不懂的“字母”。
- 性能問題:UUID 是字符串類型,而字符串類型在數據庫的查詢中效率很低。
所以,基于以上兩個原因,不建議使用 UUID 來替代雪花 ID。
小結
數據庫自增 ID 只適用于單機數據庫環境,而對于分庫、分表、數據分片來說,自增 ID 不具備唯一性,所以要要使用雪花 ID 來替代數據庫自增 ID。但雪花算法依然存在一些問題,例如時間回撥問題、節點過度依賴問題等,所以此時,可以使用雪花算法的改進框架,如百度的 UidGenerator 來作為數據庫的 ID 生成方案會比較好。